在 Python,只需要导入 urllib.parse,然后使用 quote 函数即可把任意字符串进行 URL 编码

quote 函数实质是按字符串的 UTF-8 字符值进行编码的,英文字符和半角符号是一个字节的ASCII码,中文是 UTF-8 三位字节码。
现在使用 C 语言来实现等效的代码,我在网上找到现成的代码,修改它使得从命令行接收输入字符串参数,然后进行 URL 编码并输出:
#include <stdio.h>
#include <stdlib.h>
#include <stdint.h>
#include <string.h>
#include <ctype.h>
char* urlquote(char* str) {
size_t len = strlen(str);
char* result = (char*)malloc((3 * len + 1) * sizeof(char));
size_t index = 0;
for (size_t i = 0; i < len; i++) {
char c = str[i];
if (isalnum(c) || c == '-' || c == '_' || c == '.' || c == '~' || c == '/') {
result[index++] = c;
}
else {
sprintf(&result[index], "%%%02X", (uint8_t)c);
index += 3;
}
}
result[index] = '\0';
return result;
}
int main(int argc, char* argv[]) {
if (argc!=2){
printf("Usage: urlquote.exe <string>\n\n");
return 1;
}
char* quoted_str = urlquote(argv[1]);
printf("%s\n", quoted_str);
free(quoted_str);
return 0;
}
该代码在 Linux 环境里运行没有问题,输入参数“中”字可以得出正确的编码值:%E4%B8%AD。
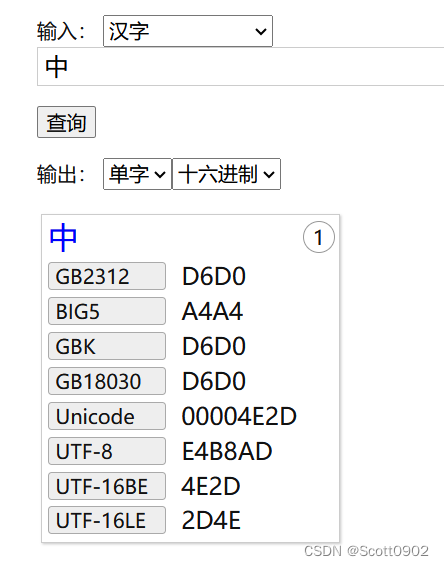
然而在 Windows 命令行环境里编译运行,如果输入半角字符可以得出正确的 URL 编码,但输入字符串只要有中文,得出的结果就截然不同。举个例子,同样的“中”字在 Windows 环境里编码的结果却是:%D6%D0。

这个 D6 D0 是什么?我在其他查询中文编码的网站上得知是 GBK 编码。
“中”字的 UTF-8 编码应该是 E4 B8 AD,三位字节组成。
Windows 和 Linux 环境运行结果不同的原因在于命令行环境的字符编码不同。Linux 以及 C 编译器使用 UTF-8 编码,因此上述代码在 Linux 命令行里输入的参数都能以 UTF-8 编码传入进而转换得出正确的结果。
然而 Windows 的命令行字符编码与本地代码页有关,不同语言版本的 Windows,其命令编码都不统一,简体中文的代码页是 GBK(936),繁体中文是 BIG5(950),上述 C 代码没有考虑什么字符编码环境,仅仅使用当前默认编码,没有正确转换到 UTF-8,所以难怪 C 语言开发者宁愿选择 Linux 或 Mac 环境来开发,就是因为 C 语言在 Windows 环境遇到中文就会出现各种水土不服的问题而令人望而生畏。
因此为了让代码能在 Windows 环境得出正确结果,就必须把传入参数的字符串进行转换成 UTF-8。由于历史问题,Windows API 库没有一步到位直接把 GBK 转换 UTF-8 的函数,只能 GBK → UniCode → UTF-8 这样来转换。上述代码修改如下:
#include <stdio.h>
#include <stdlib.h>
#include <stdint.h>
#include <string.h>
#include <ctype.h>
#include <wchar.h>
#include <windows.h>
char* urlquote(char* gbk_str) {
// 先转换UniCode
int size_needed = MultiByteToWideChar(CP_ACP, 0, gbk_str, -1, NULL, 0);
wchar_t* wide_str = (wchar_t*)malloc(size_needed * sizeof(wchar_t));
MultiByteToWideChar(CP_ACP, 0, gbk_str, -1, wide_str, size_needed);
// 再转换UTF-8
size_needed = WideCharToMultiByte(CP_UTF8, 0, wide_str, -1, NULL, 0, NULL, NULL);
char* utf8_str = (char*)malloc(size_needed);
WideCharToMultiByte(CP_UTF8, 0, wide_str, -1, utf8_str, size_needed, NULL, NULL);
size_t len = strlen(utf8_str);
char* result = (char*)malloc((3 * len + 1) * sizeof(char));
size_t index = 0;
for (size_t i = 0; i < len; i++) {
char c = utf8_str[i];
if (isalnum(c) || c == '-' || c == '_' || c == '.' || c == '~' || c == '/') {
result[index++] = c;
}
else {
sprintf(&result[index], "%%%02X", (uint8_t)c);
index += 3;
}
}
result[index] = '\0';
free(wide_str);
free(utf8_str);
return result;
}
int main(int argc, char* argv[]) {
if (argc!=2){
printf("Usage: urlquote.exe <string>\n\n");
return 1;
}
char* quote_str = urlquote(argv[1]);
printf("%s\n", quote_str);
free(quote_str);
return 0;
}运行的结果将与 Linux 环境保持一致了,而且与 Python 的 quote 函数相媲美了。
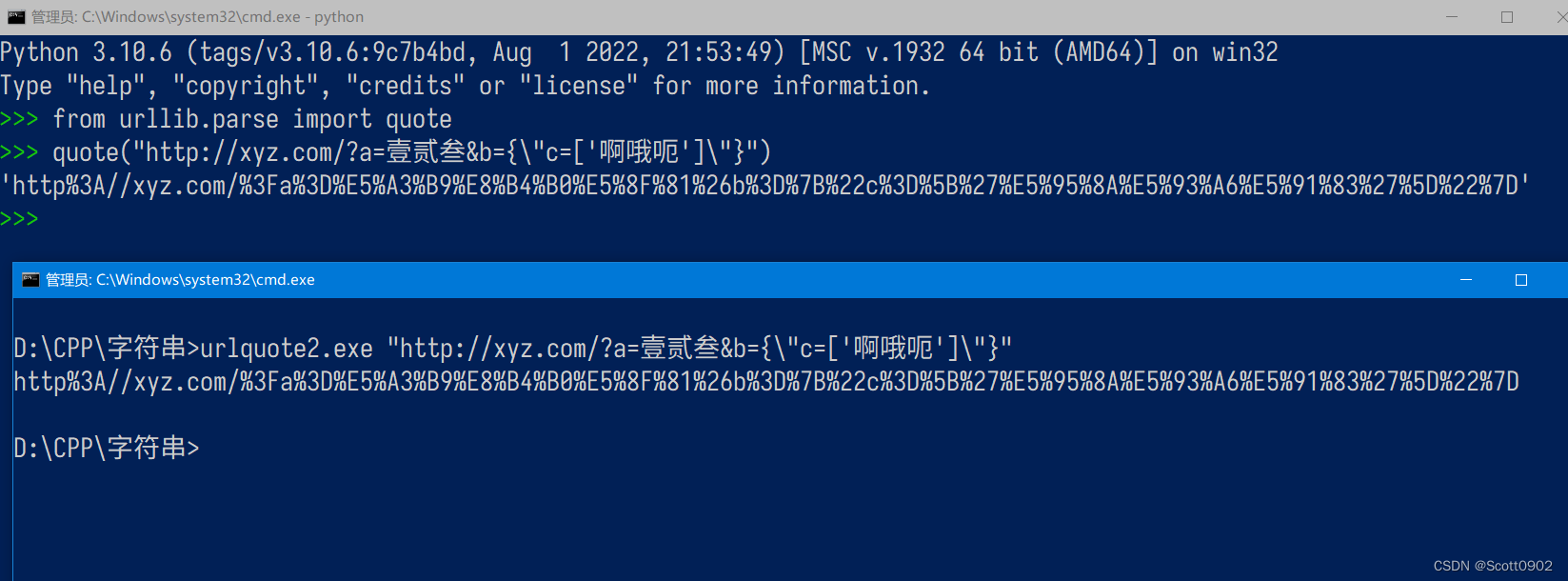
输入参数:"http://xyz.com/?a=壹贰叁&b={\"c=['啊哦呃']\"}"
Python的quote结果:
http%3A//xyz.com/%3Fa%3D%E5%A3%B9%E8%B4%B0%E5%8F%81%26b%3D%7B%22c%3D%5B%27%E5%95%8A%E5%93%A6%E5%91%83%27%5D%22%7D
C在Windows命令行运行结果:
http%3A//xyz.com/%3Fa%3D%E5%A3%B9%E8%B4%B0%E5%8F%81%26b%3D%7B%22c%3D%5B%27%E5%95%8A%E5%93%A6%E5%91%83%27%5D%22%7D