大家好,我是卖萌酱。
想象一下,如果今天让你用下面的“打孔纸带”来编程,你能接受吗?

计算机编程最早的形式是使用机器语言,也就是用二进制代码直接控制计算机硬件的每个操作。
汇编语言使用助记符来替代二进制的指令,能够让编程工作变得容易一些,但仍然要求对硬件设备的理解。
高级语言则提供了更高级的抽象,让人类可以使用近似自然语言的语法编写程序,不那么依赖底层硬件的知识,同时也能处理更复杂的编程任务。在高级语言中,编程语言又会分为“三六九等”,例如“PHP是世界上最好的编程语言”(手动狗头)。
然而,无论编程语言再“高级”,归根结底就是人与机器沟通的桥梁。而在人类世界,当两个人沟通的时候,最希望的就是对方跟自己用的是相同的语言,这样的沟通成本是最低的,也不容易产生误会和信息损失。
因此,在卖萌酱看来,随着AI的发展,未来人与机器沟通的最佳形式注定是原生自然语言。在未来,高级编程语言可能会像打孔机一样,被放进历史博物馆。
昨天,卖萌酱在参加完百度WAVE SUMMIT+深度学习开发者大会后,更加坚信了这个观点。
一、Comate AutoWork问世,用嘴编程的时代真的来了
百度在大会上正式发布了Comate AutoWork,话不多说,直接看视频:
,时长01:45
有没有被惊艳到?
你尽管把需求文档写好,剩下的由Comate自主思考、拆解需求并执行任务,完成代码的生成。

卖萌酱相信,在不远的未来,甚至代码生成这个环节都不必再暴露给程序员,Comate交付的可能直接就是需求的产物了,这是「用嘴编程」的终极形态。
而在当下,尽管AI的发展水平还做不到用自然语言替代高级编程语言,但显然自然语言未来已经开始持续往原本要100%编程语言实现的场景渗透了。
看到这里,你可能会想,我用GPT-4不也能实现这个过程吗?
暂且不说前阵子曝出来的“GPT-4”变懒变笨事件,如果你真的上手用过百度Comate,你就会发现,一个专门为编程场景设计的AI Agent驱动的IDE,体验和生产力相比一个单纯的大模型炸裂太多了!
除了上面视频中show出来的最具颠覆性的“用嘴编程、直接将需求文档变成软件交付”外,这里再简单列举几个Comate里面卖萌酱觉得特别常用的功能:
-
解释代码,再也不怕前人留下的“屎山”了:
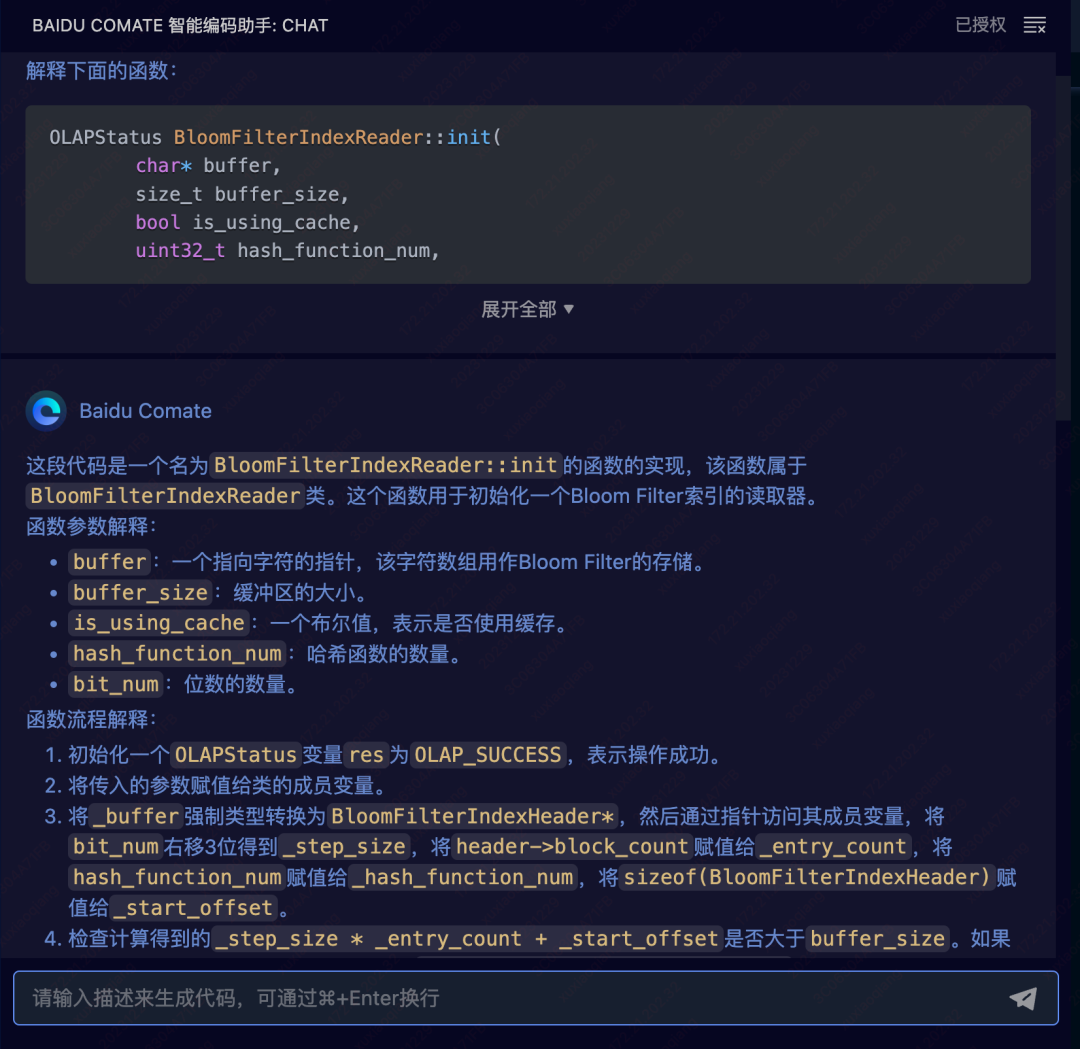
-
智能补全:这可不是简单的语法补全,而是深入业务逻辑的智能补全:
-
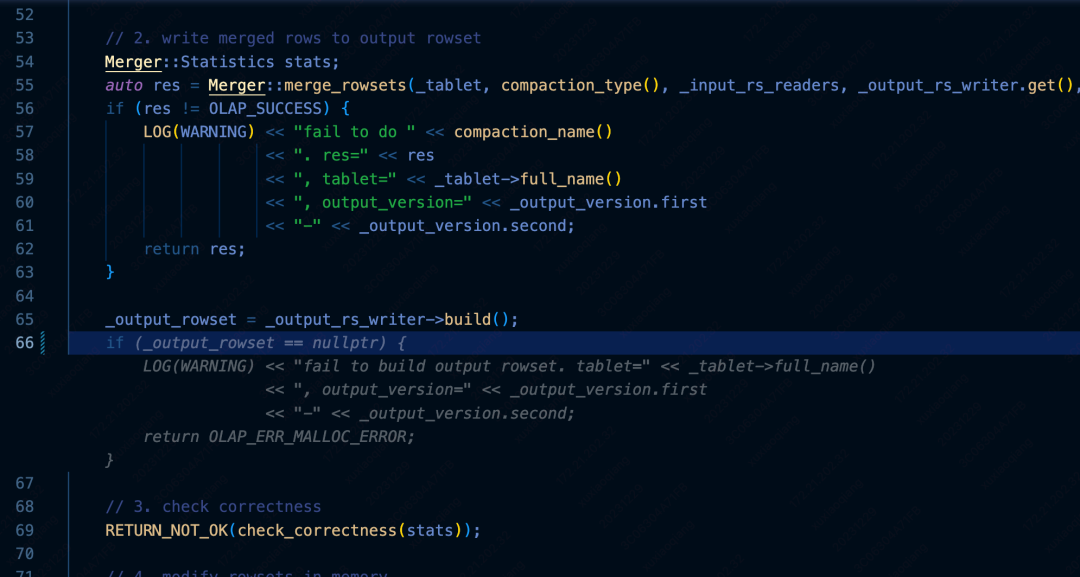
代码优化:Comate可以对代码进行优化,规避难以发现的潜在代码漏洞,让代码更健壮,业务更稳定。
总之,可以用一张图来描述Comate AutoWork:

百度Comate AutoWork渗透到了研发的全链路,开发者仅需明确目标和需求,后续研发过程例如需求拆解、制定计划、生成代码、调试运行等步骤,不仅可以顺序执行,而且中间的任何一个步骤,都可以单独拆出来无缝集成到开发者现有的代码库/工作流中。
你可能会怀疑,这种新型的软件开发范式,会带来多少效率提升呢?
以下是一个很高频的软件需求——体验券/优惠券抽奖转盘。
以往要从头开发这样的一个需求,至少要搭进去一个资深程序员一天甚至数天时间。
如果用百度Comate Autowork来开发,这个答案是——2分钟!
开发效率提升数百上千倍,真的不是噱头,而是我们所处的大模型时代正在真实发生的事情。拥抱大模型时代,你就能成为享受到这份时代红利的第一批开发者。
另外百度在昨天WAVE SUMMIT+大会上正式宣布,开放Comate AutoWork邀测。开发者可以直接在Comate官⽹申请试⽤。
Comate AutoWdork传送门:
https://comate.baidu.com/
二、Comate AutoWork背后的技术原理
Comate AutoWork这么厉害,背后技术是如何实现的呢?
我们都知道对当下的大模型而言,仅仅做单独每项的代码补全、代码生成已经不是个难事了,但是这远远支撑不起来 AutoWork在研发全链路的惊艳表现。
Comate AutoWork惊艳的背后正是得益于 ——⽂⼼大模型思维链能力+RAG技术的代码智能检索技术。
基于⽂⼼大模型超强的思维链能力, AutoWork 能够像一个智能体一样来思考和执行任务,能够听懂人的需求,然后顺序执行需求拆解、制定计划、生成代码、调试运行等步骤,因为AutoWork 能够分钟级拿下开发一个优惠券抽奖转盘的程序就不足为奇了。
但光有智能体的思维链能力还不够,我们都知道在这一代技术下,目前的大语言模型普遍存在幻觉,这个问题对编程而言简直是致命的,毕竟程序执行代码,容错率可是0,别说一整行代码,哪怕是一个字母、一个冒号都不能出错。

而为了保证代码不会出错,这背后就少不了RAG智能代码检索技术了,
RAG检索增强生成(Retrieval Augmented Generation)技术简单来讲就是将用户输入的知识库信息补充到大语言模型中的过程。然后,大语言模型就可以在用户提问时,检索这些知识库信息来增强其生成的回答。
而Comate 基于RAG技术,专门为编程领域设计研发了RAG智能代码检索技术,能够让用户从代码库中检索可能回答问题的最相关内容,从而解决LLM的幻觉等问题。
此外,用过Comate之后,你会发现它的响应非常快速,在这背后,则是百度飞桨对文心大模型推理效率提升的一系列黑科技了。本次WAVE SUMMIT+大会上同样不例外。例如多Stream的并行算子调度,有效减少硬件等待的耗时和运行时的阻塞;在自定义算子和自定义融合策略方面做了大幅优化等。持续的大模型推理效率优化是Comate为开发者提供丝滑开发体验的后盾保障。
三、Comate已席卷8000+家企业
值得一提的是,百度在10月份推出了Comate SaaS版服务后,目前已被8000家左右的企业使用。
而且百度还全新发布了Comate的开放定制能力,企业可以根据个性化需求,定制智能研发能力。通过对接私域知识让Comate更理解业务,也可以用自有代码库来对模型精调,打造更适合每家企业自己的智能代码助手。
如今,Comate还可通过插件对接第三能力,首批支持包括Gitee/Github/Gitlab,Postman,Jira等。

顺带一提,关于Comate背后的核心技术之一——文心一言,百度CTO 王海峰在大会现场披露,文心一言用户规模已突破1亿!

这个数字是自8月31日文心一言获准开放对公众提供服务以来取得的成绩,仅仅用了四个月,这也是国内第一家用户规模超过1亿用户的大模型产品。
四、百度开启AI原生应用时代
在Comate这次重大升级和文心一言1亿+用户规模突破的背后,是百度对AI坚定不移的研发投入和对AI原生应用的重视。
百度自2019年起就深耕预训练模型研发,发布了文心大模型 1.0。经过四年积累,百度于今年3月在全球科技大厂中率先发布了知识增强大语言模型文心一言。10月份,文心一言的基础模型升级到4.0,理解、生成、逻辑和记忆四大人工智能基础能力全面提升。且文心大模型4.0过去两个多月整体效果又提升了32%。文心大模型底座能力的不断提升,是如今能强力加持到开发工具链上的重要原因。
而早在今年10月的百度世界大会上,伴随着文心4.0的发布,百度推出了一系列大模型赋能的AI原生应用。百度创始人、董事长兼CEO李彦宏在大会中预言:“我们将进入一个AI原生的时代。”

到了12月份,李彦宏在一场大会上再次强调:“大模型时代来临,真正的价值在于原生应用,我们要去卷 AI 原生应用,把这个做出来了才有价值。不要再卷大模型进展了,这对大多数人来说不是机会。”
“大模型带来的智能涌现,是开发AI原生应用的基础。”文心大模型在4.0时代综合能力的进化,是为未来一个智能时代的到来奠基。除了文心大模型4.0以外,百度还推出了基于基础模型带来的搜索、GBI、如流、文库、网盘、地图等十余款应用。这些基于基础模型的 AI 原生应用,以及昨天新发布的两分钟就能开发一个新程序的黑科技Comate AutoWork 无疑是百度占据AI原生时代高地的证明。
最后,则是百度深知服务好开发者的重要性——得开发者得天下。
AI原生应用的时代,注定将从AI原生的Comate起步,被专注AI原生的新时代开发者开启。
