前段时间搭建Hadoop分布式集群,踩了不少坑,网上很多资料都写得不够详细,对于新手来说搭建起来会遇到很多问题。以下是自己根据搭建Hadoop分布式集群的经验希望给新手一些帮助。当然,建议先把HDFS和MapReduce理论原理看懂了再来搭建,会流畅很多。
准备阶段:
系统:Ubuntu Linux16.04 64位 (下载地址:https://www.ubuntu.com/download/desktop)
安装好Ubuntu之后,如果之前没有安装过jdk,需要先安装jdk。这里安装jdk的版本是:jdk1.8.0_144 (下载地址:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html) 这里就不展开安装说明,安装jdk很简单,这里自行百度吧。
建议Ubuntu下载64位,因为Hadoop2.5.0之后的版本里面的库都是64位的,32位的Linux系统里面每次运行Hadoop都会报警告。
现在准备好了一台安装了java的Ubuntu虚拟机,别忘了搭建Hadoop集群至少需要三台Ubuntu虚拟机。
最简单的办法就是 使用VMware自带的克隆的办法,克隆出三台一模一样的虚拟机。
具体操作参见地址 (https://jingyan.baidu.com/article/6b97984d9798f11ca2b0bfcd.html)
准备好了三台Ubuntu Linux虚拟机,接下来就开始搭建集群。
先总的看一下所有的步骤:
一、配置hosts文件
二、建立hadoop运行帐号
三、配置ssh免密码连入
四、下载并解压hadoop安装包
五、配置 /etc/hadoop目录下的几个文件及 /etc/profile
六、格式化namenode并启动集群
接下来根据步骤开始搭建:
一、配置hosts文件
以上准备了三台虚拟机,但是虚拟机的主机名也是一样的,需要现对虚拟机主机名进行修改,来进行区分一个主节点和两个从节点。
修改主机名命令:
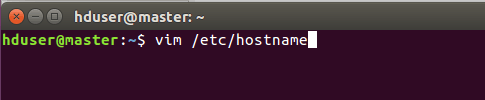
显示的master就是主机名,我这里已经修改好了,可以把三台虚拟机分别命名 主节点:master 从节点1:node1 从节点2:node2

修改好了,保存即可。
接下来,分别查看三台虚拟机的ip地址,命令如下:
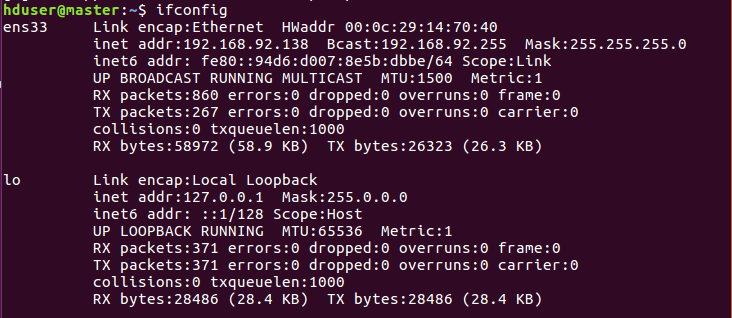
inet addr就是这台虚拟机的ip地址。
接下来打开hosts文件 进行修改:

将三台虚拟机的ip地址和主机名加在里面,其它的不用动它。
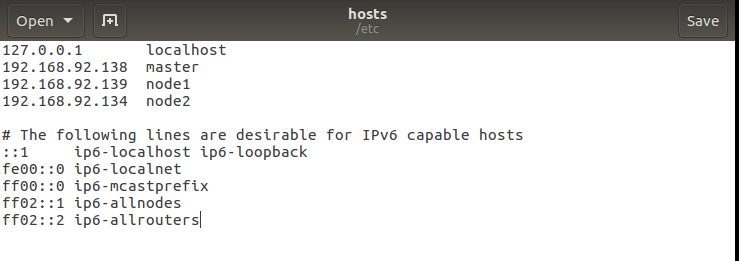
三台虚拟机都要修改hosts文件。简单的说配置hosts后三台虚拟机就可以进行通信了,可以互相ping一下试试,是可以ping通的。
二、建立hadoop运行帐号
解释一下这一步骤,就是建立一个group组,然后在三台虚拟机上重新建立新的用户,将这三个用户都加入到这个group中。
以下操作三台虚拟机都要进行相同操作:
首先添加一个叫hadoop用户组进来
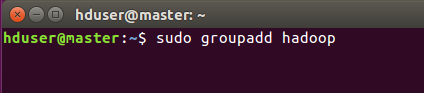
添加名叫hduser的用户,并添加到hadoop组中。

接着输入以下指令然后输入两次密码
然后赋予hduser用户admin权限

接下来的操作 切换到刚刚新建的用户进行
三、配置ssh免密码连入
开始配置ssh之前,先确保三台机器都装了ssh。
输入以下命令查看安装的ssh。
如果缺少了opensh-server,需要进行安装。

安装完毕之后开始配置ssh
接下来的这第三个步骤的操作请注意是在哪台主机上进行,不是在三台上同时进行。
(1)下面的操作在master机上操作
首先在master机上输入以下命令,生成master机的一对公钥和私钥:

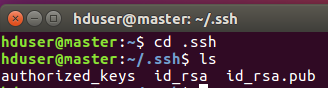
以下命令进入认证目录可以看到, id_rsa 和 id_rsa.pub这两个文件,就是我们刚刚生成的公钥和私钥。
然后,下面的命令将公钥加入到已认证的key中:

再次进入生成目录,可以看到多出authorized_keys这个文件:
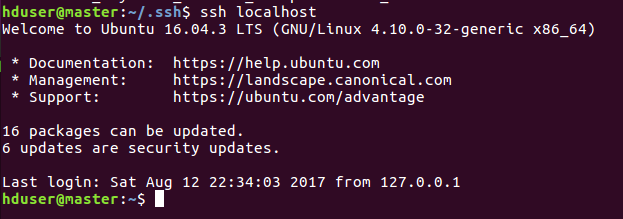
然后输入ssh localhost 登录本机命令,第一次提示输入密码,输入exit退出,再次输入ssh localhost不用输入密码就可以登录本机成功,则本机ssh免密码登录已经成功。
到这里是不是已经对ssh免密码登录有了认识,不要着急,开始配置node1和node2节点的ssh免密码登录,目的是让master主机可以不用密码登录到node1和node2主机。
(2)这一步分别在node1和node2主机上操作:
将master主机上的is_dsa.pub复制到node1主机上,命名为node1_dsa.pub。node2主机进行同样的操作。

将从master得到的密钥加入到认证,node2主机进行同样的操作。

然后开始验证是不是已经可以进行ssh免密码登录。
(3)在master机上进行验证
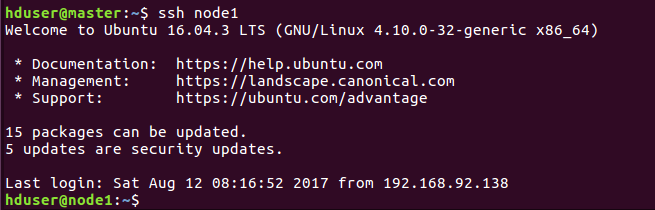
同样第一次需要密码,之后exit退出,再ssh node1就不需要密码登录成功,说明ssh免密码登录配置成功!
如果失败了,可能是前面的认证没有认证好,可以将.ssh目录下的密钥都删了重新生成和配置一遍。或者检查下hosts文件ip地址写的对不对。
四、下载并解压hadoop安装包
版本:Hadoop2.6.0 (下载地址:http://mirrors.hust.edu.cn/apache/hadoop/common/)
建议初学者选择2.6.0或者2.7.0版本就可以了,而且如果后面要配置Eclipse开发环境的话,这两个版本的插件很容易找到,不用自己去编译。
话不多说,将hadoop压缩包,解压到一个文件夹里面,我这里解压到了home文件夹,并修改文件夹名为hadoop2.6。所在的目录就是/home/hduser/hadoop2.6
三台主机都要解压到相应位置
五、配置 /etc/hadoop目录下的几个文件及 /etc/profile
主要有这5个文件需要修改:
~/etc/hadoop/hadoop-env.sh
~/etc/hadoop/core-site.xml
~/etc/hadoop/hdfs-site.xml
~/etc/hadoop/mapred-site.xml
~/etc/hadoop/slaves
/etc/profile
三台机都要进行这些操作,可以先在一台主机上修改,修改完了复制到其它主机就可以了。
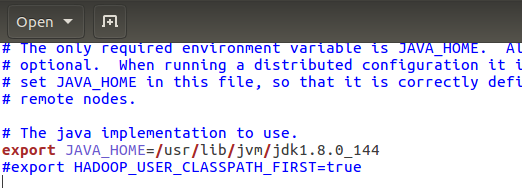
首先是hadoop-env.sh ,添加java安装的地址,保存退出即可。
然后core-site.cml
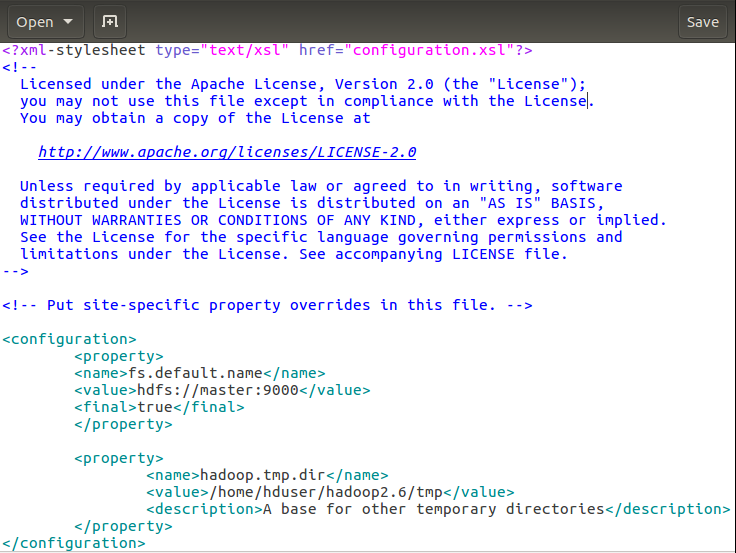
解释下:第一个fs.default.name设置master机为namenode 第二个hadoop.tmp.dir配置Hadoop的一个临时目录,用来存放每次运行的作业jpb的信息。
接下来hdfs-site.xml的修改:
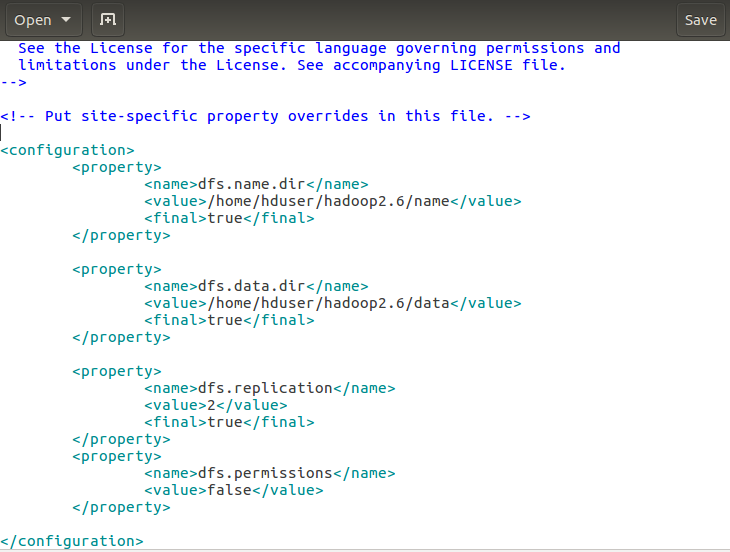
解释下:dfs.name.dir是namenode存储永久性的元数据的目录列表。这个目录会创建在master机上。dfs.data.dir是datanode存放数据块的目录列表,这个目录在node1和node2机都会创建。 dfs.replication 设置文件副本数,这里两个datanode,所以设置副本数为2。
接下来mapred-site.xml的修改:
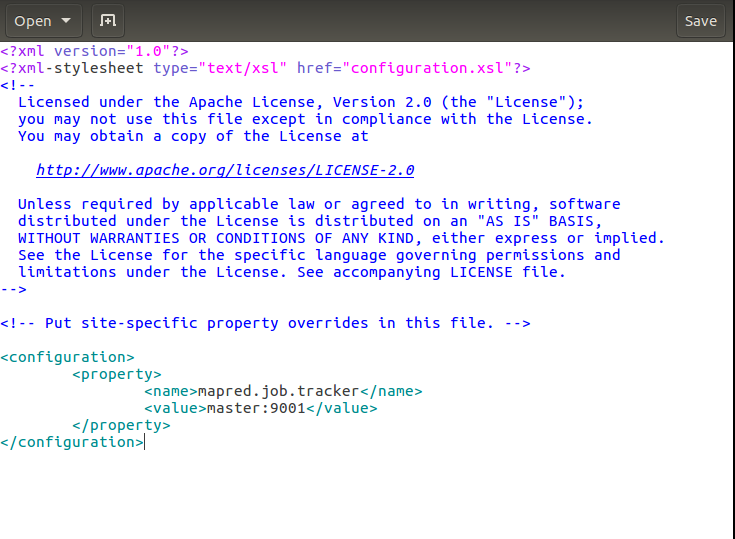
解释下:这里设置的是运行jobtracker的服务器主机名和端口,也就是作业将在master主机的9001端口执行。
接下来修改slaves文件

这里将两台从主机的主机名node1和node2加进去就可以了。
最后修改profile文件 ,如下进入profile:

将这几个路径添加到末尾:

修改完让它生效:

检查下是否可以看到hadoop版本信息
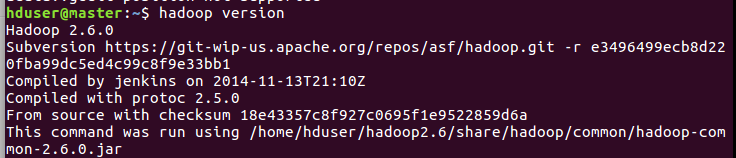
显示出了版本信息,如果没有显示出来,回过去检查 profile路径是否填写错误。
六、格式化namenode并启动集群
接下来需要格式化namenode,注意只需要在 master主机上进行格式化。格式化命令如下:

看到successful表示格式化成功。
接下来启动集群:

启动完毕,检查下启动情况: master主机看到四个开启的进程,node1和node2看到三个开启的进程表示启动成功。

