大家好,我是全栈小5,欢迎阅读文章!
此篇是【话题达人】序列文章,这一次的话题是《如何解决大模型的幻觉问题》


大模型
先来了解基本术语和缩写全称,比如LLM。
LLM是Large Language Model的缩写,指的是一种大规模语言模型,可以用来为许多自然语言处理(Natural Language Processing)任务提供先验知识。
大模型的LLM是指具有大量参数和计算能力,可以处理大规模数据集的语言模型。
最近,像GPT-3、T5等大规模的预训练语言模型已被广泛研究和应用,可以用于NLP领域的文本生成、QA、文本分类等任务。
模型幻觉
我们这里用了一个幻觉的词,实际上就是LLM输出的内容不准确或者误导人的意思,模型还会自己乱编一些代码和不存在的类库,让人雨里雾里的。
所以,要了解大模型出现幻觉问题,我觉得应该要从大模型本什么训练原则以及本身特点分析。
模型预训练
在预训练阶段,大模型使用一个庞大的文本数据集进行自我监督学习。
此过程中,模型通过尝试预测一段文本的下一个词或通过掩码预测被隐藏的词来学习语言的统计规律和语义关系。
从上面一段话我们可以挑出几个关键点【庞大文本数据集】【统计规律】【语义关系】
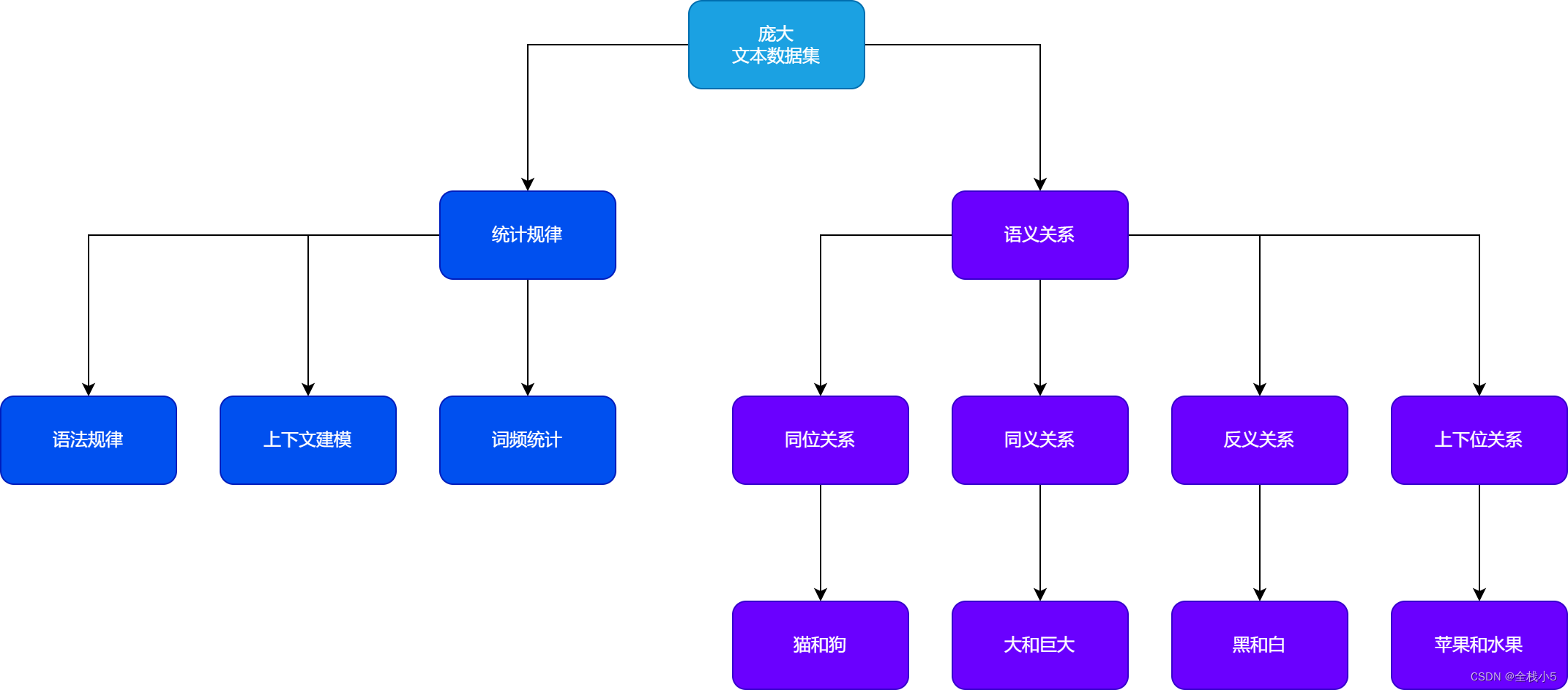
庞大文本数据集
也就是说,如果数据集量不足,那么可能是会影响到最终输出的结果,这样在众多用户者在使用过程中就会出现个别答案有偏差。
我个人觉得数据集,也许在庞大数据集基础上,可能也要对数据进行质量上提升,这样输出的结果质量也同样会有所提升。如何解决质量问题,也许人工干预是要的。
语义关系
语义关系是指词语、短语或句子之间的语义联系或关联。
它涉及到词义、上下文和逻辑等方面,用于描述词与词、短语与短语、句子与句子之间的意义关系。
以下是几个常见的语义关系的例子:
-
同义关系
指两个词或短语具有相同或相近的意义。例如,“大"和"巨大”、"去"和"离开"之间存在同义关系。 -
反义关系
指两个词或短语具有相反的意义。例如,“黑"和"白”、"高"和"矮"之间存在反义关系。 -
上下位关系
指两个词或短语之间的层次关系,其中一个词或短语是另一个的更具体或更一般的概念。例如,"狗"是"动物"的一种,"苹果"是"水果"的一种。 -
同位关系
指两个词或短语在语义上相互平行,表示同一类别或属于同一范畴。例如,"猫"和"狗"之间存在同位关系。 -
部分-整体关系
指两个词或短语之间表示部分和整体之间的关系。例如,"轮胎"和"汽车"之间存在部分-整体关系。
模型微调
微调即是使用特定任务和少量有标签数据对预先训练好的模型进行进一步训练的过程,以提高其在特定任务上的表现。
在上面概念基础可以知道两个关键信息【特定任务】【少量标签数据】
特定任务
文本分类、命名实体识别、语义角色标注、机器翻译等
少量标签数据
人工标注的情感分析数据、互联网上的文本数据、包括带有正向或负向情感标签的文本
如何解决
个人认为,如何有效解决,还是需要有一个分布式加集中式数据,开放更多源码和社区,集大家之所能。
普遍方法
- 正则化方法
去掉不重要的特征,避免模型过于复杂 - 数据增强
通过多种方式,组合成更多的训练样本 - 集成学习
总结:大模型出现的幻觉,我觉得不可避免,如何解决我觉得仍然离不开训练,不断加强和深度学习,出现错误的概率会越来越少,大模型训练通过人工干预微调,可以想象成它就是一个孩子需要不断有人教它和自我学习。