1、缓冲区
所谓缓冲区,简单来说就是程序运行时内存中的一块连续的区域。例如C语言中经常要用到的数组,其中最常见的是字符数组。在一个程序中,会声明各种变量。静态全局变量是位于数据段并且在程序开始运行时的时候被加载。而程序的动态的局部变量则分配在堆栈里面。如果向一个缓冲区复制数据,但是复制的数据量比缓冲区大的时候,就会发生缓冲区溢出。缓冲区溢出漏洞一直被列为最危险的一类漏洞。
2、缓冲区溢出漏洞产生的根源
冯诺依曼体系结构对代码和数据采用统一编址,没有严格区分二者。冯诺依曼体系结构规定:
(1) 数字计算机的数制采用二进制,计算机应该按照程序顺序执行。
(2) 计算机由控制器、运算器、存储器、输入设备、输出设备五大部件组成。
(3) 程序和数据以二进制代码形式不加区别地存放在存储器中,存放位置由地址确定。
(4) 控制器根据存放在存储器中的指令序列(程序)进行工作,并由一个程序计数器控制指令执行。控制器具有判断能力,能根据计算结果选择不同的工作流程。
因此,在冯诺依曼体系下,无论程序计数器指向数据区还是代码区,都会将指向的内容当做代码执行。
3、缓冲区溢出的类型
根据技术难度和出现的历史顺序,缓冲区溢出大致可以分为以下三代:
第一代缓冲区溢出主要指栈溢出。
第二代缓冲区溢出包括堆、函数指针覆盖、单字节越界的漏洞利用。
第三代缓冲区溢出包含格式化字符串攻击、堆管理结构漏洞。
从发展历程来看,栈溢出由于其原理简单,效果稳定,因此一直是主要的缓冲区溢出威胁。
第二代堆溢出主要是指利用堆溢出来覆盖函数指针和程序静态数据等,以进一步获得程序的控制权。
第三代缓冲区溢出中,格式化字符串攻击主要是由于编译器对格式化字符%n的限制以及编程中自身的习惯和意识而导致的,现在已经很难遇到。而随着对操作系统堆管理结构的分析,更多的堆溢出开始通过对堆结构中特定指针的覆盖,来达到修改EIP的目的。
4、缓冲区溢出产生的条件
- 使用非类型安全的语言,如 C/C++(不判断边界)。
- 以不安全的方式访问或复制缓冲区(不考虑大小)。
- 编译器将缓冲区放在内存中关键数据结构旁边或邻近的位置。(例如堆栈)
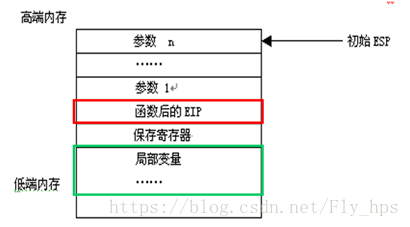
5、栈溢出
栈溢出的利用方式一般可以分为以下几种:修改邻接变量、修改函数返回地址和S.E.H结构覆盖等。下面分别介绍以上三种方式:
(1) 修改邻接变量:函数的局部变量在栈中一个挨着一个排列。如果这些局部变量中有数组之类的缓冲区,并且程序中存在数组越界的缺陷,那么越界的数组元素就有可能破坏栈中相邻变量的值,甚至破坏栈帧中所保存的EBP值、返回地址等重要数据。
栈溢出程序:


因为strcpy函数将128字节的数据赋予96字节的buffer,导致其相邻的内存部分被多余的数据覆盖。如果被覆盖的部分正好是程序控制流程的关键部分,我们就可以通过这种方式改变程序的流程,跳过某些正常的判断验证分支转而按照我们的意愿执行程序流向。
(1) 修改函数返回地址:
函数调用一般是通过系统栈实现的。如前所述,可以看出函数的返回地址具有相当重要的作用。如果函数返回地址被修改,那么在当前函数执行完毕准备返回原调用函数时,程序流程将被改变。
改写邻接变量的方法是很有用的,但这种漏洞利用对代码环境的要求相对比较苛刻。更通用、更强大的攻击通过缓冲区溢出改写的目标往往不是某一个变量。而是栈帧搞地质的EBP和函数返回地址等值。通过覆盖程序中的函数返回地址,攻击者可以直接将程序跳转到其预先设定并输入的ShellCode去执行。
如下图所示,通过覆盖修改返回地址,使其指向某条跳转指令,更改程序流程,从而转至ShellCode处执行。与简单的领接变量改写不同的是,通过修改函数指针可以随意更改程序指向,并执行攻击者向进程中植入自己定制的代码,实现“自主”控制。
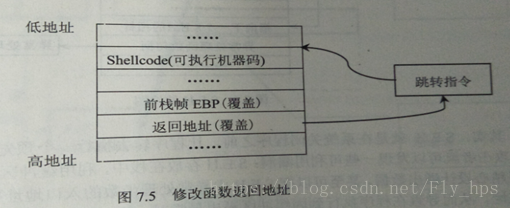
另一种较为简单的方法是直接将内存中ShellCode的地址赋给返回地址,然后使得程序直接跳转到ShellCode处执行。但是程序每次执行进入内存的地址是不一样的,我们无法保证每次程序运行时程序的装载地址都相同(这也使得每次在程序运行的时候,ShellCode在内存中的地址可能不同),所以就很有可能导致这种采用直接复制地址值的简单方式在以后的运行过程中出现跳转异常。为了避免这种情况的发生,我们可以在覆盖返回地址的时候赋给其某条跳转指令所在的地址,然后再通过这条跳转指令指向动态变化的ShellCode地址。这样,便能够确保程序执行流程在任何系统中运行都可以被正确定向。
(3)S.E.H结构覆盖
异常处理结构也很有可能被攻击者所利用。S.E.H在系统中,包含两个DWORD指针:S.E.H链表指针和异常处理函数句柄,共8个字节。当异常块(Exception Block)出现时,编译程序要生成特殊代码。编译程序必然产生一些表来处理S.E.H的数据结构。编译程序还必须提供回调函数,操作系统可以调用这些函数,保证异常块被处理。编译程序还要负责准备栈结构和其他内部信息,供操作系统使用和参考。当栈中有多个S.E.H的时候,他们之间通过链表指针在栈内由栈顶向栈底串成单向链表,位于链表最顶端的S.E.H通过TEB 0字节偏移处距离栈顶最近的S.E.H,使用异常处理函数句柄所指向的代码来处理异常。如果该异常处理函数运行失败,则顺着S.E.H链表一次尝试其他异常处理函数;如果程序预先安装的所有异常处理函数均无法处理,系统将采用默认的异常处理函数,弹出错误对话框,并且强制关闭程序。具体流行如下图所示:

其实,S.E.H就是在系统关闭程序之前,让程序转去执行一个预先设定的回调函数。这样,攻击者就可以发现一些可利用漏洞:S.E.H存放在栈中,利用缓冲区溢出可以覆盖S.E.H,如此精心设计溢出数据,甚至可以把S.E.H中异常处理函数的入口地址改为ShellCode的起始地址,从而导致在程序执行到缓冲区溢出异常时,Windows处理溢出异常转而执行的不适正常的异常处理函数,而是ShellCode。
6、ShellCode
ShellCode是指能完成特殊任务的自包含的二进制代码,根据不同的任务可能是发出一条系统调用或建立一个高权限的Shell,ShellCode也就由此而得名。
ShellCode的最终目的是取得目标机器的控制权,所以一般被攻击者利用系统的漏洞送入系统中执行,从而获得特殊权限的执行环境,或给自己设立有特权的账户。与ShellCode相关的还有Payload,在漏洞利用时,一般把ShellCode以及实现跳转到ShellCode的那部分填充代码合称为Payload。由于两者意义相差不大,现在也有很多人将Payload简称为ShellCode。
7、ShellCode具有以下特点:
(1)长度受限
(2)不能使用特定字符,例如\x00,\xff等
(3)具有重定位能力,由于ShellCode没有PE头,因此ShellCode中使用的API和数据必须由ShellCode自己进行重定位。
(4)一定的兼容性。为了支持更多的操作系统平台,ShellCode需要具有一定的兼容性。
实际上,ShellCode相当于一段小型的病毒代码,它也需要像病毒一样进行重定位,但是由于长度限制,其功能一般不复杂,常常只完成一个或两个功能(例如:打开本机的某个端口,并等待链接,或者像某个特定主机发起链接,供远程Shell控制本机等等)。
8、堆栈对字符串的处理方式
假设局部变量为字符串数组,请问在堆栈中如何给字符串数组分配空间的?
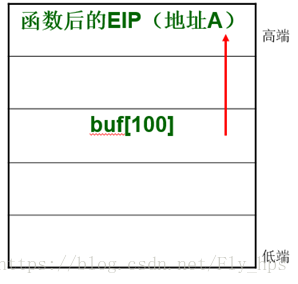
由于程序缺少必要的边界检查,如果局部变量中有字符数组存在,只要赋予该数组的字符串足够长,就能将上面的返回地址覆盖掉。字符数组超出了开始为其分配的空间大小,缓冲区溢出就发生了。
精心构造溢出所用的字符串,将4个字节返回地址替换成别有用心的地址,当函数返回时,我们就能引导程序到我们指定的代码去执行,从而获得程序控制权。
如果地址A所指定的内存空间事先存放了设计好的攻击代码,那么攻击就会随之发生。
9、缓冲区溢出实例:打开记事本
会用到的API函数
- WinExec(“notepad” ,1 );
- ExitProcess(0);
构造攻击代码(机器码)
Push 646170 Push 65746f6e Push 1 Mov eax, esp Add eax,4 Push eax Moveax,WinExec Call eax Push 0 Moveax,ExitProcess Call eax
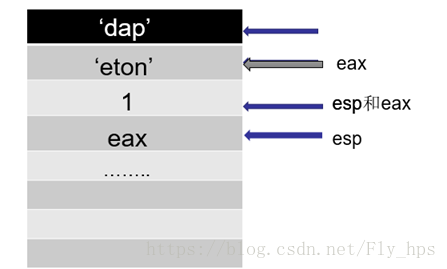
如何覆盖返回地址
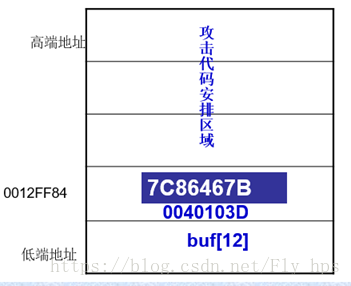
- 观察:函数结束后,esp内的值(本例中为:0012FF84H)
- 溢出的攻击代码放在函数返回后栈顶指针esp指向的位置。
- 只需要在返回地址安排一条代码,让它跳转到攻击代码存放的地址处。
- 安排在返回地址处的指令:JMP ESP

- 为了程序通用性,最好在系统必要的动态链接库中去找(如kernel32)。
- 最后找到的这个地址7C86467B,对应二进制码FF E4(对应的汇编指令jmp esp)。该地址在kernel32.dll中。
为加强程序的通用性,程序如何改?
DWORD a1 = (DWORD)GetProcAddress(LoadLibrary("kernel32.dll"),"WinExec");
DWORD a2 =(DWORD)GetProcAddress(LoadLibrary("kernel32.dll"),"ExitProcess");
*(DWORD*)(shellcode+49) = a1;
*(DWORD*)(shellcode+58) = a2;
10、缓冲区溢出漏洞避免的方法
- 检查容易出错的函数
- 数组边界检查,要求代码传递缓冲区的长度
- 程序指针完整性检查
思考:
- 函数调用前后,堆栈有什么变化?
- 为什么能发生缓冲区溢出?
- 溢出发生后,程序会转到哪里去执行?
- 什么是Shellcode?它有什么特点?
- 如何加强溢出程序的通用性?
- 如何防范缓冲区溢出?