前言:
这篇文章将分为两个部分,第一个部分主要是ChatGPT的一些应用,以及GPT4的一些插件推荐,第二个部分是OpenAI的api介绍。
ChatGPT应用部分:
OpenAI 的 GPT(生成式预训练变压器)模型经过训练可以理解自然语言和代码。GPT 提供文本输出来响应其输入。GPT 的输入也称为“提示词”。设计提示词本质上就是如何“编程”GPT 模型,通常是通过提供说明或一些如何成功完成任务的示例。 GPT模型介绍:
| MODELS |
DESCRIPTION |
| GPT-4 |
语言模型,GPT-3.5的改进,可以理解并处理自然语言,拥有较强的逻辑推理能力,与创造能力 |
| GPT-3.5 |
语言模型,GPT-3的改进,可以理解并处理自然语言,是目前所有模型中响应速度最快的模型,具有一定的逻辑推理能力。 |
| DALL·E |
图像生成模型,可以在自然语言提示下生成和编辑图像。 |
| Whisper |
语音识别模型,可以将音频转换为文本。 |
| Embeddings |
一种嵌入模型,用于分析文本之间的相关性,适用于搜索,分类,聚合,推荐等功能 |
| Moderation |
用于检测敏感词,这是通过GPT模型微调后的模型,可以检测出一些暴力血腥等话题,根据检测到的内容进行屏蔽等操作。 |
| GPT-3 |
语言模型,现在基本处于弃用状态,但是从它本身衍生出来的davinci、curie、ada、babbage这四个衍生品是目前唯一的可微调模型。3.5和4的微调官方说是23年下半年的某一个月具体时间还不确定。(这四个可微调模型本质还是GPT-3模型) |
GPT的语言模型不过多介绍,可以直接在ChatGPT官网上用到,而图像生成模型可以看前面的AI绘画功能模块有介绍到。语言识别模型,稍微用过几次,要说它非常厉害的话个人感觉也不至于,只能说中规中矩吧,这个模型是开源出来的,所以可以把模型下载下来,然后网上有许多人弄出了交互器可以直接用,具体操作可以看这篇文章:
whisper离线安装教程 | 存内网环境下部署whisper - lukeewin的博客openai开源了whisper,这是一个支持多语言的自动语音识别项目,其中对普通话的支持虽说不是最好的,但是在众多开源的语音识别中,对中文的识别还是蛮不错的。在联网的机器上部署whisper很简单,但是在一些对安全性要求很高的企业内部想要在离线的状态下安装部署whisper,那么将会遇到很多问题,所以这次记录一下我如何在离线状态下安装成功的。最后希望这篇文章能够帮助到你。![]() https://blog.lukeewin.top/archives/openai-whisper-offline-installtips:这种模型对算力还是有点要求的,虽然相比于图片生成模型的算力要求会要小很多,但是显卡太差还是不行的。
https://blog.lukeewin.top/archives/openai-whisper-offline-installtips:这种模型对算力还是有点要求的,虽然相比于图片生成模型的算力要求会要小很多,但是显卡太差还是不行的。
关于嵌入模型暂时还没用到就不介绍了,感兴趣可以查阅openai的官方文档:
ChatGPT推出的插件功能:
ChatGPT官网提供的模型是GPT3.5与GPT4。3.5的模型就不过多介绍了,主要介绍一下模型4的一些新功能:
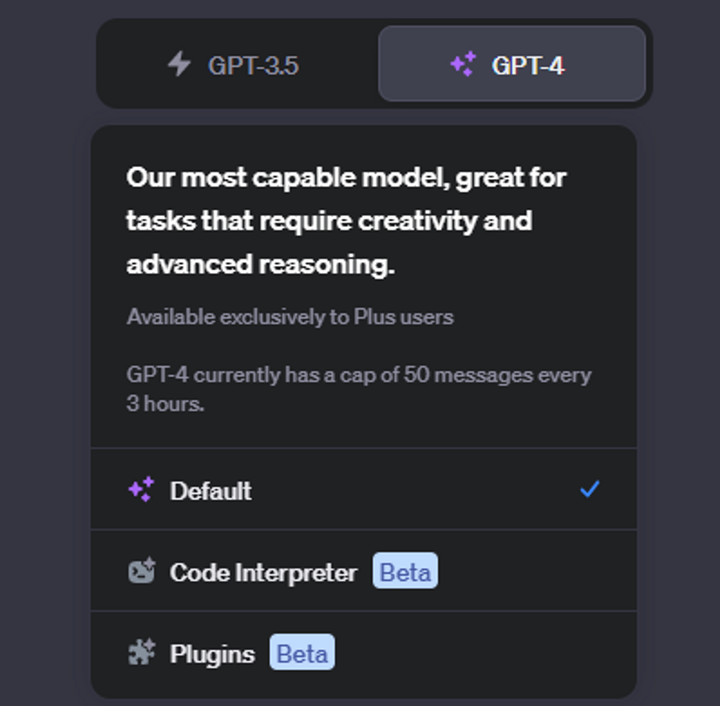
plus会员现在从每3小时只能提问25次提升到了每3小时可以提问50次,这已经基本可以满足日常的使用了。现在官方推出的两个功能Code Interpreter和Plugins。
Code Interpreter这个功能可以说是非常强大,可以吧它理解为一个python沙箱,它支持用户上传文件,然后根据用户的指示生成对应的python代码去对文件进行处理,目前我个人挖掘出来的功能是图表制作,文件类型转换,文件对比,代码修改等。一次可上传的文件大小最好小于100M,但网上也有上传超过100M的文件也能正常运行。
最后是插件功能,这个功能是官方提供给一些开发者自行开发插件的权限,让开发者可以根据一些对应的需求开发出对应的插件,当然这个插件开发权限需要申请,感觉如果不是公司申请的话审核就会巨慢,我以及申请了两个月了还是一点信都没有(撰写此部分时是23年8月10日)。目前这个功能里面已经有了八百余个插件,但其实有很多插件只是以提供服务的名义,借助ChatGPT的流量给自己公司的产品打广告而已。实际体验下来并不好,所以这里我主要推荐一些我自己会用到,并且确实还可以的插件:

-
webpilot:搜索引擎,可以链接互联网,勉强弥补了GPT不能连接互联网的缺点
-
wolfram:图表生成,数学计算,可以理解为人工智能加wolfram,理科生福音。
-
AI Tool Hunt:AI工具推荐,可以让它推荐一些好用的ai工具。
-
tutory:学习导师,告诉它要学什么东西,预计多久学完,它会跟你制定计划,然后按照计划找它学习就行,这个插件可以让你比较快的对某方面的知识有一个较全面的了解。
-
speak:语言学习
OPENAI API接口调用:
官方文档链接:https://platform.openai.com/docs/introduction/overview
要调用OpenAI的接口首先需要有API key,注册好openai的账号后,可以在官网的API keys处创建一个新的api key。(key的格式为:sk-VGhpcyBrZXkgaXMgZmFrZS5KdXN0IHVzaW5nIHRlc3Qh)如果是新账号前三个月每个月会有5美金的免费额度。

官方提供的对外接口主要分为如下五个模块:
-
聊天:可以应用于一些自然语言的对话场景。
-
图像:应用于图像生成、图像编辑、根据已有图像生成变体。
-
嵌入:应用于一些软件的搜索引擎,notion的搜索就用到了这部分的API。
-
语言:可以根据音频转文字,或者实时翻译等。
-
微调:根据自己的需求对模型进一步训练。
下面以聊天功能为例,简单介绍API的使用。
聊天API的调用办法:
openai支持直接用命令行进行api调用(前提是给对应网址做好代理)。tips:同时官方也推出了python和nodejs库,安装库的命令为:
Python:pip install openai
Node.js:npm install openai
For Example,下面就是一段完整的请求信息:
curl <https://api.openai.com/v1/chat/completions> \\
-H "Content-Type: application/json" \\
-H "Authorization: Bearer sk-VGhpcyBrZXkgaXMgZmFrZS5KdXN0IHVzaW5nIHRlc3Qh" \\
-d '{
"model": "gpt-4-0613",
"messages": [{"role": "user", "content": "你好,请用中文回复我"}],
"temperature": 0.7
}'
第一行:首先curl后面跟的地址就是目标服务器的地址。语言模型的服务器地址都是这个,至于绘画等其他模型的地址可以去上面提供的官方文档地址查看。当然如果是使用openai提供的python或者nodejs库就不需要管地址是哪个直接调用官方提供的对应方法就行。
第二行的“-H”指定了请求的内容类型为JSON格式。它告诉服务器请求的主体部分是以JSON格式编码的数据。这一行不用管一般不用变。
第三行是用来提供密钥的一行,sk开头的就是密钥,把自己的密钥换上去就行。
前面三行没啥好说的就是一个格式,从第四行开始就是提供给服务器的一些参数了:
-
model:指定访问的gpt模型型号,如果不知道目前可以用哪些模型可以输入如下指令:
curl <https://api.openai.com/v1/models> \\ -H "Authorization: Bearer $OPENAI_API_KEY"
模型之间的差异可以查阅官方文档
-
messages:这个参数作为主要的输入,总共包含两个参数:
-
rule:表示content中的内容是何种对象发起的,总共分为三种对象:system、user、assistant。system对象用于规范助手的行为,比如system后面跟上“你是一个专业的心理医生”。当服务器接收到system对象的消息时不会回复消息,但是在之后的对话中会按照system规范的行为进行回复这个对象是可选的,在一场对话中不一定要用该对象。user对象也就是用户对象,表示后面的内容是用户提出的问题,服务器再接收到user对象的问题后便会以assistant对象的身份对问题进行回答。所以一种一场对话一般是一条system对象之后就是来回一次或多次的user对象和assistant对象问答。
-
content:这个参数里面就是我们需要像服务器发送的问题。
-
-
temperature:这个变量控制的是ai回复的随机性,这个参数的值在0到1之间,当参数高于 0 时,每次提交相同的提示都会导致不同的完成结果。
参数差不多介绍网络尝试在终端上运行这段命令,这里我租了一台腾讯云的境外服务器,所以不用设置流量代理:
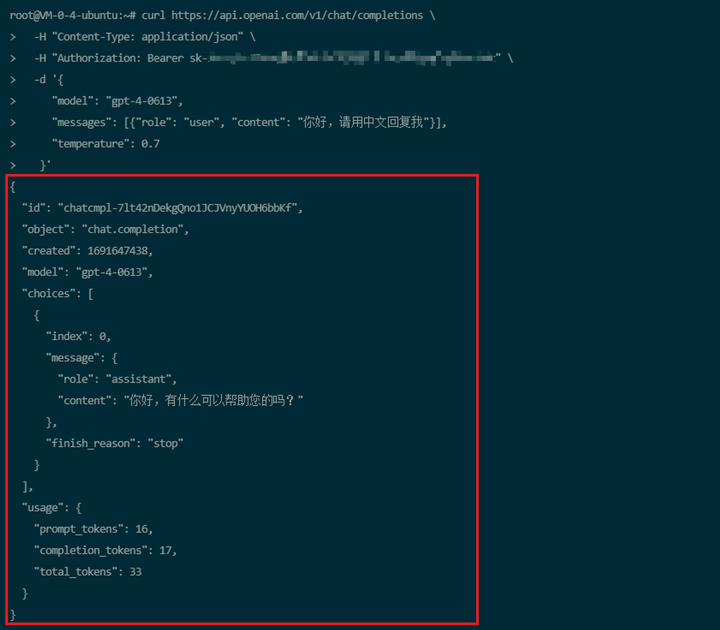
上图红框中的内容就是服务器返回的内容,可以看到同样是content参数中返回服务器的回答。在返回的内容中还有一个参数需要注意,就是下方的usage。这涉及到一个问题总共消耗了多少token,而token和扣费是挂钩的。
这里补充一下token计费有关的内容:首先了解一下token是如何计算的,对于人工智能模型来说当它接收到一段自然语言后,会做一个基本且关键的步骤就是对输入的文本进行拆分,这一过程被称为“分词”。在分词过程中,一段连续的自然语言文本会被划分为一系列更小的、有意义的单元,如词或词组。这些单元为AI提供了一个更加结构化的方式来理解和处理文本。
在OpenAI里'token' 就是指代一个词、子词或字符。继续看一下示例:
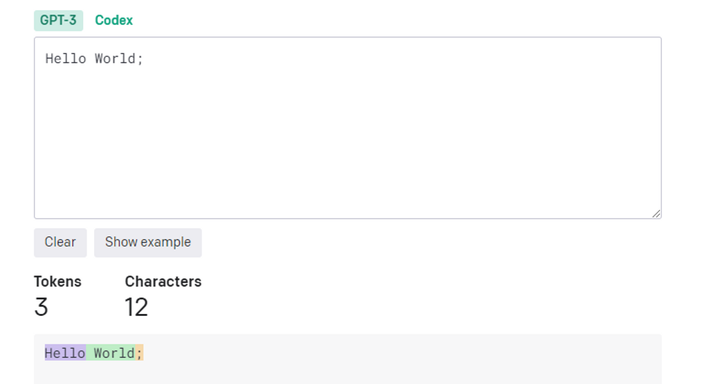
上图是openai官方的分词器可以看到Hello World;这句话被拆分成了三个token。再看看中文的拆分情况:

可以看到一个汉字会被视为两个token,这是由于中文不会像英文一样用空格来对词做分割,所以在分词过程中只能是按照一个汉字一个汉字的拆分。当然有些ai训练时训练频率较高的汉字可能也会只占用一个Token,但有些十分生僻的汉字会需要三个token。
了解了token的计算观察上面那段消息用到的token数量:
usage":{
"prompt_tokens":16,
"completion_tokens":17,
"total tokens":33
}
-
prompt_tokens:表示我们的提示词所占token数,也就是你好,请用中文回复我占用了16个Token。
-
completion_tokens:表示服务器的回复所占token数,也就是你好,有什么可以帮助您的吗?占用了17个token。
-
最后总和为33个token,openai的计费是根据输入输出分别计算金额。
最后看一下token的价格表:(数据获取时间为2023年8月10日)
| Model |
Input |
Output |
| GPT-4-8K |
$0.03 / 1K tokens |
$0.06 / 1K tokens |
| GPT-4-32K |
$0.06 / 1K tokens |
$0.12 / 1K tokens |
| GPT-3.5-Turbo-4k |
$0.0015 / 1K tokens |
$0.002 / 1K tokens |
| GPT-3.5-Turbo-16K |
$0.003 / 1K tokens |
$0.004 / 1K tokens |
模型后面经常会看到"4K","16K","32K"这样的字样,这些通常是指模型的"词汇表"(Vocabulary)大小。
词汇表是模型在处理文本时用到的所有可能的单词或符号的集合。
这里的"K"就是千,所以"4K"就是4000,"16K"就是16000。这意味着,如果一个模型的词汇表大小是"32K",那么这个模型在处理文本时可以识别和处理32000种不同的单词或符号。
词汇表的大小对于模型的性能和效率有重要的影响。如果词汇表太小,模型可能无法处理一些罕见的单词。反之,如果词汇表太大,模型可能会变得非常大和慢,因为它需要更多的参数来处理更多的单词。
更多定价详情,可以去官网的定价表查询:Pricing
以上就是openai接口调用的全部内容。