
前言:
MySQL的性能是大家在使用时十分关心的问题,比如在高并发访问时,并且有慢sql存在的情况下,MySQL的性能会明显下降,这会导致数据库响应时间变慢,甚至导致数据库宕机。那么为了避免Mysql性能问题,比较常用的方式创建适当的索引,提升sql语句的执行效率。而本文简单介绍一下和索引有关的回表,从实际案例出发,讲讲什么是回表,如何避免回表,如何减少回表。
实际案例:
前置仓产能动态ETA时效降级需求,提供一个数据同步接口,接送大数据同步过来的前置仓的仓负债和配负债,需要支持批量,最多可支持10个批量。
表结构如下,可以看到唯一索引是 UNIQUE KEY `uniq_shop` (`shop_id`,`shop_type`)
CREATE TABLE `shop_load_degrade_strategy` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`shop_id` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '门店ID',
`shop_type` int(11) NOT NULL DEFAULT '0' COMMENT '门店类型',
`current_store_load` int(10) NOT NULL DEFAULT '0' COMMENT '当前仓负载',
`active_store_load` int(10) NOT NULL DEFAULT '0' COMMENT '正在使用的仓负载',
`active_store_degrade_delay` int(11) NOT NULL DEFAULT '0' COMMENT '正在使用的仓降级时间分钟数',
`current_delivery_load` int(10) NOT NULL DEFAULT '0' COMMENT '当前配送负载',
`active_delivery_load` int(10) NOT NULL DEFAULT '0' COMMENT '正在使用的配送负载',
`active_delivery_degrade_delay` int(11) NOT NULL DEFAULT '0' COMMENT '正在使用的配送降级时间分钟数',
`current_load_active_auto` tinyint(3) unsigned NOT NULL DEFAULT '0' COMMENT '仓配负载自动生效,1开启',
`enable` tinyint(3) unsigned NOT NULL DEFAULT '0' COMMENT '是否开启,1开启',
`artificial_active_time` datetime DEFAULT NULL COMMENT '运营手动生效时间',
`active_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '最后生效时间',
`approver` varchar(100) DEFAULT NULL COMMENT '审批人',
`status` tinyint(4) NOT NULL DEFAULT '0' COMMENT '状态:1启用,0失效',
`yn` tinyint(3) unsigned NOT NULL DEFAULT '0' COMMENT '1删除',
`update_pin` varchar(50) NOT NULL DEFAULT '' COMMENT '最后修改人',
`update_time` datetime NOT NULL COMMENT '修改时间',
`create_pin` varchar(50) NOT NULL DEFAULT '' COMMENT '创建人',
`create_time` datetime NOT NULL COMMENT '创建时间',
`ts` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '时间戳',
PRIMARY KEY (`id`),
UNIQUE KEY `uniq_shop` (`shop_id`,`shop_type`),
KEY `idx_active_time` (`active_time`),
KEY `idx_update_pin` (`update_pin`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='门店负载降级策略表';
数据处理流程
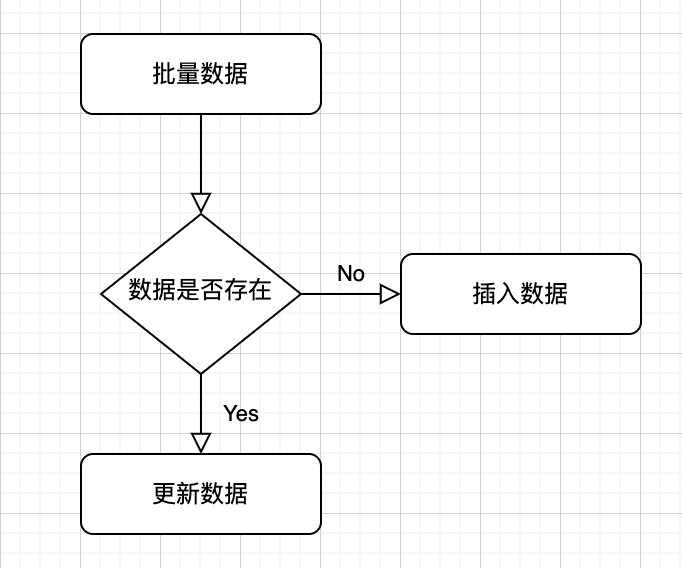
最简单的处理方式就是,逐条数据处理
public void handRecords(List<ShopLoadDegradeStrategy> records){
for(ShopLoadDegradeStrategy shopLoadDegradeStrategy: records){
dbShopLoadDegradeStrategy = findByshopIdAndShopType(shopLoadDegradeStrategy);
if(null != dbShopLoadDegradeStrategy)
shopLoadDegradeStrategy.setId(dbShopLoadDegradeStrategy.getId())
updateById(shopLoadDegradeStrategy);
}else{
insert(shopLoadDegradeStrategy);
}
}
}
最初的优化思想的减少网络传输次数
public void handRecords(List<ShopLoadDegradeStrategy> records){
//批量查询
List<ShopLoadDegradeStrategy> dbShopLoadDegradeStrategys = findAllByshopIdAndShopTypeList(records);
updateShopLoadDegradeStrategys,insertShopLoadDegradeStrategys = handleShopLoadDegradeStrategys(records,dbShopLoadDegradeStrategys);
updateForEach(updateShopLoadDegradeStrategys);
//批量插入
batchInsert(insertShopLoadDegradeStrategys);
}
具体sql语句:
批量按照门店Id和门店类型查询数据是否存在
select * from shop_load_degrade_strategy where (shop_id=? and shop_type=?) or (shop_id=? and shop_type=?)
存在更新数据, 因为shop_id和shop_type是组合的唯一索引,所以按照主键更新和按照唯一索引更新的结果是一样的。但是过程真的一样吗?
update shop_load_degrade_strategy set current_store_load=?,current_delivery_load=? where shop_id=? and shop_type=?
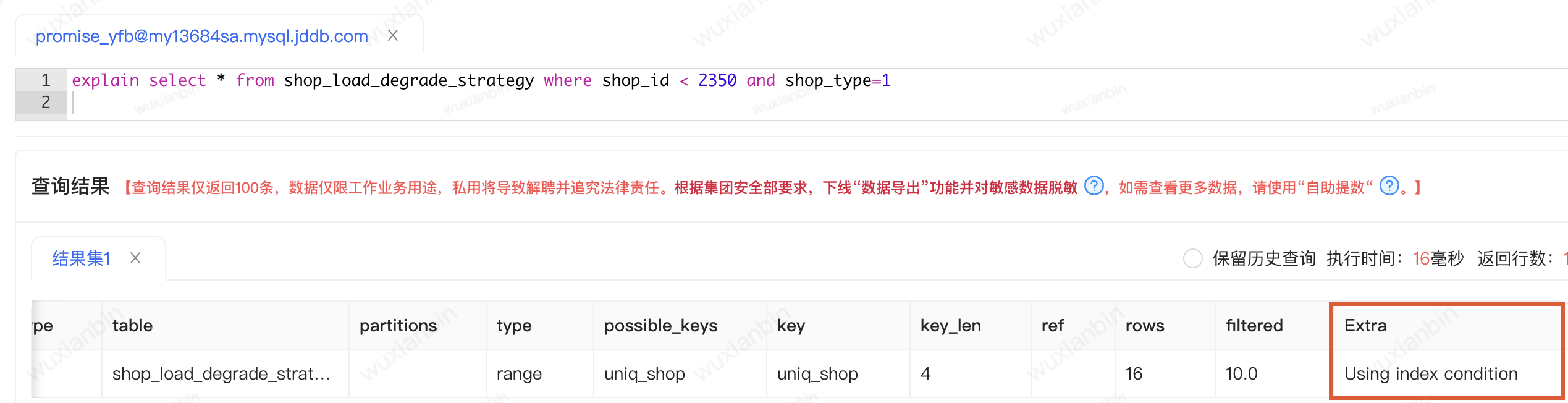
看是很简单的两个sql语句,explain分析sql执行计划,可以看出用到了索引,并且sql语句执行也很快,不存在慢sql的问题。还有优化的空间吗?
优化过程分析
先简单介绍一下索引按物理存储分类
mysql的B+树
1)聚集索引(聚簇索引) InnoDB的聚簇索引就是按照主键顺序构建 B+Tree结构。叶子节点存储数据行的数据。
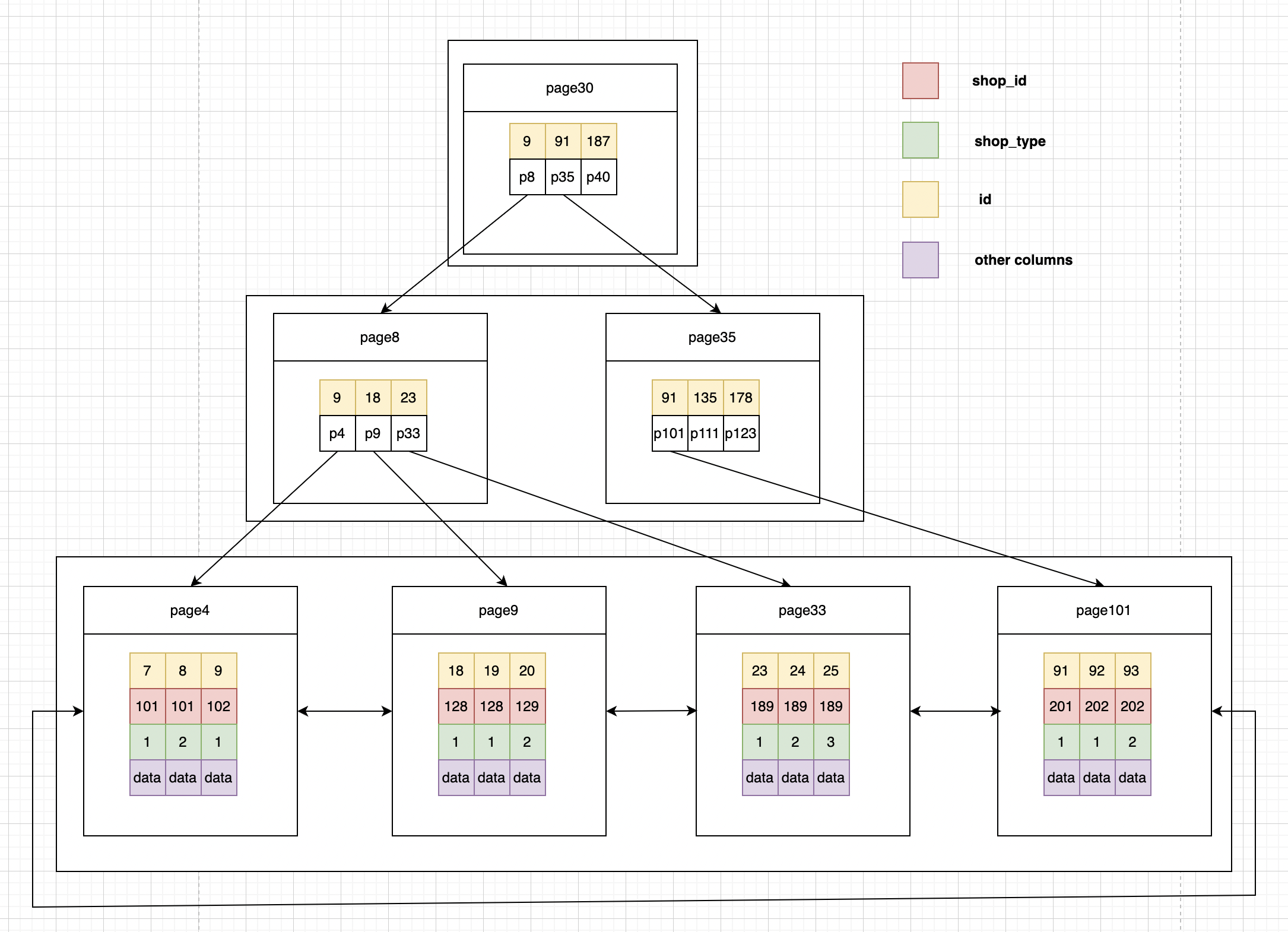
2)辅助索引(二级索引) InnoDB的辅助索引就是按照索引列构建 B+Tree结构。叶子节点存储的是索引列的值以及对应行的主键值
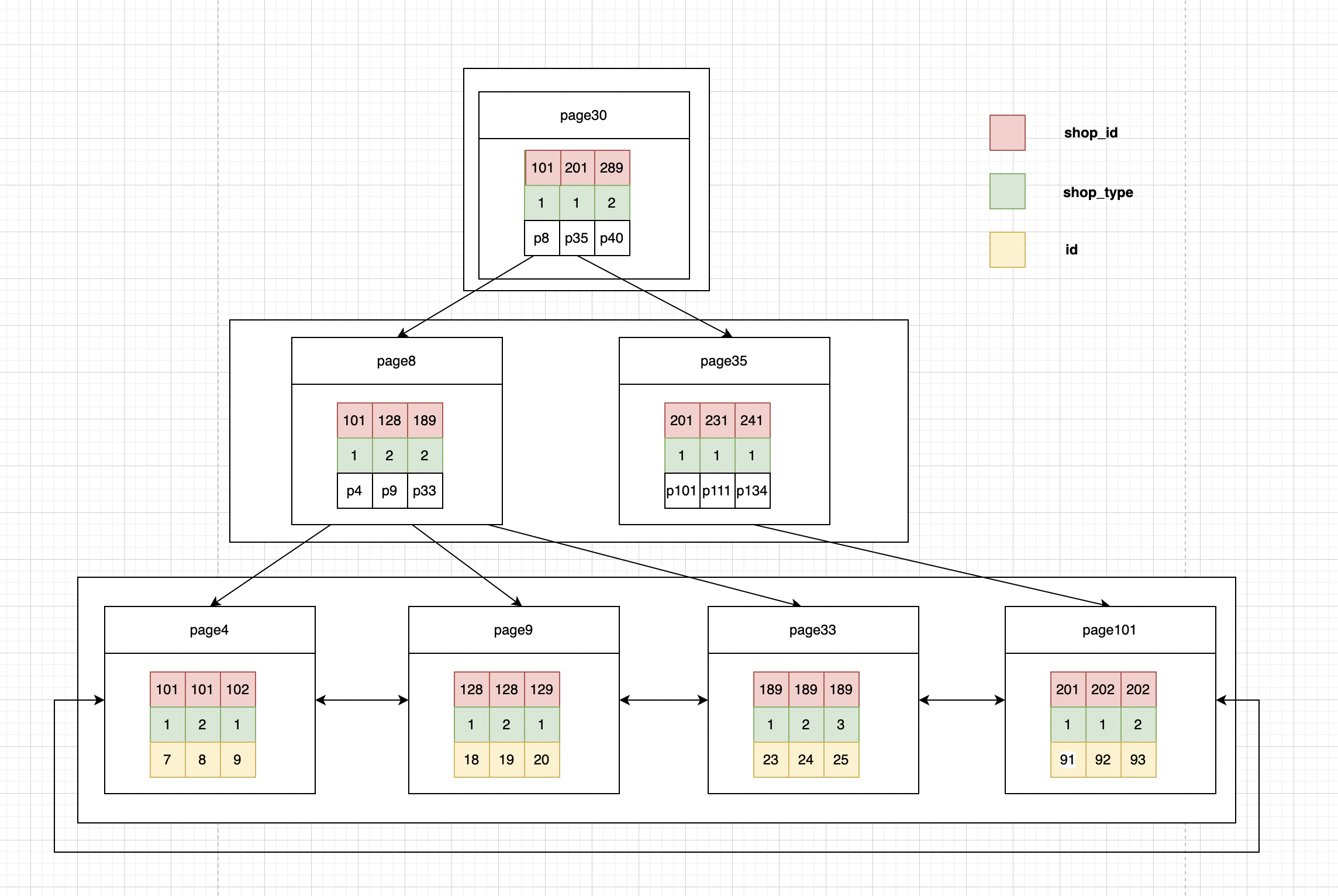
覆盖索引并不是说是索引结构,覆盖索引是一种很常用的优化手段。因为在使用辅助索引的时候,我们只可以拿到主键值,相当于获取数据还需要再根据主键查询主键索引再获取到数据。但是试想下这么一种情况,在上面shop_load_degrade_strategy表中的组合索引查询时,如果我只需要id,shop_id,shop_type字段的,那是不是意味着我们查询到组合索引的叶子节点就可以直接返回了,而不需要回表。这种情况就是覆盖索引。
查询sql语句优化为:
select id,shop_id,shop_type from shop_load_degrade_strategy where (shop_id=? and shop_type=?) or (shop_id=? and shop_type=?)
优化前
1.select * from shop_load_degrade_strategy where (shop_id=? and shop_type=?) or (shop_id=? and shop_type=?)
优化前:
1.先查询辅助索引找到对应的主键Id
2.然后通过id回表查询数据表的数据。

优化后
1.只需要查询辅助索引就可以,通过查询辅助索引就可以查询到所以需要的列,想要使用覆盖索引,查询的结果的列只能包含在辅助索引列和主键索引列。通过查看sql计划可以到Extra的值为Using index。
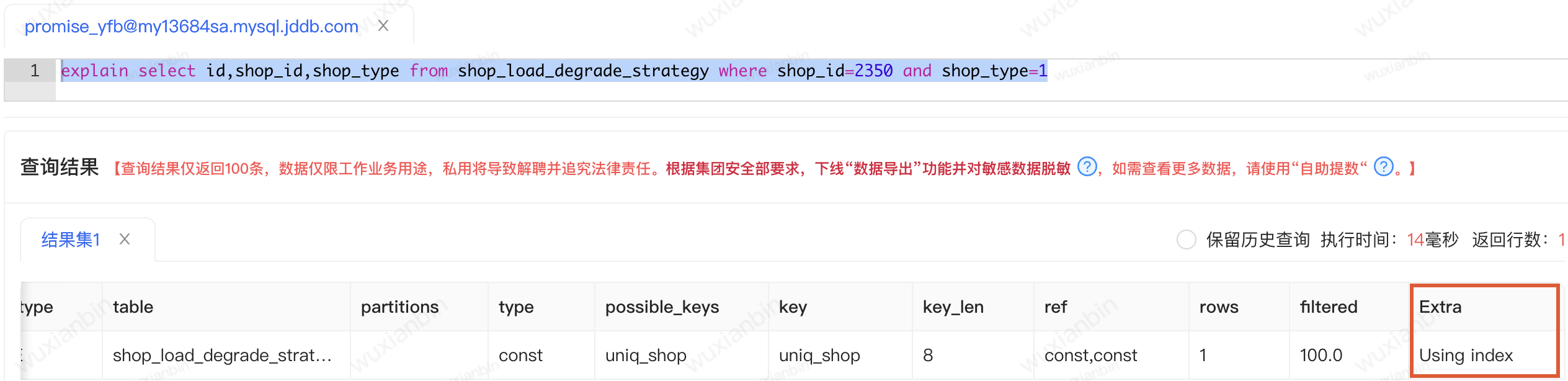
总结:优化前要查询除了索引字段(shop_id,shop_type)和主键(id)之外的字段,不能用到覆盖索引这种方式。所以在编写sql的时候,查询的数据列一定是满足业务的最小列集合,首先减少网络传输的数据量,同时也会减少应用的内存使用,还有看看能不能使用到覆盖索引这种方式进行优化,有些情况下甚至会在辅助索引中增加联合索引的列来使用到覆盖索引减少回表。
更新sql语句的优化
优化后:
update shop_load_degrade_strategy set current_store_load=?,current_delivery_load=? where id=?
优化前:
update shop_load_degrade_strategy set current_store_load=?,current_delivery_load=? where shop_id=? and shop_type=?
优化前的更新语句虽然使用到了辅助索引作为查询条件来进行数据更新,但是mysql执行sql的过程为:
1.先查询辅助索引找到索引对应的主键Id
2.然后通过id回表查询数据表的数据。
3.最后更新数据。
优化后的sql执行过程为:
1.通过id回表查询数据表的数据。
2.最会更新对应id的数据,
从以上描述可以看出,减少回表也是我们优化sql语句的一种很重要的思想。通过减少回表这个思想和处理数据的方式,引出说明一下mysql索引下推这个概念,其核心思想就是减少回表
什么是索引下推
索引下推(Index Condition Pushdown,索引条件下推,简称ICP),是MySQL5.6版本的新特性,它可以在对联合索引遍历过程中,对索引中包含的所有字段先做判断,过滤掉不符合条件的记录之后再回表,能有效的减少回表次数(目前我们使用的mysql版本较高,一般大家可能感觉这是正常的,但是mysql5.6之前都不是这样实现的,下面会细细道来)。
适用条件
我们先来了解一下索引下推的使用条件及限制:
原理介绍
具体例子
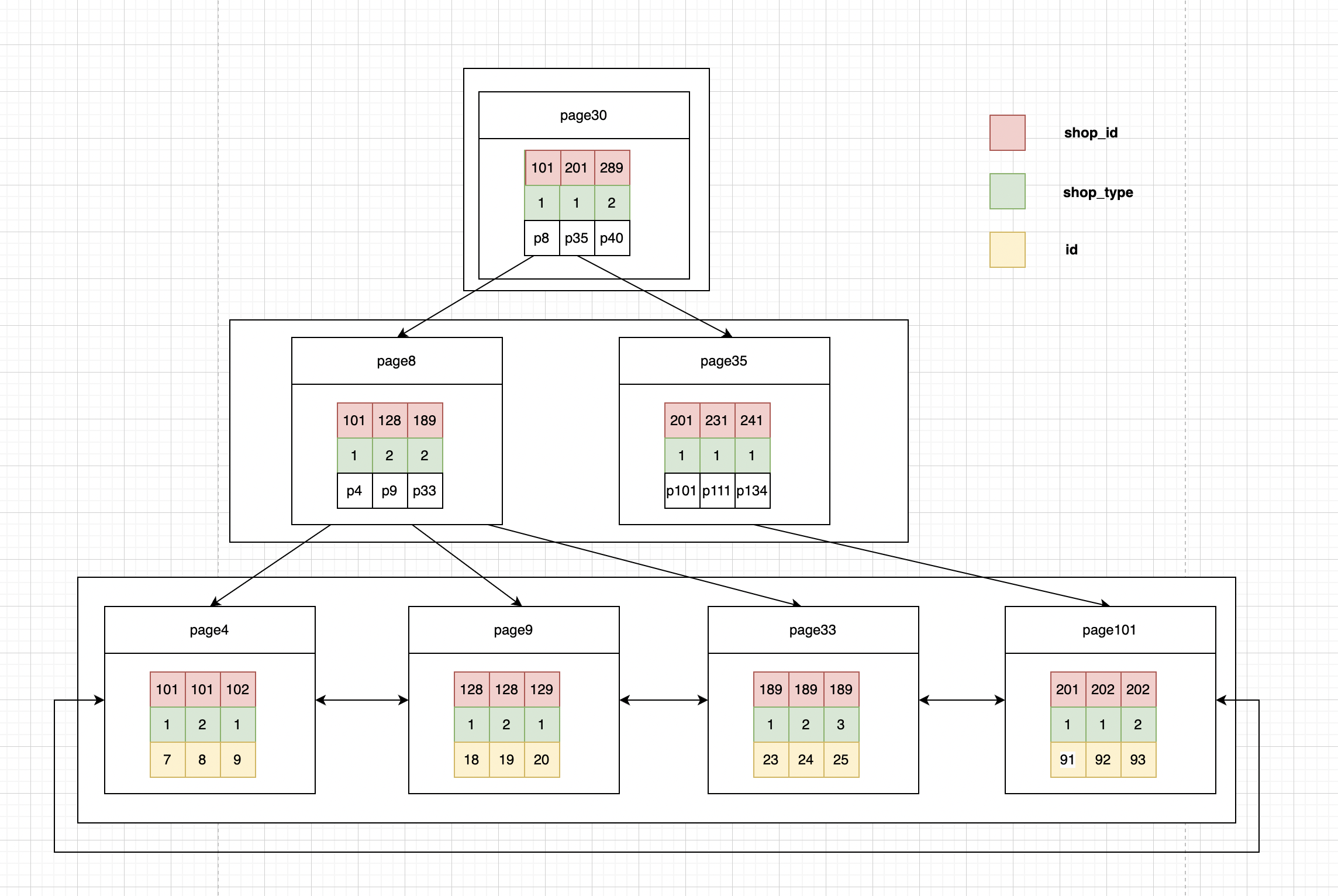
聚簇索引
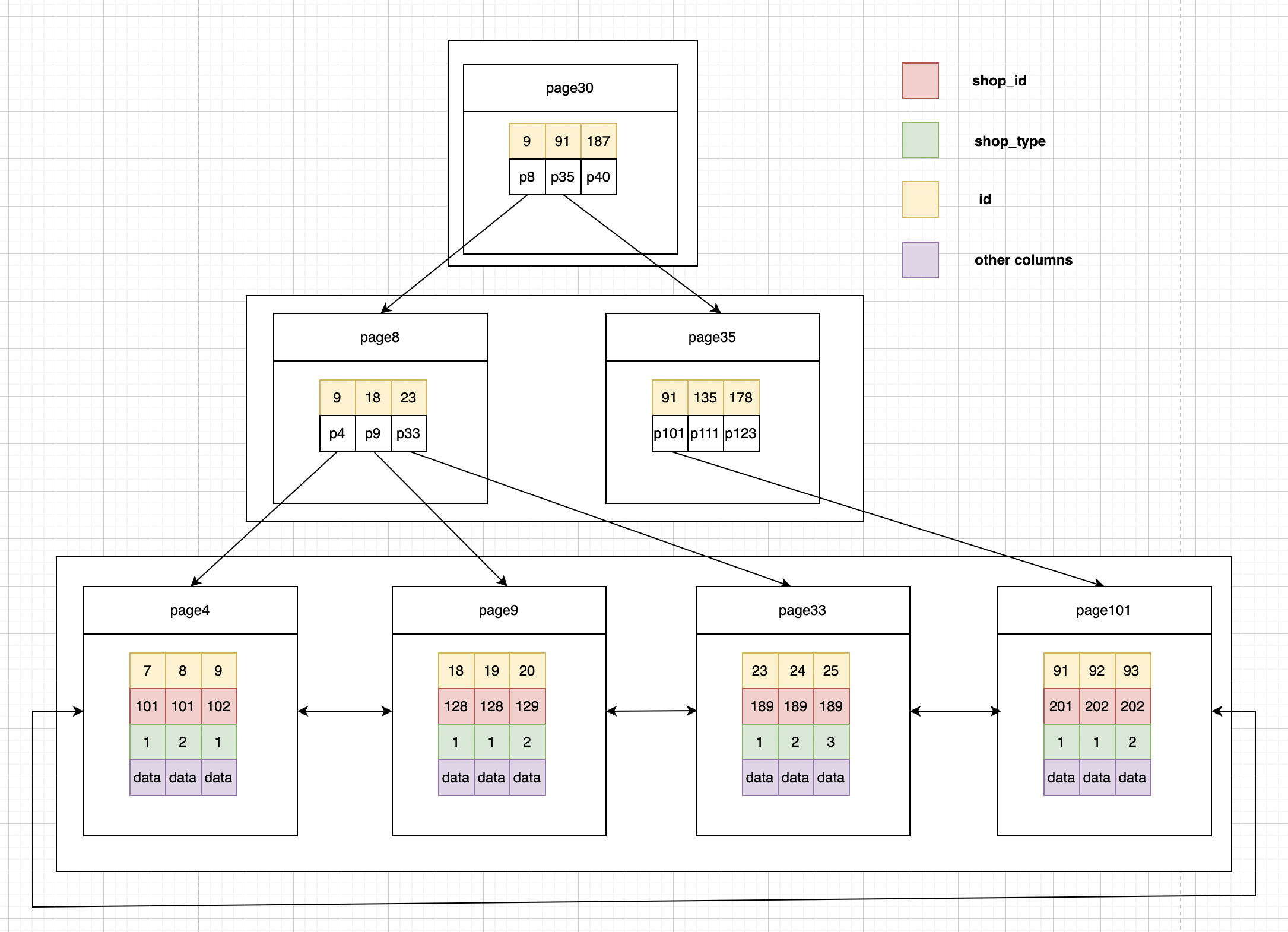
辅助索引
假设有一条查询语句
select * from shop_load_degrade_strategy where shop_id <102 and shop_type=1;
根据索引最左匹配原则,上面这个sql语句在查索引树的时候,只能用102,查到第一个满足条件的记录:id为7,8两条记录。
那接下来我们具体看一下 使用与未使用ICP的情况。
未使用ICP情况下:
1.存储引擎根据联合索引先找到shop_id<102 的主键id(7、8),再逐一进行回表扫描,去聚簇索引找到完整的行记录,再根据条件shop_type=1对拿到的数据进行筛,可以看到有两次回表。
使用ICP情况下:
1.存储引擎会根据(shop_id,shop_type)联合索引,找到shop_id <102,由于联合索引中包含shop_type
列,所以存储引擎直接再联合索引里按照条件shop_type=1进行过滤,就只会找到主键id(7),然后根据过滤后的数据再依次进行回表扫描。可以看到只有一次回表。通过sql执行计划可以看出 Extra的值为“Using index condition”表示使用了索引下推。
结语:
回表操作:当所要查找的字段不在非主键索引树上时,需要通过叶子节点的主键值去主键索引上获取对应的行数据,这个过程称为回表操作,可以看出Mysql通过索引下推来减少回表次数,从而提高sql性能。所以在项目开发编写sql语句的时候,要时刻注意是否可以通过减少回表或者不回表来优化sql性能,减少Mysql数据性能的压力。
参考文献:
https://dev.mysql.com/doc/refman/5.6/en/index-condition-pushdown-optimization.html
JetBrains 全家桶 2024 首个大版本更新 (2024.1) 老乡鸡“开源”了 微软都打算付钱了,为何还是被骂“白嫖”开源? 【已恢复】腾讯云后台崩了:大量服务报错、控制台登入后无数据 德国也要“自主可控”,州政府将 3 万台 PC 从 Windows 迁移到 Linux deepin-IDE 终于实现了自举! Visual Studio Code 1.88 发布 好家伙,腾讯真把 Switch 变成了「思维驰学习机」 RustDesk 远程桌面启动重构 Web 客户端 微信基于 SQLite 的开源终端数据库 WCDB 迎来重大升级