随着互联网的普及和发展,越来越多的数据可以通过网络获取。其中,天气数据是一种重要的数据资源,它涵盖了各个地区的气温、湿度、风力等信息。在Python中,我们可以利用网络爬虫技术来获取天气数据,并进行进一步的分析和应用。
天气数据分析在许多领域都有广泛的应用。例如,气象部门可以利用历史天气数据来预测未来的天气情况,帮助人们做出准确的决策;农业部门可以根据天气数据调整农作物的种植计划,提高产量和质量;旅游行业可以根据天气预报为游客提供更好的旅行建议等等。
使用Python进行天气数据分析具有许多优势。首先,Python具有丰富的网络爬虫库和数据处理库,使得数据获取和处理变得简单高效。其次,Python具有易于学习和使用的语法,使得初学者也能够快速上手。此外,Python还有庞大的开源社区和丰富的第三方库,可以提供各种功能和工具,满足不同需求的天气数据分析项目。
在本文中,我们将介绍如何使用Python进行天气数据爬取和分析。首先,我们将学习如何通过网络请求获取天气数据,并使用数据处理库对其进行清洗和整理。然后,我们将探索不同的数据分析方法,例如统计分析、可视化和机器学习等,以揭示天气数据中的模式和趋势。最后,我们将讨论如何将天气数据应用于实际问题,例如气象预测、农作物管理和城市规划等。
一、概述
-
项目背景 随着气候变化对人类生活的影响日益显著,准确的天气信息对个人和企业的决策和规划至关重要。2345天气网站作为一个权威的天气预报平台,提供了全面、实时的天气数据。在这样的背景下,我们希望基于2345天气网站的数据进行采集和分析,以满足以下需求: 天气数据采集:通过爬虫技术自动从2345天气网站获取各地区的天气数据。包括温度、湿度、风力、降雨量等多个指标的实时数据,以及未来几天的天气预报。这将为用户提供方便快捷的天气查询服务。 数据存储和管理:将采集到的天气数据进行结构化存储和管理,建立一个可靠的数据库。这将有助于数据的长期保存和后续的分析应用。 数据分析与可视化:对采集到的天气数据进行分析和挖掘,提取有价值的信息和模式。通过统计分析、趋势预测等方法,揭示不同地区天气变化的规律和趋势。同时,通过可视化手段,以图表、地图等形式展示分析结果,帮助用户更直观地理解天气数据。 决策支持与应用开发:基于天气数据的分析结果,为用户提供准确的天气预报和决策支持。例如,可以为旅行者提供天气建议,为农民提供农业生产指导,为城市管理者提供环境规划等。此外,还可以基于天气数据开发相关的应用程序和服务,满足用户对个性化天气信息的需求。 通过基于2345天气网站天气信息的采集与分析,我们将为用户提供全面、精准的天气数据和服务,帮助用户做出更明智的决策,同时推动气象科学的发展和应用。
-
项目目标
本项目旨在利用基于Python的网络爬虫技术对2345天气数据进行全面分析。我们将使用requests库来获取微博2345网站平台上最新和最热门的话题天气数据,并使用pandas库对数据进行处理和分析。通过结合matplotlib可视化技术进行分析,我们可以实现以下目标:
数据获取:使用Python编写网络爬虫程序,从天气网站或气象数据提供商的API中获取实时或历史天气数据。
数据清洗和整理:对获取的天气数据进行清洗、去除无效数据、处理缺失值等操作,以确保数据的准确性和一致性。
数据存储:将清洗后的天气数据存储到合适的数据结构中,例如数据库、CSV文件或Excel表格,以便后续分析和使用。
数据分析:利用Python的数据分析库(如Pandas、NumPy和Matplotlib)对天气数据进行统计分析、可视化和探索性数据分析(EDA),以揭示数据中的模式、趋势和关联性。
结果展示:将分析和预测结果可视化呈现,通过图表、报告或交互式界面向用户展示天气数据的洞察和应用价值。
该项目旨在利用Python的网络爬虫技术和数据分析工具,实现对天气数据的获取、清洗、分析和应用。通过这些步骤,可以为气象部门、农业、旅游等领域提供有关天气的准确信息和决策支持。
二、网络爬虫设计
-
网络爬虫原理 网络爬虫是一种自动化程序,用于从互联网上获取数据。其工作原理可以分为以下几个步骤: 定义起始点:网络爬虫首先需要定义一个或多个起始点(URL),从这些起始点开始抓取数据。 发送HTTP请求:爬虫使用HTTP协议向目标网站发送请求,获取网页内容。通常使用GET请求来获取页面的HTML代码。 获取网页内容:当网站接收到请求后,会返回相应的网页内容。爬虫将接收到的响应解析为字符串形式,以便进一步处理。 解析网页:爬虫使用解析库(如BeautifulSoup、lxml等)对网页进行解析,提取所需的数据。解析过程涉及HTML结构分析、XPath或CSS选择器的使用,以定位和提取目标数据。 处理数据:爬虫对提取的数据进行清洗、去除噪声、转换格式等处理操作,以确保数据的质量和一致性。 存储数据:根据需求,爬虫可以将处理后的数据存储到数据库、文本文件、Excel表格或其他数据存储介质中。 跟踪链接:爬虫会根据预设规则或算法,从当前页面中提取其他链接,并将这些链接加入待抓取队列。这样,爬虫可以深入遍历网站的各个页面。
-
网络爬虫的程序架构及整体执行流程
1、网络爬虫程序框架
基于Python的网络爬虫的天气数据分析项目,以下是网络爬虫程序框架:
导入所需的模块和库:导入了requests、csv和BeautifulSoup等库,以便进行HTTP请求、CSV文件操作和HTML解析。
设置请求头信息:定义了headers字典,包含了User-Agent信息,用于伪装浏览器发送请求。
定义城市列表和日期范围:给定了一个城市列表list1,其中每个元素包含了城市名称和对应的区域ID。同时,通过循环遍历1到12的范围,获取每个月的数据。
发送HTTP请求并解析响应:通过构建URL,发送HTTP GET请求获取天气数据的JSON响应。然后使用json()方法将响应内容解析为Python对象。
解析网页内容:使用BeautifulSoup库将响应内容转换为BeautifulSoup对象,以便提取数据。通过使用HTML标签和属性进行定位,使用find_all()方法获取每一行(tr标签)的数据。
提取数据并写入CSV文件:在每一行中,使用find_all('td')方法获取每列的数据,并提取日期、最高温度、最低温度、天气、风力风向和空气质量指数。然后将这些数据存储在列表list0中。
异常处理:使用try-except语句捕获可能出现的异常,并跳过处理。网络爬虫程序架构如图1所示。
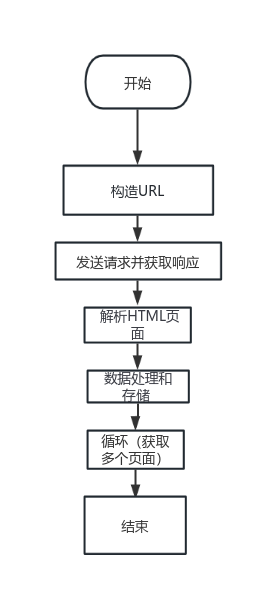
图1网络爬虫程序架构图
2、网络爬虫的整体流程
-
获取初始URL;
-
发送请求并获取响应;
-
解析HTML页面;
-
数据处理和存储;
-
分析是否满足停止条件,并进入下一个循环。
网络爬虫的整体流程图如图2所示。
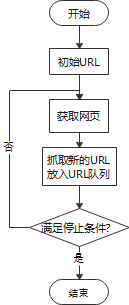
图2 网络爬虫的整体流程图
-
网络爬虫相关技术
-
数据爬取 使用requests库发送HTTP请求,并使用headers伪装浏览器标识。程序遍历城市列表和月份范围,构建URL并发送请求获取天气数据的JSON响应。然后,使用BeautifulSoup库解析响应内容,并使用HTML标签和属性定位数据。爬虫提取日期、最高温度、最低温度、天气、风力风向和空气质量指数等数据。最后,通过将数据写入CSV文件,实现数据的存储和持久化。这个爬虫程序使用了多个库和模块,通过编写合适的代码逻辑,实现了从目标网站上爬取天气数据的功能。
-
数据解析 数据解析部分使用了BeautifulSoup库对爬取到的网页内容进行解析。首先,将响应内容传递给BeautifulSoup构造函数,并指定解析器为'lxml'。然后,通过调用find_all()方法定位目标数据的HTML元素,使用索引和属性获取具体的数据值。在这个程序中,使用find_all('td')获取每一行的所有列数据,并通过索引提取日期、最高温度、最低温度、天气、风力风向和空气质量指数等信息。解析得到的数据存储在相应的变量中,然后可以进一步处理或写入CSV文件。通过使用BeautifulSoup库的强大功能,程序能够有效地从HTML页面中提取出所需的数据,并进行后续的处理和分析。
-
数据存储 文本文件:将数据以文本文件的形式进行存储,例如使用CSV(逗号分隔值)或JSON(JavaScript对象表示)格式。这种方法简单直接,适合存储结构化的数据。
-
反爬虫
User-Agent检测:网站可能会检查HTTP请求中的User-Agent字段,如果发现与普通浏览器的User-Agent不匹配,则可能被视为爬虫并拒绝访问。所以想要设User-Agent模拟浏览器。
请求频率限制:网站可以设置对于同一IP地址或同一用户的请求频率进行限制,如果超过限制,则可能被视为爬虫并暂时禁止访问。需要设置睡眠时间,降低采集频率。
-
需求分析 基于Python网络爬虫的天气数据分析具有以下需求分析: 数据获取:需要通过网络爬虫技术从天气网站或气象数据提供商的API中获取实时或历史天气数据。数据获取应该是自动化、高效和准确的,能够覆盖多个城市和时间范围。 数据清洗与整理:获取到的天气数据可能存在噪声、缺失值或格式不一致等问题。因此,需要进行数据清洗和整理,以确保数据的准确性和一致性。清洗过程应包括去除重复数据、处理缺失值、规范化单位等。 数据存储与管理:清洗后的天气数据需要进行合适的存储和管理。可以选择将数据存储为CSV文件或Excel表格。数据存储应考虑数据量的大小、查询和管理的方便性。 数据分析与可视化:利用Python的数据分析库(如Pandas、NumPy、Matplotlib、Seaborn等),对天气数据进行统计分析、可视化和探索性数据分析(EDA)。例如,绘制温度趋势图、空气质量分布图、风向雷达图等,以揭示数据中的模式、趋势和关联性。
-
网络爬虫系统设计 数据获取模块:使用Python的requests库发送HTTP请求,从天气网站或气象数据提供商的API中获取实时或历史天气数据。通过构建合适的URL和请求头信息,获取JSON格式的响应数据。 数据解析与清洗模块:使用BeautifulSoup或其他HTML解析库对获取到的网页内容进行解析。通过定位HTML元素和属性,提取所需的天气数据,如日期、温度、天气情况、风力风向等。对数据进行清洗,处理缺失值、去除重复数据等操作。 数据存储模块:将解析后的天气数据存储到合适的数据存储介质中,如关系型数据库(如MySQL、PostgreSQL)或非关系型数据库(如MongoDB)。根据需要,可以将数据保存为CSV文件或Excel表格。 数据分析与可视化模块:使用Python的数据分析库(如Pandas、NumPy)进行数据统计分析、图表绘制和探索性数据分析。通过绘制折线图、柱状图、箱线图等,展示温度变化、降雨分布等天气数据的趋势和特征。 根据以上设计思路和设计原则得出功能结构图。如图3所示。
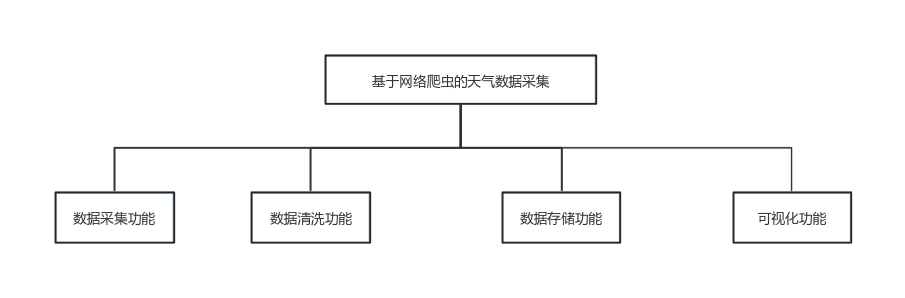
图3 功能结构图
-
分析工具 基于Python网络爬虫的天气数据分析工具有许多,以下是其中几个常用的工具: requests:requests是一个简洁而强大的HTTP请求库,可以用来发送HTTP请求并获取网页内容。 BeautifulSoup:BeautifulSoup是一个解析HTML和XML文档的Python库,可以方便地从网页中提取所需的信息。 csv:csv模块是Python标准库中的一个功能强大的模块,用于读写CSV文件,可以将爬取到的数据保存为CSV格式。 pandas:pandas是一个数据分析和处理库,可以方便地进行数据清洗、转换、分析和可视化等操作。 pyecharts:pyecharts是一个基于Echarts的数据可视化库,可以用来生成各种图表,包括折线图、柱状图、雷达图、饼图等,用于展示和分析数据。 matplotlib:matplotlib是一个绘图库,可以用来生成各种静态、动态、交互式的图表和图形,适用于数据可视化和分析。 seaborn:seaborn是一个基于matplotlib的统计数据可视化库,提供了更高级的接口和样式,使得数据可视化更加简单和美观。
-
爬取过程
1、网页数据的爬取
通过使用requests库发送HTTP请求,结合BeautifulSoup库解析HTML数据,实现了从2345天气网站采集指定城市和月份的天气信息,并将数据存储在CSV文件中。首先,通过导入所需的requests、BeautifulSoup和csv模块,以及定义列名和文件路径等相关信息。
接下来,使用open()函数创建一个CSV文件,并将列名写入该文件。然后,定义一个城市ID列表list1,循环遍历列表中的每个城市ID。
在城市ID循环的内部,再次进行循环以获取每个月份的数据。根据城市ID和月份构建URL,发送GET请求获取对应月份的天气数据。通过设置请求头部信息模拟浏览器访问,包括Accept、Accept-Encoding、User-Agent等。
通过解析返回的JSON数据,提取出天气信息所在的HTML代码段。然后使用BeautifulSoup库解析HTML代码,查找所有<tr>标签,表示每一行的天气数据。
在每一行的循环内部,通过查找<td>标签提取日期、最高温度、最低温度、天气状况和风力风向等信息。将这些信息添加到一个列表list0中。
接着,打开CSV文件,并以追加模式将list0写入CSV文件中,每次追加一行数据。
最后,在异常处理中使用pass语句跳过无效的数据行。关闭文件操作。数据采集结果大概11万条,最后抓取数据代码运行结果如图4所示。

图4 网页数据爬取结果图
2、数据的处理
从2345天气网站上获取的天气数据可能存在一些噪声、冗余或格式不规范的问题,需要进行数据清洗和处理。
使用Python中的数据处理和清洗工具(如Pandas、NumPy等),对采集到的天气数据进行去重、缺失值处理、格式转换等操作。
对异常数据进行处理,如剔除错误的温度值、修正日期格式等,确保数据的准确性和一致性。
-
日期处理
导入所需的库:导入pandas和pyecharts库,并给它们取别名pd和pyecharts。
读取天气数据:使用pd.read_csv()函数读取包含日期和温度字段的天气数据文件,并将其存储在DataFrame中。
数据预处理:对日期字段进行适当的处理,以确保能够正确地解析日期信息。同时,对温度字段进行必要的类型转换,以便后续的数值计算和可视化。
统计不同时间段内的平均温度:根据日期字段,将数据按照不同的时间段(例如每天、每周、每月等)进行分组,并计算每个时间段内的平均温度。代码如下所示。

(2)对数据进行转换
数据预处理:对温度字段进行适当的处理,包括去除单位符号并转换为数值类型。同时,对空气质量指数字段进行处理,拆分空气质量程度和具体指数,并转换为数值类型。
分组统计最高温度、最低温度和空气质量指数:根据空气质量程度和城市分组,计算每个组的最高温度和最低温度。代码如下所示。

(3)数据进行筛选
对天气字段进行处理,例如筛选出包含特定关键词(如'小雨'、'中雨'、'大雨'、'暴雨'、'雨夹雪')的行数据。
统计雨天频率和平均温度:利用Counter库的Counter函数统计每个关键词在数据中出现的频率。同时,计算这些雨天关键词对应的平均温度。这样的分析帮助用户了解不同雨天类型的频率以及与之相关的平均温度。
三、数据可视化和分析
(一)、数据可视化
Matplotlib是一个常用的Python数据可视化库,它提供了丰富的绘图工具和函数,可以帮助我们将数据以图形的形式展示出来。通过Matplotlib,我们可以创建各种类型的图表,包括线型图、散点图、柱状图、饼图等,以及二维和三维的图形。
Matplotlib的优势在于其简单易用的接口和强大的功能。它可以与Python的其他科学计算库(如NumPy和Pandas)无缝集成,使得数据的处理和可视化变得更加高效。此外,Matplotlib还提供了丰富的自定义选项,使得我们可以根据需求调整图表的样式、颜色、标签、标题等,从而使得图表更加美观和易读。
使用Matplotlib进行数据可视化的基本步骤通常包括导入Matplotlib库、准备数据、创建图表对象、添加数据和标签、设置图表样式和属性,最后展示图表。Matplotlib支持多种输出格式,可以将图表保存为图片文件或者嵌入到交互式的应用程序中。
除了基本的静态图表绘制,Matplotlib还支持动画和交互式可视化。我们可以利用Matplotlib的动画功能创建动态的图表,以展示数据随时间变化的趋势;而通过与其他库(如Seaborn和Plotly)结合使用,我们可以实现更加交互式的数据可视化,例如鼠标悬停、缩放、拖动等操作。
1、天气变化趋势分析
天气变化趋势分析用折线图展示,代码如下:

根据提供的天气变化趋势分析结果,可以得出以下解读:
温度变化趋势:从数据中可以看出,温度的变化是不断波动的。整体上,温度呈现出一定的季节性变化,夏季温度较高,冬季温度较低。然而,在同一个季节内,仍然存在较大的日常波动。
最高温度:数据中最高温度出现在夏季,最高可达37℃。这可能是炎热的天气,需要注意防暑降温。
最低温度:数据中最低温度出现在冬季,最低可达-1℃。这可能是非常寒冷的天气,需要注意保暖措施。
季节过渡:从数据中可以看到,在季节过渡期间(如春季和秋季),温度的变化较为频繁,有时会出现明显的冷热交替。
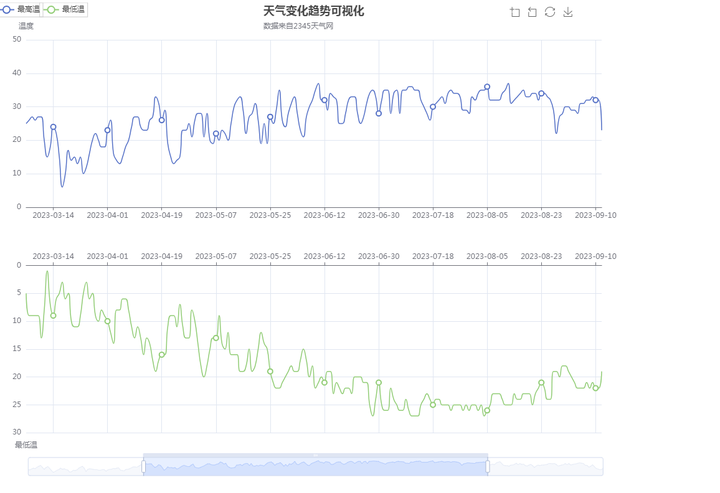
添加图片注释,不超过 140 字(可选)
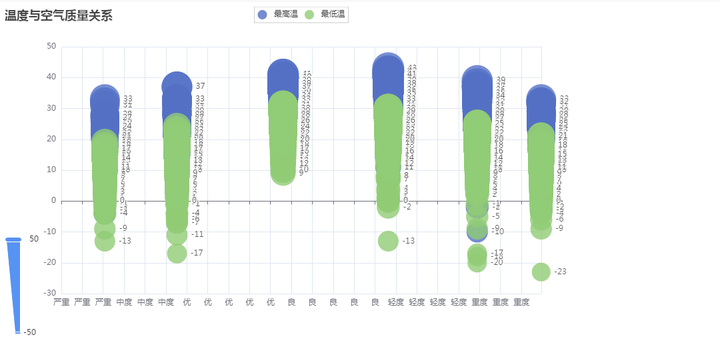
2、温度与空气质量关系
温度与空气质量关系用散点图展示,代码如下:

严重污染:从数据中可以看出,在最高温度较高、最低温度较低的城市,空气质量普遍被划定为严重污染级别。这可能是由于高温天气导致空气污染物浓度上升,以及低温天气下不利于空气污染物扩散。
重度污染:部分城市在最高温度和最低温度方面表现较为一般,但仍然被划定为重度污染级别。这可能是由于其他因素(如工业排放、交通污染等)对空气质量造成了影响。
需要注意的是,以上解读是基于温度与空气质量之间的一般关系进行的推测,并不代表所有情况都适用。实际的空气质量程度受多种因素综合影响,包括但不限于温度、湿度、气象条件、污染源等。因此,更准确的空气质量评估需要综合考虑各种因素,并进行专业监测和分析。
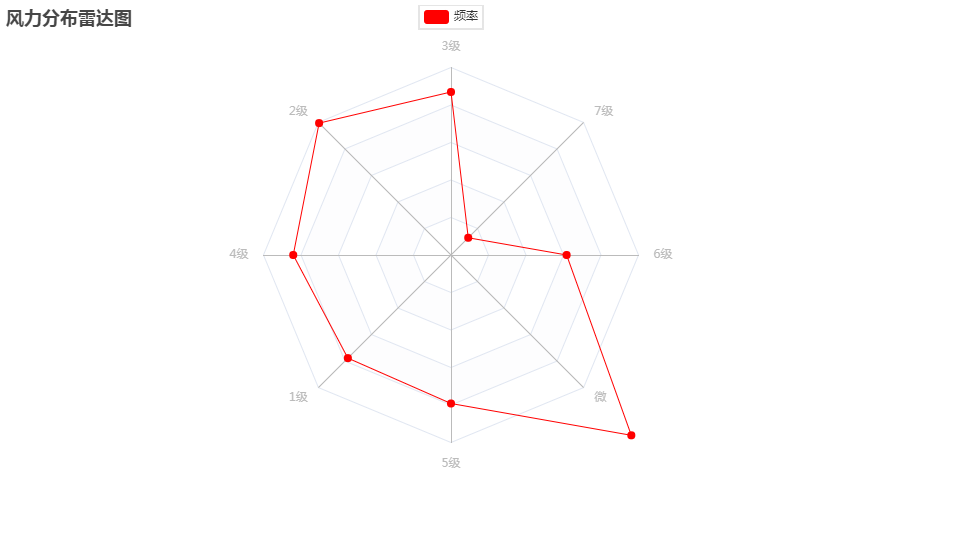
3、风力分析
风力分析用雷达图展示,主要代码如下:

1级风力:数据中出现最频繁的是1级风力,数量为31,113次。1级风力通常被定义为轻微的微风,这意味着风力较小,不会对人们的活动产生明显影响。
2级风力:其次是2级风力,数量为39,792次。2级风力被定义为轻风,比1级风力稍强,但仍然是相对较弱的风力。
3级风力:紧随其后的是3级风力,数量为26,083次。3级风力被定义为轻劲风,比2级风力略强,可能会对树木、草地等造成一定影响。
4级风力:数据中显示4级风力的数量为8,414次。4级风力被定义为劲风,具有一定的强度,可能会对户外活动和建筑物带来一定影响。
5级风力:数据中显示5级风力的数量为1,584次。5级风力被定义为强风,风力较大,可能会引起树木摇摆、海浪波动等现象。
6级风力:数据中显示6级风力的数量为185次。6级风力被定义为疾风,风力较强,可能会对人们的活动和建筑物造成较大影响。
7级风力:数据中显示7级风力的数量为13次。7级风力被定义为大风,具有很高的风力强度,可能会对人们的出行和建筑物安全带来较大威胁。
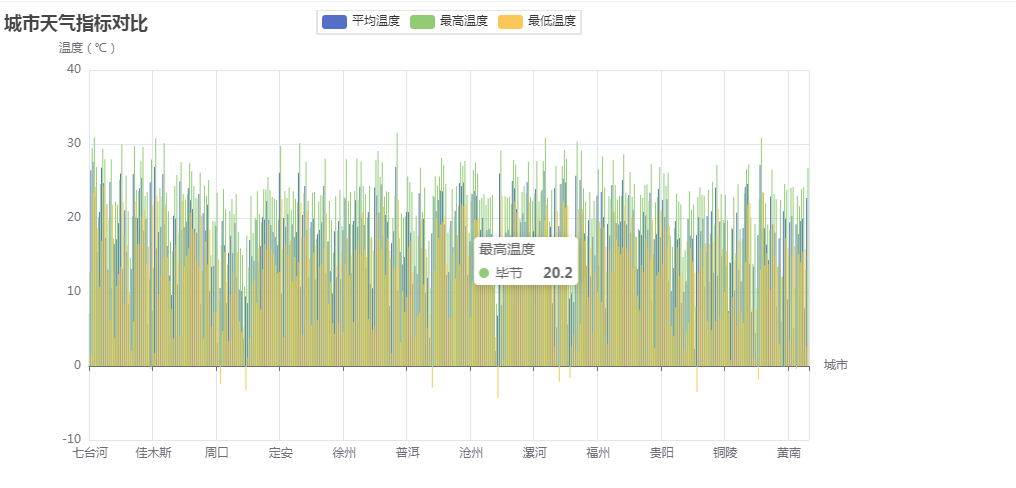
4、城市天气指标对比
城市天气指标对比用柱形图展示,主要代码如下:

最高温度对比:从最高温度数据来看,不同城市的最高温度存在较大差异。例如,七台河的最高温度为12.6℃,而三亚和万宁的最高温度分别达到了30.9℃和29.4℃。这显示了不同城市在气候上的显著差异。
最低温度对比:在最低温度方面,城市之间的差异也很明显。例如,三亚的最低温度为24.2℃,而齐齐哈尔的最低温度仅为2.5℃。这反映了不同地区的气候条件和季节变化。
平均气温对比:通过比较不同城市的平均气温,可以进一步了解其整体气候状况。例如,龙岩的平均气温为22.7℃,相对较高,而七台河的平均气温为7.1℃,则较为寒冷。
5、雨天分析
雨天分析用柱形图展示,主要代码如下:

小雨:小雨频率最高,达到了22281次。小雨天气一般降水量较小,可能会对户外活动带来一定影响。在小雨天气下,最高温度为22.1℃,最低温度为15.6℃,平均温度为18.8℃。
中雨:中雨频率为6673次。中雨相对于小雨而言,降水量较大,可能会给人们的出行和活动带来一定困扰。中雨天气下,最高温度为24.2℃,最低温度为18.3℃,平均温度为21.2℃。
大雨:大雨频率为2603次。大雨天气下,降水量更大,可能导致街道积水和交通不便。在大雨天气中,最高温度为26.4℃,最低温度为20.7℃,平均温度为23.6℃。
暴雨:暴雨频率为1139次。暴雨是一种极端的降水天气,降水量非常大,可能引发洪涝和山体滑坡等灾害。在暴雨天气下,最高温度为26.9℃,最低温度为21.8℃,平均温度为24.4℃。
雨夹雪:雨夹雪频率为685次。雨夹雪是指同时降下雨水和雪花的天气现象,常见于气温较低的时候。雨夹雪天气下,最高温度为7.2℃,最低温度为-0.4℃,平均温度为3.4℃。

6、天气类型分析
天气类型分析用玫瑰图展示,主要代码如下:

多云:多云天气出现频率最高,达到了63075次。多云天气指天空中云量较多,但没有明显的降水。
阴:阴天出现次数为32301次。阴天指天空被云层覆盖,光线相对较暗,但并没有明显的降水。
晴:晴天出现次数为34882次。晴天指天空基本没有云层,阳光明媚。
小雨:小雨出现次数为22281次。小雨是一种降水量较小的雨,可能会对人们的活动带来一定影响。
中雨:中雨出现次数为6673次。中雨是一种降水量较大的雨,可能会给人们的出行和活动带来困扰。
大雨:大雨出现次数为2603次。大雨是一种降水量更大的雨,可能会导致街道积水和交通不便。
雨夹雪、小雪、暴雨、雾等其他天气类型也有出现,每种天气类型的次数各不相同。

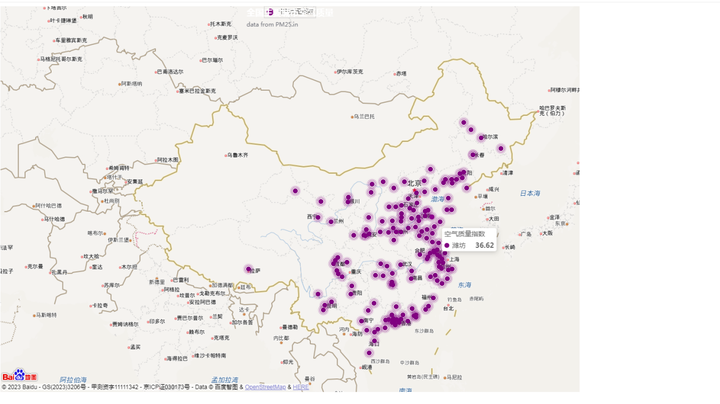
7、全国主要城市空气质量分析
全国主要城市空气质量分析用百度地图展示,主要代码如下:

空气质量指数对比:不同城市的空气质量指数存在较大差异。例如,七台河的空气质量指数为51.2,而三门峡的空气质量指数为71.5。这显示了不同城市之间空气质量的差异。
空气质量状况评估:根据中国环境保护部发布的标准,空气质量指数在0-50之间被认为是优良的,51-100之间为良好,101-150之间为轻度污染,151-200之间为中度污染,201-300之间为重度污染,超过300为严重污染。根据给出的数据,可以看出绝大多数城市的空气质量指数在良好或者轻度污染范围内。
四、结论
4.1 结论
天气变化趋势:通过对长期天气数据的分析,我们可以观察到季节性的天气变化趋势。在不同季节,温度、降水量和风力等因素会有相应的变化。
高温天气:夏季部分地区存在高温天气,最高温度可达30℃以上。这种高温天气可能对人们的健康和生活带来一定影响,需要注意防暑降温措施。
降雨情况:根据降雨量数据,我们可以了解到各地的降雨情况。在雨季或梅雨季节,可能会出现较多的降雨天气。此时,需要关注城市排水系统的状况,以及出行安全。
风力情况:风力是一个重要的天气指标,可以影响户外活动和航海等。根据风力数据,我们可以了解到不同城市的风力情况,并根据需求合理安排活动。
4.2建议
关注天气预报:通过关注天气预报,可以提前了解未来几天的天气情况,从而合理安排出行和活动。尤其是在高温、降雨等特殊天气条件下,及时掌握天气信息对人们的生活和工作很重要。
注意防护措施:根据不同的天气情况,采取相应的防护措施。在高温天气中,要注意做好防暑降温工作,保持适当的室内温度,避免中暑。在降雨天气中,要关注城市排水系统是否畅通,避免出现积水导致的交通问题。
调整活动计划:根据天气情况,适当调整户外活动计划。在高温天气中,可以选择避免强烈阳光暴晒的时间段进行户外活动,或者选择室内活动。在降雨天气中,可以选择室内活动,或者带上雨具做好防雨准备。
关注空气质量:除了天气情况,关注空气质量也是重要的。根据空气质量指数,了解当地的空气质量状况,并根据需要采取相应的防护措施,如佩戴口罩、减少户外活动等。
参考文献
[1] [1]陈海燕,朱庆华,常莹.基于Python的网页信息爬取技术研究[J].电脑知识与技术:学术版,2021,17(8):195-196.
[2]钟机灵.基于Python网络爬虫技术的数据采集系统研究[J].信息通信,2020(4):96-98.
[3]单艳,张帆.基于Python的网页信息爬取技术研究[J].电子技术与软件工程,2021(14):238-239.
[4]冯艳茹.基于Python的网络爬虫系统的设计与实现[J].电脑与信息技术,2021,29(6):47-50.
[5]孙梦薇,姚渝琪.关于Python爬虫在网页信息统计中的应用探讨[J].电子世界,2020(9):60-61.
[6]罗春.基于网络爬虫技术的大数据采集系统设计[J].现代电子技术,2021,44(16):115-119.
[7]钱贝贝,陈志波.基于Python爬虫的音乐数据可视化分析[J].电脑知识与技术:学术版,2022,18(8):6-8.
[8]刘恒利,揭圣,詹懿.基于ECharts对食药物质毒性六方位图谱[J].信息技术与信息化,2022(12):39-42.