在云服务器ECS上用Python写一个搜索引擎
一、场景介绍
一台阿里云ECS云服务器就是一台带有公网IP地址的计算机。用户可以通过远程登录使用这台计算机;同时,由于带有公网IP,用户在ECS云服务器上部署的网站、APP、小程序等,可以被其他人通过互联网访问。
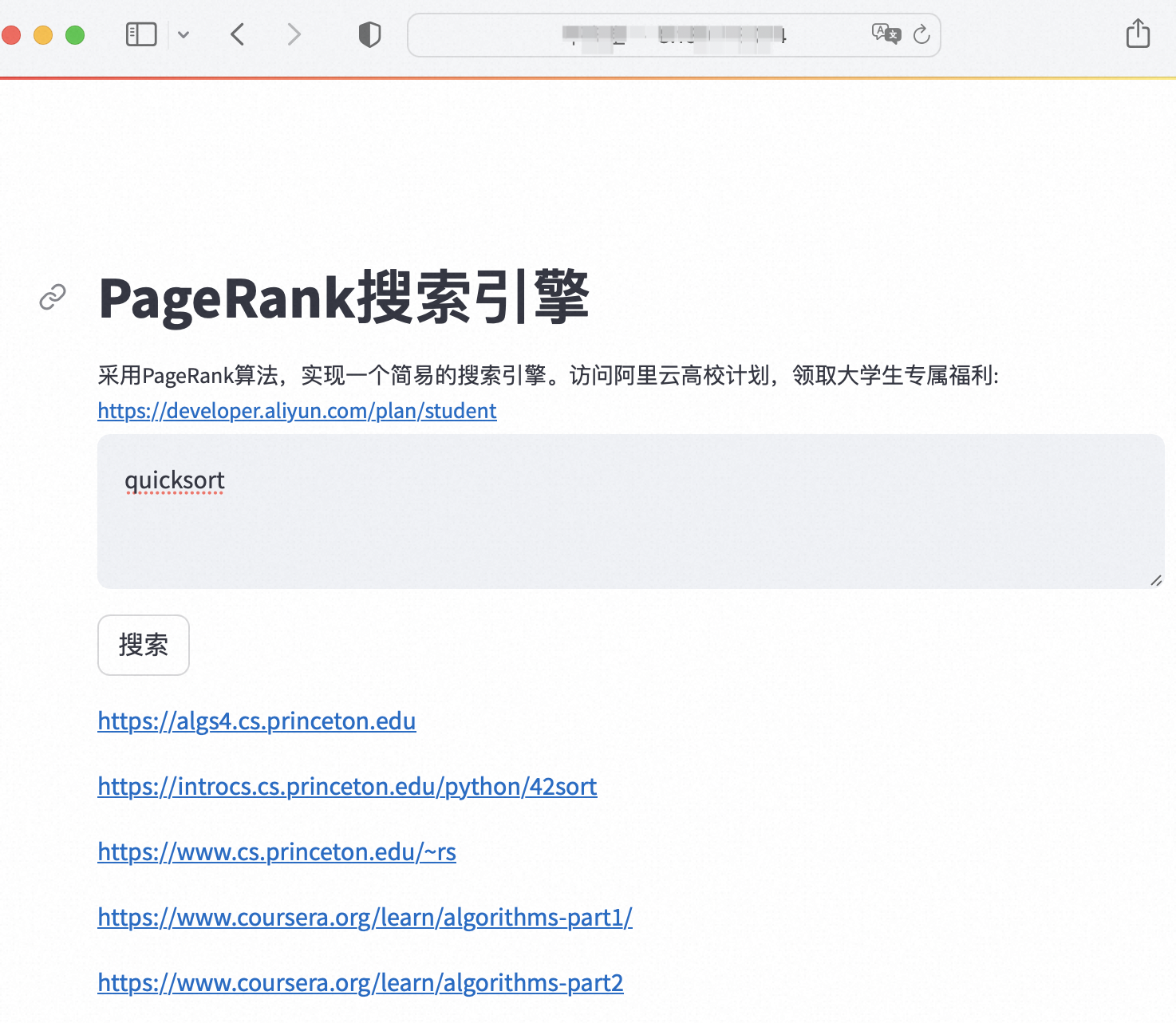
本实验应用PageRank算法,使用Python,在一台ECS云服务器上搭建了一个简易版的搜索引擎。可以用单个英文词语作为搜索词,搜索相关的网页。实现的效果如下图所示。在搜索框中,输入搜索词,例如"universe",单击搜索,搜索引擎即会按相关度从高到低,列出相关的网页。
二、搜索引擎的组成
本案例中的搜索引擎由两部分组成:网页的爬取及排序,以及用户使用搜索引擎进行搜索。
2.1 网页的爬取及排序
首先,搜索引擎需要从互联网上爬取网页。爬取到网页后,做两方面的工作:
-
获取网页间的超链接关系,使用PageRank算法对网页进行排序。PageRank算法的基本原理是,被引用越多的网页(即获取的超链接越多),重要性越高,类似于被引用次数越多的学术论文重要性越高的原理。对算法的说明可参考下面这本书:Google’s PageRank and Beyond: The Science of Search Engine Rankings。
-
编制搜索词的索引。从网页中提取词语,分析这些词语出现在哪些网页。
2.2 用户使用搜索引擎进行搜索
用户搜索某个词(例如 computer)时,搜索引擎首先从搜索词的索引中,找到这个词出现在哪些网页。然后,获取这些网页的PageRank值,按照值的大小,由高至低排序,呈现给用户。
本案例中,数据存储做了简化处理,采用了txt文档存储数据,没有使用数据库。Web页面采用Streamlit生成。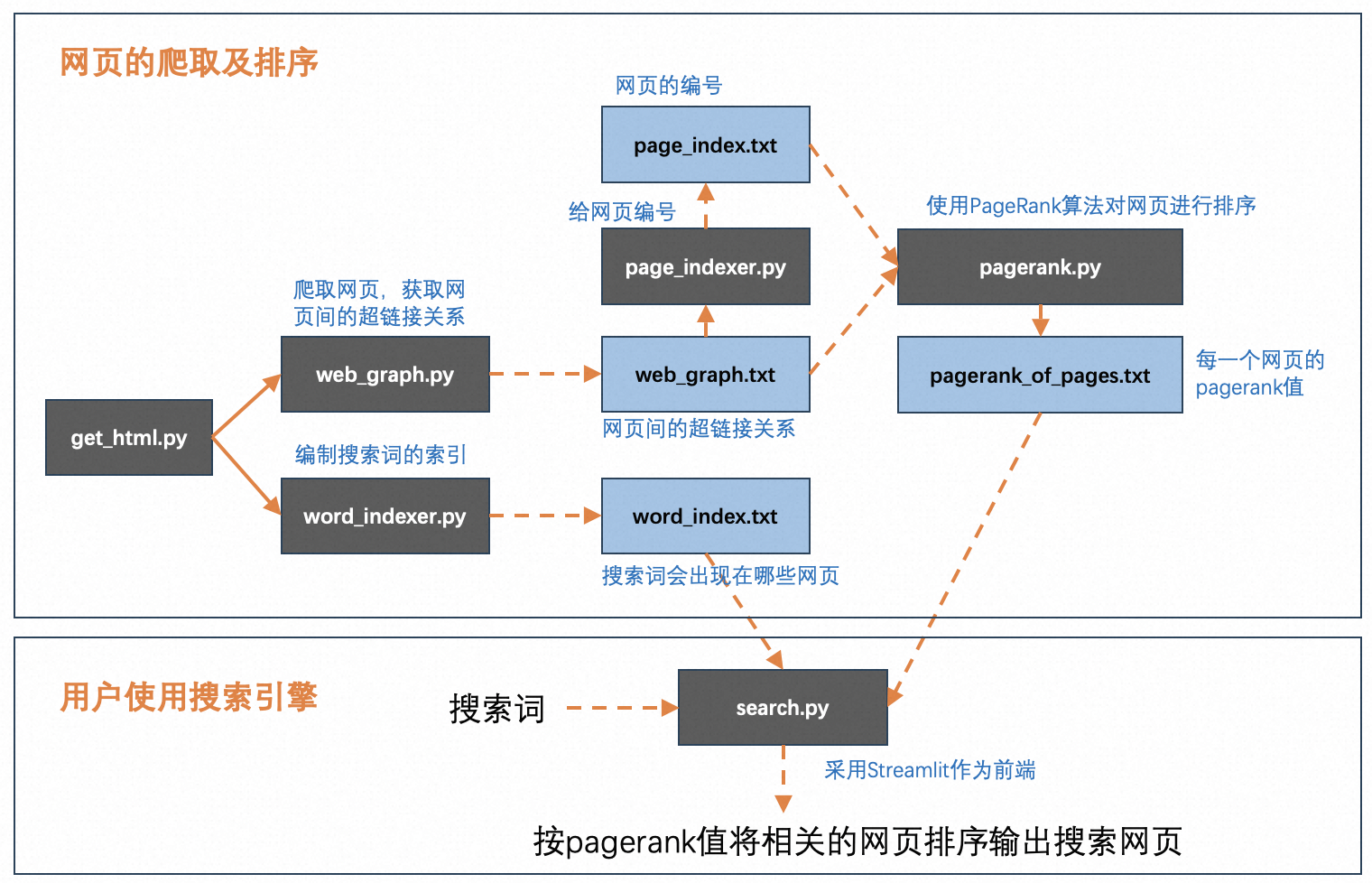
三、操作步骤
3.1 环境准备
-
创建用于运行搜索引擎的ECS实例。ECS实例建议配置如下:
扫描二维码关注公众号,回复: 17353639 查看本文章
-
实例规格:选择2vCPU 2 GiB的实例规格
-
系统盘:40 GiB
-
公网IP:选中分配公网 IPv4 地址并选择1M。
-
镜像:选择Linux系统的镜像,本实验中选取Alibaba Cloud Linux,版本为Alibaba Cloud Linux 3.2104 LTS 64位。当您选择其他Linux系统时,运行命令与本文有所不同。
-
-
实例安全组的入方向规则,放行22、80、443、8501端口(Streamlit默认使用8501端口)。
3.2 安装Anaconda
Anaconda中包含了Python、NumPy等本项目中需要的依赖项。
-
远程连接ECS实例。
-
更新操作系统。
sudo yum update -y sudo yum upgrade -y -
下载Anaconda安装包。
wget https://repo.anaconda.com/archive/Anaconda3-2023.09-0-Linux-x86_64.sh -
安装Anaconda。
bash Anaconda3-2023.09-0-Linux-x86_64.sh-
当出现下图所示信息时,单击Enter,继续安装过程。
-
出现下面的界面后,连续多次单击Enter。**在这里需要注意,此处安装软件是在显示它的授权协议,让用户阅读。不要一直按住Enter,而是建议一下一下地点击Enter,后续会出现****Do you accept the license terms?**的提示(紧接着一个步骤)。默认的选项是no,如果一直按住Enter,安装过程会中止。
-
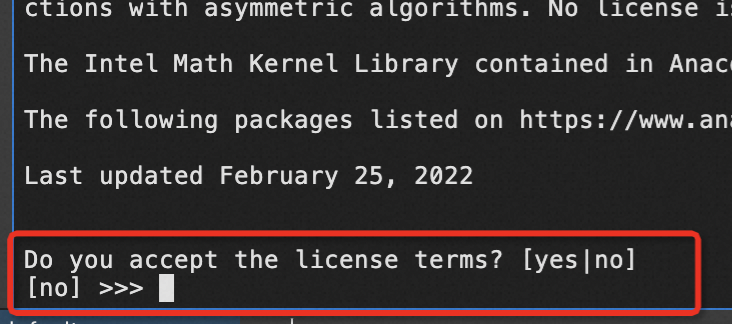
出现Do you accept the license terms? [yes|no]时,输入yes,单击Enter继续安装。
-
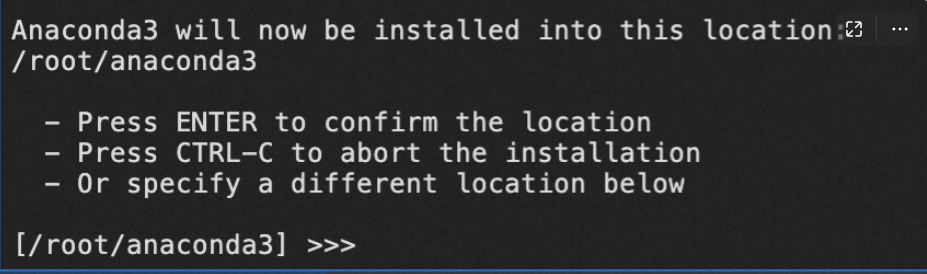
出现如下提示,单击Enter继续,等待Anaconda完成安装。
-
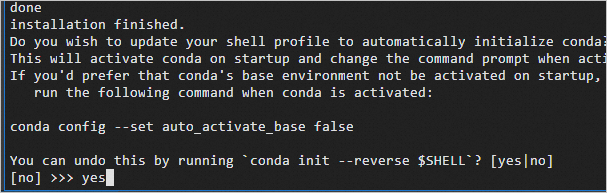
出现如下提示时,输入yes,单击Enter继续安装。
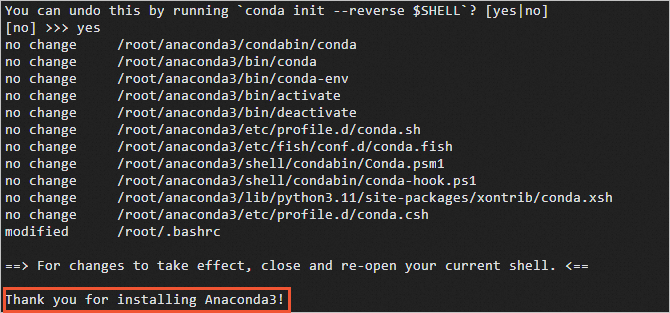
出现如下图所示信息时,说明Anaconda已安装完成。
-
-
单击页面右上角的
 图标,打开一个新终端。
图标,打开一个新终端。当出现(base)字样,表示Anaconda已启动。
说明
在实际开发过程中,通常需要通过conda安装虚拟环境,在虚拟环境中继续后续操作。本实验中略去此步骤。
3.3 安装Streamlit
Streamlit用于展示Web页面。
pip install streamlit
3.4 下载搜索引擎代码
搜索引擎能搜索到哪些网页,取决于搜索引擎通过爬虫获得了哪些网页。本实验中,以Introduction to Programming in Python网页为起始网页,爬取了总计322个网页。因此,搜索的结果限于这322个网页。用户可以通过在web_graph.py中添加新的起始网页,爬取新的网页。
-
下载搜索引擎代码压缩包。
wget https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/en-US/20231011/uhsy/search_engine_demo_aliyun.zip -
解压缩搜索引擎代码压缩包。
yum install unzip unzip search_engine_demo_aliyun.zip -
切换到
search_engine_demo_aliyun目录。cd search_engine_demo_aliyunsearch_engine_demo_aliyun目录下的文件结构如下所示:
-
**search.py:**运行该程序,可以启动搜索引擎网页,供用户使用。
-
pageranking:包含爬取网页、计算PageRank值、生成词的索引所需要的程序。
-
web_graph.py:爬取网页,生成网页间的关系图(graph);
-
page_indexer.py:对使用web_graph.py爬取到的网页做编号,以方便使用PageRank算法时做矩阵运算;
-
pagerank.py:使用PageRank算法计算网页的重要性;
-
word_indexer.py:对爬取到的网页中的词进行分析,确定每一个词分别出现在了哪些网页;
-
get_html.py:获取网页的hmtl内容,web_graph.py和word_indexer.py都会调用这个程序;
-
setup.py:用于同时运行web_graph.py, page_indexer.py, pagerank.py, word_indexer.py,并存储数据。
-
-
**data:**用于存储运行./pageranking/setup.py后生成的数据。
-
web_graph.txt: 用于存储网页间的关联关系,本质上是一个有向图。采用字典的方式存储数据,key为一个网页,value为这个网页上超链接指向的网页组成的数组;
-
page_indexer.txt: 爬取到的网页的编号。这里的网页经过了去重。采用字典的方式存储数据,key为一个网页,value为网页的编号;
-
pagerank_of_pages.txt:采用PageRank算法计算出的各个网页的PageRank值,即重要性。采用字典的方式存储数据,key为一个网页,value为这个网页的PageRank值;
-
word_index.txt:词的索引,即词会出现在哪些网页。采用字典的方式存储数据,key为一个词,value为出现了这个词的网页的数组。
-
-
3.5 运行搜索引擎
-
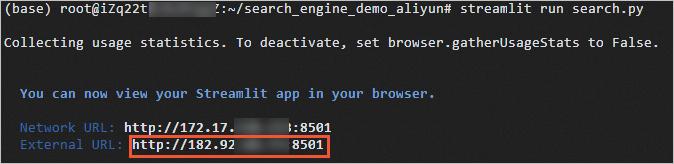
启动搜索引擎。
streamlit run search.py当显示如下信息时,说明Streamlit已启动。
-
复制External URL显示的公网IP地址输入到浏览器,就可以访问并使用搜索引擎。
-
修改网页的爬取及排序。
本实验中,以Introduction to Programming in Python这个网页为起始网页,爬取了总计322个网页。因此,搜索的结果限于这322个网页。
您可以通过在web_graph.py中添加新的起始网页,爬取新的网页。例如,如果要增加以Algorithms这个网页为起始网页,做爬虫,让搜索引擎能搜到更多的网页。可以按如下步骤操作:
-
切换到pageranking目录。
cd /root/search_engine_demo_aliyun/pageranking -
打开web_graph.py文件。
vim web_graph.py -
按
i键进入编辑模式。 -
在seed_urls数组中,增加
https://algs4.cs.princeton.edu/home/。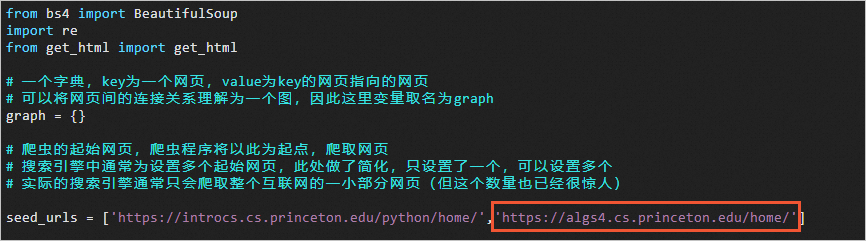
-
按Esc键,输入**:wq**,按Enter键,输入并保存文件。
-
-
执行如下命令,开始更新data文件夹中的数据。
其中,web_graph.txt、word_index.txt的生成需要较长的时间(约10分钟)。运行完毕后,搜索引擎即可覆盖更多的网页。
python setup.py
四、常见问题
4.1 运行setup.py时可能的问题
运行python setup.py做新的爬虫任务时,耗时较长,任务可能被中断。如果被中断,可以尝试重新运行。
4.2 如何使搜索引擎一直在线
在云服务器ECS上运行搜索引擎时,如果远程连接中断,search.py文件也会中止运行,导致搜索引擎无法使用。可以采用screen命令,解决这个问题。
-
执行
ctrl+z终止search.py程序。 -
查看占用8501端口的进程。
lsof -i:8501例如,占用该端口的PID位41644,输入下列命令中止该进程,释放8501端口。
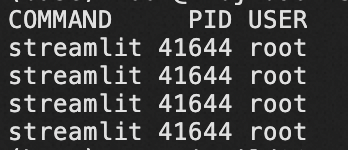
kill -9 41644 -
执行以下命令,使用screen新建一个窗口。
screen -S search
-
在新生成的窗口里,运行下列命令,启动搜索引擎。
streamlit run search.py -
按住ctrl+A,再按D,出现下列提示(detached from …)后,说明detach成功。
这样,即使远程连接中断、退出登录ECS实例,搜索引擎仍然将正常工作。