谢尔盖·费尔德曼(Sergey Feldman)是西雅图AI2的高级应用研究科学家,专注于自然语言处理和机器学习。

2020 年是搜索 Semantic Scholar 的一年,Semantic Scholar 是一款免费的、人工智能驱动的科学文献研究工具,位于艾伦人工智能研究所。我们今年最大的努力之一是提高搜索引擎的相关性,从今年年初开始,我的任务就是弄清楚如何使用大约 3 年的搜索日志数据来构建更好的搜索排名。
最终,我们最终得到了一个搜索引擎,可以为我们的用户提供更相关的结果,但一开始我低估了让机器学习在搜索中正常工作的复杂性。“没问题,”我心想,“我可以做到以下几点,并在 3 周内彻底成功”:
- 获取所有搜索日志。
- 做一些特征工程。
- 训练、验证和测试出色的机器学习模型。
- 部署。
尽管这似乎是搜索引擎文献中的既定做法,但出于竞争原因,实际使搜索引擎工作的实践工作中的许多经验和见解通常不会发表。由于 AI2 专注于 AI 的共同利益,因此我们将许多技术和研究开放并免费使用。在这篇文章中,我将“全面”说明为什么上述过程并不像我们希望的那样简单,并详细说明以下问题及其解决方案:
- 数据绝对是肮脏的,需要仔细理解和过滤。
- 许多功能在模型开发过程中提高了性能,但在实践中使用时会导致奇怪和不需要的行为。
- 训练模型固然很好,但选择正确的超参数并不像在保留测试集上优化 nDCG 那么简单。
- 训练有素的模型仍然会犯一些奇怪的错误,需要事后纠正来修复它们。
- Elasticsearch 很复杂,而且很难做到正确。
除了这篇博文,本着开放的精神,我们还发布了目前在 www.semanticscholar.org 上运行的完整 Semantic Scholar 搜索重新排名模型,以及您自己进行重新排名所需的所有工件。在这里查看: GitHub - allenai/s2search: The Semantic Scholar Search Reranker
Search Ranker 概述
首先,我简要介绍一下 Semantic Scholar 的高级搜索架构。当在Semantic Scholar上进行搜索时,将执行以下步骤:
- 您的搜索查询将转到 Elasticsearch(我们索引了近 ~190M 篇论文)。
- 排名靠前的结果(我们目前使用 1000)由机器学习排名器重新排名。
我们最近对 (1) 和 (2) 进行了改进,但这篇博文主要是关于在 (2) 上所做的工作。我们使用的模型是具有 LambdaRank 目标的 LightGBM 排名器。它的训练速度非常快,评估速度快,并且易于大规模部署。诚然,深度学习有可能提供更好的性能,但模型摆动、缓慢的训练(与 LightGBM 相比)和较慢的推理都是不利的。
数据必须按如下方式构建。给定查询 q、有序结果集 R = [r_1, r_2, ..., r_M],以及每个结果的点击次数 C = [c_1, c_2, ..., c_M],我们将以下输入/输出对作为训练数据馈送到 LightGBM 中:
f(q, r_1), c_1
f(q, r_2), c_2
...
f(q, r_m), c_m
其中 f 是特征化函数。每个查询最多有 m 行,LightGBM 优化了一个模型,如果c_i > c_j,则 model(f(q, r_i)) > model(f(q, r_j)) 尽可能多地训练数据。
这里的一个技术点是,您需要通过按其位置的逆倾向得分对每个训练样本进行加权来纠正位置偏差。我们通过在搜索引擎结果页面上运行随机位置交换实验来计算倾向得分。
特征工程和超参数优化是实现这一切的关键组成部分。我们稍后会回到这些,但首先我将讨论训练数据及其困难。
数据越多,问题越多
机器学习智慧101说“数据越多越好”,但这种说法过于简单化了。数据必须是相关的,删除不相关的数据很有帮助。我们最终需要删除大约三分之一的数据,这些数据不满足启发式的“是否有意义”过滤器。
这是什么意思?假设查询是 SARS-CoV-2 的气溶胶和表面稳定性与 SARS-CoV-1 相比,搜索引擎结果页面 (SERP) 返回以下论文:
- SARS-CoV-2 与 SARS-CoV-1 相比的气溶胶和表面稳定性
- SARS-CoV-2的近端起源
- 感染患者上呼吸道标本中的SARS-CoV-2病毒载量
- ...
我们预计点击将在位置 (1) 上,但在此假设数据中,它实际上位于位置 (2) 上。用户点击了与其查询不完全匹配的论文。这种行为有合理的原因(例如,用户已经阅读了论文和/或想要查找相关论文),但对于机器学习模型来说,这种行为看起来像噪音,除非我们有功能允许它正确推断这种行为的根本原因(例如,基于以前搜索中点击的内容的特征)。当前的架构不会根据用户的历史记录对搜索结果进行个性化设置,因此这种训练数据使学习变得更加困难。当然,数据大小和噪音之间需要权衡——你可以拥有更多嘈杂的数据或更少的数据更干净,而后者更适合解决这个问题。
另一个例子:假设用户搜索深度学习,搜索引擎结果页面返回了这些年份和引用的论文:
- 年份 = 1990,引用次数 = 15000
- 年份 = 2000,引用次数 = 10000
- 年份 = 2015,引用次数 = 5000
现在点击在位置 (2) 上。为了论证,假设所有 3 篇论文都同样“关于”深度学习;也就是说,他们在标题/摘要/地点中出现短语深度学习的次数相同。撇开话题性不谈,我们认为学术论文的重要性是由新近度和引用次数共同决定的,在这里,用户既没有点击最新的论文,也没有点击被引用最多的论文。这有点像稻草人的例子,例如,如果数字(3)的引用次数为零,那么许多读者可能更喜欢数字(2)排在第一位。尽管如此,以上两个示例为指导,用于删除“无意义”数据的过滤器检查了给定三元组(q、R、C)的以下条件:
- 是否所有点击的论文都比未点击的论文被引用更多?
- 是否所有点击的论文都比未点击的论文更新?
- 是否所有点击的论文在文本上都与标题中的查询更加匹配?
- 是否所有点击的论文在文本上都与作者字段中的查询更加匹配?
- 是否所有点击的论文在文本上都与场地字段中的查询更加匹配?
我要求可接受的训练示例至少满足这 5 个条件之一。当所有被点击的论文的值(引文编号、新近度、匹配分数)都高于未点击论文中的最大值时,每个条件都得到满足。您可能会注意到,摘要不在上面的列表中;包括或排除它没有任何实际区别。
如上所述,这种过滤器删除了大约三分之一的所有(查询、结果)对,并在我们的最终评估指标中提供了大约 10% 到 15% 的改进,这将在后面的部分中更详细地描述。请注意,此过滤是在删除可疑的机器人流量后进行的。
特征工程挑战
我们为每个(查询、结果)对生成了一个特征向量,总共有 22 个特征。特征化器的第一个版本产生了 90 个特征,但其中大多数是无用的或有害的,这再次证实了来之不易的智慧,即当你为它们做一些工作时,机器学习算法通常会更好地工作。
最重要的功能包括在论文的标题、摘要、地点和年份字段中查找查询文本的最长子集。为此,我们从查询中生成所有可能的 ngram 长度不超过 7,并在论文的每个字段中执行正则表达式搜索。一旦我们有了匹配项,我们就可以计算各种特征。以下是按纸张字段分组的最终功能列表。
- title_fraction_of_query_matched_in_text
- title_mean_of_log_probs
- title_sum_of_log_probs*match_lens
- abstract_fraction_of_query_matched_in_text
- abstract_mean_of_log_probs
- abstract_sum_of_log_probs*match_lens
- abstract_is_available
- venue_fraction_of_query_matched_in_text
- venue_mean_of_log_probs
- venue_sum_of_log_probs*match_lens
- sum_matched_authors_len_divided_by_query_len
- max_matched_authors_len_divided_by_query_len
- author_match_distance_from_ends
- paper_year_is_in_query
- paper_oldness
- paper_n_citations
- paper_n_key_citations
- paper_n_citations_divided_by_oldness
- fraction_of_unquoted_query_matched_across_all_fields
- sum_log_prob_of_unquoted_unmatched_unigrams
- fraction_of_quoted_query_matched_across_all_fields
- sum_log_prob_of_quoted_unmatched_unigrams
其中一些功能需要进一步解释。有关更多详细信息,请访问本文末尾的附录。如果你想要血腥的细节,所有的特征化都发生在这里。
为了了解所有这些功能的重要性,下面是当前在生产环境中运行的模型的 SHAP 值图。
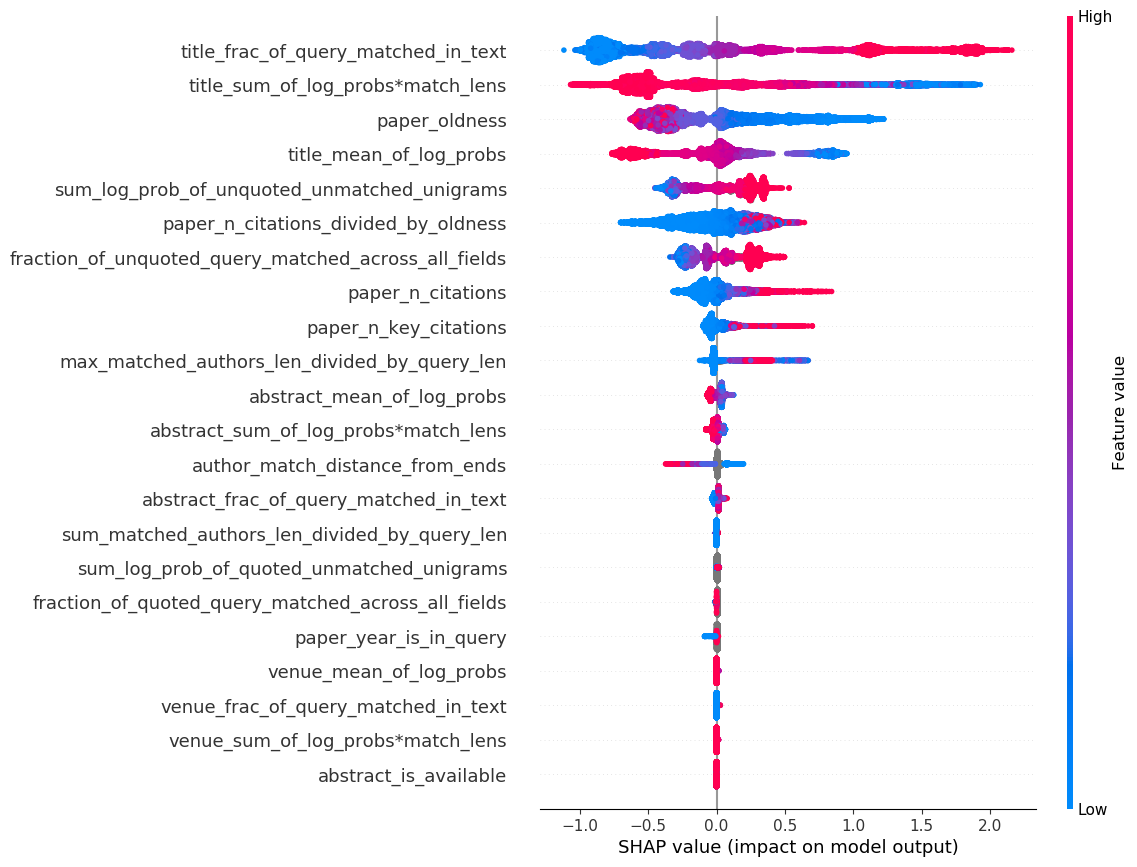
如果您以前没有看过 SHAP 图,那么阅读起来有点棘手。样本 i 和特征 j 的 SHAP 值是一个数字,大致告诉您“对于此样本 i,此特征 j 对最终模型分数的贡献有多大”。 对于我们的排名模型,较高的分数意味着论文的排名应该更接近顶部。SHAP 图上的每个点都是一个特定的(查询、结果)点击对样本。颜色对应于该要素在原始要素空间中的值。例如,我们看到title_fraction_of_query_matched_in_text特征位于顶部,这意味着它是具有最大(绝对)SHAP 值总和的特征。它从左边的蓝色(接近 0 的低特征值)到右边的红色(接近 1 的高特征值),这意味着模型已经学会了标题中查询的匹配程度与论文排名之间的大致线性关系。正如人们所预料的那样,越多越好。
其他一些观察结果:
- 许多关系看起来是单调的,这是因为它们大致是: LightGBM 允许您指定每个特征的单变量单调性,这意味着如果所有其他特征保持不变,则如果特征上升/下降,输出分数必须以单调方式上升(可以指定上升和下降)。
- 了解匹配的查询量和匹配的日志概率是很重要的,而不是多余的。
- 该模型了解到,最近的论文比旧的论文更好,即使这个特征没有单调性约束(唯一没有这种约束的特征)。正如人们所预料的那样,学术搜索用户喜欢最近的论文!
- 当颜色为灰色时,这意味着缺少该功能——LightGBM 可以本地处理缺失的功能,这是一个很大的好处。
- 场地功能看起来非常重要,但这只是因为一小部分搜索是面向场地的。不应删除这些功能。
正如您所料,关于这些功能的许多小细节对于正确使用非常重要。这里详细介绍这些细节超出了这篇博文的范围,但如果你曾经做过特征工程,你就会知道其中的练习:
- 设计/调整功能。
- 训练模型。
- 进行错误分析。
- 注意你不喜欢的奇怪行为。
- 返回 (1) 并调整。
- 重复。
如今,除了将 (1) 替换为“设计/调整神经网络架构”,并在 (1) 和 (2) 之间添加“查看模型是否训练”作为额外的步骤之外,执行此循环更为常见。
评估问题
机器学习的另一个无懈可击的教条是训练、验证/开发和测试拆分。它非常重要,很容易出错,而且它有复杂的变体(我最喜欢的话题之一)。这个想法的基本陈述是:
- 使用训练数据进行训练。
- 使用验证/开发数据选择模型变体(包括超参数)。
- 估计测试集上的泛化性能。
- 永远不要将测试集用于其他任何事情。
这很重要,但在学术出版物之外通常是不切实际的,因为您可用的测试数据并不能很好地反映“真实”的生产测试数据。当您想要训练搜索模型时尤其如此。
为了理解原因,让我们将训练数据与“真实”测试数据进行比较/对比。训练数据的收集方式如下:
- 用户发出查询。
- 一些现有系统(Elasticsearch + 现有 reranker)会返回结果的第一页。
- 用户从上到下(可能)查看结果。他们可能会点击一些结果。他们可能会也可能不会在此页面上看到每个结果。有些用户会转到结果的第二页,但大多数用户不会。
因此,每个查询的训练数据有 10 个或 20 个或 30 个结果。另一方面,在生产过程中,模型必须对 Elasticsearch 获取的前 1000 个结果进行重新排名。同样,训练数据只是现有重新排名器选择的前几个文档,而测试数据是 Elasticsearch 选择的 1000 个文档。这里朴素的方法是获取搜索日志数据,将其划分为训练、验证和测试,然后完成一组良好的工程(功能、超参数)的过程。但是,没有充分的理由认为,在类似训练的数据上进行优化将意味着你在“真实”任务上有良好的表现,因为它们是完全不同的。更具体地说,如果我们创建一个模型,它擅长对之前的重新排名器的前 10 个结果进行重新排序,这并不意味着这个模型将擅长对 ElasticSearch 的 1000 个结果进行重新排序。后 900 名候选人从来都不是训练数据的一部分,可能看起来不像前 100 名,因此重新排名所有 1000 名候选人与重新排名前 10 名或 20 名的任务根本不相同。
事实上,这在实践中是一个问题。我整理的第一个模型管道使用保留的 nDCG 进行模型选择,而此过程中的“最佳”模型出现了奇怪的错误并且无法使用。从定性上讲,“好”的nDCG模型和“坏的”nDCG模型看起来并没有太大区别——两者都是坏的。我们需要另一个更接近生产环境的评估集,非常感谢 AI2 首席执行官 Oren Etzioni 提出了我接下来将要描述的想法的精髓。
与直觉相反,我们最终使用的评估集根本不是基于用户点击的。取而代之的是,我们从真实用户查询中随机抽取了 250 个查询,并将每个查询分解为其组成部分。例如,如果查询是 soderland etzioni emnlp open ie information extraction 2011,则其组件为:
- 作者: etzioni, soderland
- 地点: emnlp
- 年份: 2011
- 文本:打开即,信息提取
这种分解是手工完成的。然后,我们将此查询发送到之前的语义学术搜索(S2),谷歌学术(GS),Microsoft Academic Graph(MAG)等,并查看顶部有多少结果满足搜索的所有组成部分(例如作者,地点,年份,文本匹配)。在此示例中,假设 S2 有 2 个结果,GS 有 2 个结果,MAG 有 3 个满足所有组件的结果。我们将采用 3(其中最大的一个),并要求此查询的前 3 个结果必须满足其所有组件条件(上面的要点)。这是一篇示例论文,它满足了此示例的所有组件。它由 Etzioni 和 Soderland 于 2011 年在 EMNLP 上发表,包含确切的 ngram “open IE”和“information extraction”。
除了上面的作者/地点/年份/文本部分外,我们还检查了引文顺序(从高到低)和新近顺序(从最近到最近)。要获得特定查询的“通过”,重排器模型的顶级结果必须与所有组件匹配(如上例所示),并遵循引文顺序或新近排序。否则,模型将失败。有可能在这里进行更细粒度的评估,但全有或全无的方法奏效了。
这个过程并不快(两个人需要 2-3 天的工作),但最后,我们将 250 个查询分解为多个组成部分,每个查询的目标结果数,以及用于评估任何建议模型满足 250 个查询中哪一部分的代码。
事实证明,在这个指标上爬山更有成效,原因有两个:
- 它与用户感知的搜索引擎质量更相关。
- 每个“失败”都附带了对哪些组件不满意的解释。例如,作者不匹配,引用/新近排序不被考虑。
一旦我们制定了这个评估指标,超参数优化就变得明智了,特征工程也明显加快了。当我开始模型开发时,这个评估指标约为 0.7,最终模型在这组特定的 0 个查询中的得分为 93.250。对于选择 250 个查询,我感觉不到指标差异,但我的预感是,如果我们继续使用一组全新的 250 个查询进行模型开发,模型可能会得到进一步改进。
事后校正
即使是最好的模型有时也会做出看似愚蠢的排名选择,因为这是机器学习模型的本质。许多此类错误都可以通过简单的基于规则的事后更正来修复。以下是对模型分数的事后更正的部分列表:
- 带引号的匹配项高于未带引号的匹配项,而带引号较多的匹配项高于较少的带引号的匹配项。
- 确切的年份匹配结果将移至顶部。
- 对于作者全名(如 Isabel Cachola)的查询,该作者的结果将移至顶部。
- 查询中所有一元组都匹配的结果将移至顶部。
您可以在此处的代码中看到事后更正。
贝叶斯 A/B 测试结果
我们进行了几周的 A/B 测试,以评估新的重新排名器的性能。以下是查看每个发出的查询的(平均)总点击次数时的结果:

这告诉我们,人们在搜索结果页面上点击的频率增加了约 8%。但是他们会点击更高的位置结果吗?我们可以通过查看每个查询点击的最大倒数排名来检查这一点。如果没有单击,则分配的最大值为 0。

答案是肯定的——点击的最大倒数排名上升了约 9%!为了更详细地了解点击位置的变化,以下是用于控制和测试的最高/最大点击位置的直方图:
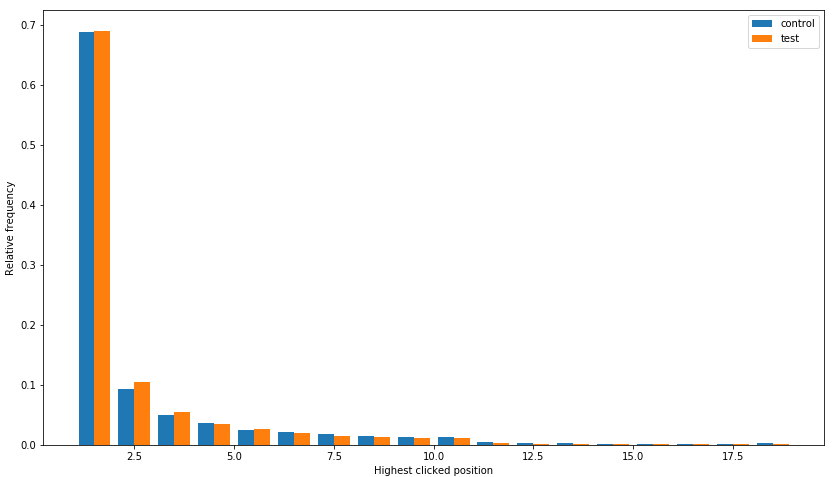
此直方图排除了非点击,并显示大部分改进发生在位置 2,其次是位置 3 和位置 1。
为什么不在 Elasticsearch 中完成所有这些操作呢?
以下两部分由 Semantic Scholar 的搜索工程主管 Tyler Murray 撰写。
Elasticsearch 提供了一套强大的工具和集成,即使是最高级的用户也能构建各种匹配、评分和重新排名子句。虽然功能强大,但当跨许多字段/子句/过滤器组合时,这些功能往往会令人困惑,最坏的情况是荒谬的。对于更复杂的搜索用例,调试和调整提升、过滤器、重新评分所涉及的工作很快就会变得站不住脚。
对于希望从手动调整的加权和重新评分转向根据真实世界用户行为训练的搜索系统的搜索团队来说,LTR 往往是首选方法。与另一种方法相比,在实施 LTR 时,会出现以下优点和缺点:
优点:
- 重新评分发生在 Elasticsearch 的查询生命周期中。
- 避免或最小化与“通过”重新排名的候选人相关的网络成本。
- 使技术保持在与主存储引擎更紧密的轨道内。
- 搜索技术的正常运行时间与群集隔离,而不是分散在服务中。
缺点:
- 插件架构需要 Java 二进制文件才能在 Elasticsearch JVM 中运行。
- 在修改、部署和测试时,迭代速度可能会非常缓慢,因为需要完全滚动重启集群。对于较大的集群尤其如此。(>5结核病)
- 尽管 Java 保持着活跃且成熟的生态系统,但大多数尖端的机器学习和 AI 技术目前都存在于 Python 世界中。
- 在一个难以收集判断和/或根本不可能大规模收集判断的空间中,LTR 方法变得难以有效训练。
- 在 A/B 测试中并排测试排名算法的灵活性有限,而无需在同一集群中运行多个排名插件。
当我们展望未来如何测试和部署排名变化时,Elasticsearch 插件方法的缺点在两个主轴上大大超过了优点;首先,迭代和测试速度,因为这对于我们启动以用户为中心的改进方法至关重要。在我们迭代时,离线测量对于测试各种模型的健全性至关重要,但最终的测量将始终是模型在野外的表现。有了 Elasticsearch 提供的插件架构,迭代和测试就变得相当繁琐和耗时。其次,通过 Python 生态系统实现的强大工具链超过了任何短期延迟回归。事实证明,集成各种语言模型和现有机器学习技术的灵活性在解决广泛的相关性问题方面卓有成效。将这些解决方案转换回 Java 生态系统将是一项艰巨的工作。总而言之,Elasticsearch 为构建强大的搜索体验奠定了坚实的基础,但随着需要处理更复杂的相关性问题以及更快的迭代速度,我们越来越需要将目光投向 Elasticsearch 生态系统之外。
在 Elasticsearch 中调整候选查询
事实证明,获得过滤、评分和重新评分子句的正确组合比预期的要困难得多。这在一定程度上是由于从用于支持基于插件的排名模型的现有基线开始工作,但也由于索引映射的一些问题。一些注意事项可以帮助指导他人完成他们的旅程:
Don’t:
- Allow the documents you’re searching against to become bloated with anything but the necessary fields and analyzers for search ranking. If you’re using the same index to search and hydrate records for display you may want to consider whether multiple indices/clusters are necessary. Smaller documents = faster searches, and becomes increasingly more important as your data footprint grows.
- Use many multi_match queries as these are slow and prove to generate scores for documents that are difficult to reason about.
- Perform function_score type queries on very large result sets without fairly aggressive filters or considering whether this function can be performed in a rescore clause.
- Use script_score clauses, they’re slow and can easily introduce memory leaks in JVM. Just don’t do it.
- Ignore the handling of stopwords in your indices/fields. They make a huge difference in scoring, especially so with natural language queries where a high number of terms and stopword usage is common. Always consider the common terms (<= v7.3) query type mentioned below or a stopword filter in your mapping.
- Use field_name.* syntax in filters or matching clauses as this incurs some non-trivial overhead and is almost never what you want. Be explicit about which fields/analyzers you are matching against.
Do:
- Consider using common terms queries with a cutoff frequency if you don’t want to filter stopwords from your search fields. This was what pushed us over the edge in getting a candidate selection query that performed well enough to launch.
- Consider using copy_to during indexing to build a single concatenated field in places where you want to boost documents that match multiple terms in multiple fields. We recommend this approach anywhere you are considering a multi_match query.
- Use query_string type queries if your use case allows for it. IMO these are the most powerful queries in the ES toolbox and allow for a huge amount of flexibility and tuning.
- Consider using a rescore clause as it improves performance of potentially costly operations and allows the use of weighting matches with constant scores. This proved helpful in generating scores that we could reason about.
- Field_value_factor scoring in either your primary search clause or in a rescore clause can prove incredibly useful. We consider highly cited documents to be of a higher relevance and thus use this tool to boost those documents accordingly.
- Read the documentation on minimum_should_match carefully, and then read it a few more times. The behavior is circumstantial and acts differently depending on the context of the use.
结论和致谢
新的搜索已在 semanticscholar.org 上上线,我们认为这是一个很大的改进!试一试,通过电子邮件向我们提供一些反馈 [email protected]。
该代码也可供您仔细检查和使用。欢迎反馈。
整个过程花了大约 5 个月的时间,如果没有 Semantic Scholar 团队很大一部分人的帮助,这是不可能的。我特别要感谢道格·唐尼(Doug Downey)和丹尼尔·金(Daniel King)不知疲倦地与我一起集思广益,查看了无数的原型模型结果,并告诉我它们是如何以新的和有趣的方式被打破的。我还要感谢 Madeleine van Zuylen 在这个项目上所做的所有精彩的注释工作,以及 Hamed Zamani 的有益讨论。也要感谢工程师们,他们拿走了我的代码,并神奇地让它在生产中工作。
附录:有关功能的详细信息
- *_fraction_of_query_matched_in_text — 在此特定字段中匹配了查询的哪一部分?
- log_prob是指语言模型实际匹配的概率。例如,如果查询是用于情感分析的深度学习,而短语情感分析是匹配项,我们可以在快速、低开销的语言模型中计算其对数概率,以了解惊喜程度。直觉是,我们不仅想知道在特定字段中匹配了多少查询,还想知道匹配的文本是否有趣。比赛的概率越低,它应该越有趣。例如,“病毒载量的优势”比“他们去商店”更令人惊讶的 4 克。*_mean_of_log_probs 是字段中匹配项的平均对数概率。我们使用 KenLM 作为我们的语言模型,而不是类似 BERT 的东西——它快如闪电,这意味着我们可以为每个功能调用它数十次,并且仍然能够快速特征化——足以在生产中运行 Python 代码。(非常感谢 Doug Downey 推荐此功能类型和 KenLM。
- *_sum_of_log_probs*match_lens — 采用平均对数概率并不能提供有关匹配是否发生多次的任何信息。总和有利于查询文本多次匹配的论文。这主要与摘要相关。
- sum_matched_authors_len_divided_by_query_len — 这与标题、摘要和地点的匹配类似,但每个论文作者的匹配是一次完成一个。此功能有一些额外的技巧,我们更关心姓氏匹配而不是名字和中间名匹配,但不是绝对的。您可能会遇到一些搜索结果,其中中间名匹配的论文排名高于姓氏匹配的论文。这是一项功能改进 TODO。
- max_matched_authors_len_divided_by_query_len — 总和让您了解总体上匹配的作者字段的匹配量,最大值告诉您最大的单个作者匹配量是多少。直观地说,如果你搜索谢尔盖·费尔德曼,一篇论文可能是(谢尔盖·帕特尔,罗伯塔·费尔德曼),另一篇是(谢尔盖·费尔德曼,玛雅·古普塔),第二篇论文要好得多。max 特征允许模型学习这一点。
- author_match_distance_from_ends — 有些论文有 300 位作者,您更有可能纯粹偶然地获得作者匹配。在这里,我们告诉模型作者匹配的位置。如果您匹配了第一作者或最后一位作者,则此功能为 0(并且模型会了解到较小的数字很重要)。如果匹配作者中的 150 分(满分 300 分),则特征为 150(大值被认为是坏的)。该功能的早期版本只是 len(paper_authors),但该模型学会了过于严厉地惩罚许多作者的论文。
- fraction_of_*quoted_query_matched_across_all_fields — 尽管我们为每个论文字段都有零星的匹配项,但了解在所有字段合并时匹配了多少查询会很有帮助,这样模型就不必尝试学习如何添加。
- sum_log_prob_of_unquoted_unmatched_unigrams — 本文中未匹配的一元组的对数概率。在这里,模型可以弄清楚如何惩罚不完整的匹配。例如,如果你搜索深度学习来识别蚯蚓,模型可能只找到没有深度这个词或没有蚯蚓这个词的论文。它可能会降低排除蚯蚓等非常令人惊讶的术语的匹配项,假设引用和新近度具有可比性。