

为了应对用户规模的增加和交易活动的激增,淘宝购物车近年来进行了一系列技术升级,其中主要集中在扩容与性能优化上。本文将简要介绍这些改进措施,以及它们如何提升购物车的响应速度和用户体验,以实现“又快!又丝滑!”的购物体验。主要包括:
淘宝购物车扩容分析与解决方案
网络包大小与服务端并行化分析与方案

扩容的背景
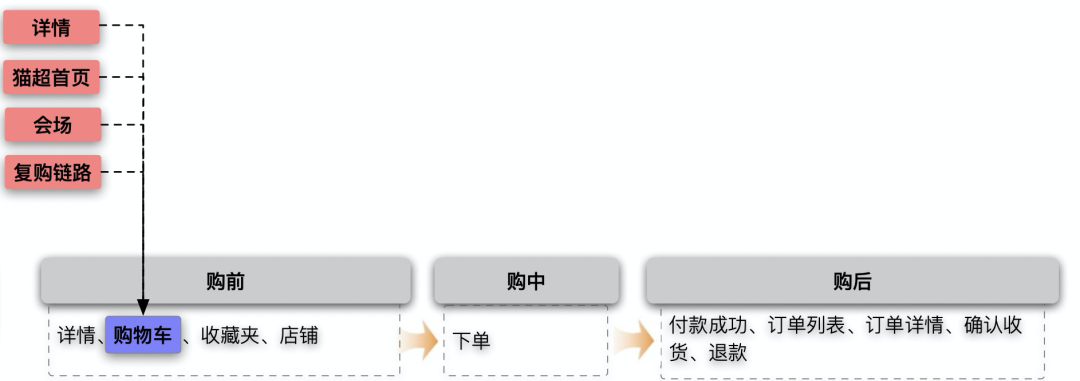
首先讲一讲购物车的职责。购物车承载着购前环节中促成购买的职责:对于下单犹豫的用户,用营销等手段提升用户决策效率,对于转化确定性较高的用户,精准的推荐让他买的更多;在购中环节提供流畅的交易体验:优惠计算的准确性和过程的清晰度以及各种业务形态商品的凑单合并结算等。作为在购前链路中直面消费者的重要节点,购物车里的体验问题就显得十分重要且敏感。
分析往年的用户原声可以发现,用户对于扩容有强烈诉求。
So 购物车大刀阔斧般的升级可以说是刻不容缓!


扩容的挑战与解法
▐ 扩容的挑战
数据库的挑战
存储瓶颈与相关影响
扩容首先带来的就是存储容量的上涨,按扩容到300的预期估算,存储量上涨就大约达到了2倍,在物理机资源有限的情况下存储量的上涨会同时到来BP缓存率的下降,这样就导致其他用户的数据只能去物理磁盘读取,磁盘IO会成为巨大的瓶颈,进而导致数据库各个操作的RT飙升。
扩容后由于 BP 命中率下降,冷数据访问导致大量读盘,数据库磁盘 IO 会成为巨大瓶颈。
实时计算量放大对交易全链路的挑战
现有架构的特点:「分页商品实时计算」
但是遇到类似 跨店满减筛选、降价筛选、消费券筛选等强依赖实时计算结果的产品设计,需要针对用户加购品做全量计算并一次性下发给客户端。
购物车筛选的实现
大促跨店满减报名是类目+商家纬度,营销规则又包含了部分类目黑标的逻辑。 但是购物车跨店满减筛选是商品纬度的判断。所以这里有一个从类目+商家到商品纬度的打平计算的过程。

为了判断商品是否报名了跨店满减,需要调用 营销 进行实时计算。
用户纬度的所有加购品经过 营销 计算后,购物车才能筛选出哪些参与了跨店满减。
下发客户端数据体积过大,导致用户体验变差
下发300+个品的数据包预计约为1M左右,在弱网环境下,按 100KB/s计算,需要的传输时间是10s 左右。
购物车已经采用了分页实时计算方案,提高用户秒开体验
由于筛选涉及全量下发,扩容会放大对交易链路的计算量且增加购物车本身的性能压力,从而导致用户体验的降低。
▐ 扩容的解法
引入 tairsql 提升购物车读性能
以双十一峰值的购物车监控为例,在峰值期间有明显的脉冲流量,且主要流量集中在查询与勾选这两种依赖读db的操作类型,而涉及写db的流量(加购,删除,更新等)明显偏少。
查询购物车的SQL逻辑基本属于简单语句,SQL这种的查询条件主要是用户id、加购状态等。并且购物车数据是按照用户纬度聚合,单次请求返回的数据体积不会太大。
所以我们总结出购物车的流量特点为:
典型的读多写少, sql返回数据不会太大
有瞬时脉冲
对RT敏感

读写分离

引入tairsql后,峰值期间的读流量全部走tairsql,写流量仍然会对db与taisql执行双写,同时有数据同步任务(精卫任务)做同步兜底。
使用tairsql与db做读写分离
采用双写+精卫方案保证数据同步
预计算
预计算链路图示:


网络传输优化:
压缩数据:使用如Gzip这样的数据压缩技术或结合业务逻辑做裁剪减少传输数据的大小。
缓存策略:合理设置缓存策略,减少不必要的网络请求和包大小。
延迟加载:对于购物车非关键资源进行延迟加载,优先加载对用户体验影响最大的内容。
服务端耗时优化:
缓存机制:使用内存缓存如tair等,对频繁访问的数据进行缓存,减少网络传输压力。
并发处理:优化代码,使用异步处理和多线程技术,提高服务端的并发处理能力。
代码优化:精简代码逻辑,移除不必要的中间件和服务

▐ 包大小对网络rt影响分析
在当今的网络环境中,上下行带宽往往是不对称的,这种不一致性在移动网络中也很常见,网络运营商为了更有效地利用有限的无线频谱资源,往往会分配更多的带宽给下行链路,以提供更好的媒体消费体验。考虑到这种上下行带宽的不一致性,上行包的优化往往比下行包的优化收益更大。因为下行通常有更多的可用带宽,即使存在一些性能瓶颈,用户也可能不会立即感受到明显的性能下降。而上行链路由于其固有的带宽限制,任何性能的微小提升都能给用户带来明显的体验改善。优化上行数据包,例如通过减少发送的数据量、实现数据包的压缩、优化传输协议以及应用智能队列管理,能够有效降低延迟、提高上传速度,从而在带宽受限的情况下尽量减少阻塞和等待时间。
▐ 购物车状态协议缓存
状态协议数据同时存在于上行与下行协议中,且客户端不依赖。
为了达到和客户端解耦的效果,最直观的方法就是将这份数据存到缓存中。然而在结合交易流量和现有计算资源做一个简单估算后,我们发现事情并没有那么简单。结合淘宝购物车的峰值流量来测算,整体产生的带宽量级会达到数十GB,在当前的规格资源下根本不够用。
压缩与缓存
-
Base64编码原理:Base64编码将每组3个字节(共24位)的原始数据划分为4个单元,每个单元6位。由于每6位只能表示64种状态(2^6 = 64),Base64编码选择了一个64字符的集合来表示这些状态。这个字符集通常包括大写和小写英文字母(A-Z, a-z)、数字(0-9)、加号(+)和斜杠(/)。实际编码时,Base64处理器会查找这个字符集,将每个6位的值映射为相应的字符。 -
数据膨胀:考虑到大多数字符编码(如ASCII,UTF-8)中,一个字符通常占用8位(1字节)。在Base64编码中,每4个字符用来表示原始数据的3个字节。这意味着每个原始字节在编码后占用了8 * 4 / 3 = 10.666...位。换言之,原始数据的大小会增加大约1/3(33%)。
▐ 流式Api
流式api介绍
-
request streaming: 多个上行对应一个下行; -
response streaming: 一个上行对应多个下行; -
bidirectional streaming: 端云双向流式服务;

引入流式后
通过流式api的引入,下行包拆成了主包与副包,状态协议在副包中,其余数据保留在主包。客户端在收到主包后即可执行渲染逻辑,等效于状态数据在网络传输中的耗时,不再影响用户端到端体验耗时。

▐ 接口耗时分析
商品数据较少时:服务端优化点在于下发数据量,在网络包优化中已经得到了解决
商品数据较大时:服务端优化点在于降低耗时
▐ 并行化改造
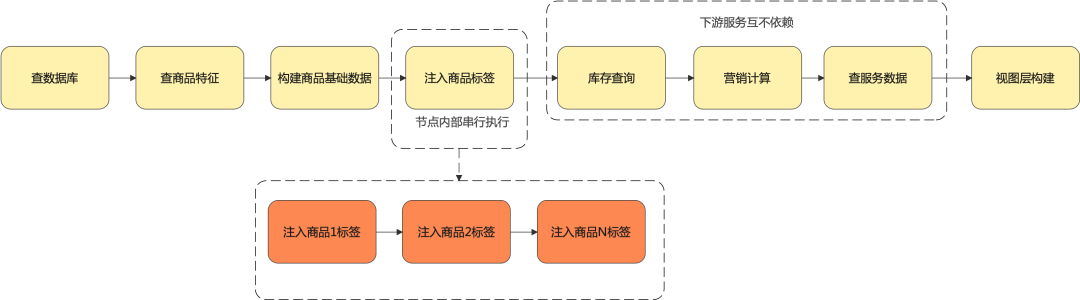
结合业务回头来看整个流程,会发现全串行流程中低效的点:
部分节点之间并没有严格的顺序关系,例如查服务数据在注入商品标签后即可执行,且服务数据当前只在视图层构建有用。
互不依赖的下游服务例如库存查询、营销计算、查服务数据是低效的串行查询。
购物车平均商品数过大的特点,导致和商品数相关的节点内部做foreach循环非常低效,典型的有例如注入商品标签、视图层构建。
找到问题后,我们最终采用基于ForkJoinPool的方式实现购物车并行化改造:
这种面向多子任务且支持并行化的方式,就非常适用于购物车场景中的多商品处理,例如:
并行处理多商品任务:购物车的一大特点就是平均商品数多,每个商品标签注入、单个视图分组构建等操作都可以作为一个子任务独立执行。
任务可拆分性:购物车中的每个商品处理逻辑都是独立的,这使得任务可以很方便地被拆分成小任务并行执行。
提高响应性能:使用 ForkJoinPool 可以在多核处理器上同时执行多个商品的处理任务,从而减少总体的处理时间,提高系统的响应速度。
动态任务调度:"工作窃取"算法能够在运行时动态地重新平衡任务负载,如果某些商品的处理耗时较长,ForkJoinPool 能够确保其他线程不会闲置,而是帮助处理剩余的工作。
结合ForkJoinPool的方式做并行优化后的购物车流程简化图如下:
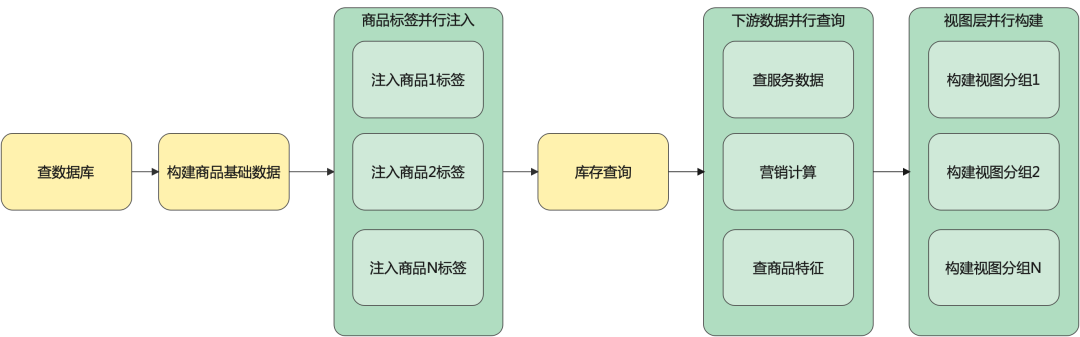
注入商品标签和视图层构建,从商品维度拆分子任务,使用并行化。
将部分仅视图层且互不依赖的下游数据节点做聚合,内部做并行查询。

团队介绍
看到这里相信诸位能够感受到购物车技术体系的复杂度和深度,笔者所在的团队是淘天集团交易前链路技术团队(购物车&下单),在这里,你能够不断被各种商业模式烧脑,也能够不断被各种新兴技术锤炼,更能收获一群志同道合的战友。值此变革关键时期,也急需有能力和有梦想的你一起参与:
1. 负责淘宝购物车、下单等面向全民用户的C端产品演进和迭代,每一次需求每一行代码都能创造巨大的商业价值。
2. 支撑集团16N组织下形态各异电商的购物车、下单平台应用的维护(buy2 carts2),在这里见证如何针对形态各异的电商进行架构抽象出电商内核,并通过高度灵活的开放扩展机制解决业务的差异性。
3. 操刀完整的端到端协议的设计、演进和优化(奥创),见证移动时代在客户端不发版的情况下,如何既能高效满足产品需求迭代,又能获得native一样优异的消费者体验。
4. 全程保障每一次大促流量洪峰背后的业务安全和稳定性,全力促成持续的平台架构演进,确保用户每一次购物车浏览,每一次下单能够丝滑顺畅。
本文分享自微信公众号 - 大淘宝技术(AlibabaMTT)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。