文章目录
模块 < 包 < 库
模块
以py为后缀的文件,其中定义了一些常量和函数,模块名称即为py文件的名称。
import 模块
包
模块的结构化管理,将众多具有相关功能的模块文件组合成包。包文件有_init_.py和模块文件组成,用init文件识别是否为包文件
import 包.模块
库
具有某些功能的模块和包都可以被称作为库。
math
提供对浮点数的数学运算函数,math 模块下的函数返回值均为浮点数
import math
dir(math)
# 包含54个常量/方法
random
| 函数 | 描述 |
|---|---|
| choice(seq) | 从序列的元素中随机挑选一个元素,比如random.choice(range(10)),从0到9中随机挑选一个整数 |
| randrange ([start,] stop [,step]) | 从指定范围内,按指定基数递增的集合中获取一个随机数,基数默认值为 1 |
| random() | 随机生成下一个实数,它在[0,1)范围内 |
| seed([x]) | 改变随机数生成器的种子seed |
| shuffle(lst) | 将序列的所有元素随机排序 |
| uniform(x, y) | 随机生成下一个实数,它在[x,y]范围内 |
urllib
urllib库用于操作网页URL,并对网页的内容进行抓取和处理
模块
request
打开和读取URL
urlopen方法
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
- url,网页地址
- data,发送到服务器的其他数据对象,默认为none
- timeout,设置访问超时时间
- cafile、capath,前者为CA证书,后者为CA证书的路径,使用HTTPS需要用到
- casefault,已被弃用
- context,ssl.SSLContext类型,用来指定SSL设置
网页内容读取
read(),读取整个网页内容,可以指定读取长度
readline(),读取文件的一行内容
readlines(),读取文件的全部内容,把读取的内容赋值给一个列表变量
from urllib.request import urlopen
url = urlopen("http://c.biancheng.net/view/2397.html")
print(url.read(100))
print(url.readline())
lines = url.readlines()
for line in lines:
print(line)
网页状态码
getcode(),获取网页状态码
网页保存本地
from urllib.request import urlopen
myURL = urlopen("https://www.runoob.com/")
f = open("runoob_urllib_test.html", "wb")
content = myURL.read() # 读取网页内容
f.write(content)
f.close()
本地生成runoob_urllib_test.htm文件,包含网页所有内容
file处理,https://www.runoob.com/python3/python3-file-methods.html
编码解码
quote(),编码
unquote(),解码
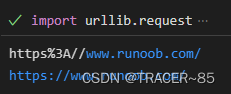
import urllib.request
encode_url = urllib.request.quote("https://www.runoob.com/") # 编码
print(encode_url)
unencode_url = urllib.request.unquote(encode_url) # 解码
print(unencode_url)
字符串编码顺序:gbk、unicode、utf16、url解码
字符串解码顺序:url解码、utf16、unicode、gbk
error
包含urllib.request抛出的异常
parse
解析URL
robotparser
解析robots.txt文件