1.下载及安装指南、参考文档、模型下载
github上链接:
https://github.com/iperov/DeepFaceLab
软件版本链接:
https://mega.nz/folder/Po0nGQrA#dbbttiNWojCt8jzD4xYaPw
指导文档:https://mrdeepfakes.com/forums/threads/guide-deepfacelab-2-0-guide.3886/
预训练模型:https://mrdeepfakes.com/forums/forums/trained-models.34/
软件说明:前两个是AMD显卡版本,后两个一个是30系列显卡,一个是20系列显卡版本。

2.使用说明
直接双击解压安装即可,里面包含了三部分,其中_internal 源码,不要动。
workspace,data_dst 目标视频的文件操作目录,data_src原视频的操作目录,model模型文件存放目录
bat启动文件
2.1 bat操作指南
官方文档给出详细介绍
指导文档:https://mrdeepfakes.com/forums/threads/guide-deepfacelab-2-0-guide.3886/
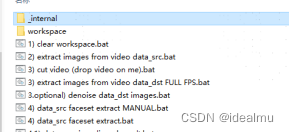
具体需要使用到的步骤
2)extract images from video data_src.bat 将源视频转换成图片
3)extract images from video data_dst FULL FPS.bat 将目标视频转图片
4)data_src faceset extract.bat 裁剪src人脸保存在data_src/aligned中
4.1) data_src view aligned result.bat 查看裁剪人脸的结果,手动删除非正脸、模糊的人脸素材
5) data_dst faceset extract.bat 裁剪dst的人脸,并保存在data_dst/aligned中
5.1) data_dst view aligned results.bat 查看裁剪人脸的结果
6) train SAEHD.batt 训练模型,一般使用这个模型
7) merge SAEHD.bat 合成结果,加载data_dst中的每一帧图片并结合data_dst/aligned中的结果去换脸,会生成一个merged和merged_mask文件在data_dst中
8)merged to mp4.bat 读取dst.mp4中的音轨信息和merged中的图片合成一个MP4文件
3 模型训练
模型选择:一般选择liae系列模型,liae系列模型更容易训练、占用显存小、速度快、光影效果要优于DF模型。
分辨率选择:分辨率越大越难把脸训练清楚。一般192~256的分辨率就够用了,除非对细节要求很高,不在乎时间成本的训练可以去使用更高分辨率的模型。
F, WF选择:F脸不包含额头部分,WF脸包含额头部分
训练参数说明:
Autobackup every N hour ( 0…24 ?:help ):每多少个小时备份一下模型
Write preview history ( y/n ?:help ) : n,不用保存,每次保存模型的时候会保存一张结果图片
Target iteration:0,0是一直训练,想停止的时候直接ctrl + c停止会自动保存一次模型
Flip SRC faces randomly ( y/n ?:help ) :如果DST的素材和SRC中素材有些脸上的色彩和光照是反的话,可以使能这个SRC镜像,就是将SRC素材随机镜像翻转
Flip DST faces randomly ( y/n ?:help ) : n,DST素材随机镜像,这个一般不需要开
Batch_size ( ?:help ) :训练批大小,如果报显存溢出降低其大小
Eyes and mouth priority ( y/n ?:help ) :眼睛嘴巴优先训练,如果时间允许,可以前期开,后期关;时间不允许,一直开着训练即可
Uniform yaw distribution of samples ( y/n ?:help ) :有助于训练侧脸,建议开启训练
Blur out mask ( y/n ?:help ) :降低了对dst背景的学习,更加关注mask区域的学习,结合
background style power 使用以获得更好的dst背景效果,如果觉得background style power参数太大,学得更像dst的脸可以开启并调小background style power参数。
Place models and optimizer on GPU ( y/n ?:help ) :y, 开启。
Use AdaBelief optimizer? ( y/n ?:help ) :y, 开启。
Use learning rate dropout ( n/y/cpu ?:help ) :y,开启。
Enable random warp of samples ( y/n ?:help ) :随机扭曲素材,使训练更加泛化,前期开,后期关;可一直开。
Random hue/saturation/light intensity ( 0.0 … 0.3 ?:help ) :这个是对SRC数据集根据SRC数据的颜色、光线、饱和度等略微平均了一下SRC素材,进行的一个随机操作,开不开影响不大,主要减少了SRC素材的闪烁,在一开始的时候选素材就要尽量避免SRC色彩过大的不一致,不然会造成闪烁,0.1以下即可。
GAN power ( 0.0 … 5.0 ?:help ) : GAN,一般不必要,这个选项要在基本模型训练好之后,关闭
Enable random warp of samples ( y/n ?:help ) 并且使能Use learning rate dropout ( n/y/cpu ?:help )后开启,为了获得更详细锐利的面部结果。如果要用的话选择0.01即可。
GAN训练也需要花很长时间。
GAN patch size ( 3-640 ?:help ) :提高GAN的训练质量,占显存,默认使用1/8的分辨率值。
GAN dimensions ( 4-512 ?:help ):GAN网络的维度,维度越高,GAN质量越好,使用默认值16即可。
Face style power ( 0.0…100.0 ?:help ) : 和Background style power ( 0.0…100.0 ?:help ) :控制图像的人脸部分(FSP)或背景部分(BSP)的风格转移,用于将目标/目的地脸部(data_dst)的颜色信息转移到最终预测的脸部,从而改善照明和颜色匹配,但高值可能会导致预测的脸部看起来不像您的源脸部,更像您的目标脸部。这个一定程度上可以匹配dst上的光影和面部一些特征,但是值越高可能结果越差,根据实际情况调整这个值。建议FSP 0.01一下,BSP 0.1一下。
Color transfer for src faceset ( none/rct/lct/mkl/idt/sot ?:help ) : 这个是转移dst面部的一些颜色到src上,使src面部色彩更接近dst。这里有好几种不同的色彩转移算法,一般使用rct。在src色彩变换不明显,dst色彩变换明显的时候开启。其他时候可以不用开启。这个是训练时候增加src的数据集,参考文档中有关于这几种色彩迁移算法的介绍。
Enable gradient clipping ( y/n ?:help ) :一般都有预训练模型了,就不需要重新训练一个预训练模型,关必即可。
4 合成参数和使用
Table 键可以切换换脸图片和一下合成参数使用说明
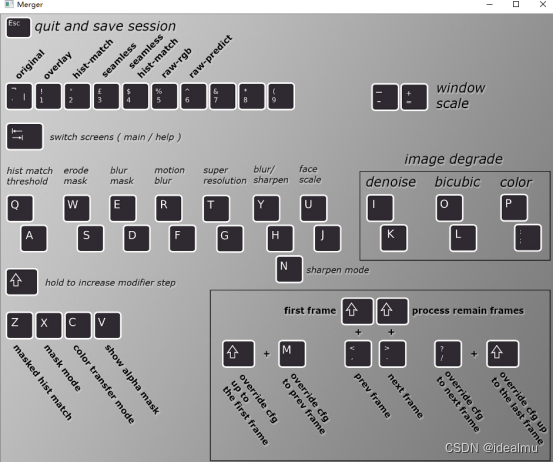
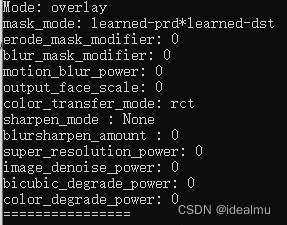
Mode: 对应,1-6,~是原来的脸,1是换后的脸,23456是根据dst的脸做了一些算法匹配,通常只用1,可以手动调一下看一下哪个合适;
Mask_mode: 对应x键,切换mask模式,一般默认的learned-prd*learned-dst效果好一些,可以手动调一下哪个合适;
Erode_mask_modifier: 对应W/S,增加会使换脸的部分向里收缩,这个值比较重要,根据换的结果调整;0~100来回尝试;
Blur_mask_modifier: 对应E/D, 边缘模糊,让换脸的边缘更加自然,50~150左右来回尝试
Motion_blur_power: 对应R/F, 运动模糊,基本不用;
Out_face_scale: 对应U/J, 放大缩小脸,基本不用;
Color_transfer_mode: 对应C, 注意这个使训练那个使没关系的,即使训练没有使能CT,这里仍然能够使用CT中的算法,推荐rct。慎用sot-m,sot-m占用很多资源,使合成速度变得很慢;
Sharpen_mode: 对应N,锐化模式选择,基本不用;
Blursharpen_amount: 锐化模糊的选择,可以用来模糊,必须Sharpen_mode不是None才起作用,基本不用;
Super_resolution_power: 超级分辨率,不要太高,太高看起来不真实,根据图片分辨率尝试选择,可以在50以下尝试;
后三个用来降低图片质量的,基本用不到。