梳理Java并发编程相关的面试题,主要参考《JAVA并发编程实战》(Brian Goetz, Joshua Bloch, David Holmes, Tim Peierls, Joseph Bowbeer, Doug Lea 著, 韩锴, 方妙 译)一书,其余部分整合网络相关内容。注意,关于Java基础相关的面试题可以参考Java基础常见面试题总结一文,JVM相关的面试题可以参考Java虚拟机常见面试题总结。
Java为什么要支持并发编程(多线程编程)
多线程具有如下优点:
(1)线程可以有效的降低程序的开发和维护成本,同时提升复杂程序的性能。(还需辩证的看)
(2)发挥计算机多处理器的强大能力(主要特性)
(3)建模的简单性,可以将复杂并且异步的工作流进一步分解为一组简单并且同步的工作流,每个工作流在一个单独的线程运行,并且在特定的同步位置进行交互。(不敢苟同)
(4)异步事件的简化处理(多线程处理——并不一定有优势)
(5)响应更灵敏的用户界面(多线程的GUI不合适,会增加系统的复杂度。但是单线程GUI+长任务处理机制可以提供更灵敏的交互)
但是,也要注意多个线程并发执行时,存在以下问题:安全性问题、活跃性问题、性能问题。
(1)安全性
线程安全问题
(2)活跃性问题
活跃性关注“某件正确的事情最终会发生”。当某个操作无法继续执行下去时,就会发生活跃性问题。如死锁、饥饿、活锁等,均会带来活跃性问题。
(3)性能问题
线程同步带来的性能问题、线程切换带来的性能问题
说一下Java内存模型
Java 内存模型(Java Memeory Model,JMM)的目标是屏蔽各种硬件和操作系统的内存访问差异,以实现多平台场景下达到一致的内存访问效果。在JDK 1.5以后,Java内存模型逐渐成熟和完善。
Java内存模型对外提供的接口还是程序中变量的访问规则,即虚拟机将变量存储到内存,以及从内存中获取变量。注意,这里的变量仅指非线程私有变量(不包括局部变量和方法参数),包括实例字段、静态字段和构成数组对象的元素。
Java内存模型规定所有的变量(实例字段、静态字段、构成数组对象的元素,不包括局部变量和方法参数)都存储在主内存(Main Memory)中。每个线程则拥有自己的工作内存(Working Memory)。在线程的工作内存中,保存该线程使用到的变量的主内存副本拷贝。Java内存模型如下:
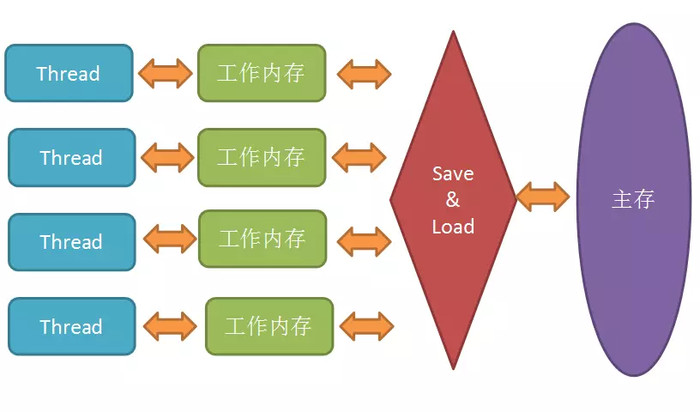
内存交互操作规则
主内存与工作内存交互时,必须遵循交互协议,才能保证主内存与工作内存的一致性。Java内存模型定义8种原子操作和执行规则来实现这一点。这8种操作是:
(1) lock(锁定):作用于主内存的变量,它把一个变量标志为一条线程独占的状态。
(2) unlock(解锁):作用于主内存中的变量,它把一个处于锁定状态的变量释放出来,释放后的变量才可以被其他线程锁定。
(3) read(读取):作用于主内存的变量,它把一个变量的值从主内存传输到线程的工作内存中,以便随后的load动作使用。
(4) load(载入):作用于工作内存的变量,它把read操作从主内存中得到的变量值放入工作内存的变量副本中。
(5) use(使用):作用于工作内存的变量,它把工作内存中一个变量的值传递给执行引擎。
(6) assign(赋值):作用于工作内存的变量,它把一个从执行引擎接受到的值赋给工作内存的变量。
(7) store(存储):作用于工作内存的变量,它把工作内存中一个变量的值传送到主内存中,以便随后的write操作使用。
(8) write(写入):作用于主内存中的变量,它把store操作从主内存中得到的变量值放入主内存的变量中。
对应执行流程如下:
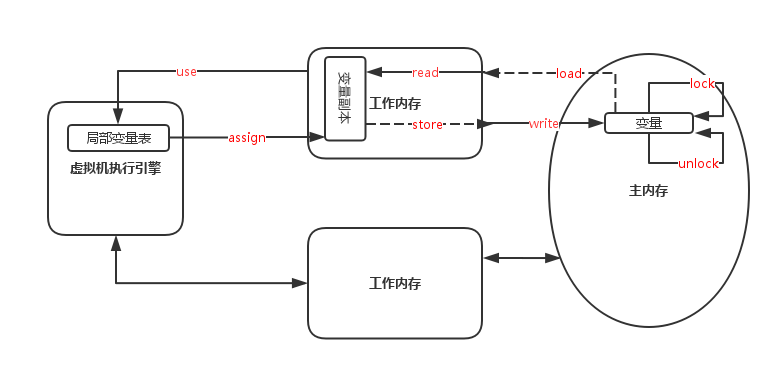
8种基本操作对应的执行规则比较繁琐,这里不再介绍,后续会学习其等效判断原则————先行发生原则,来确定一个访问在并发环境下是线程安全的。
原子性、可见性、有序性
Java内存模型是围绕着并发过程中如何处理原子性、可见性和有序性这三个特征来建立。
原子性(Atomicity)–操作的原子性
所谓原子性操作就是指这些操作是不可中断的,要么一定做完,要么就没有执行。Java中基本数据类型的读取和赋值操作是原子性操作。 比如:
i = 2; // 赋值操作,是原子性操作
j = i; // 读取i的值,然后再赋值给j, 2步操作
i++; // 读取i的值,加1,再写回主存,3步操作
有个例外是,虚拟机规范中允许对64位数据类型(long和double),分为2次32位的操作来处理,但是最新JDK实现时还是实现了原子操作的。 JMM只实现了基本的原子性,诸如i++那样的操作,必须借助于synchronized或Lock对象来保证整个代码块的原子性。
综上,在Java中只有以下两类场景能保证原子性:
(1) 基本数据类型的读取和赋值操作是原子性操作;
(2) lock操作和unlock操作之间的操作是原子性操作。由于lock和unlock操作未直接开放给用户,可使用更高层次的字节码指令monitorenter和monitorexit隐式调用这两个操作。对应Java代码,就是synchronized代码块是原子性操作,Lock对象修饰的代码块是原子性操作。
可见性(Visibility,也称并发可见性)
可见性是指当多个线程访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即得知修改的值。
Java内存模型是通过在变量修改后将新值同步到主内存,在变量读取前从主内存刷新变量值规则,来实现可见性的。
对于volatile修饰的变量,可以保证可见性。(volatile变量具有可见性,能保证新值立即同步到主内存,以及每次使用前立即从主内存刷新)
除了volatile外,synchronized和final关键字也可实现可见性。synchronized同步块的可见性是由“对一个变量执行unlock操作之前,必须先把此变量同步回主内存中”这个规则保证。
final关键字的可见性则是通过“被final修饰的字段,在构造器中完成初始化后,如果构造器没有把this的引用传递出去,那么在其他线程中就能看见final字段的值”保证。
综上,在Java中有三类场景可保证可见性:
(1) volatile 关键字
(2) synchronized 关键字
(3) final 关键字
有序性(Ordering)
Java内存模型的有序性是指:如果在本线程内部观察,所有的操作都是有序的;如果在一个线程中观察另一个线程,所有的操作都是无序的。前半句是指“线程内表现为串行的语义(Within-Thread As-If-Serial Semantics)”,后半句是指“指令重排”现象和“工作内存与主内存同步延迟”现象。
Java提供volatile关键字和syncronized关键字保证线程间操作的有序性。
(1) volatile关键字本身包含禁止指令重排序的语义。
(2) syncronizd关键字通过“一个变量在同一时刻只允许一个线程对其进行lock操作”保证有序性。
综上,在Java中有两类场景可保证有序性:
(1) volatile 关键字
(2) synchronized 关键字
先行发生规则(Happens-before)
在介绍内存交互操作规则时,曾提到等效判断原则————先行发生原则,该原则用来确定一个访问在并发环境下是线程安全的。详细来说,“先行发生规则”是判断数据是否存在竞争、线程是否安全的主要依据。
先行发生是Java内存模型中定义的两项操作之间的偏序关系。如果说操作A先行发生于操作B,就是说A产生的影响能被B观察到,”影响“包括修改了内存中的共享变量值、发送了消息、调用了方法等。
Java内存模型定义一些先行发生关系,对于这些先行发生关系,无需任何同步器协助,可以直接使用。而对于不在此列的关系,就没有顺序性保障,虚拟机可以随意的进行重排。也就是说,先行发生原则能够保证有序性。这些先行发生规则是:
(1) 程序次序规则(Program Order Rule):在一个线程内,代码的书写顺序和执行顺序一致。总结来说,线程内表现串行语义。
(2) 管程锁定规则(Monitor Lock Rule):unlock 操作先行发生于后面对同一个锁的 lock 操作。
(3) volatile 变量规则(Volatile Variable Rule):对一个 volatile 变量的写操作先行发生于后面对这个变量的读操作。
(4) 线程启动规则(Thread Start Rule):线程对象 start() 方法先行发生于此线程的每一个动作。
(5) 线程终止规则(Thread Termination Rule):线程中所有操作先行发生于对此线程的终止检测。常用的终止检测有Thread join()方法结束、Thread.isAlive()方法返回值进行终止检测。
(6) 线程中断规则(Thread Interruption Rule):对线程 interrupt() 方法的调用先行发生于被中断线程的代码检测到中断事件的发生:可以通过 Thread.interrupted() 方法检测到是否有中断发生。
(7) 对象终结规则(Finalizer Rule):一个对象的初始化完成先行发生于它的 finalize() 方法的开始。
(8) 传递性(Transitivity):如果操作A先行发生于操作B,B先行发生于C,那么A先行发生于C。
注意,“时间先后顺序”和“先行发生原则”没有太大关联,“先行发生原则”并不要求“时间先后顺序”,而“时间先后顺序”也无法保证“先行发生原则”(指令重排序)。并发问题中,受“时间先后顺序”干扰时,必须以“先行发生原则”为准。
volatile 关键字
volatile是Java中的关键字,它用于确保多线程环境下变量的可见性和有序性,但不能保证原子性。volatile可以说是Java虚拟机提供的最轻量级的同步机制,Java内存模型对volatile专门定义了一些特殊的访问规则。使用volatile修饰的共享变量(也称volatile 变量),具备三个特性:
(1) 保证操作的可见性。保证了不同线程对volatile变量操作的内存可见性;
(2) 无法保证操作的原子性。因为volatile关键字无法保证“原子性”,所以volatile变量的写操作无法保证原子性。
(3) 保证操作的有序性。volatile关键字通过禁止指令重排序,可以确保多个操作的有序性。
volatile关键字特性
保证操作的可见性
根据Java内存模型变量,变量在线程间传递均需要通过主内存来完成,例如,线程A修改一个变量的值,然后向主内存进行回写,另外一条线程B在线程A回写完成了之后再从主内存进行读取操作,新变量值才会对线程B可见。
对于 volatile 变量,在一个线程的工作内存被修改后,会立即同步回主内存,另一个线程每次在使用该 volatitle 变量时,都必须重新从主内存加载,进而保证可见性。
对可见性的误解,认为以下描述成立:“volatile变量对所有线程是立即可见的,对volatile变量所有的写操作都能立刻反应到其他线程之中,换句话说,volatile变量在各个线程中是一致的,所以基于volatile变量的运算在并发下是安全的”。这句话的论据部分并没有错,但是其论据并不能得出“基于volatile变量的运算在并发下是安全的”这个结论。volatile变量在各个线程的工作内存中不存在一致性问题(在各个线程的工作内存中,volatile变量也可以存在不一致的情况,但由于每次使用之前都要先刷新,执行引擎看不到不一致的情况,因此可以认为不存在一致性问题),但是Java里面的运算并非原子操作,导致volatile变量的运算在并发下一样是不安全的。
对保证操作的可见性,正确的描述是,当一个线程修改了一个volatile变量的值,其他线程会立即看到这个修改。这是因为volatile关键字会禁止CPU缓存和编译器优化,确保每次读取变量时都会从主内存中获取最新的值,从而确保了变量的可见性。

无法保证操作原子性
因为volatile关键字无法保证“原子性”,所以使用volatile关键字修饰的变量如果是原子性的操作,则具备原子性,否则必须使用syncronized或Lock对象等保证原子性。 对于不符合以下两条规则的运算场景,均需通过加锁来保证原子性:
(1) 运算结果并不依赖变量的当前值,或者能够确保只有单一的线程修改变量的值。
(2) 变量不需要与其他的状态变量共同参与不变约束。
使用volatile变量控制并发的示例代码如下:
volatile boolean shutdownRequested;
public void shutdown() {
shutdownRequested = true;
}
public void doWork() {
while(!shutdownRequested) {
// do something
}
}
保证操作的有序性
volatile关键字可以确保多个操作的有序性。即在一个线程中执行的操作,在另一个线程中也会按照相同的顺序执行。这是因为在Java内存模型中,一个线程中的操作会被排序,形成一个操作序列。但是,不同的线程可能看到操作序列的不同顺序。volatile关键字可以确保多个操作之间的顺序性,即一个线程中的操作会按照相同的顺序执行。上述能力也称为禁止指令重排序。指令重排序是指:代码书写的顺序与代码实际执行顺序不同,指令重排序是编译器或者处理器为了提高程序性能做出的优化。(编译成机器码后,重新调整下顺序,可能更符合CPU的特点,能最大限度的发挥CPU的性能)。
指令重排序不是指令任意重排或指令任意排序,CPU需要能正确处理指令依赖情况以保障程序能得出正确的执行结果。譬如指令1把地址A中的值加10,指令2把地址A中的值乘以2,指令3把地址B中的值减去3,这时指令1和指令2是有依赖的,其顺序不能重排——(A+10)2与A2+10显然不相等,但指令3可以重排到指令1、 2之前或者中间,只要保证CPU执行后面依赖到A、 B值的操作时能获取到正确的A和B值即可。
普通的变量仅仅会保证在该方法的执行过程中所有依赖赋值结果的地方都能获取到正确的结果,而不能保证变量赋值操作的顺序与程序代码中的执行顺序一致。因为在一个线程的方法执行过程中无法感知到这点,这也就是Java内存模型中描述的所谓的“线程内表现为串行的语义”(Within-Thread As-If-SerialSemantics)。
但是,指令重排序后干扰程序的并发执行,使其无法达到“代码书写顺序”的效果。指令重排序功能在JDK 1.5之后才真正实现。
volatile底层实现
加入volatile关键字的代码会多出一个lock前缀指令。lock前缀指令实际相当于一个内存屏障(Memory Barrier或Memory Fence),内存屏障提供了以下功能:
1.指令重排序时不能把后面的指令重排序到内存屏障之前的位置(禁止指令重排序);
2.使得本CPU的Cache写入内存,该写入动作也会引起别的CPU或者别的内核无效化其Cache,相当于让新写入的值对别的线程可见。
volatile变量规则简介
假设T表示一个线程,V1和V2分别表示两个volatile类型变量,那么在进行read、load、use、assign、store和write操作时需要满足以下规则:
(1) 读可见性
只有当线程T对变量V1执行的前一个动作是load的时候,线程T才能对变量V1执行use动作;并且,只有当线程T对变量V1执行的后一个动作是use的时候,线程T才能对变量V1执行load动作。线程T对变量V1的use动作可以认为是和线程T对变量V1的load、read动作相关联,必须连续一起出现。这条规则要求在工作内存中,每次使用V1前都必须先从主内存刷新最新的值,用于保证能看见其他线程对变量V1所做的修改后的值。即使用变量:read->load->use
(2) 写可见性
只有当线程T对变量V1执行的前一个动作是assign的时候,线程T才能对变量V1执行store动作;并且,只有当线程T对变量V1执行的后一个动作是store的时候,线程T才能对变量V1执行assign动作。线程T对变量V1的assign动作可以认为是和线程T对变量V1的store、write动作相关联,必须连续一起出现。这条规则要求在工作内存中,每次修改V1后都必须立刻同步回主内存中,用于保证其他线程可以看到自己对变量V1所做的修改。即修改变量:assign->store->write
(3) 禁止指令重排序
假定动作A是线程T对变量V1实施的use或assign动作,假定动作F是和动作A相关联的load或store动作,假定动作P是和动作F相应的对变量V1的read或write动作;类似的,假定动作B是线程T对变量V2实施的use或assign动作,假定动作G是和动作B相关联的load或store动作,假定动作Q是和动作G相应的对变量V2的read或write动作。如果A先于B,那么P先于Q。这条规则要求volatile修饰的变量不会被指令重排序优化,保证代码的执行顺序与程序的顺序相同。
(4) long和double变量的非原子协定
Java 内存模型要求lock、unlock、read、load、assign、use、store和write这8个操作都具有原子性,但是对于64位的数据类型 long 和 double,在模型中特别定义了一条宽松的规定:允许虚拟机将没有被volatile修饰的64位类型是long和double的数据读写操作划分为两次32位的操作来进行。这就是所谓的 long 和 double 的非原子性协定(Nonatomic Treatment of double and long Variables)。
尽管long和double具有“非原子协定”,但是大多数虚拟机都将其操作“原子化”。因此,在编码时,无需特别将long和double变量声明为volatile。
volatile变量、普通变量和锁
volatile变量读操作性能与普通变量无异,写操作性能会慢一些,因为需要在本地代码中插入“内存屏障指令”来保证处理器不发生乱序执行。
volatile变量对总开销要比锁低。如果一个场景既能使用锁也能使用volatile变量,则尽量使用volatile变量。
volatile使用场景
编写无锁的代码,提高性能。如优化因synchronized滥用导致的性能问题。
synchronized关键字
synchronized是Java中的关键字,它用于实现同步访问共享资源,可解决共享资源竞争问题,以确保多个线程之间共享资源访问的正确性。当一个方法或代码块被声明为synchronized时,只有一个线程可以执行该方法或代码块。其他尝试访问该方法或代码块的线程将会被阻塞,直到当前线程执行完该方法或代码块。需要说明的是,synchronized关键字可能会导致线程阻塞和性能下降。因此,在使用synchronized关键字时,应该仔细考虑同步访问的必要性,并尽可能地减小同步访问的范围。
synchronized 与 Java 内存模型
synchronized关键字可保证所修饰元素的原子性、可见性、有序性。
对于非原子性操作,诸如i++那样的操作,可以借助synchronized来保证整个代码块的原子性。
synchronized也可实现可见性。synchronized同步块的可见性是由“对一个变量执行unlock操作之前,必须先把此变量同步回主内存中”这个规则保证。
对于有序性,syncronizd关键字通过“一个变量在同一时刻只允许一个线程对其进行lock操作”这个规则来保证。
synchronized 使用场景
根据synchronized关键字修饰元素的类型,可将其使用场景分为两类:使用syncronized修饰代码块(也称同步代码块)或使用syncronized修饰方法(也称为同步方法)。其中,使用syncronized修饰方法,又根据是否是static方法,分为使用syncronized修饰类方法和syncronized修饰对象方法。
synchronized作用于代码块
synchronized关键字作用于方法中的代码块,此时基于 synchronized 指定实例加锁。用法实例如下:
synchronized(instanceName) {
// instanceName 表示指定实例
/* 代码块 */
}
synchronized作用于对象方法
synchronized关键字作用于对象方法,此时基于当前对象加锁。使用模式如下:
synchronized 访问类型 返回值 methodName() {
/* 方法体 */
}
synchronized作用于类方法
synchronized关键字作用于对象方法,此时基于当前类加锁。使用模式如下:
synchronized 访问类型 static 返回值 methodName() {
/* 方法体 */
}
使用syncronized关键字可以保证在同一时刻仅有一个线程访问该同步代码块或同步方法。synchronized 通过下述规则保证该特性:
(1) 当多个线程同时访问synchronized同步块或同步方法时,只能有一个线程得到执行,其他线程必须等待。
(2) 当一个线程访问synchronized同步块或同步方法时,其他线程仍可同时调用object中其它非synchronized同步块或方法。
(3) 当一个线程访问synchronized同步块或同步方法时,它会获得整个object的对象锁或类锁。因此,其他线程对于object的所有同步块或同步方法的访问都将被暂时阻塞,直至当前线程执行完这个同步块或同步方法。
(4) 当线程完成synchronized同步块或同步方法访问时,它会释放整个object的对象锁或类锁。因此,需要调用object上同步块或同步方法的其他线程将尝试获取这个object的对象锁。
synchronized 原理
synchronized 本质使用 Java 内置的 Monitor(管程、监视器)Object 实现线程同步。对同步代码块和同步方法,使用不同的实现方式。对于同步代码块,则是使用 monitorenter 和 monitorexit 指令 实现的;而同步方法,则是采用 ACC_SYNCHRONIZED标记符实现。
(1) 同步代码块
monitorenter 指令插入到同步代码块的开始位置,monitorexit 指令插入到同步代码块的结束位置,JVM则保证每一个monitorenter都有一个monitorexit与之相对应。任何对象都有一个monitor与之相关联,当且一个monitor被持有之后,该对象将处于锁定状态。
根据虚拟机规范的要求,在执行monitorenter指令时,首先要尝试获取对象的锁。如果这个对象没被锁定,或者当前线程已经拥有了那个对象的锁,把锁的计数器加1,相应的,在执行monitorexit指令时会将锁计数器减1,当计数器为0时,锁就被释放。如果获取对象锁失败,那当前线程就要阻塞等待,直到对象锁被另外一个线程释放为止。
注意:(a)首先,synchronized同步块对同一条线程来说是可重入的,不会出现自己把自己锁死的问题;(b)其次,同步块在已进入的线程执行完之前,会阻塞后面其他线程的进入。
(2) 同步方法
当某个线程要访问该方法时,会检查该方法是否有 ACC_SYNCHRONIZED 标志,如果有设置,则需要先获得监视器锁,然后开始执行方法,方法执行之后再释放监视器锁。
Java 实现 Monitor Object简介
不同虚拟机,对Monitor Object的实现略有不同。这里以HotSpot为例,简单介绍monitor的实现(基于ObjectMonitor实现)。ObjectMonitor的主要数据结构如下:
ObjectMonitor() {
_header = NULL;
_count = 0; // 记录个数
_waiters = 0,
_recursions = 0;
_object = NULL;
_owner = NULL; // ObjectMonitor的持有者
_WaitSet = NULL; // 处于wait状态的线程,会被加入到_WaitSet
_WaitSetLock = 0 ;
_Responsible = NULL ;
_succ = NULL ;
_cxq = NULL ;
FreeNext = NULL ;
_EntryList = NULL ; // 处于等待锁block状态的线程,会被加入到该列表
_SpinFreq = 0 ;
_SpinClock = 0 ;
OwnerIsThread = 0 ;
}
可以看到,ObjectMonitor中有两个队列,_WaitSet 和_EntryList,用来保存ObjectWaiter对象列表(等待锁的线程都会被封装成ObjectWaiter对象),_owner指向持有ObjectMonitor对象的线程。当多个线程同时访问一段同步代码时,首先会进入_EntryList 集合,当线程获取到对象的 monitor 后进入 _Owner 区域并把monitor中的owner变量设置为当前线程同时monitor中的计数器count加1;若线程调用 wait() 方法,将释放当前持有的monitor,owner变量恢复为null,count自减1,同时该线程进入 WaitSet集合中等待被唤醒。若当前线程执行完毕也将释放monitor(锁)并复位变量的值,以便其他线程进入获取monitor(锁)。
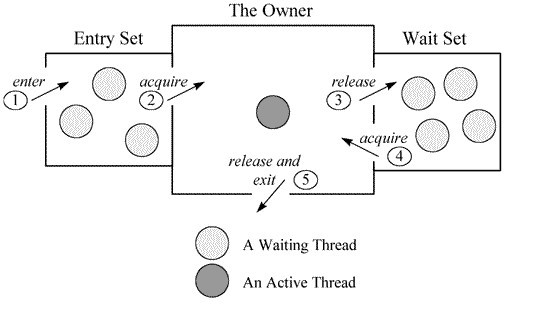
Java线程模型实现
主流操作系统都提供线程实现,Java语言则提供在不同硬件和操作系统平台下对线程操作的统一处理。
操作系统实现线程时,主要有三种方式:使用内核线程的实现、使用用户线程的实现和使用用户线程 + 轻量级进程混合实现。
使用内核线程的实现
内核线程(Kernel-Level Thread, KLT)就是直接由操作系统内核支持的线程,这种线程由内核完成线程切换,内核通过操纵调度器(Scheduler)对线程进行调度,并负责将线程的任务映射到各个处理器上。
程序一般不会直接使用内核线程,而是使用内核线程的一种高级接口——轻量级进程(Light Weight Process, LWP),这种轻量级进程与内核线程之间是 1:1 的关系。轻量级进程就是通常意义上的线程。
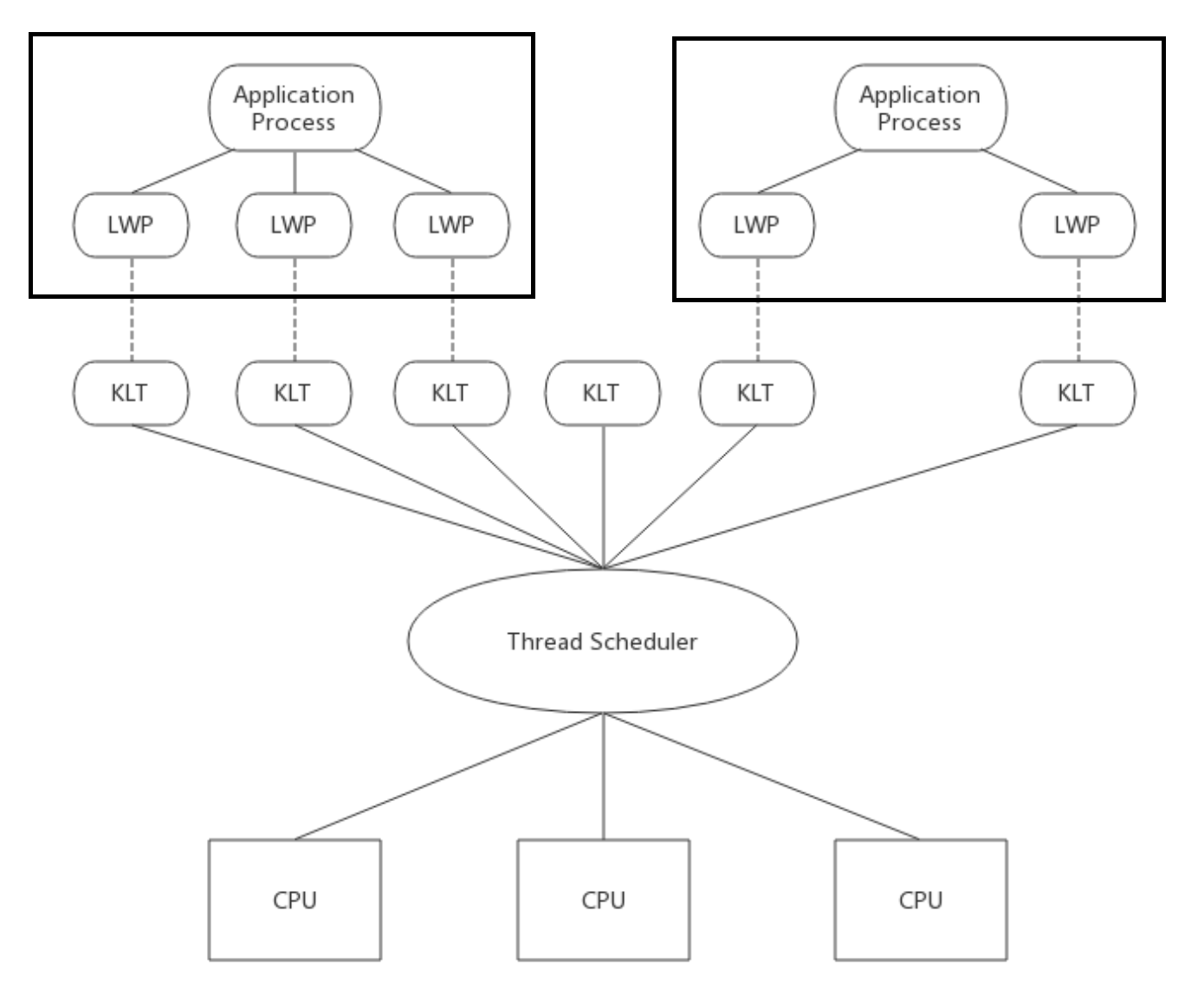
(1) 优点
由于内核线程的支持,每个轻量级进程都成为一个独立的调度单元,即使有一个轻量级进程在调用时阻塞了,也不会影响整个进程继续工作。
(2) 缺点
由于是基于内核线程实现的,所以各种线程操作,如创建、析构及同步,都需要进行内核的调用,而内核调用的代价相对较高,需要在用户态(User Mode)和内核态(Kernel Mode)间来回切换。并且由于每个轻量级进程都需要一个内核线程支持,因为内核线程数有限,所以一个系统支持的轻量级进程的数量是有限的。
使用用户线程的实现
广义上讲,一个线程只要不是内核线程就可以认为是用户线程(User Thread, UT),因此广义上轻量级进程也属于用户线程。狭义上的用户线程指的是完全建立在用户空间的线程,系统内核无法感知到用户线程的存在。用户线程的操作,如创建、同步、销毁和调度完全在用户态中完成,不需要内核帮助。
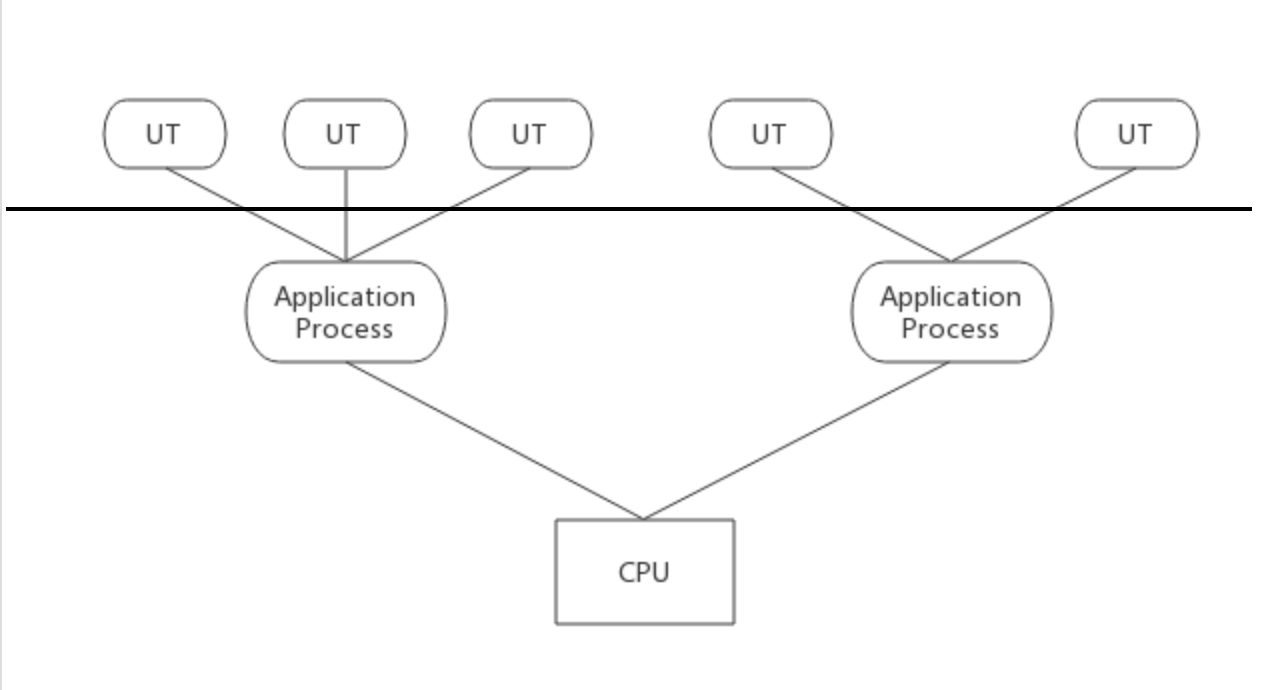
(1) 优点
由于不需要在用户态和内核态间来回切换,因此操作非常快速且消耗低,并且支持的线程数量也相对较大。
(2) 缺点
由于没有内核的帮助,线程所有的操作都需要用户程序自己处理,并且由于操作系统只把资源分配给进程,诸如“阻塞如何处理”、“多处理器系统中如何将线程任务映射到各个处理器”,等这类问题处理比较困难。这些问题导致了现在单纯使用用户线程的程序越来越少。
使用用户线程 + 轻量级进程混合实现
在这种实现中,用户线程还是完全建立在用户空间,因此线程的创建、析构、切换等操作依然快速且消耗低,并且支持的线程数量较大。操作系统提供轻量级进程作为用户线程和内核线程的桥梁,这样可以使用内核提供的线程调度以及处理器映射,用户线程的调度也交由轻量级进程处理,这大大降低了进程阻塞的风险。在这种混合模式中,用户线程与轻量级进程的数量比是不定的,即为 N:M 的关系。许多 UNIX 系统,如 Solaris、HP-UX 等都提供了 N:M 的线程模型。
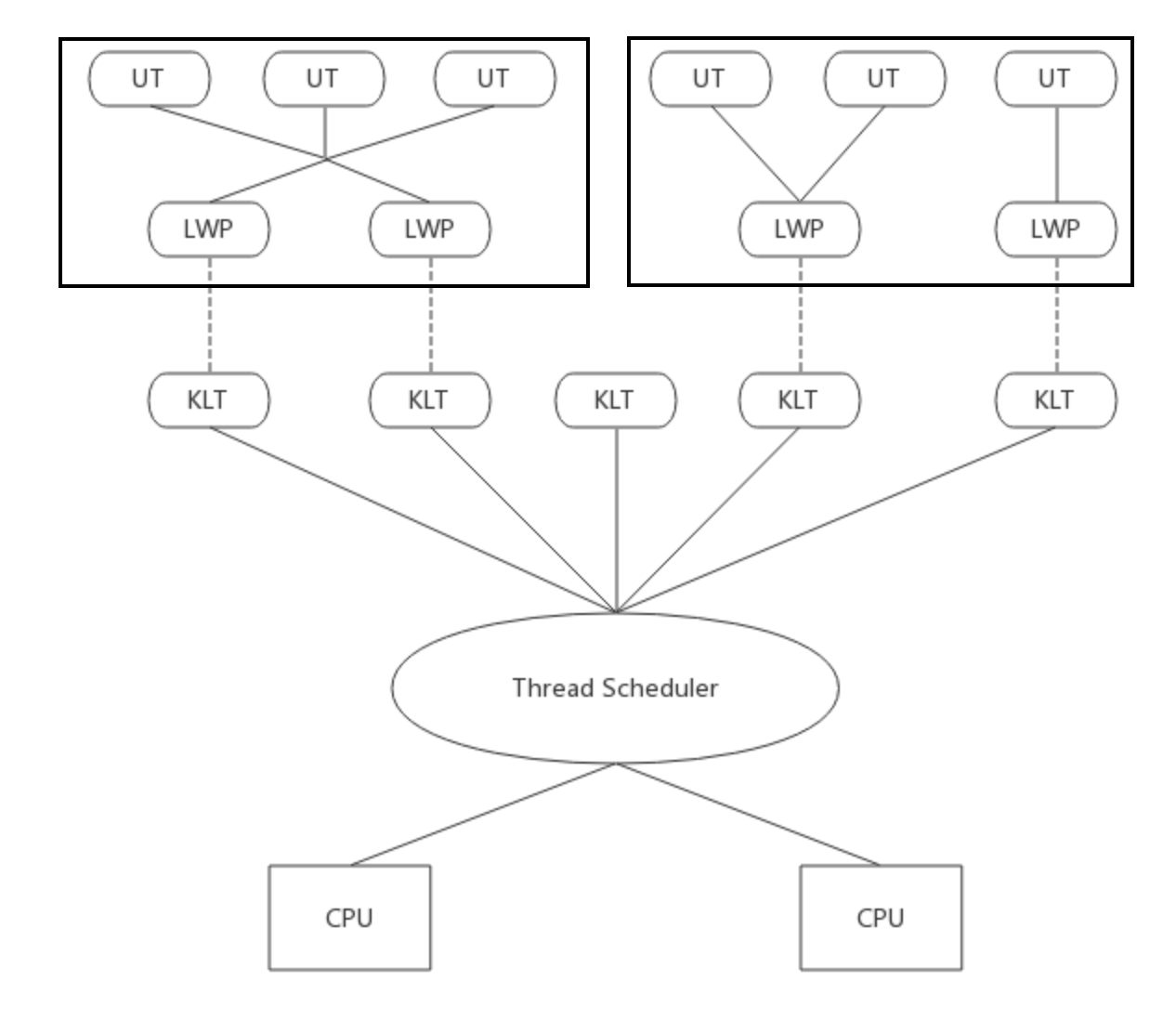
(1) 优点
线程的操作均是在用户态进行,操作快速且消耗低。 一个线程或轻量级进程阻塞,不会影响整个进程的工作。
(2) 缺点
暂无
Java使用线程模型
Java语言在JDK 1.2之前,仅支持“用户线程模型”实现,在JDK 1.2中实现基于操作系统原生线程模型实现。
线程模型只对线程的并发规模和操作成本产生影响,对Java程序的编写和运行来说,这些差异是透明的。
线程调度
线程调度是系统为线程分配处理器使用权的过程,根据是否区分线程优先级,将线程调度分为两种:协同式线程调度和抢占式线程调度。
协同式线程调度
使用协同式线程调度的多线程系统,线程的执行时间由线程本身控制。线程将自己的工作做完后,要主动通知系统切换到另一个线程。
(1) 优点
实现简单,由于需要线程做完工作后主动通知系统进行线程切换,所以没有线程同步问题。
(2) 缺点
线程执行时间不可控,如果一个线程编写有问题,一直不告知操作系统进行线程切换,那么程序将会阻塞,严重的可能会造成系统崩溃。
抢占式线程调度
使用抢占式线程调度的多线程系统,每个线程由操作系统分配执行时间,线程切换不由线程来决定(Java 中,可以通过 Thread.yield() 让出执行时间,当然不一定管用)。
(1) 优点
线程执行时间是确定的、可控的,因此不会有一个线程导致整个程序阻塞的问题。
(2) 缺点
需要考虑线程同步问题。
Java的线程调度
Java 的线程调度使用的是抢占式。
虽然 Java 的线程调度是由操作系统自动完成的,但是我们还是可以“建议”操作系统给某些线程多一点执行时间,另外一些线程少一点执行时间,这个操作可以通过设置线程的优先级来完成。Java 提供了 10 个级别的线程优先级,在两个线程同时处于 Ready 状态时,优先级越高的越容易先被执行。不过,由于 Java 的线程是映射到原生线程上来实现的,所以最终的线程调度还是取决于操作系统,并且操作系统的线程优先级的数量可能和 Java 的不能一一对应(如 Solaris 中有 2^32 种优先级,而 Windows 中只有 7 种)。
线程状态转换
在介绍Java语言中线程状态前,先简要介绍下操作系统中工作线程的状态切换。 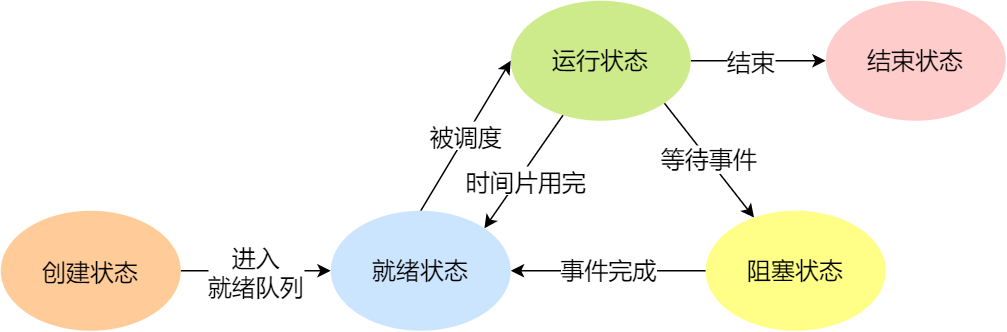
操作系统中工作线程共三种状态:Ready, Running, Blocked。 其中:
(1) Ready(就绪) 代表当前的调度实例在可执行队列中,随时可以被切换到占用处理器的运行状态。
(2) Running(运行) 代表当前的调度实例正在占用处理器运行中。
(3) Blocked(阻塞) 代表当前的调度实例在等待相应的资源。
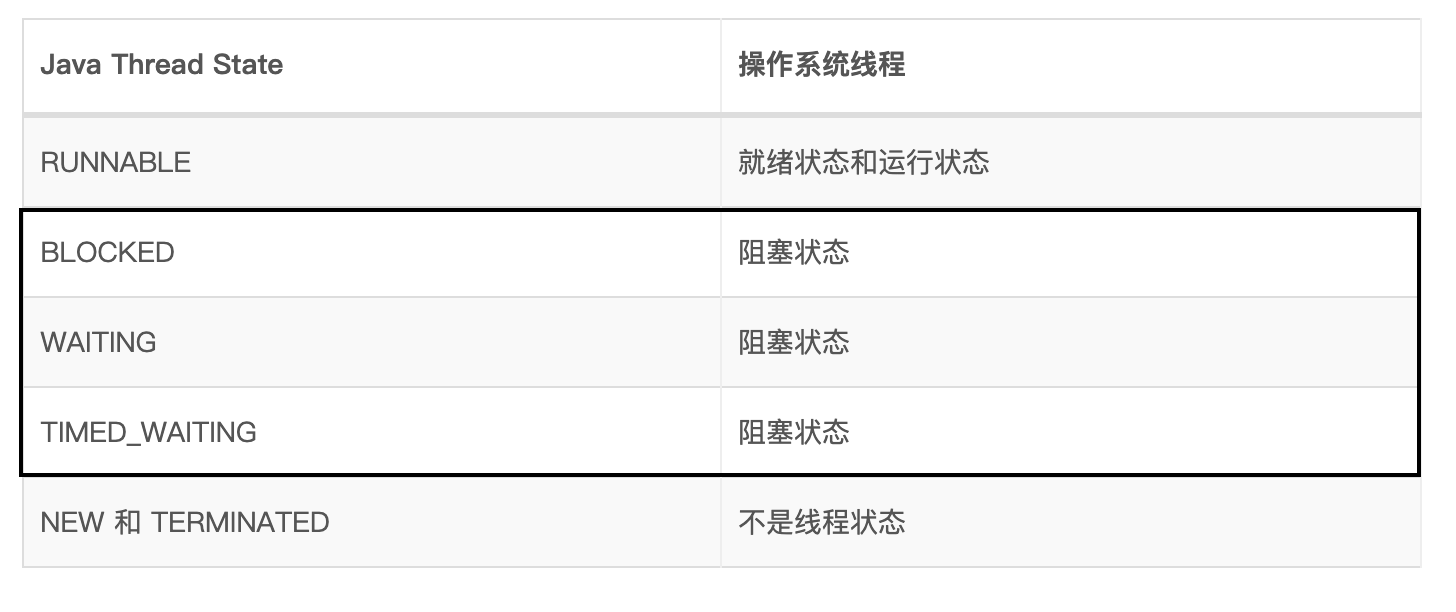
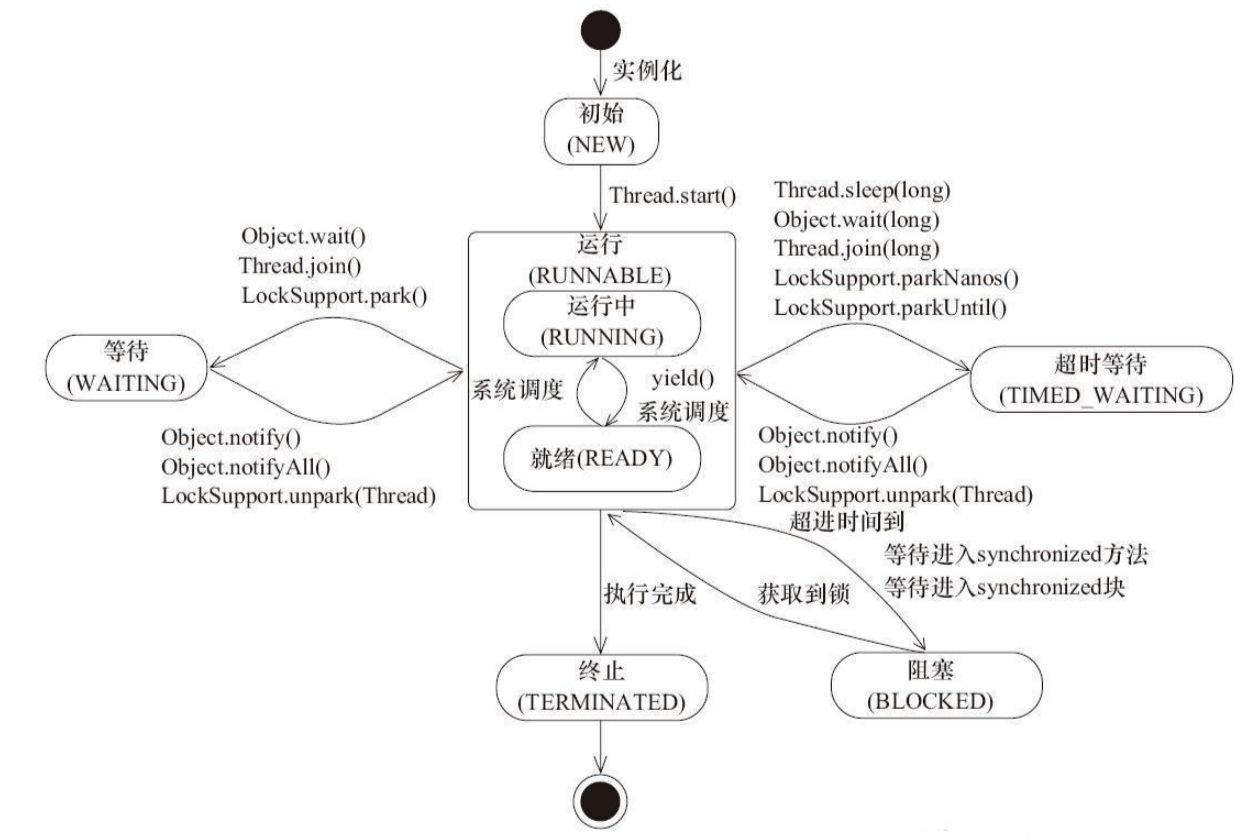
Java Thread 有 6 种状态:
(1) New(新建): 未启动的线程处于这种状态。
(2) Runable(可运行):该状态包括操作系统线程状态中的Running和Ready。也就是说,该状态的线程或正在运行,或等待操作系统中的其他资源,比如处理器。
(3) Waiting(无限期等待):没有显式设置唤醒时间而处于等待的线程状态。该类线程需要被其他线程显式唤醒。 某一线程可调用下列方法之一而处于等待状态:
不带超时值的 Object.wait();不带超时值的 Thread.join();LockSupport.park()。
例如,已经在某一对象上调用了 Object.wait() 的线程正等待另一个线程,以便在该对象上调用 Object.notify() 或 Object.notifyAll()。已经调用了 Thread.join() 的线程正在等待指定线程终止。
(4) Timed Waiting(限时等待):显式指定唤醒时间而等待的线程的线程状态。某一线程因为调用以下带有指定正等待时间的方法之一而处于限时等待状态:
Thread.sleep();带有超时值的 Object.wait();带有超时值的 Thread.join();LockSupport.parkNanos();LockSupport.parkUntil。
(5) Blocked(阻塞):受阻塞并且正在等待监视器锁的某一线程的线程状态。处于受阻塞状态的某一线程正在等待监视器锁,以便进入一个同步的块/方法,或者在调用 Object.wait 之后再次进入同步的块/方法。
“阻塞状态”和“等待状态”在Java语言中的区别是:“阻塞状态”在等待获取一个排他锁,而“等待状态”则是等待一段时间或唤醒动作的发生。Java线程中的“阻塞状态”和“等待状态”都对应操作系统线程中的“阻塞状态”。
(6) Terminated(结束):已终止线程的线程状态。线程已经结束执行。
Java线程的状态转移图如下所示:
线程安全
线程安全的一个比较恰当的定义是:“当多个线程访问一个对象时,如果不用考虑这些线程在运行时环境下的调度和交替执行,也不需要进行额外的同步,或者在调用方进行任何其他的协调操作,调用这个对象的行为都可以获得正确的结果,那这个对象是线程安全的”。
简言之,线程安全就是指多个线程访问某个类时,这个类始终都能表现出正确的行为,那么就称这个类是线程安全的。
也就是说,代码本身封装了所有必要的正确性保障手段(如互斥同步),令调用者无需关心多线程的问题,更无需采用任何措施来保证多线程的正确调用。
在线程安全的定义中,最核心的概念是正确性,如果对线程安全的定义感到模糊,那么就是因为缺乏对正确性的清晰定义。
正确性的定义是,某个类或代码的行为与其规范完全一致。因此,可将单线程的正确性近似定义为“所见即所知(we know it when we see it)”。
线程安全等级
按照线程安全的“安全程度”由强至弱来排序,可将Java语言中各种操作共享的可变数据分为以下5类:不可变、绝对线程安全、相对线程安全、线程兼容和线程对立。
不可变
在Java语言中(特指JDK 1.5之后),不可变(Immutable)对象一定是线程安全的,无论是对象的方法实现还是方法的调用者,都不需要再采取任何的线程安全保障措施。
一旦一个不可变的对象被正确地构建出来(没有发生this引用逃逸的情况),那其外部的可见状态永远也不会改变,永远也不会看到它在多个线程之中处于不一致的状态。“不可变”带来的安全性是最简单和最纯粹的。
Java语言中,(1)如果共享数据是一个基本数据类型,那么只要在定义时使用final关键字修饰它就可以保证它是不可变的;(2)如果共享数据是一个对象,那就需要保证对象的行为不会对其状态产生任何影响才行。java.lang.String 是一个典型的不可变对象,调用它的substring()、replace()和concat()等方法都不会影响它原来的值,只会返回一个新构造的字符串对象。
保证对象行为不影响自己状态的途径有很多种,其中最简单的就是把对象中带有状态的变量都声明为final,这样在构造函数结束之后,它就是不可变的。
在Java API中符合不可变要求的类型,除了上面提到的String之外,常用的还有枚举类型,以及java.lang.Number的部分子类,如Long和Double等数值包装类型,BigInteger和BigDecimal等大数据类型。
绝对线程安全
绝对的线程安全完全满足**Brian Goetz(《Java并发编程实战》作者)**给出的线程安全的定义,这个定义其实是很严格的,一个类要达到“不管运行时环境如何,调用者都不需要任何额外的同步措施”通常需要付出很大的,甚至有时候是不切实际的代价。
在Java API中标注自己是线程安全的类,大多数都不是绝对的线程安全。java.util.Vector是一个线程安全的容器,相信所有的Java程序员对此都不会有异议,因为它的add()、get()和size()这类方法都是被synchronized修饰的,尽管这样效率很低,但确实是安全的。但是,即使它所有的方法都被修饰成同步,也不意味着调用它的时候永远都不再需要同步手段。(remove和get同时执行会出现问题)
相对线程安全
相对线程安全就是通常意义上所讲的线程安全,它需要保证对这个对象单独的操作是线程安全的,但在调用时,需要做额外的保障措施。如对于一些特定顺序的连续调用,可能需要在调用端使用额外的同步手段来保证调用的正确性。
在Java语言中,大部分的线程安全类都属于这种类型,例如Vector、Hashtable、Collections的synchronizedCollection()方法包装的集合等。
线程兼容
线程兼容是指对象本身并不是线程安全的,但是可以通过在调用端正确地使用同步手段来保证对象在并发环境中可以安全地使用,我们平常说一个类不是线程安全的,绝大多数时候指的是这一种情况。Java API中大部分的类都是属于线程兼容的,如与前面的Vector和HashTable相对应的集合类ArrayList和HashMap等。
对象本身不是线程安全,但可采取同步手段,保证对象在并发环境下安全使用。或保证仅有一个线程能访问该对象。
线程对立
**线程对立是指无论调用端是否采取同步措施,都无法在多线程环境中并发使用的代码。由于Java语言天生就具备多线程特性,线程对立这种排斥多线程的代码是很少出现的,而且通常都是有害的,应当尽量避免。
一个线程对立的例子是Thread类的suspend()和resume()**方法,如果有两个线程同时持有一个线程对象,一个尝试去中断线程,另一个尝试去恢复线程,如果并发进行的话,无论调用时是否进行了同步,目标线程都是存在死锁风险的,如果suspend()中断的线程就是即将要执行resume()的那个线程,那就肯定要产生死锁了。也正是由于这个原因,suspend()和resume()方法已经被JDK声明废弃(@Deprecated)了。常见的线程对立的操作还有System.setIn()、Sytem.setOut()和System.runFinalizersOnExit()等。
线程安全实现
了解线程安全后,接下来学习如何实现线程安全。常见实现线程安全的方法有三种:互斥同步(阻塞同步)、非阻塞同步、 无同步。
互斥同步(Mutual Exclusion&Synchronization)
互斥同步也被称为阻塞同步(Blocking Synchronization),是常见的一种并发正确性保障手段。同步是指在多个线程并发访问共享数据时,保证共享数据在同一个时刻只被一个(或者是一些,使用信号量的时候)线程使用。而互斥是实现同步的一种手段,临界区(Critical Section)、互斥量(Mutex)和信号量(Semaphore)都是主要的互斥实现方式。简言之,互斥是方法,同步是目的。
在Java中,最基本的互斥同步手段就是synchronized关键字。除synchronized关键字外,还可以使用java.util.concurrent(下文称J.U.C)包中的重入锁(ReentrantLock)来实现同步。在基本用法上,ReentrantLock与synchronized很相似,他们都具备一样的线程重入特性,只是代码写法上有点区别,一个表现为API层面的互斥锁(lock()和unlock()方法配合try/finally语句块来完成),另一个表现为原生语法层面的互斥锁。
互斥同步最主要的问题就是进行线程阻塞和唤醒所带来的性能问题,这也是这种同步称为阻塞同步的原因。互斥同步属于一种悲观的并发策略,总是认为只要不去做正确的同步措施(例如加锁),那就肯定会出现问题,无论共享数据是否真的会出现竞争,它都要进行加锁(这里讨论的是概念模型,实际上虚拟机会优化掉很大一部分不必要的加锁)、用户态核心态转换、维护锁计数器和检查是否有被阻塞的线程需要唤醒等操作。
非阻塞同步(Non-Blocking Synchronization)
随着硬件指令集的发展,我们有了另外一个选择:基于冲突检测的乐观并发策略,通俗地说,就是先进行操作,如果没有其他线程争用共享数据,那操作就成功了;如果共享数据有争用,产生了冲突,那就再采取其他的补偿措施(最常见的补偿措施就是不断地重试,直到成功为止),这种乐观的并发策略的许多实现都不需要把线程挂起,因此这种同步操作称为非阻塞同步。
为什么说使用乐观并发策略需要“硬件指令集的发展”才能进行呢?因为我们需要操作和冲突检测这两个步骤具备原子性,靠什么来保证呢?如果这里再使用互斥同步来保证就失去意义了,所以我们只能靠硬件来完成这件事情,硬件保证一个从语义上看起来需要多次操作的行为只通过一条处理器指令就能完成,这类指令常用的有:
测试并设置(Test-and-Set)
获取并增加(Fetch-and-Increment)
交换(Swap)
比较并交换(Compare-and-Swap,下文称CAS)
加载链接/条件存储(Load-Linked/Store-Conditional,下文称LL/SC)
其中,CAS指令需要有3个操作数,分别是内存位置(在Java中可以简单理解为变量的内存地址,用V表示)、旧的预期值(用A表示)和新值(用B表示)。CAS指令执行时,当且仅当内存位置V中存储值符合旧预期值A时,处理器用新值B更新V的值,否则它就不执行更新,但是无论是否更新V的值,都会返回V的旧值(保证不存在其他线程更新该值),上述的处理过程是一个原子操作。
在JDK 1.5之后,才可以使用CAS操作,该操作由sun.misc.Unsafe类里面的compareAndSwapInt()和compareAndSwapLong()等几个方法包装提供,虚拟机在内部对这些方法做了特殊处理,即时编译出来的结果就是一条平台相关的处理器CAS指令,没有方法调用的过程,或者可以认为是无条件内联进去了。
由于Unsafe类不是提供给用户程序调用的类(Unsafe.getUnsafe()的代码中限制了只有启动类加载器(Bootstrap ClassLoader)加载的Class才能访问它),因此,如果不采用反射手段,我们只能通过其他的Java API来间接使用它,如J.U.C包里面的整数原子类,其中的**compareAndSet()和getAndIncrement()**等方法都使用了Unsafe类的CAS操作。
无同步方案
要保证线程安全,并不一定就要进行同步,两者没有因果关系。同步只是保证共享数据争用时的正确性的手段。如果一个方法本来就不涉及共享数据,那它自然就无须任何同步措施去保证正确性,因此会有一些代码天生就是线程安全的,下面简单地介绍其中的两类。
(1) 可重入代码(Reentrant Code)
可重入代码也叫做纯代码(Pure Code),可以在代码执行的任何时刻中断它,转而去执行另外一段代码(包括递归调用它本身),而在控制权返回后,原来的程序不会出现任何错误。
相对线程安全来说,可重入性是更基本的特性,它可以保证线程安全,即所有的可重入的代码都是线程安全的,但是并非所有的线程安全的代码都是可重入的。
可重入代码有一些共同的特征,例如不依赖存储在堆上的数据和公用的系统资源、用到的状态量都由参数传入、不调用非可重入的方法等。可以通过一个简单的原则来判断代码是否具备可重入性:如果一个方法,它的返回结果是可以预测的:只要输入了相同的数据,就都能返回相同的结果。
(2) 线程本地存储(Thread Local Storage)
如果一段代码中所需要的数据必须与其他代码共享,那就看看这些共享数据的代码是否能保证在同一个线程中执行?如果能保证,我们就可以把共享数据的可见范围限制在同一个线程之内,这样,无须同步也能保证线程之间不出现数据争用的问题。
符合这种特点的应用并不少见,大部分使用消费队列的架构模式(如“生产者-消费者”模式)都会将产品的消费过程尽量在一个线程中消费完,其中最重要的一个应用实例就是经典Web交互模型中的“一个请求对应一个服务器线程”(Thread-per-Request)的处理方式,这种处理方式的广泛应用使得很多Web服务端应用都可以使用线程本地存储来解决线程安全问题。(不适合在线程池中使用)
Java语言中,如果一个变量要被多线程访问,可以使用volatile关键字声明它为“易变的”;如果一个变量要被某个线程独占,Java中就没有类似C++中**__declspec(thread)这样的关键字,不过还是可以通过java.lang.ThreadLocal类**来实现线程本地存储的功能。
每一个线程的Thread对象中都有一个ThreadLocalMap对象,这个对象存储了一组以TreadLocal.threadLocalHashCode为键,以本地线程变量为值的K-V值对,ThreadLocal对象就是当前线程的ThreadLocalMap的访问入口,每一个ThreadLocal对象都包含了一个独一无二的threadLocalHashCode值,使用这个值就可以在线程K-V值对中找回对应的本地线程变量。
线程安全与原子性
所谓原子性操作就是指这些操作是不可中断的,要么一定做完,要么就没有执行。 比如:
i = 2; // 赋值操作,是原子性操作
j = i; // 读取i的值,然后再赋值给j, 2步操作
i++; // 读取i的值,加1,再写回主存,3步操作
Java中基本数据类型的读取和赋值操作是原子性操作。有个例外是,虚拟机规范中允许对64位数据类型(long和double),分为2次32位的操作来处理,但是最新JDK实现时还是实现了原子操作的。 JMM只实现了基本的原子性,诸如i++那样的操作,必须借助于synchronized或Lock对象来保证整个代码块的原子性。
综上,在Java中只有以下两类场景能保证原子性:
(1) 基本数据类型的读取和赋值操作是原子性操作;
(2) lock操作和unlock操作之间的操作是原子性操作。由于lock和unlock操作未直接开放给用户,可使用更高层次的字节码指令monitorenter和monitorexit隐式调用这两个操作。对应Java代码,就是synchronized代码块是原子性操作,Lock对象修饰的代码块是原子性操作。
竞态条件(Race Condition)
在并发编程中,竞态条件是指由于不恰当的执行时序而出现不正确的结果的情况。当某个计算的正确性取决于多个线程交替执行时序时,那么就会发生竞态条件。简言之,正确的结果要取决于运气。最常见的竞态条件类型是“先检查后执行(Check-Then-Act)”操作,即通过一个可能失效的观测结果来决定下一步的操作:首先观察到某个条件为“真”(如文件X不存在),然后根据这个观察结果采用响应的动作(如创建文件X)。而事实上,在观察到这个结果以及开始创建文件之间,观察结果可能已经无效(另一个线程在这期间创建了文件X),从而导致各种问题(未预期的异常、数据被覆盖、文件被破坏等)。
要避免竞态条件问题,就必须在某个线程修改该变量时,通过某种方式防止其他线程使用这个变量,从而确保其他线程只能在修改操作完成之前或之后读取和修改状态,而不是在修改状态的过程中。为此,可以使用线程安全对象(原子变量类、线程安全类等)来确保代码的线程安全性。
典型的场景是使用双锁检验实现的单例模式
显式锁
显式锁并不是一种替代内置加锁的方式,而是当内置加锁机制(synchronized)不适用时,作为一种可选择的高级功能。
Lock与ReentrantLock
Lock提供了一种无条件的、可轮询的、定时的以及可中断的锁获取操作,所有加锁和解锁的方法都是显式的。在Lock的实现中必须提供与内部锁相同的内存可见性语义,但在加锁语义、调度算法、顺序保证以及性能特性等方面可以有所不同。Lock接口定义如下:
public interface Lock {
void lock();
void lockInterruptibly() throws InterruptedException;
boolean tryLock();
boolean tryLock(long timeout, TimeUnit unit) throws InterruptedException;
void unlock();
Condition newCondition();
}
ReentrantLock实现了Lock接口。ReentrantLock提供了与synchronized相同的互斥性和内存可见性。在获取ReentrantLock时,有着与进入同步代码块相同的内存语义,在释放ReentrantLock时,也有着与退出同步代码块相同的内存语义。此外,与synchronized一样,ReentrantLock还提供可重入的加锁语义。
ReentrantLock与synchronized不同的是,它还为处理锁的不可用性问题提供了更高的灵活性。
尽管内置锁在大多数情况下都能很好的工作,但在功能上存在一些局限性。如无法中断一个正在等待获取锁的线程,或者无法在请求获取一个锁时无限地等待下去。内置锁必须在获取该锁的代码块中释放,这虽然简化了编码工作,并且与异常处理操作实现了很好的交互,但却无法实现非阻塞结构的加锁规则。显式锁,作为一种灵活加锁机制,能提供更好的活跃性和性能。
Lock接口的标准使用形式如下:
Lock lock = new ReentrantLock();
...
lock.lock();
try {
// 更新对象状态
// 捕获异常,并在必要时恢复不可变条件
} finally {
lock.unlock();
}
注意,在使用Lock时,必须在finally中显式释放锁。未避免忘记释放锁(因为需要主动释放锁,所以存在未释放锁的风险),可以使用“未释放锁”检查器进行检查。
轮询锁和定时锁
Lock接口提供了多种锁获取模式。可定时的与可轮询的锁获取模式是由tryLock方法实现的,与无条件的锁获取模式相比,tryLock具有更完善的错误恢复机制。在内置锁中,死锁是一个严重的问题,恢复程序的唯一方法是重新启动程序,而防止死锁的唯一方法是在构造程序时避免出现不一致的锁顺序。可定时的锁与可轮询的锁提供了另一种选择:避免死锁的发生。
如果不能获得所有需要的锁,那么可以使用可定时的或可轮询的锁获取方式,从而重新获取控制权,释放已获得的锁,然后重新尝试获取所有锁。这里以使用tryLock获取两个锁,如果不能同时获得,那么就回退并重新尝试为例,其代码如下:
while(true) {
if(A.lock.tryLock()) {
try {
if(B.lock.tryLock()) {
try {
...
} finally {
B.lock.unlock();
}
}
} finally {
A.lock.unlock();
}
}
...
}
在实现具有时间限制的操作时,定时锁同样非常有用。当在带有时间限制的操作中调用一个阻塞方法时,它能根据剩余时间来提供一个时限。如果操作不能在指定的时间内给出结果,那么就会使程序提前结束。当使用内置锁时,在开始请求锁后,这个操作将无法取消,因此内置锁很难时限带有时间限制的操作。
使用定时的tryLock方式示例如下:
long nanosToLock = unit.ToNanos(timeout) - estimateNanosToSend(message);
if(!lock.tryLock(nanosToLock, NANOSECONDS)){
return false;
}
try {
return ...;
} finally {
lock.unlock();
}
可中断的锁获取
正如定时的锁获取操作能在带有时间限制的操作中使用独占锁,可中断的锁获取操作同样能在可取消的操作中使用加锁。lookInterruptibly方法能在获得锁的同时保持对中断的响应,并且由于它包含在Lock中,因此无需创建其他类型的不可中断阻塞机制。 示例代码如下:
...
lock.lockInterruptibly();
try {
...
} finally {
lock.unlock();
}
...
非块结构加锁
在内置锁中,锁的获取和释放等操作都是基于代码块的————释放锁的操作总是与获取锁的操作处于同一个代码块,而不考虑控制权如何退出该代码块。自动的锁释放操作简化了对程序的分析,避免了可能的编码错误,但有时需要更灵活的加锁规则。
通过降低锁的粒度可以提高代码的可伸缩性。锁分段技术就是一个很好的体现。可以采用类似的原则来降低链表中锁的粒度,即为每个链表节点使用一个独立的锁,使不同的线程可以独立地对链表的不同部分进行操作。每个节点的锁将保护链接指针以及在该节点中存储的数据,因此当遍历或修改链表时,必须持有该节点上的这个锁,直到获得下一个节点的锁,只有这样,才能释放前一个节点的锁。这种技术可称为“连锁式加锁(Hand-Over-Hand Locking)”或者“锁耦合(Lock Coupling)”。
性能因素
对于同步原语来说,竞争性能是可伸缩性的关键因素:如果有越多的资源耗费在锁的管理和调度上,那么应用程序得到的资源就越少。锁的实现方式越好,将需要越少的系统调度和上下文切换,并且在共享内存总线上的内存同步信号量也越少,而一些耗时的操作将占用应用程序的计算资源。
注意,性能是一个在不断变化的评价指标,且变化的非常快。在Java 6以后,内置锁的性能和ReentrantLock性能差异不大。
公平性
在ReentrantLock的构造函数中提供两种公平性选择:创建一个非公平的锁(默认)或一个公平的锁。在公平的锁上,线程将按照发出请求的顺序获得锁,但在“非公平”的锁上,允许“插队”:当一个线程请求非公平锁时,如果在发出请求的同时,该锁的状态变为可用,那么这个线程将跳过队列中所有的等待线程并获得这个锁。非公平的ReentrantLock并不提倡“插队”行为,但无法防止某个线程在合适的时候进行“插队”。在非公平的锁中,只有当锁被某个线程持有时,新发出请求的线程才会被放入队列中。
在大多数情况下,非公平锁的性能要高于公平锁的性能。在激烈的竞争中,非公平锁的性能高于公平锁的性能的一个原因是:在恢复一个被挂起的线程与该线程真正开始运行之间存在严重的延迟。
与默认的ReentrantLock一样,内置加锁并不会提供确定的公平性保证,但在大多数情况下,在锁实现上实现统计上的公平性保证已经足够了。
synchronized与ReentrantLock对比
ReentrantLock在加锁和内存上提供的语义与内置锁相同,此外它还提供了一些其他功能,包括定时的锁等待、可中断的锁等待、公平性,以及实现非块结构的加锁等。
与ReentrantLock等显式锁相比,内置锁仍具有极大优势。首先,内置锁被广大开发人员锁熟悉,且简洁紧凑,而且在许多现有的程序中都已经使用了内置锁。其次,ReentrantLock的危险性要比同步机制高,因为ReentrantLock要求在finally中调用unlock。所以,仅当内置锁无法满足需求时,才可以考虑使用ReentrantLock。(ReentrantLock是内置锁的补充,而不是替代)
另外,未来更可能会提升synchronized而不是ReentrantLock的性能。因为synchronized是JVM的内置属性,它能执行一些优化(如对线封闭的锁对象的锁消除优化),而如果通过基于类库的锁来实现这些功能,则可能性不大。
读-写锁
ReentrantLock实现一种标准的互斥锁:每次最多只有一个线程能持有ReentrantLock。对于维持数据的完整性,互斥通常是一种过于强硬的加锁规则,因此在某些场景下会限制并发性。互斥是一种保守的加锁策略,虽然可以避免“写/写”冲突和“写/读”冲突,但也避免了“读/读”冲突。对于“读多写少”的场景,这显然不合适。只要每个线程都能确保读到最新的数据,并且在读取数据时,不会有其他的线程修改数据,那么就不会发生问题。在这种情况下,就可以使用读/写锁:一个资源可以被多个读操作访问,或者被一个写操作访问,但两者不能同时进行。
ReadWriteLock暴露了两个Lock对象,其中一个用于读操作,另一个用于写操作。要读取有ReadWriteLock保护的数据,必须首先获得读取锁,当需要修改ReadWriteLock保护的数据时,必须首先获得写入锁。尽管这两个锁看上去是彼此独立的,但读取锁和写入锁只是“读-写锁”对象的不同视图。ReadWriteLock接口定义如下:
public interface ReadWriteLock {
Lock readLock();
Lock writeLock();
}
读写锁的读取锁和写入锁之间的交互可以采用多种实现方式。一些可选实现包括:
(1) 释放优先。当一个写入操作释放写入锁时,并且队列中同时存在读线程和写线程,可以选择优先释放的线程(读线程,写线程,最先发出请求的线程)。
(2) 读线程插队。如果锁是由读线程持有,但有写线程正在等待,那么新到达的读线程能否立即获得访问权,还是在写线程后等待。
(3) 重入性。读取锁和写入锁是否设置成可重入。
(4) 降级。如果一个线程持有写入锁,那么它能否在不释放该锁的情况下获得读取锁?
(5) 升级。读取锁能否优先于其他正在等待的读线程和写线程而升级为一个写入锁?
ReentrantReadWriteLock为这两种锁提供了可重入的加锁语义。ReentrantReadWriteLock在构造时,也可以选择是一个非公平的锁(默认)还是一个公平的锁。
ReentrantReadWriteLock中的写入锁只能有唯一的所有者,并且只能由获得该锁的线程来释放。
使用读—写锁来包装Map的示例代码如下:
public class ReadWriteMap<K,V> {
private final Map<K,V> map;
private final ReadWriteLock lock = new ReentrantReadWriteLock();
private final Lock readLocker = lock.readLock();
private final Lock writeLocker = lock.writeLock();
public ReadWriteMap(Map<K,V> map) {
this.map = map;
}
public V put(K key, V value) {
writeLocker.lock();
try {
return map.put(key, value);
} finally {
writeLocker.unlock();
}
}
// Map上其他写操作也执行相同的操作
...
public V get(Object key) {
readLocker.lock();
try {
return map.get(key);
} finally {
readLocker.unlock();
}
}
// Map上其他读操作也执行相同的操作
...
}
总结
与内置锁相比,显式锁提供了一些扩展功能,有着更高的灵活性。但ReentrantLock不能完全替代synchronized,只有在synchronized无法满足需求时,才应使用它。
锁优化
高效并发是从JDK 1.5到JDK 1.6的一个重要改进。其中一个特性就是各种锁优化技术。如适应性自旋锁(Adaptive Spinning)、锁消除(Lock Elimination)、锁粗化(Lock Coarsening) 、轻量级锁(Lightweight Locking)、偏向锁(Biased Locking)。
目的:高效的共享数据、以及解决竞争问题,从而提高程序的执行效率。
适应性自旋锁(Adaptive Spinning)
互斥同步对性能最大的影响是阻塞的实现,挂起线程和恢复线程的操作都需要转入内核态中完成,这些操作给系统的并发性能带来了很大的压力。另一方面,许多应用的共享数据的锁定状态只会持续很短的一段时间,为了这段时间去挂起和恢复线程并不值得。如果可以让后面请求锁的线程“稍等一下”,但不放弃处理器的执行时间,查看持有锁的线程是否很快就会释放锁。为了让线程等待,我们只需让线程执行一个忙循环(自旋),这项技术就是所谓的自旋锁。
自旋锁在 JDK 1.4.2 引入,默认是关闭的。在JDK 1.6改为默认开启。自旋等待不能代替阻塞,自旋等待本身虽然避免了线程切换的开销,但它还是要占用处理器时间的,因此,如果锁被占用的时间很短,自旋等待的效果就会非常好,反之,如果锁被占用的时间很长,那么自旋的线程只会白白消耗处理器资源,反而会带来性能上的浪费。因此,自旋等待的时间必须要有一定的限度,如果自旋超过了限定的次数仍然没有成功获得锁,就应当使用传统的方式去挂起线程了。自旋次数的默认值是10次,用户可以使用参数-XX:PreBlockSpin来更改。
JDK 1.6引入自适应的自旋锁。自适应意味自旋的时间不再固定,而是由前一次在同一个锁上的自旋时间及锁的拥有者的状态来决定。如果在同一个锁对象上,自旋等待刚刚成功获得过锁,并且持有锁的线程正在运行中,那么虚拟机就会认为这次自旋也很有可能再次成功,进而它将允许自旋等待持续相对更长的时间,比如100个循环。另外,如果对于某个锁,自旋很少成功获得过,那在以后要获取这个锁时将可能省略掉自旋过程,以避免浪费处理器资源。
锁消除(Lock Elimination)
锁消除是指虚拟机即时编译器在运行时,对代码上要求同步,但是被检测到不可能存在共享数据竞争的锁进行消除。锁消除的主要判定依据来源于逃逸分析的数据支持,如果判断在一段代码中,堆上的所有数据都不会逃逸出去从而被其他线程访问到,那就可以把它们当做栈上数据对待,认为它们是线程私有的,同步加锁自然就无须进行。代码示例如下:
// 看似没有同步的代码
public String concatString(String str1,String str2,String str3){
return str1 + str2 + str3;
}
// // Javac转化后的代码
// public String concatString(String str1,String str2,String str3){
// StringBuffer stringbuffer = new StringBuffer();
// stringbuffer.append(str1); // 该方法是一个同步方法,下同
// stringbuffer.append(str2);
// stringbuffer.append(str3);
// return stringbuffer.toString();
// }
锁粗化(Lock Coarsening)
原则上,总是推荐将同步块的作用范围限制得尽量小————只在共享数据的实际作用域中才进行同步,这样是为了使得需要同步的操作数量尽可能变小,如果存在锁竞争,那等待锁的线程也能尽快拿到锁。
大部分情况下,上面的原则都是正确的,但是如果一系列的连续操作都对同一个对象反复加锁和解锁,甚至加锁操作是出现在循环体中的,那么这类频繁的互斥同步操作会导致不必要的性能损耗。
如果虚拟机探测到有这样一串零碎的操作都对同一个对象加锁,将会把加锁同步的范围扩展(粗化)到整个操作序列的外部,这样只需要加锁一次就可以了。
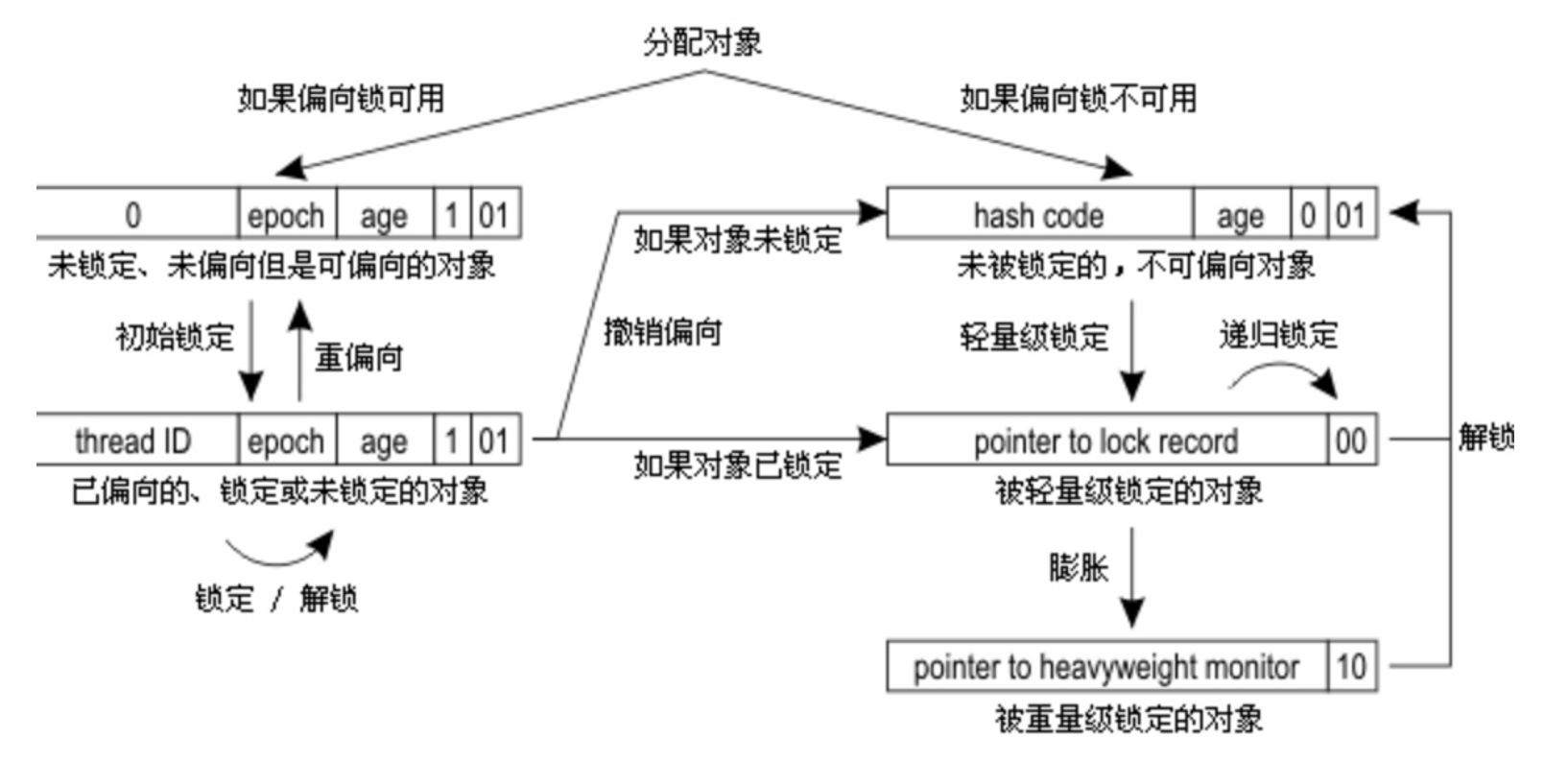
轻量级锁(Lightweight Locking)
轻量级锁是JDK 1.6 加入的新型锁机制,它名字中的“轻量级”是相对于使用操作系统互斥量来实现的传统锁而言的,因此传统的锁机制就称为“重量级”锁(如 synchronized 关键字,Lock对象等)。首先需要强调一点的是,轻量级锁并不是用来代替重量级锁的,它的本意是在没有多线程竞争的前提下,减少传统的重量级锁使用操作系统互斥量产生的性能消耗。
要理解轻量级锁,必须先从HotSpot虚拟机的对象(对象头部分)的内存布局开始介绍。HotSpot虚拟机的对象头(Object Header)分为两部分信息,第一部分用于存储对象自身的运行时数据,如哈希码(HashCode)、GC分代年龄(Generational GC Age)等,这部分数据的长度在32位和64位的虚拟机中分别为32bit和64bit,官方称它为“Mark Word”,它是实现轻量级锁和偏向锁的关键。另外一部分用于存储指向方法区对象类型数据的指针,如果是数组对象的话,还会有一个额外的部分用于存储数组长度。图表如下:

对象头信息是与对象自身定义的数据无关的额外存储成本,考虑到虚拟机的空间效率,Mark Word被设计成一个非固定的数据结构以便在极小的空间内存储尽量多的信息,它会根据对象的状态复用自己的存储空间(Mark Word 空间可复用)。例如,在32位的HotSpot虚拟机中对象未被锁定的状态下,Mark Word的32bit空间中的25bit用于存储对象哈希码(Hash Code),4bit用于存储对象分代年龄,2bit用于存储锁标志位,1bit固定为0,在其他状态(轻量级锁定、重量级锁定、GC标记、可偏向)下对象的存储表示如下图:

轻量级锁获取过程
轻量级锁加锁的前提是“同步对象锁状态为无锁状态”。主要有如下步骤:
(1)代码进入同步块(如synchronized修饰的代码块)时,如果同步对象锁状态为无锁状态(锁标识位为“01”状态,是否为偏向锁标识位为“0”),虚拟机首先将在当前线程的栈帧中建立一个名为锁记录(Lock Record)的空间,用于存储锁对象目前的Mark Word的拷贝,官方称之为 Displaced Mark Word。这时候线程堆栈与对象头的状态如下:
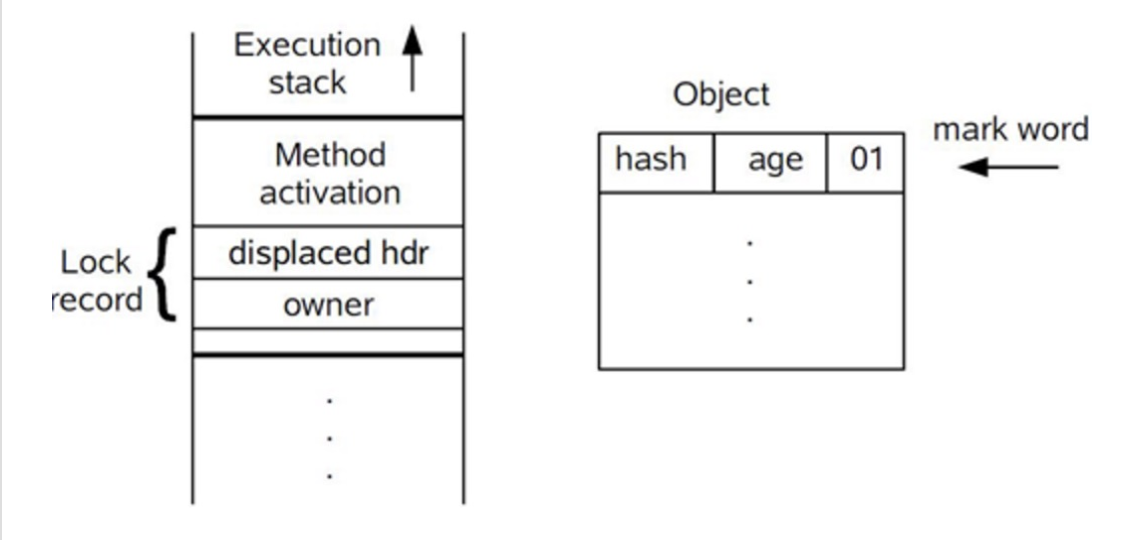
(2)拷贝对象头中的Mark Word复制到当前线程的锁记录(Lock Record)中。
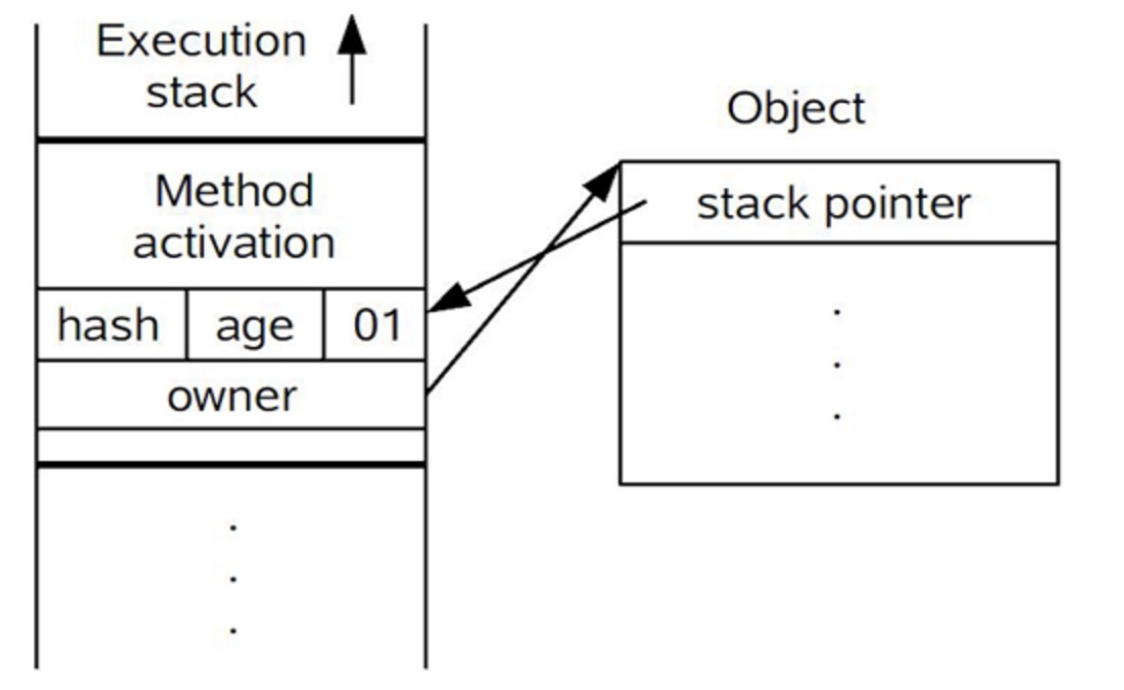
(3)拷贝成功后,虚拟机将使用CAS操作尝试将对象的Mark Word更新为指向Lock Record的指针,并将Lock Record里的owner指针指向对象的Mark Word。如果更新成功,则执行步骤(4),否则执行步骤(5)。
(4)如果更新动作成功,那么这个线程就拥有了该对象的锁,并且对象Mark Word的锁标志位设置为“00”,即表示此对象处于轻量级锁定状态,这时候线程堆栈与对象头的状态如下图。
(5)如果更新操作失败,虚拟机首先会检查对象的Mark Word是否指向当前线程的栈帧,如果是就说明当前线程已经拥有了这个对象的锁,那就可以直接进入同步块继续执行。否则说明多个线程竞争锁,轻量级锁就要膨胀为重量级锁,锁标志的状态值变为“10”,Mark Word中存储的就是指向重量级锁(互斥量)的指针,后面等待锁的线程也要进入阻塞状态。 而当前线程便尝试使用自旋来获取锁,自旋就是为了不让线程阻塞,而采用循环去获取锁的过程。
轻量级锁释放过程
(1)通过 CAS 操作尝试把线程中复制的Displaced Mark Word对象替换当前的Mark Word。
(2)如果替换成功,整个同步过程就完成了。
(3)如果替换失败,说明有其他线程尝试过获取该锁(此时锁已膨胀),那就要在释放锁的同时,唤醒被挂起的线程(自旋锁对象优先获取该锁)。
轻量级锁适用场景
轻量级锁实现同步性能提高的前提是“对于绝大部分的锁,在整个同步周期内都是不存在竞争的”这一场景。
如果存在锁竞争,那么相比重量级锁,轻量级锁还会增加CAS操作,从而降低性能。
偏向锁(Biased Locking)
引入偏向锁是为了在无多线程竞争的情况下尽量减少不必要的轻量级锁执行路径,因为轻量级锁的获取及释放依赖多次CAS原子指令,而偏向锁只需要在置换ThreadID的时候依赖一次CAS原子指令(由于一旦出现多线程竞争的情况就必须撤销偏向锁,所以偏向锁的撤销操作的性能损耗必须小于节省下来的CAS原子指令的性能消耗)。上面说过,轻量级锁是为了在线程交替执行同步块时提高性能,而偏向锁则是在只有一个线程执行同步块时进一步提高性能。
偏向锁获取过程
(1)访问Mark Word中偏向锁的标识位是否设置成1,锁标识位是否为01——确认为可偏向状态。
(2)如果为可偏向状态,则测试线程ID是否指向当前线程,如果是,进入步骤(5),否则进入步骤(3)。
(3)如果线程ID并未指向当前线程,则通过CAS操作竞争锁。如果竞争成功,则将Mark Word中线程ID设置为当前线程ID,然后执行(5);如果竞争失败,执行(4)。
(4)如果CAS获取偏向锁失败,则表示有竞争。当到达全局安全点(safepoint)时获得偏向锁的线程被挂起,偏向锁升级为轻量级锁,然后被阻塞在安全点的线程继续往下执行同步代码。
(5)执行同步代码。
偏向锁释放过程
偏向锁的释放在上述第四步骤中有提到。偏向锁只有遇到其他线程尝试竞争偏向锁时,持有偏向锁的线程才会释放锁,线程不会主动去释放偏向锁。偏向锁的撤销,需要等待全局安全点(在这个时间点上没有字节码正在执行),它会首先暂停拥有偏向锁的线程,判断锁对象是否处于被锁定状态,撤销偏向锁后恢复到未锁定(标志位为“01”)或轻量级锁(标志位为“00”)的状态。
重量级锁、轻量级锁和偏向锁之间转换
基础构建模块(容器-含并发)
非线程安全容器类
在非线程安全容器中,HashMap的使用频率极高。这里重点介绍下HashMap。
HashMap
JDK1.8对HashMap底层的实现进行了优化,例如引入红黑树的数据结构和优化扩容实现等等。本文结合JDK1.7和JDK1.8的区别,深入探讨HashMap的结构实现和功能原理。
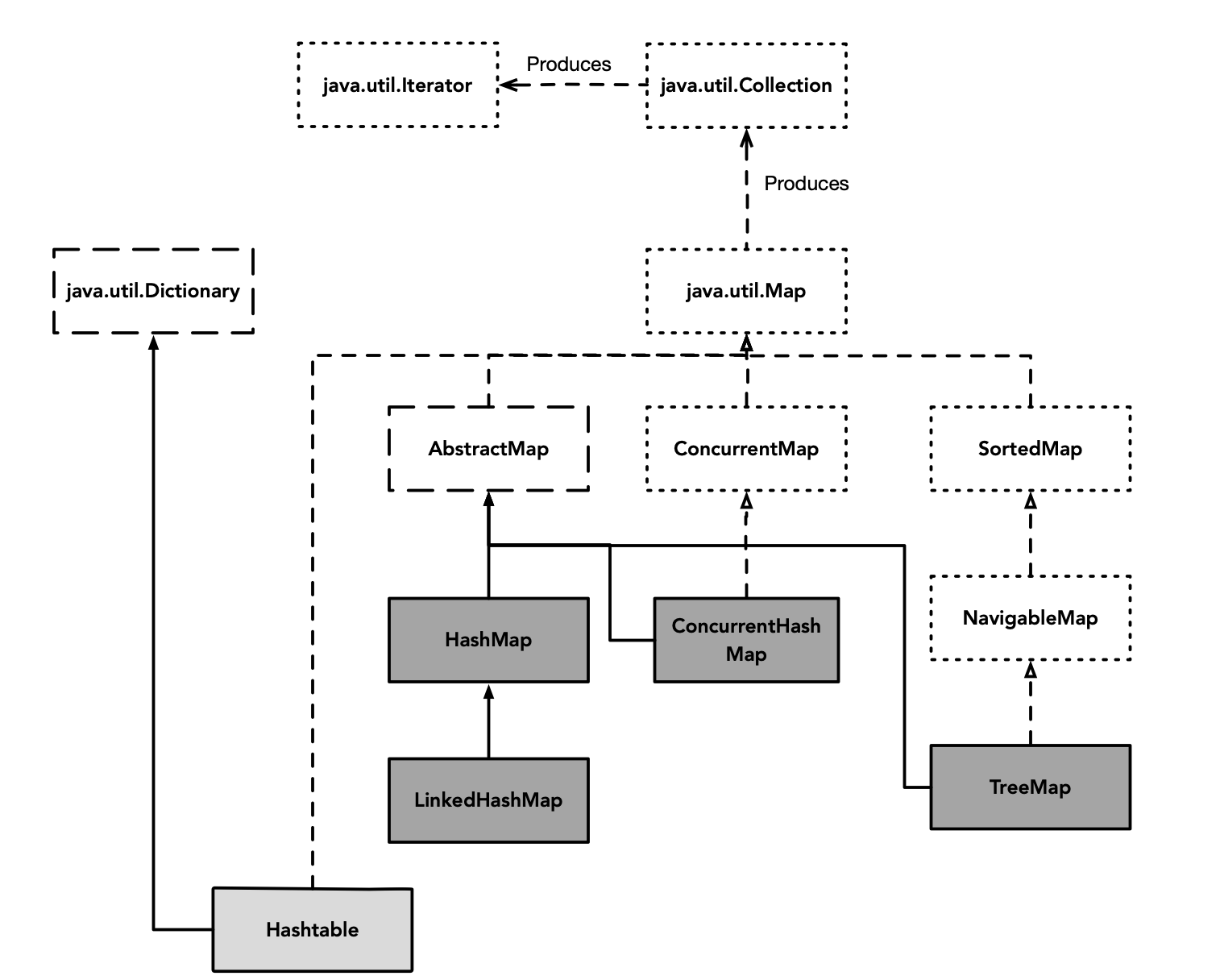
1 HashMap基于数组+链表+红黑树(JDK1.8增加红黑树部分)实现
(1)HashMap 使用 Node[] table(哈希桶数组)存储键值对
Node实体结构如下:
static class Node<K,V> implements Map.Entry<K,V> {
final int hash; //用来定位数组索引位置
final K key;
V value;
Node<K,V> next; //链表的下一个node, 使用链表处理哈希冲突
Node(int hash, K key, V value, Node<K,V> next) {
... }
public final K getKey(){
... }
public final V getValue() {
... }
public final String toString() {
... }
public final int hashCode() {
... }
public final V setValue(V newValue) {
... }
public final boolean equals(Object o) {
... }
}
(2)HashMap使用链表处理冲突
哈希表无法避免冲突。为解决冲突,HashMap使用链地址法来解决问题(其他的处理冲突的方法还有:开放定址法、再哈希法、建立公共溢出区等)。链地址法,就是在每个数组元素上添加一个链表结构,当数据被Hash后,得到数组下标,把数据放在对应下标元素的链表上。
(3)HashMap使用红黑树解决链表过长的问题
即使负载因子(Load Factor)和Hash算法设计再合理,也无法避免会处理冲突的链表过长的问题。当链表过长时,会降低Hash的性能(从O(1)降到O(n))。为较少链表在这种场景下带来的性能问题,JDK1.8 引入红黑树。
当链表长度太长(TREEIFY_THRESHOLD = 8)时,链表就转换为红黑树。
红黑树是一种特殊的有序二叉树,其插入、删除、查找的时间复杂度位O(log N),因其支持自平衡,所以其性能在最坏场景下,要优于有序二叉树。更多红黑树数据结构的工作原理可以参考教你初步了解红黑树一文。
(4)HashMap支持自动化扩容
在 HashMap 中 Node[] table的初始化长度(length)默认值是16,负载因子(Load factor)默认值是0.75,最大容量(threshold)是HashMap所能容纳的最大数据量的Node(键值对)个数,threshold = length * Load factor。
当HashMap中存储数据超过 threshold,就需要重新resize(扩容),扩容后的HashMap容量是之前容量的两倍。在HashMap中,table的长度length大小必须为2的n次方(一定是合数),这是一种非常规的设计,常规的设计是把桶的大小设计为素数。相对来说素数导致冲突的概率要小于合数,具体证明可以参考为什么一般hashtable的桶数会取一个素数一文。Hashtable初始化桶大小为11,就是桶大小设计为素数的应用(Hashtable扩容后不能保证还是素数)。HashMap采用这种非常规设计,主要是为了在取模和扩容时做优化,同时为了减少冲突,HashMap定位哈希桶索引位置时,也加入了高位参与运算的过程。
注意,默认的负载因子0.75是对空间和时间效率的一个平衡选择,建议大家不要修改,除非在时间和空间比较特殊的情况下,如果内存空间很多而又对时间效率要求很高,可以降低负载因子Load factor的值;相反,如果内存空间紧张而对时间效率要求不高,可以增加负载因子loadFactor的值,这个值可以大于1。
另外,HashMap使用 size 表示实际存在的键值对数量。
2 HashMap是非线程安全
HashMap非线程安全,即任一时刻可以有多个线程同时写HashMap,可能会导致数据的不一致。如果需要满足线程安全,可以用 Collections的synchronizedMap方法包装HashMap,使其具有线程安全的能力,或者使用ConcurrentHashMap。
3 Fast-fail
在使用迭代器的过程中如果HashMap被修改,那么ConcurrentModificationException将被抛出,也即Fast-fail策略。具体实现如下:
当HashMap的iterator()方法被调用时,会构造并返回一个新的EntryIterator对象,并将EntryIterator的expectedModCount设置为HashMap的modCount(该变量记录了HashMap被修改的次数)。
HashIterator() {
expectedModCount = modCount;
Node<K,V>[] t = table;
current = next = null;
index = 0;
if (t != null && size > 0) {
// advance to first entry
do {
} while (index < t.length && (next = t[index++]) == null);
}
}
在通过该Iterator的next方法访问下一个Entry时,它会先检查自己的expectedModCount与HashMap的modCount是否相等,如果不相等,说明HashMap被修改,直接抛出ConcurrentModificationException。该Iterator的remove方法也会做类似的检查。该异常的抛出意在提醒用户及早意识到线程安全问题。
线程安全解决方案
单线程条件下,为避免出现ConcurrentModificationException,需要保证只通过HashMap本身或者只通过Iterator去修改数据,不能在Iterator使用结束之前使用HashMap本身的方法修改数据。因为通过Iterator删除数据时,HashMap的modCount和Iterator的expectedModCount都会自增,不影响二者的相等性。如果是增加数据,只能通过HashMap本身的方法完成,此时如果要继续遍历数据,需要重新调用iterator()方法从而重新构造出一个新的Iterator,使得新Iterator的expectedModCount与更新后的HashMap的modCount相等。
多线程条件下,可使用Collections.synchronizedMap方法构造出一个同步Map,或者直接使用线程安全的ConcurrentHashMap。
同步容器类
同步容器类将状态封住起来,并对每个公有方法进行同步,使得每次只有一个线程能够访问容器的状态(使用synchronized关键字修饰)。
同步容器类都是线程安全的,但无法保证“绝对线程安全”(同步容器类在执行某些场景的复合操作时,需要额外的客户端加锁来保护),且不支持并发操作。
在同步容器中,介绍下最早出现的Vector。
Vector
Vector是 JDK 1.0 版本提供的同步容器类,并在JDK 1.2中实现了Collection接口。随着JDK版本的不断更新,这个类已经逐渐被弃用。
1 Vector 基于动态数组实现
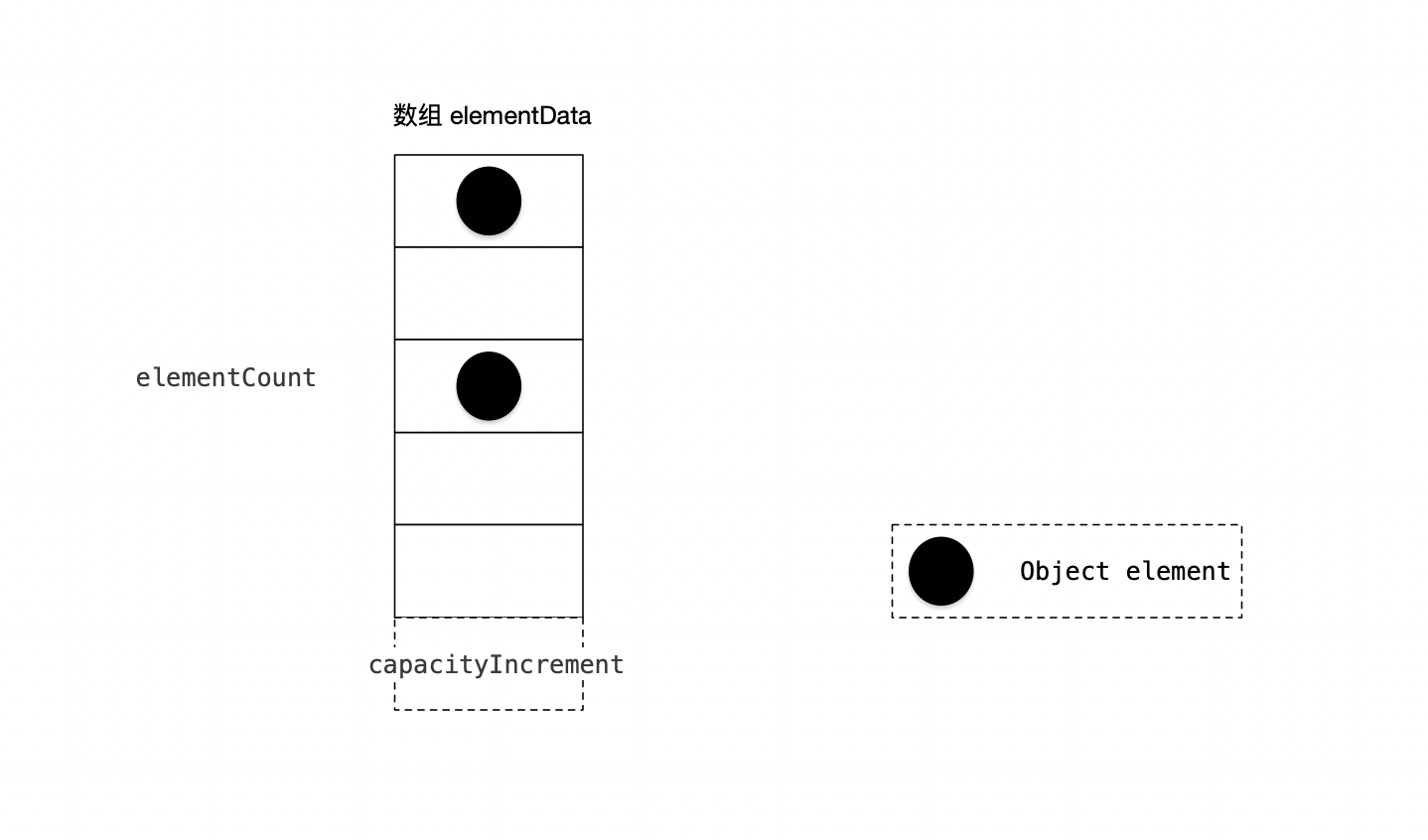
(1) Object[] elementData 数组保存添加到Vector中的元素。elementData是个动态数组,默认值大小10。随着Vector中元素的增加,Vector的容量也会,根据capacityIncrement动态增长。
(2) elementCount 是数组的实际大小。
(3) capacityIncrement 是动态数组的增长系数。在创建Vector时,可指定capacityIncrement的大小。当capacityIncrement值小于等于0,或者未设置时,Vector中将增长一倍。
(4) Vector的克隆函数,会将全部元素克隆到一个数组中。
private void grow(int minCapacity) {
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + ((capacityIncrement > 0) ?
capacityIncrement : oldCapacity);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
elementData = Arrays.copyOf(elementData, newCapacity); // 将全部元素克隆到新数组
}
2 Vector是线程安全
Vector作为同步容器类,通过将状态封住起来,并对每个公有方法进行同步,使得每次只有一个线程能够访问容器的状态(使用synchronized关键字修饰)。
代码示例如下:
public class Vector<E>
extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
protected Object[] elementData;
protected int elementCount;
protected int capacityIncrement;
// 公有方法均使用 synchronized 修饰
public synchronized int capacity() {
return elementData.length;
}
public synchronized int size() {
return elementCount;
}
// 其他公共方法
...
}
3 Vector上某些复合操作存在非线程安全问题
Vector作为同步容器类无法保证“绝对线程安全”(同步容器类在执行某些场景的复合操作时,需要额外的客户端加锁来保护),且不支持并发操作。
容器上常见的复合操作有迭代(反复访问元素,制动遍历完容器中所有元素),跳转(根据指定顺序找到当前元素的下一个元素)以及条件运算,等等。 同步容器类中,容器被多个线程并发修改时,可能会出现意料之外的行为。实例如下:
对 Vector 封装两个方法:getLast、deleteLast,都会“先检查再运行”操作。完整代码如下:
public static Object getLast(Vector vec){
int lastIndex=vec.size()-1;
return vec.get(lastIndex);
}
public static Object deleteLast(Vector vec){
int lastIndex=vec.size()-1;
return vec.remove(lastIndex);
}
从方法调用的角度来看,如果线程A在10个元素中调用getLast,线程B调用deleteLast。当线程B在线程A读取lastIndex后执行时,线程A在执行getLast时,将抛出ArrayIndexOutOfBoundsException异常(数组越界)。
所以, 同步容器类要遵循同步策略,即客户端加锁。示例代码如下:
public static Object getLast(Vector vec){
synchronized(vec){
int lastIndex=vec.size()-1;
return vec.get(lastIndex);
}
}
public static Object deleteLast(Vector vec){
synchronized(vec){
int lastIndex=vec.size()-1;
return vec.remove(lastIndex);
}
}
并发容器
同步容器在高并发场景下存在性能问题(本质是使用串行方式处理并发问题)。随着并发技术的发展和稳定,出现了越来越多的并发容器。Java 5.0提供了多种并发容器来改进同步容器的性能。如果说同步容器是将所有对容器状态的访问串行化,那么并发容器时针对多个线程多个线程并发访问设计的。
ConcurrentHashMap
Java 7为实现并行访问,引入了Segment这一结构,实现了分段锁,理论上最大并发度与Segment个数相等。Java 8为进一步提高并发性,摒弃了分段锁的方案,而是直接使用一个大的数组。同时为了提高哈希碰撞下的寻址性能,Java 8在链表长度超过一定阈值(8)时将链表(寻址时间复杂度为O(N))转换为红黑树(寻址时间复杂度为O(long(N)))。
put操作和get操作
对于put操作,如果Key对应的数组元素为null,则通过CAS操作将其设置为当前值。如果Key对应的数组元素(也即链表表头或者树的根元素)不为null,则对该元素使用synchronized关键字申请锁,然后进行操作。如果该put操作使得当前链表长度超过一定阈值,则将该链表转换为树,从而提高寻址效率。
对于读操作,由于数组被volatile关键字修饰,因此不用担心数组的可见性问题。同时每个元素是一个Node实例(Java 7中每个元素是一个HashEntry),它的Key值和hash值都由final修饰,不可变更,无须关心它们被修改后的可见性问题。而其Value及对下一个元素的引用由volatile修饰,可见性也有保障。
阻塞队列和生产者——消费者模式
Java 5.0增加了新的容器类型:BlockingQueue。类库中包含BlockingQueue的多种实现。如LinkedListBlockingQueue和ArrayBlockingQueue是FIFO队列,二者分别于LinkedList和ArrayList类似,但比同步List拥有更好的并发性能。PriorityBlockingQueue是一个按照优先级排序的队列,当希望按照某种特定的顺序处理元素时,这个队列将非常有用。SynchronousQueue则不是一个真正的队列,因为它不会为队列中的元素维护存储空间。它维护一组线程,这些线程在等待着把元素加入或移出队列。
双端队列和工作密取
Java 6增加了两种容器类型:Deque(发音为"deck")和BlockingQueue,它们分别对Queue和BlockingQueue进行了扩展。Deque是一个双端队列,实现了队列头和队列尾的高效插入和移除。具体实现包括:ArrayDeque和LinkedBlockingQueue。
同步工具类
同步工具类可以是任何一个对象,只要它根据其自身的状态来协调线程的控制流。阻塞队列(BlockingQueue)可以作为同步工具类,其他类型的同步工具类还包括闭锁(Latch)、信号量(Semaphore)以及栅栏(Barrier)等。除了使用平台类库提供的同步工具类外,还可以创建自己的同步工具类。
闭锁
闭锁时一种同步工具类,可以延迟线程的进度直到其到达终止状态。闭锁的作用相当于一扇门:在闭锁到达结束状态之前,这扇门一直是关闭的,并且没有任何线程能通过,当到达结束状态时,这扇门会打开并允许所有的线程通过。当闭锁到达结束状态后,将不会再改变状态,因此这扇门将永远保持打开状态。闭锁可以用来确保某些活动直到其他活动都完成后才继续执行,如:
(1) 确保某个计算在其需要的所有资源都被初始化后才继续执行。
(2) 确保某个服务在其依赖的所有其他服务都有已经之后才启动。
CountDownLatch
CountDownLatch是一种灵活的闭锁实现,它可以使一个或多个线程等待一组事件发生。
FutureTask
信号量
栅栏
原子变量与非阻塞同步机制
在java.util.concurrent包的许多类中,如Semaphore和ConcurrentLinkedQueue,都提供了比Synchronized机制更高的性能和可伸缩性。
近几年,在并发算法领域的大多数研究都侧重于非阻塞算法,这种算法用底层的原子机器指令(例如比较交换指令)代替锁来确保数据在并发访问中的一致性。非阻塞算法被广泛地用于操作系统和JVM中实现线程/进程调度机制、垃圾回收机制和锁和其他并发数据结构。
与基于锁的方案相比,非阻塞算法尽管在设计和实现上复杂得多,但它们在可伸缩性和活跃性上却拥有巨大的优势。非阻塞算法可使多个线程在竞争相同数据时不会发生阻塞,因此它能在粒度更细的层次上进行协调,并极大地减少调度开销。而且,在非阻塞算法中不存在死锁和其他活跃性问题。在基于锁的算法中,如果一个线程在休眠或自旋的同时持有一个锁,那么其他线程都无法执行下去,而非阻塞算法不会受到单个线程失败的影响。从Java 5.0开始,可以使用原子变量类(如AtomicInteger和AtomicReference)来构建高效的非阻塞算法。此外,原子变量除了用于非阻塞算法的开发,还可用做一种“更好的volatile类型变量”使用。原子变量除了提供与volatile类型变量相同的内存语义外,还支持原子的更新操作。
非阻塞同步机制比基于锁的阻塞同步机制,尽管设计和实现更复杂,但在可伸缩性和活跃性上却拥有巨大的优势。从Java 5.0开始,可以使用原子变量类来构建高效的非阻塞算法。原子变量除了用于非阻塞算法的开发,还可用做一种“更好的volatile类型变量”使用。原子变量除了提供与volatile类型变量相同的内存语义外,还支持原子的更新操作。
非阻塞算法在设计和实现上非常困难,但通常能提供更高的可伸缩性,并能更好的防止活跃性故障的发生。
锁的劣势
使用一致的锁定协议来协调对共享状态的访问,可以确保无论哪个线程持有守护变量的锁,都能采用独占方式来访问这些变量,并且对变量的任何修改对随后所获得这个锁的其他线程都是可见的。
如果有多个线程同时请求锁,那么JVM就需要借助操作系统的功能。如果出现这种情况,那么这些线程的挂起和恢复等过程会存在很大的开销,并且存在较长时间的中断。如果在基于锁的类中包含细粒度的操作,那么当锁上存在激烈的竞争时,调度开销与工作开销的比值会非常高。
锁还存在一些其他缺点。当一个线程正在等待锁时,它不能做任何其他事情。如果一个线程在持有锁的情况下被延迟执行,那么所有需要这个锁的情况下被延迟执行。如果被阻塞线程的优先级较高,而持有锁的线程优先级较低,那么这将是一个严重的问题————也被称为优先级反转(Priority Inversion)。如果持有锁的线程被永久地阻塞,那么所有等待这个锁的线程就永远无法执行下去。
除此之外,锁定方式对细粒度的操作来说仍是一种高开销的机制。
硬件对并发的支持
独占锁是一种悲观技术————它假设最坏的情况,并且只有在确保其他线程不会造成干扰的情况下才能执行下去。
对于细粒度的操作,还有一种更高效的方法,也是一种乐观的方法,通过这种方法可以在不发生干扰的情况下完成更新操作。
在针对多处理器操作而设计的处理器中提供了一些特殊指令,用于管理对共享数据的并发访问。现在,几乎所有的现代处理器都包含了某种形式的原子读-改-写指令,如比较并交换(Compare-and-Swap)或者关联加载/条件存储(Load-Linked/Store-Conditional)。操作系统和JVM使用这些指令来实现锁和并发的数据结构,但在Java 5.0之前,在Java类中还不能直接使用这些指令。
比较并交换(Compare-And-Swap,CAS)
在大多数处理器架构中采用的方法是实现一种比较并交换指令。CAS包含3个操作数————需要读写的内存位置V、进行比较的值A和拟写入的新值B。当且仅当V的值等于A时,CAS才会通过原子的方式用新值B来更新V的值,否则不会执行任何操作。无论位置V的值是否等于A,都将返回V原有的值。CAS的含义是:“我认为V的值应该是A,如果是,那么将V的值更新成B,否则不修改并告诉V的值实际是多少”。CAS是一项乐观技术,它希望能成功地执行操作,并且如果有另一个线程在最近一次检查后更新了该变量,那么CAS能检测到这个错误。
当多个线程尝试使用CAS同时更新同一个变量时,只有其中一个线程能更新变量的值,而其他线程都将失败。然而,失败的线程并不会被挂起,而是被告知在这次竞争中失败,并可再次尝试。这种灵活性大大减少了与锁相关的活跃性风险。
CAS的典型使用模式是:首先从V中读取A,并根据A计算新值B,然后再通过CAS以原子方式将V中的值由A变成B(只要在这期间没有任何线程将V的值修改为其他值)。由于CAS能检测到来自其他线程的干扰,因此即使不使用锁也能实现原子的读——改——写操作序列。
CAS的主要缺点是,它将使调用者处理竞争问题(通过重试,回退,放弃),而在锁定中能自动处理竞争问题(线程在获得锁之前将一直阻塞)。(事实上,CAS最大的缺点在于难以围绕着CAS正确地构建外部算法)
CAS的性能要进行实测。
JVM对CAS的支持
在Java 5.0中引入了底层的支持,在int、long和对象的引用等类型上都公开了CAS操作,并且JVM把它们编译为底层硬件提供的最有效方法。在支持CAS的平台上,运行时把它们编译为相应的(多条)机器指令。在最坏的情况下,如果不支持CAS指令,那么JVM将使用自旋锁。
在原子变量类(如java.util.conncurrent.atomic中的AtomicXxx)中使用了这些底层的JVM支持为数字类型和引用类型提供一种高效的CAS操作,而且在java.util.concurrent中大多数类在实现时则直接或间接的使用这些原子变量类。
原子变量类
原子变量比锁的粒度更细,量级更轻,并且对于在多处理器系统上实现高性能的并发代码来说是非常关键的。原子变量将发生竞争的范围缩小到单个变量上,从而获得最细的粒度。在使用基于原子变量而非锁的算法中,线程在执行时更不易出现延迟,并且如果遇到竞争,也更容易恢复过来。
原子变量类相当于一个泛化的volatile变量,能够支持原子的和有条件的读-改-写操作。以AtomicInteger为例,该原子类表示一个int类型的值,并提供get和set方法,这些volatile类型的int变量在读取和写入上有着相同的语义。它还提供了一原子的compareAndSet方法,以及原子的添加、递增和递减等方法。AtomicInteger直接利用了硬件对并发的支持,因此在发生竞争的情况下,能提供更高的可伸缩性。
共有12个原子变量类,可分为四组:标量类(Scalar)、更新器类、数组类及复合变量类。所有这些类都支持CAS,此外AtomicInteger和AtomicLong还支持算术运算。
原子的标量类没有扩展一些基本的包装类,这是因为:基本类型的包装类是不可修改的,而原子变量类是可修改的。在原子变量类中同样没有重新定义hashCode或equals方法,每个实例都是不同的。
非阻塞算法
如果在某种算法中,一个线程的失败或挂起不会导致其他线程也失败或挂起,那么这种算法被称为非阻塞算法。如果在算法的每个步骤中都存在某个线程能够执行下去,那么这种算法被称为无锁(Lock-Free)算法。如果在算法中仅将CAS用于协调线程之间的操作,并且能正确地实现,那么它既是一种无阻塞算法,又是一种无锁算法。
创建非阻塞算法的关键在于,找出如何将原子修改的范围缩小到单位变量上,同时还要维护数据的一致性。
非阻塞的栈
非阻塞的链表
原子的域更新器
原子的域更新器表示现有volatile域的一种基于反射的“视图”,从而能够在已有的volatile域上使用CAS。
ABA问题
CAS存在ABA问题。在某些算法中,如果V的值首先由A变成B,再由B变成A,那么仍然被认为是发生了变化,并需要重新执行算法中的某些步骤。
如果在算法中采用自己的方式来管理节点对象的内存,那么可能出现ABA问题。一种相对简单的解决方案是:不是更新某个引用的值,而是更新两个值,包括一个引用和一个版本号。即使这个值由A变为B,然后又变为A,版本号也将是不同的。
AtomicStampedReference将更新一个“对象-引用”二元组,通过在引用上加上“版本号”,从而避免ABA问题。
线程协作
多个线程间协同工作。构建自定义的同步工具。
类库中包含许多存在状态依赖性的类,如FutureTask、Semaphore和BlockingQueue等。在这些类的一些操作中有着基于状态的前提条件。如,不能从一个空的队列中删除元素或者不能向一个已满的队列添加元素等。
创建状态依赖类的最简单的方法通常是在类库中现有状态依赖类的基础上进行构造。但如果类库没有提供需要的功能,那么还可以使用Java语言和类库提供的底层机制来构造自己的同步机制,包括内置的条件队列、显式的Condition对象以及AbstractQueuedSynchronizer框架(简称AQS)。
状态依赖性管理
在单线程程序中调用一个方法时,如果某个基于状态的前提条件未得到满足,那么这个条件将永远无法成真。但在多线程程序中,基于状态的条件可能会由于其他线程的操作而改变。举例来说,一个资源池可能在几条指令之前还是空的,但现在却变为非空,因为另一个线程可能会返回一个元素到资源池。
所以,在编写顺序程序中的类时,要使得这些类在其前提条件未满足时就失败,而在编写并发程序中的类时,虽然有时在前提条件不满足的情况下不会失败,但通常一个更好的选择是:等待前提条件变为真。
在生产者—消费者的设计中经常会使用向ArrayBlockingQueue这样的有界缓存。在有界缓存提供的put和take操作中都包含一个前提条件:不能从空缓存中获取元素,也不能将元素放入已满的缓存中。当前提条件未满足时,依赖状态的操作可以抛出一个异常或返回一个错误状态(让调用者处理这个问题),也可以保持阻塞直到对象进入正确的状态。
接下来,将以有界缓存为例,介绍前提条件失败的处理。在实现有界缓存前,先定义一个基类BaseBoundedBuffer。在这个基类中实现了一个基于数组的循环缓存。其中缓存状态变量均使用内置锁保护,并提供同步的doPut和doTake方法,并在子类中通过这些方式实现put和take操作。BaseBoundedBuffer定义如下:
@ThreadSafe
public abstract class BaseBoundedBuffer<V> {
@GuardedBy("this") private final V[] buf;
@GuardedBy("this") private final int tail;
@GuardedBy("this") private final int head;
@GuardedBy("this") private final int count;
protected BaseBoundedBuffer(int capacity) {
this.buf = (V[]) new Object[capacity];
}
protected synchronized final void doPut(V v) {
buf[tail] = v;
if(++tail == buf.length) {
tail = 0;
}
++count;
}
protected synchronized final V doTake() {
V v = buf[head];
buf[head] = null;
if(++head == buf.length) {
head = 0;
}
--count;
return v;
}
public synchronized final boolean isFull() {
return count == buf.length;
}
public synchronized final boolean isEmpty() {
return count == 0;
}
}
将前提条件的失败传递给调用者
这里采取“先检查再运行”的逻辑策略,将前提条件的失败传递给调用者。在实现一个简单的有界缓存时,put和take方法都进行了同步,以确保实现对缓存状态的独占访问。代码实现如下:
@ThreadSafe
public class GrumpyBoundedBuffer<V> extends BaseBoundedBuffer<V> {
public GrumpyBoundedBuffer(int size) {
super(size);
}
public synchronized void put(V v) throws BufferFullException {
if(isFull()) {
throw new BufferFullException();
}
doPut(v);
}
public synchronized V take() throws BufferEmptyException {
if(isEmpty()) {
throw new BufferEmptyException();
}
return doTake();
}
}
尽管上述方式实现简单,但却带来了使用上的复杂。(典型的接口设计复杂,接口实现简单的示例)异常应该用于发生异常条件的情况中。从逻辑上来说,“缓存已满”或“缓存为空”等并不是有界缓存的一个异常条件,就像“红灯”并不代表交通信号灯出现异常一样。因为调用者在使用上述有界队列时,必须做好捕获异常的准备,并且在每次缓存操作时都需要重试,这加大了使用的复杂性。调用示例代码如下:
while(true) {
try {
V item = buffer.take();
// 使用item
break;
} catch(BufferEmptyException e) {
Thread.sleep(SLEEP_GRANULARITY);
}
}
这种方法的变化形式是:当缓存处于某种错误的状态时返回一个错误值。这种方式是“抛出异常”的改进,但这种方法并没有解决根本问题:调用者必须自行处理前提条件失败的情况。类似地,Queue提供两种选择:poll方法能在队列为空时返回null,而remove方法则抛出一个异常。但Queue并不适合在生产者–消费者设计中使用。BlockingQueue的操作只有当队列处于正确状态时才会进行处理,否则将阻塞。因此当生产者和消费者并发执行时,BlockingQueue才是更好的选择。
注意,休眠状态并不是调用者实现重试的唯一方式,也可以直接重新调用take方法或put方法。这种方法被称为忙等待或自旋等待。由于自旋等待可能会带来过多的CPU消耗(如果等待实现过长)、休眠时间过长(缓存状态在休眠后就可用),客户代码必须在这两者之间进行选择:要么容忍自旋带来的CPU时钟消耗,要么容忍由于休眠而导致的低响应性。(除了忙等待和休眠外,还可以选择调用Thread.yield来将线程转换到就绪状态)
使用轮询与休眠来实现简单的阻塞
为了避免让调用者在每次调用时都实现重试逻辑,可以在有界缓存的put方法和take方法实现一种简单的“轮询与休眠”重试机制。如果缓存为空,那么take将休眠并直到另一个线程在缓存中放入一些数据:如果缓存是满的,那么put将休眠并直到另一个线程从缓存中移除一些数据,以便有空间容纳新的数据。这种方法将前提条件的管理操作封装起来,并简化了对缓存的使用————这正是朝正确的改进方向迈进。使用简单阻塞实现的有界缓存示例代码如下:
@ThreadSafe
public class SleepyBoundedBuffer<V> extends BaseBoundedBuffer<V> {
public SleepyBoundedBuffer(int size) {
super(size);
}
public void put(V v) throws InterruptedException {
while(true) {
synchronized(this) {
if(!isFull) {
doPut(v);
return;
}
}
Thread.sleep(SLEEP_GRANULARITY);
}
}
public V take() throws InterruptedException {
while(true){
synchronized(this) {
if(!isEmpty()) {
return doTake();
}
}
Thread.sleep(SLEEP_GRANULARITY);
}
}
}
在实现put方法和take方法时,必须在持有有界缓存实体类的锁的时候才能测试相应的状态条件,因为表示状态条件的变量是由有界缓存实体类来保护的。如果检测到不满足前提条件,那么当前执行的线程将首先释放锁并休眠一段时间,从而使其他线程能够访问缓存,并在唤醒后重新请求锁,并再次尝试执行操作。因此,线程将反复地在休眠以及测试状态条件等过程之间进行切换,直到可以执行操作为止。
从调用者角度来说,调用者无需处理失败和重试,只需在响应性和CPU使用率上进行权衡。但是,该方式对调用者提出了一个新的需求:处理InterruptedException。当一个方法由于等待某个前提条件变成真而阻塞时,需要提供一种取消机制。与大多数具备良好行为的阻塞库方法一样,这里通过中断来支持取消,如果该方法被中断,那么将提前返回并抛出InterruptedException。
实际应用中,基于轮询与休眠实现的阻塞操作需要付出巨大的努力。(将这种策略应用到生产环境中,还需考虑更多问题)如果存在某种挂起线程的方法,并且这种方法能确保当某个条件满足时立即唤醒,那么将极大地简化实现工作。这正是条件队列实现的功能。
使用条件队列等待前提条件
“条件队列”使得一组线程(也将其称为等待线程集合)能够通过某种方式来等待特定的条件变成真。传统队列的元素是一个个数据,而条件队列中的元素是一个个正在等待相关条件的线程。
正如每个Java对象都可以作为一个锁,每个对象同样可以作为一个条件队列,并且Object的wait、notify和notifyAll方法就构成了内部条件队列的API。要调用对象X中条件队列的任何一个方法,必须持有对象X上的锁。这将“等待由状态构成的条件”与“维护状态一致性”两种机制紧密地绑定在一起:只有能对状态进行检查时,才能在某个条件上等待,并且只有能修改状态时,才能从条件等待中释放另一个线程。
Object.wait会自动释放锁,并请求操作系统挂起当前线程,从而使其他线程能够获得这个锁并修改对象的状态。当被挂起的线程醒来时,它将在返回之前重新获取锁。从直观上理解,调用wait意味着“我要去休息,但当发生特定的事情请唤醒我”,而调用notify或notifyAll方法则意味着“特定的事情发生了”。
使用wait和notifyAll实现的缓存队列示例代码如下:
@ThreadSafe
public class BoundedBuffer<V> extends BaseBoundedBuffer<V> {
// 条件谓词: not-full(!isFull())
// 条件谓词: not-empty(!isEmpty())
public BoundedBuffer(int size) {
super(size);
}
// 阻塞并直到:not-full
public synchronized void put(V v) throws InterruptedException {
while(isFull()) {
wait();
}
doPut(v);
notifyAll();
}
// 阻塞并直到:not-empty
public synchronized V take() throws InterruptedException {
while(isEmpty()) {
wait();
}
V v = doTake(v);
notifyAll();
return v;
}
}
最终,BoundedBuffer变得足够好:不仅简单易用,而且实现了清晰的状态依赖性管理。(后续实现可从notfiyAll优化到单一通知方法,效率更高)在产品的正式版本中,还应包括限时版本的put和take。(阻塞操作需提供限时版本和不限时版本两种)通过使用定时版本的Object.wait,可以很容易的实现这些方法。
状态依赖性管理总结
单线程程序中调用一个方法时,如果基于某个状态的前提条件未得到满足,那么这个条件就无法成真。但在多线程程序中,基于状态的条件可能会由于其他线程的操作而改变。因此在编写并发程序中的类时,虽然有时在前提条件不满足的情况下不会失败,但通常一个更好的选择是:等待前提条件变为真。也即多线程场景下“状态依赖性管理”。
当前提条件未满足时,依赖状态的操作可以抛出一个异常或返回一个错误状态(让调用者处理这个问题),也可以保持阻塞直到对象进入正确的状态。在实现阻塞时,可以通过轮询或休眠实现简单的阻塞,也可使用条件队列实现优雅的阻塞。
条件队列使用详解
条件队列使构建高效及高响应性的状态依赖类变得更容易,但同时也很容易被不正确的使用。虽然许多规则或规范能确保正确地使用条件队列,但在编译器或系统平台上却并没有强制要求遵循这些规则。(这也是为什么要尽量基于LinkedBlockingQueue、Latch、Semaphore和FutureTask等类来构造程序的原因之一)
条件谓词
要想正确地使用条件队列,就必须找出对象在哪个条件谓词上等待。条件谓词是使某个操作成为状态依赖操作的前提条件。条件谓词是由类中各个状态变量构成的表达式。在API中,并没有对条件谓词进行实例化的方法,并且在Java语言规范或JVM实现中并没有任何信息可以确保正确地使用它们。但如果没有条件谓词,条件等待机制将无法发挥作用。
在条件等待中存在一个重要的四元关系:加锁、wait方法、notify方法和一个条件谓词。在条件谓词中包含多个状态变量,而状态变量由一个锁来保护,因此在测试条件谓词之前必须先持有这个锁。锁对象和条件队列对象(调用wait和notify等方法所在的对象)必须是同一个对象。当调用某个条件谓词的wait时,调用者必须已经持有与条件队列相关的锁,并且这个锁必须保护着构成条件谓词的状态变量。
过早唤醒
在条件等待中,wait方法的返回并不一定意味着线程正在等待的条件谓词已经变成真。
首先,内置条件队列可以与多个条件谓词一起使用(一个条件队列可以与多个条件谓词相关,如BoundedBuffer中使用的条件队列与“非满”和“非空”两个条件谓词相关)。所以,当一个线程由于notfifyAll的调用而醒来后,并不一定意味着线程正在等待的条件谓词已经成真。
其次,当重新进入调用wait代码时,它已经重新获取与条件队列相关的锁。但是,条件谓词仍有可能已经不是真。在发出通知的线程调用notifyAll时,条件谓词可能已变成真,但是在重新获取锁的时,又变成了假。在线程被唤醒到wait重新获取锁的这段时间里,可能有其他线程已经获取了这个锁,并修改了对象的状态。或者,条件谓词从调用wait起,根本就没有变成真。因为这个notifyAll会唤醒所有的线程,而不仅仅是在这个条件谓词上等待的线程。
所以,每当线程从wait中唤醒时,都必须再次测试条件谓词,如果条件谓词不为真,就继续等待(或失败)。由于线程在条件谓词不为真的情况下,也可以反复地醒来,因此必须在一个循环中调用wait,并在每次迭代中都测试条件谓词。条件等待的标准形式如下:
void stateDependentMethod() throws InterruptedException {
// 必须通过一个锁来保护条件谓词
synchronized(lock) {
while(!conditionPredicate()) {
lock.wait();
}
// 此时,条件谓词为真
}
}
丢失的信号
丢失的信号是指:线程必须等待一个已经为真的条件,但在开始等待之前没有检查条件谓词。丢失的信号是另一种形式的活跃性故障。一旦丢失信号,线程将等待一个已经发生过的事件。如果线程A通知了一个条件队列,而线程B随后在这个条件队列上等待,那么线程B将不会立即醒来,而是需要另一个通知来唤醒。
所以,如果线程必须等待一个为真的条件,在开始等待前,需检查条件谓词。
通知
条件等待的前一半内容是等待,后一半内容是通知。每当在等待一个条件时,一定要确保在条件谓词变为真时,通过某种方式发出通知。
在条件队列API中有两个发出通知的方法:notify和notifyAll。无论调用哪一个,都必须持有与条件队列对象相关联的锁。在调用notify时,JVM会从这个条件队列上等待的多个线程中选择一个来唤醒,而调用notifyAll则会唤醒所有在这个条件队列上等待的线程。
由于多个线程可以基于不同的条件谓词在同一个条件队列上等待,所以如果使用notify而不是notifyAll时,将是一种危险的操作:因为单一的通知很容易导致类似于信号丢失的问题。假设线程A在条件队列上等待条件谓词PA,同时线程B在同一个条件队列上等待条件谓词PB。现在,假设PB变成真,并且线程C执行一个notify:JVM将从它拥有的众多线程中选择一个并唤醒。如果选择线程A,那么它被唤醒,但看到PA尚未成真,将继续等待。同时,线程B本可以执行,但却没有被唤醒。只能等待下一次通知。这虽不是严格意义上的“丢失信号”,但导致的问题是相同的:线程正在等待一个已经(或者本应该)发生过的信号。
只有同时满足以下两个条件时,才能使用单一的notify:
(1) 所有等待线程的类型都相同。只有一个条件谓词与条件队列相关,并且每个线程在从wait返回后将执行相同的操作。
(2) 单进单出。在条件变量上的每次通知,最多只能唤醒一个线程来执行。
由于notify方法使用场景受限,更多情况下,还是会选择使用notifyAll。然而,notifyAll会带来极大的性能开销。如果有多个线程在一个条件队列上等待,那么调用notifyAll将唤醒每个线程,并使得这些线程在锁上发生竞争。然而,它们中最多只有一个能获得锁,其他则需重新回到休眠状态。因此,在每个线程执行一次notifyAll时,将出现大量的上下文切换操作以及发生竞争的锁获取操作。
针对notifyAll存在的缺陷,可以使用“条件通知”进行优化。继续以有界缓存为例,首先,仅当缓存从空变为非空,或者从满变为非满时,才需要释放一个线程。并且仅当put或take影响到这些状态转换时,才发出通知。示例代码如下:
public synchronized void put(V v) throws InterruptedException {
while(isFull) {
wait();
}
boolean wasEmpty = isEmpty();
doPut(v);
if(wasEmpty) {
notifyAll();
}
}
虽然“条件通知”可以提升性能,但却很难正确地实现(而且会使子类的实现变得复杂,除非禁用子类扩展功能),因此在使用时应谨慎。
单次通知和条件通知都属于优化措施。通常,在使用优化措施时,应遵循“首选使程序正确地执行,然后才使其运行更快”的原则。如果不正确地使用这些优化措施,那么很容易在程序中引入奇怪的活跃性故障。
子类的安全问题
在使用条件通知或单次通知时,一些约束条件使得子类化过程变得更加复杂。要想支持子类化,那么在设计类时需要保证:如果在实施子类化时违背了条件通知或单次通知的某个需求,那么在子类中可以增加合适的通知机制来代表基类。
对于状态依赖的类,要么将其等待和通知等协议完全向子类公开(并写入正式文档),要么完全阻止子类参与到等待和通知等过程中。(要么围绕继承来设计和文档化,要么禁止使用继承)当设计一个可继承的状态依赖类时,至少需要公开条件队列和锁,并期望将条件谓词和同步策略都写入文档。此外,还可能需要公开一些底层的状态变量。另一种选择就是完全禁止子类化。如将类声明为final或将条件队列、锁和状态变量等设置为私有。
封装条件队列
由于条件队列使用时依赖一些规则或规范,而调用者会自以为理解了在等待和通知上使用的协议,并且采用一种违背设计的方式来使用条件队列,所以应把条件队列封装起来。这样,除了使用条件队列的类,就不能在其他地方访问它。
不幸的是,这条建议————将条件队列对象封装起来,与线程安全类的最常见设计模式并不一致,在这种模式中建议使用对象的内置锁来保护对象自身的状态。
入口协议与出口协议
Wellings通过“入口协议和出口协议”(Entry and Exit Protocols)来描述wait和notify方法的正确使用。对于每个依赖状态的操作,以及每个修改其他操作依赖状态的操作,都应该定义一个入口协议和出口协议。入口协议就是该操作的条件谓词,出口协议则包括,检查被该操作修改的所有状态变量,并确认它们是否使某个其他的条件谓词变为真,如果是,则通知相关的条件队列。
在AbstractQueuedSynchronizer中使用出口协议。这个类并不是由同步器类来执行自己的通知,而是要求同步器方法返回一个值来表示该类的操作是否已经解除了一个或多个等待线程的阻塞。
显式的Condition对象
除了内置的条件队列,还可以使用显式的Condition对象。Condition接口定义如下:
public interface Condition {
void await() throws InterruptedException;
boolean await(long time, TimeUnit unit) throws InterruptedException;
long awaitNanos(long nanosTimeout) throws InterruptedException;
void awaitUninterruptibly();
boolean awaitUntil(Date deadline) throws InterruptedException;
void signal();
void signalAll();
}
一个Condition和一个Lock关联在一起,就像一个条件队列和一个内置锁相关联一样。要创建一个Condition,可以在相关联的Lock上调用Lock.newCondition方法。正如Lock比内置加锁提供更加丰富的功能,Condition同样比内置条件队列提供了更丰富的功能:在每个锁上可存在多个等待、条件等待可以是可中断的或不可中断的、基于时限的等待,以及公平的或非公平的队列操作。
与内置条件队列不同的是,对于每个Lock,可以有任意数量的Condition对象。Condition对象继承了相关的Lock对象的公平性,对于公平的锁,线程会按照FIFO顺序从Condition.await中释放。
在Condition对象中,与wait、notify和notifyAll方法对应的分别是await、signal和signalAll。但是,Condition是对Object的扩展,所以她也包含wait和notify方法。在使用时,一定要确保使用正确的版本————await和signal。
使用Condition实现的有界缓存示例代码如下:
@ThreadSafe
public class ConditionBoundedBuffer<T> {
protected final Lock lock = new ReentrantLock();
// 条件谓词:notFull(count < items.length)
private final Condition notFull = lock.newCondition();
// 条件谓词:notEmpty(count > 0)
private final Condition notEmpty = lock.newCondition();
@GuardedBy("lock")
private final T[] items = (T[]) new Object[BUFFER_SIZE];
@GuardedBy("lock")
private int tail, head, count;
// 阻塞并直到:notFull
public vodi put(T x) throws InterruptedException {
lock.lock();
try {
while(count == items.length) {
notFull.await();
}
items[tail] = x;
if(+++tail == items.length) {
tail = 0;
}
++count;
notEmpty.signal();
} finally {
lock.unlock();
}
}
// 阻塞并直到:notEmpty
public T take() throws InterruptedException {
lock.lock();
try {
while(count == 0) {
notEmpty.await();
}
T x = items[head];
items[head] = null;
if(++head == items.length) {
head = 0;
}
--count;
notFull.signal();
return x;
} finally {
lock.unlock();
}
}
}
ConditionBoundedBuffer使用两个Condition把两个条件谓词分开并放到两个等待线程集中,Condition使其更容易满足单次通知的需求。signal比signalAll高效,它能大大减少在每次缓存操作中发生的上下文切换与锁请求的次数。
当使用显式的Lock和Condition时,也必须满足锁、条件谓词和条件变量之间的三元关系。在条件谓词中包含的变量必须由Lock来保护,并且在检查条件谓词及调用await和signal时,必须持有Lock对象。
可以类比在ReentrantLock和synchronzied,在显式的Condition和内置的条件队列之间进行选择:如果需要一些高级功能,可以如使用公平的队列操作或者在每个锁上对应多个等待线程集,那么应该优先使用Condition,而不是内置条件队列。
AbstractQueuedSynchronizer
许多同步类都使用了一个共同的基类AbstractQueuedSynchronizer(AQS)。AQS是一个用于构建锁和同步器的框架,许多同步器都可以通过AQS构造出来。不仅ReentrantLock和Semaphore是基于AQS构建,还包括CountDownLatch、ReentrantReadWriteLock、SynchronousQueue和FutureTask。
AQS解决了在实现同步器时涉及的大量细节问题。基于AQS来构建同步器能带来许多好处。它不仅能极大地减少实现工作,而且也不必处理在多个位置上发生的竞争问题。在设计器、AQS时充分考虑了可伸缩性,因此java.util.concurrent中所有基于AQS构建的同步器都能获得这个优势。
大多数开发者都不会直接使用AQS,标准同步器类的集合能够满足绝大多数情况的需求。但如果能了解标准同步器类的实现方式,那么对于理解它们的工作原理是非常有帮助的。
在基于AQS构建的同步器类中,最基本的操作包括各种形式的获取操作和释放操作。获取操作是一种依赖状态的操作,并且通常会阻塞。当使用锁或信号量时,“获取”操作的含义是:获取锁或许可,并且调用者可能会一直等待直到同步器类处于可被获取的状态。
根据同步器的不同,获取操作可以是一种独占操作,也可以是一个非独占操作。一个获取操作包括两部分:首先,同步器判断当前状态是否允许获得操作。如果是,则允许线程执行,否则获取操作将阻塞或失败。这种判断是由同步器的语义决定的。如对于锁来说,如果它没有被某个线程持有,那么就能被成功地获取,而对于闭锁来说,如果它处于结束状态,那么也能被成功地获取。AQS中获取操作与释放操作的形式如下:
boolean acquire() throws InterruptedExcepiton {
while(当前状态不允许获取操作) {
if(需要阻塞获取请求) {
如果当前线程不在队列中,则将其插入队列
阻塞当前线程
} else {
返回失败
}
}
可能更新同步器的状态
如果线程位于队列中,则将其移除队列
返回成功
}
void release() {
更新同步器的状态
if(新的状态允许某个被阻塞的线程获取成功) {
解除队列中的一个或多个线程的阻塞状态
}
}
其次,就是更新同步器的状态,获取同步器的某个线程可能会对其他线程能否也获取该同步器造成影响。如,当获取一个锁后,锁的状态将从“未被持有”变成“已被持有”;从Semaphore获取一个许可后,将把剩余许可的数量减一;当一个线程获得闭锁时,并不会影响其他线程能够获取它,因此获取闭锁的操作不会改变闭锁的状态。
如果某个同步器支持独占操作,那么需要实现一些保护方法,包括:tryAcquire、tryRelease等,对于支持共享获取的同步器,则应该实现tryAcuireShared、tryReleaseShared等方法。
为了使支持条件队列的锁(如ReentrantLock)实现起来更简单,AQS还提供了一些机制来构造与同步器相关的条件变量。
使用AQS实现一个二元闭锁。示例代码如下:
// 在OneShotLatch中,AQS状态用来表示闭锁状态————关闭(0)或者打开(1)。
@ThreadSafe
public class OneShotLatch {
private final Sync sync = new Sync();
public void signal() {
sync.releaseShared(0);
}
public void await() throws InterruptedException {
sync.acquireSharedInterruptibly(0);
}
private class Sync extends AbstractQueuedSynchronizer {
protected int tryAcquireShared(int ignored) {
// 如果闭锁是开的(state == 1),那么这个操作将成功,否则将失败
return (getState()==1) ? 1 : -1;
}
protected boolean tryReleaseShared(int ignored) {
// 现在打开闭锁
setState(1);
// 现在其他的线程可以获取该闭锁
return true;
}
}
}
OneShotLatch也可通过扩展AQS来实现,而不是将一些功能委托给AQS,但这种做法并不合理。主要原因有两点:(1) 这种做法将破坏OneShotLatch接口的简洁性,并且虽然AQS的公共方法不允许调用者破坏闭锁的状态,但调用者仍可能误用它们。所以java.util.concurrent中的所有同步器类都没有直接扩展AQS,而是都将它们的相应功能委托给私有的AQS子类来实现。
java.util.concurrent同步器类中的AQS
java.util.concurrent中的许多可阻塞类,如ReentrantLock、Semaphore、ReentrantReadWriteLock、CountDownLatch、SynchronousQueue和FutureTask等,都是基于AQS构建的。
ReentrantLock
ReentrantLock只支持独占方式的获取操作。ReentrantLock将同步状态用于保存锁获取操作的次数,并且还维护一个owner变量来保存当前所有者线程的标识符,只有在当前线程刚刚获取到锁,或者正要释放锁的时候,才会修改这个变量。
ReentrantLock还利用了AQS对多个条件变量和多个等待线程集的内置支持。Lock.newCondition将返回一个新的ConditionObject示例,这是AQS的一个内部类。
Semaphore和CountDownLatch
Semaphore将AQS的同步状态用于保存当前许可的数量。tryAcquireShared方法首先计算剩余许可的数量,如果没有足够的许可,那么会返回一个值表示获取操作失败。如果还有剩余的许可,那么tryAcquireShared会通过compareAndSetState以原子方式来降低许可的计数。如果这个操作成功,那么将返回一个值表示获取操作成功。在返回值中还包括表示其他共享获取操作能否成功的信息。如果成功,那么其他等待的线程同样会解除阻塞。
当没有足够的许可,或者当tryAcquireShared可以通过原子方式来更新许可的计数以响应获取操作时,while循环将终止。
CountDownLatch使用AQS的方式与Semaphore相似:在同步状态中保存的是当前的计数值。countDown方法调用release,从而导致计数值递减,并且当计数值为零时,解除所有等待线程的阻塞。await调用acquire,当计数器为零时,acquire将立即返回,否则将阻塞。
ReentrantReadWriteLock
ReadWriteLock接口表示存在两个锁:一个读取锁和一个写入锁,但在基于AQS实现的ReentrantReadWriteLock中,单个AQS子类将同时管理读取加锁和写入加锁。ReentrantReadWriteLock在读取锁上的操作家纪念馆使用共享的获取与释放方法,在写入锁上的操作将使用独占的获取方法和释放方法。
AQS在内部维护一个等待线程队列,其中记录了某个线程请求的是独占访问还是共享访问。在ReentrantReadWriteLock中,当锁可用时,如果位于队列头部的线程执行写入操作,那么线程会得到这个锁,如果位于队列头部的线程执行读取访问,那么队列中在第一个写入线程之前的所有线程都将获得这个锁。
FutureTask
Future.get语义类似于闭锁的语义————如果发生了某个事件,那么线程就可以恢复执行,否则这些线程将停留在队列中并直到该事件发生。
在FutureTask中,AQS同步状态被用来保存任务的状态,如正在运行、已完成或已取消。FutureTask还维护一些额外的状态变量,用来保存计算结果或抛出的异常。
线程池
真正使用多线程时,主要的使用途径还是基于线程池。
线程池,从字面意思来看,是指管理一组同构工作线程的资源池。
线程池主要解决“为每个任务分配一个线程”方式使用多线程带来的线程创建和销毁的低效问题。为了减少创建和销毁线程的次数,实现线程资源的统一管理,引入线程池。
引入线程池后,带来以下好处:
(1) 降低资源消耗。通过重复利用已创建的线程,可以降低线程创建和销毁带来的开销。
(2) 提高响应速度。当任务到达时,任务可以不需要等到线程创建就能立即执行。
(3) 提高线程的可管理性。线程是稀缺资源,如果无限制地创建,不仅会消耗系统资源,还会降低系统的稳定性。通过适当调整线程池的大小,可以创建足够多的线程以使处理器保持忙碌状态,同时防止过多线程相互竞争资源,而使应用程序耗尽内存或失败。使用线程池可以对线程资源进行统一分配、调优和监控。
线程池的工作原理
ThreadPoolExecutor是一种灵活、稳定的线程池,允许进行各种定制。是Java开发中线程池使用的事实标准。ThreadPoolExecutor中线程池结构如下:
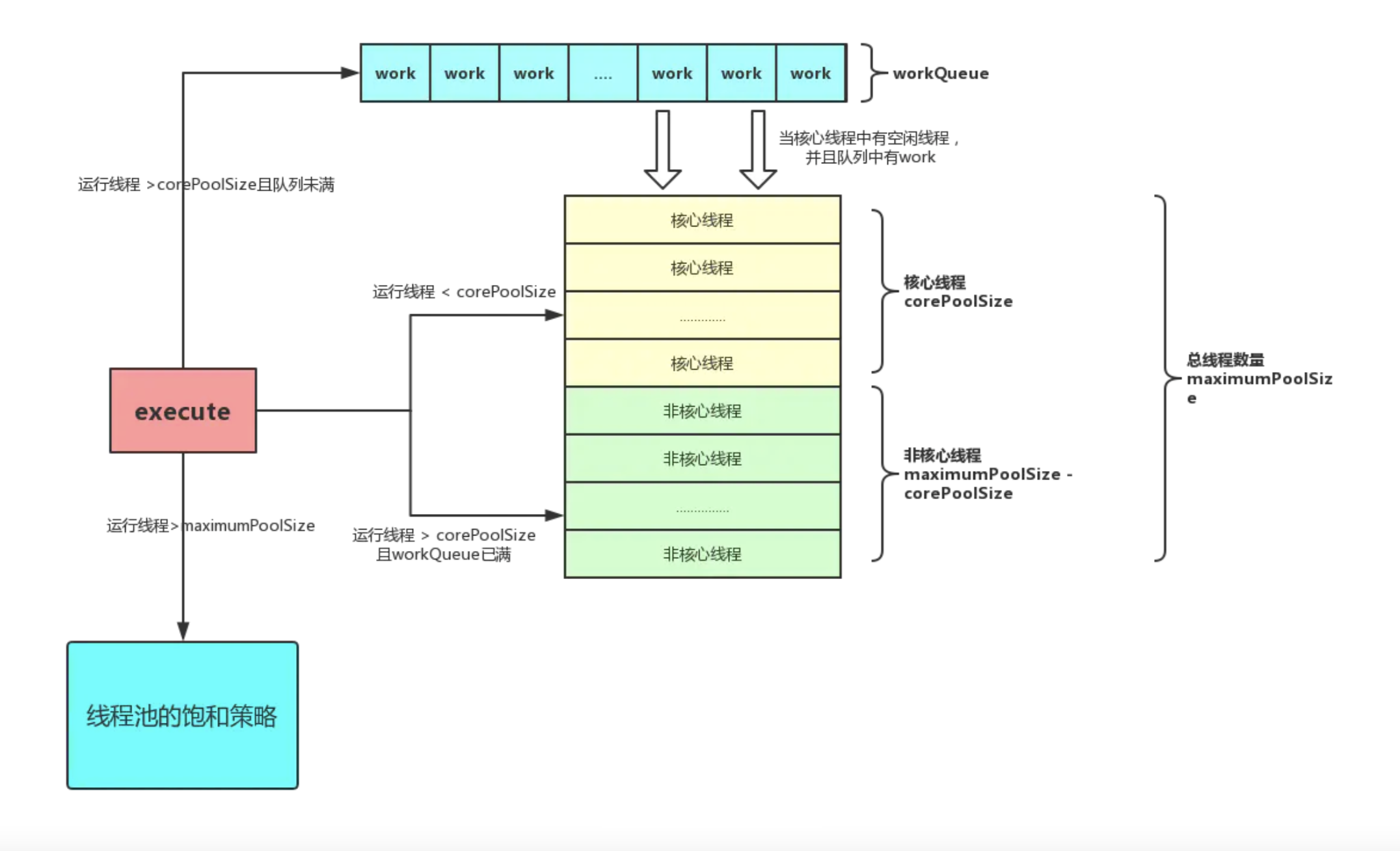
接下来介绍线程池中几个主要概念:
(1) 工作线程(Work Thread),线程池中的线程。
(2) 工作队列(Work Queue),用于存放和提取任务(也称为请求)。
(3) 核心线程数(Core Pool Size),线程池核心线程数量。
(4) 最大线程数量(maximumPoolSize),线程池最多支持创建的线程数量。
(5) 拒绝策略(RejectedExecutionHandler,也常称为饱和策略),线程池饱和(工作队列已满,且线程池线程数达到最大线程数)后,线程池的拒绝策略。
(6) 线程工厂(Thread Factory),线程池通过线程工厂来创建线程。
(7) 线程存活时间(Keep Alive Time),如果某个线程的空闲时间超过了存活时间,那么该线程将被标记为可回收,并且当线程池的当前数量超过了线程池的基本大小,这个线程将被终止。
任务提交到线程池(执行execute(Runnable)方法中提交新任务)后,线程池会根据corePoolSize和maximumPoolSize自动地调整线程池大小。判断流程如下:
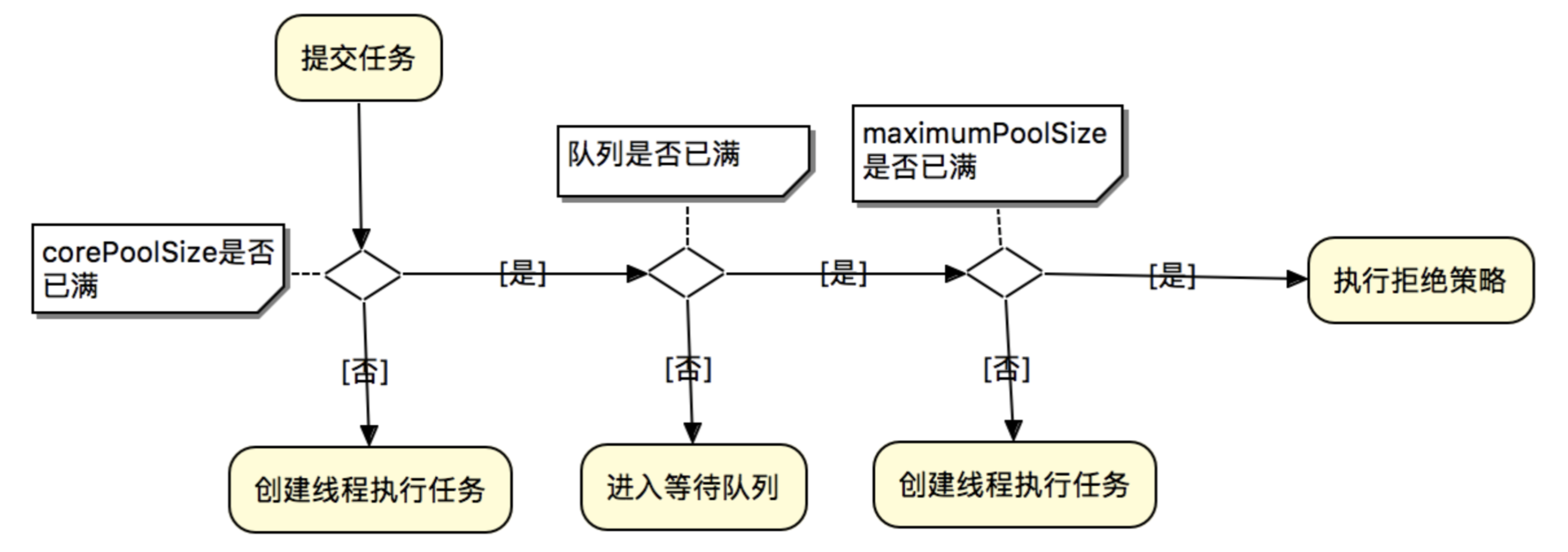
(1) 当有新任务在execute()方法提交时,首先判断当前运行的线程数量是否少于corePoolSize,如果少于corePoolSize,则创建新线程来处理任务,即使线程池中的其他工作线程处于空闲状态。
(2) 如果线程池中的工作线程的数量大于等于corePoolSize且小于maximumPoolSize,则先判断工作队列是否已满,如果未满,则先将任务推送到工作队列。如果工作队列已满,,则创建新的线程去处理任务。
(3) 如果运行的线程数量大于等于maximumPoolSize,说明工作队列已满。则通过指定的拒绝策略来处理任务。
所以,任务提交时,判断的顺序为 corePoolSize –> workQueue –> maximumPoolSize。
使用线程池时,还需注意以下特殊情况:
(1) 当设置corePoolSize和maximumPoolSize相同时,则可以创建一个固定大小的线程池。
(2) 当设置maximumPoolSize值极大(Integer.MAX_VALUE),或使用无界的工作队列(如LinkedBlockingQueue)时,则可以创建一个近似不限大小的线程池。
(3) 当设置workQueue为java.util.concurrent.SynchronousQueue时,表示工作队列容量为零。SynchronousQueue不是一个真正的队列,而是一种在线程之间进行移交的机制。要将一个元素放入SynchronousQueue中,必须有另一个线程正在等待接收这个元素。如果没有线程正在等待,并且线程池的当前大小小于最大值,那么ThreadPoolExecutor将创建一个新的线程,否则根据饱和策略,这个任务将被拒绝。直接移交的方式更高效,因为任务会直接移交给执行它的线程,而不是被首先放在队列中,然后由工作者线程从队列中提取任务。只有当线程池是无界或可以拒绝任务时,SynchronousQueue才有实际价值。(简言之,SynchronousQueue的移交特性,使任务可以阻塞等待空闲线程)
(4) corePoolSize和maximumPoolSize仅在初始化线程池时指定,但也可通过setCorePoolSize和setMaximumPoolSize进行动态更改。
饱和策略
当线程池中线程数量达到maximumPoolSize或者某个任务被提交到一个已关闭的Executor上时,饱和策略开始发挥作用。ThreadPoolExecutor的饱和策略可以通过调用setRejected-ExecutionHandler来调整。JDK提供了多种RejectedExecutionHandler实现,每种实现都包含多种不同的饱和策略:AbortPolicy、CallerRunsPolicy、DiscardPolicy和DiscardOldestPolicy。
AbortPolicy,中止策略,默认的饱和策略,该策略将抛出未检查的RejectedExecution。该策略将抛出未检查的RejectedExecutionException。调用者可以捕获这个异常,然后根据需求编写自己的处理代码。
DiscardPolicy,抛弃策略。当新提交的任务无法保存到队列中等待执行时,抛弃策略会悄悄抛弃该任务。
DiscardOldestPolicy,抛弃最旧的策略。该策略会抛弃下一个将被执行的任务,然后尝试重新提交新的任务。注意,当工作队列是一个优先队列时,该策略会导致抛弃优先级最高的任务。
CallerRunsPolicy,调用者执行策略,实现一种调节机制,该策略即不会抛弃任务,也不会抛出异常,而是将某些任务退回到调用者,从而降低新任务的流量。当线程池中的所有线程都被占用,并且工作队列被填满后,使用调用者执行策略后,下一个任务会在调用execute时在主线程中执行。由于执行任务需要一定的时间,因此主线程至少在一段时间内不能提交任何任务,从而使得工作者线程由时间来处理完正在执行的任务。在这期间,主线程不会调用accept,因此到达的请求将被保存在TCP层的队列中,而不是在应用程序的队列中。如果持续过载,那么这种过载情况会逐渐向外蔓延开来————从线程池到工作队列到应用程序再到TCP层,最终达到客户端,从而使服务器在高负载下实现一种平缓的性能降低。(不推荐使用)
当然,可以自己实现饱和策略来处理上述场景。
线程工厂
线程池通过线程工厂来创建线程。默认的线程工厂方法将创建一个新的、非守护的线程,并且不包含特殊的配置信息。在ThreadFactory中只定义了一个newThread方法。ThreadFactory定义如下:
public interface ThreadFactory {
Thread newThread(Runnable r);
}
大多数情况下需要使用定制的线程工厂方法。如希望线程池中的线程指定一个UncaughtExceptionHandler,或者实例化一个定制的Thread类用于执行调试信息的记录等。
线程回收
线程池中执行的任务,总有执行结束的时候。那么线程池当线程池中存在大量空闲线程时,也会有一定的收缩策略,来回收线程池中多余的线程。
线程池中线程的收缩策略如下:
当线程池中的线程数,超过核心线程数时。此时如果任务量下降,肯定会出现有一些线程处于无任务执行的空闲状态。那么如果这个线程的空闲时间超过了 keepAliveTime&unit 配置的时长后,就会被回收。
需要注意的是,对于线程池来说,它只负责管理线程,对于创建的线程是不区分所谓的「核心线程」和「非核心线程」的,它只对线程池中的线程总数进行管理,当回收的线程数达到 corePoolSize 时,回收的过程就会停止。
对于线程池的核心线程数中的线程,也有回收的办法,可以通过 allowCoreThreadTimeOut(true) 方法设置,在核心线程空闲的时候,一旦超过 keepAliveTime&unit 配置的时间,也将其回收掉。
public void allowCoreThreadTimeOut(boolean value) {
if (value && keepAliveTime <= 0) {
throw new IllegalArgumentException("Core threads must have nonzero keep alive times");
}
if (value != allowCoreThreadTimeOut) {
allowCoreThreadTimeOut = value;
if (value) {
interruptIdleWorkers();
}
}
}
线程死亡常见方式
守护线程(daemon)会在所有的非守护线程都死掉之后也死掉,除此之外导致一个非守护线程死掉有以下几种可能:
自然死亡,Runnable.run()方法执行完后返回。
执行过程中有未捕获异常,被抛到了Runnable.run()之外,导致线程死亡。
其宿主死亡,进程关闭或者机器死机。在Java中通常是System.exit()方法被调用。
其他硬件问题。
Java中使用线程池
阿里巴巴Java开发手册强制要求:
(1) 线程资源必须通过线程池提供,不允许在应用中自行显式地创建线程。
(2) 线程池不允许使用Executors去创建,而是通过ThreadPoolExecutor创建线程池。
简言之,Java开发中使用线程时要基于线程池创建线程,线程池通过ThreadPoolExecutor创建。
线程池的好处之一是减少在创建和销毁线程上所消耗的时间以及系统资源的开销,解决资源不足的问题。如果不使用线程池,有可能造成系统创建大量同类线程而导致过度消耗内存或“过度切换”的问题。
使用ThreadPoolExecutor创建线程池,而不使用Executors
使用Executors创建线程池可能会导致OOM(OutOfMemory ,内存溢出)。 Executor框架提供四种执行策略:
(1)newFixedThreadPool。创建一个固定长度的线程池。当达到线程池的最大数量时,线程池的规模将不再变化。
(2)newCachedThreadPool。创建一个可缓存的线程池。如果线程池的当前规模超过了处理需求,那么将回收空闲的线程,而当需求增加时,则可添加新的线程,线程池的规模不存在任何限制。
(3)newSingleThreadExecutor。创建一个线程的Executor。如果这个线程异常结束,会创建另一个线程来代替。
(4)newScheduledThreadPool。创建一个固定长度的线程池,且以延迟或定时的方式里执行任务,类似Timer。
这里,FixedThreadPool、SingleThreadExecutor因允许的工作队列的长度为Integer.MAX_VALUE,所以会出现任务大量堆积,从而导致OOM。
CachedThreadPool因允许创建的线程数是Integer.MAX_VALUE,所以会出现创建大量线程,从而导致OOM。
向线程池提交任务的几种方式
往线程池中提交任务,主要有两种方法,execute()和submit()。
execute()用于提交不需要返回结果的任务,我们看一个例子。
public static void main(String[] args) {
ExecutorService executor = Executors.newFixedThreadPool(2);
executor.execute(() -> System.out.println("hello"));
}
submit()用于提交一个需要返回果的任务。该方法返回一个Future对象,通过调用这个对象的get()方法,我们就能获得返回结果。get()方法会一直阻塞,直到返回结果返回。另外,我们也可以使用它的重载方法get(long timeout, TimeUnit unit),这个方法也会阻塞,但是在超时时间内仍然没有返回结果时,将抛出异常TimeoutException。
public static void main(String[] args) throws Exception {
ExecutorService executor = Executors.newFixedThreadPool(2);
Future<Long> future = executor.submit(() -> {
System.out.println("task is executed");
return System.currentTimeMillis();
});
System.out.println("task execute time is: " + future.get());
}
关闭线程池
在线程池使用完成之后,我们需要对线程池中的资源进行释放操作,这就涉及到关闭功能。我们可以调用线程池对象的shutdown()和shutdownNow()方法来关闭线程池。
shutdown()会将线程池状态置为SHUTDOWN,不再接受新的任务,同时会等待线程池中已有的任务执行完成再结束。
shutdownNow()会将线程池状态置为SHUTDOWN,对所有线程执行interrupt()操作,清空队列,并将队列中的任务返回回来。
另外,关闭线程池涉及到两个返回boolean的方法,isShutdown()和isTerminated,分别表示是否关闭和是否终止。
线程池常见问题
虽然线程池是构建多线程应用程序的强大机制,但使用它并不是没有风险的。在使用线程池时需注意线程池大小与性能的关系,注意并发风险、死锁、资源不足和线程泄漏等问题。
(1)线程池大小。多线程应用并非线程越多越好,需要根据系统运行的软硬件环境以及应用本身的特点决定线程池的大小。一般来说,如果代码结构合理的话,线程数目与CPU 数量相适合即可。如果线程运行时可能出现阻塞现象,可相应增加池的大小;如有必要可采用自适应算法来动态调整线程池的大小,以提高CPU 的有效利用率和系统的整体性能。
经验法则:
一般说来,大家认为线程池的核心线程数大小经验值应该这样设置:(其中N为CPU processors的个数)
(1)如果是CPU密集型应用,则线程池大小设置为N+1(或者是N),线程的应用场景:主要是复杂算法
(2)如果是IO密集型应用,则线程池大小设置为2N+1(或者是2N),线程的应用场景:主要是:数据库数据的交互,文件上传下载,网络数据传输等等
+1的原因是:即使当计算密集型的线程偶尔由于缺失故障或者其他原因而暂停时,这个额外的线程也能确保CPU的时钟周期不会被浪费。
以上是经验法则,本质还是要平衡CPU利用率和系统性能
(2)并发错误。多线程应用要特别注意并发错误,要从逻辑上保证程序的正确性,注意避免死锁现象的发生。
(3)线程泄漏。这是线程池应用中一个严重的问题,当任务执行完毕而线程没能返回池中就会发生线程泄漏现象。
活跃性
在安全性和活跃性之间常存在着某种制衡。活跃性故障是一个非常严重的问题,因为当出现活跃性故障时,除了中止应用程序外,没有其他任何机制可以帮助从这些故障中恢复过来。加锁机制虽然能确保线程安全,但是如果过度使用,则可能导致锁顺序死锁(Lock-Ordering DeadLock)。同样,使用线程池和信号量来限制对资源的使用,也可能会导致资源死锁(Resource DeadLock)。Java无法从死锁中恢复过来,因此在设计时一定要排除那些可能导致死锁出现的条件。从死锁产生的四个必要条件(互斥条件、请求和保持条件、不可剥夺条件、循环条件)来说,主要还是从”请求和保持条件“和”不可剥夺条件“来避免死锁。
常见的活跃性问题主要有:死锁、饥饿、低响应性、丢失信号和活锁等。
死锁(DeadLock)
所谓死锁,是指多个参与者(进程、线程或事务等)在运行过程中因争夺资源而造成的一种僵局,当这些参与者处于这种僵持状态时,若无外力作用,它们都将无法再向前推进。
经典的“哲学家进餐”问题很好地描述了死锁状况。
在线程A持有锁L并想获得锁M的同时,线程B持有锁M并尝试获得锁L,那么这两个线程将永远地等待下去。这种情况是最简单的死锁形式(也称为抱死(Deadly Embrace))
在数据库系统的设计中考虑了检测死锁及从死锁中恢复。在执行一个事务时,可能需要获取多个锁,并一直持有这些锁并直到事务提交。因此在两个事务之间很可能发生死锁。如果没有外部干涉,那么这些事务将永远等待下去。但数据库服务器不会让这种情况发生。当数据库服务器检测到一组事务发生死锁时(通过在等待关系的有向图中搜索循环),将选择牺牲一个事务。作为牺牲者的事务会释放它所持有的资源,从而使其他事务继续进行。
JVM在解决死锁问题时,不支持死锁的检测及处理。当一组Java线程发生死锁时,这些线程将永远不能再使用。根据线程完成工作的不同,可能造成应用程序完全停止,或者某个特定的子系统停止,或者是性能降低。恢复应用程序的唯一方式就是中止并重启它,并希望不要再发生同样的事情。
死锁造成的影响很少会立即显现出来。如果一个类可能发生死锁,那么并不意味着每次都会发生死锁,而只是表示有可能。当死锁出现时,往往是在最糟糕的时候————在高负载的情况下。
死锁产生的四个必要条件
(1) 互斥条件:进程要求对所分配的资源进行排它性控制,即在一段时间内某资源仅为一进程所占用。
(2) 请求和保持条件:当进程因请求资源而阻塞时,对已获得的资源保持不放。
(3) 不剥夺条件:进程已获得的资源在未使用完之前,不能剥夺,只能在使用完时由自己释放。
(4) 环路等待条件:在发生死锁时,必然存在一个进程–资源的环形链。
锁顺序死锁
多个线程试图以不同的顺序来获得相同的锁,则有可能发生死锁。如两个线程以不同的顺序获得相同的锁,如果按照交错的方式来请求锁,则有可能发生死锁。图示如下:
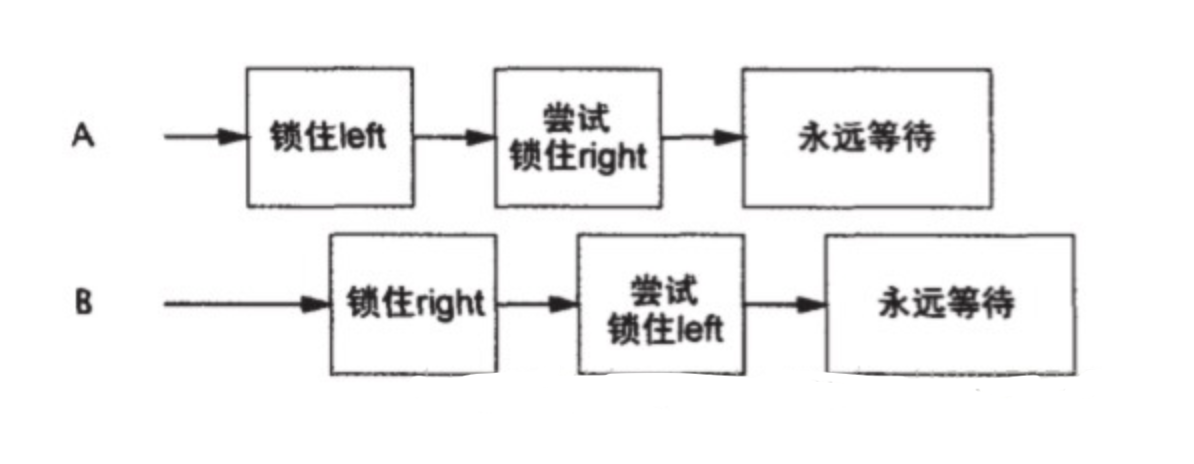
如果线程按照相同的顺序来请求锁,那么就不会出现循环加锁依赖性,因此也就不会发生锁顺序死锁问题。
如果想验证”锁顺序的一致性“,那么需要对程序中的加锁行为进行全局分析。如果只是单独分析每条获取多个锁的代码路径,不能排除锁顺序死锁问题。示例代码如下:
// 简单的锁顺序死锁
public class LeftRightLock {
private final Object left = new Object();
private final Object right = new Object();
public void leftRight() {
synchronized(left) {
synchronized(right) {
doSomething();
}
}
}
public void rightLeft() {
synchronized(right) {
synchronized(left) {
doSomething();
}
}
}
}
动态的锁顺序死锁
除了从代码中对程序加锁行为分析的锁顺序死锁,还有一种动态的锁顺序死锁。考虑程序将资金从一个账户转到另一个账户的场景。在开始转账之前,首先要获得这两个账户(Account)对象的锁,以确保通过原子方式来更新两个账户的余额,同时又不破坏一些不变形条件。示例代码如下:
// 产生动态的锁顺序死锁
public void transfreMoney(Account fromAccount, Account toAccount, DollarAmount amount) throws InsufficientFundsException {
synchronized(fromAccount) {
synchronized(toAccount) {
if(fromtAccount.getBalance().compareTo(account) < 0) {
throw new InsufficientFundsException();
} else {
fromAccount.debit(amount);
toAccount.credit(amount);
}
}
}
}
表面上,所有的线程都按照相同的顺序来获得锁,但事实上锁的顺序取决于传递给transfreMoney的参数顺序,而这些参数顺序又取决于外部输入。产生死锁的调用代码如下:
transfreMoney(myAccount, yourAccount, 1000);
transfreMoney(yourAccount, myAccount, 200);
由于无法控制参数的顺序,因此解决这个问题时,必须定义锁的顺序,并在整个应用程序中都按照这个顺序来获取锁。在指定锁的顺序时,可以使用System.identityHashCode方法。该方法将返回由Object.hashCode返回的值。示例代码如下:
private static final Object tieLock = new Object();
public void transferMoney(final Account fromAccount, final Account toAccount, final DollarAmount amount) throws InsufficientFundsException {
class Helper {
public void transfer() throws InsufficientFundsException {
if(fromAccount.getBalance().compareTo(Account < 0)) {
throw new InsufficientFundsException();
} else {
fromAccount.debit(amount);
toAccount.credit(amount);
}
}
}
int fromHash = System.ientityHashCode(fromAccount);
int toHash = System.ientityHashCode(toAccount);
if(fromHash < toHash){
synchronized(fromAccount) {
synchronized(toAccount) {
new Helper().transfer();
}
}
} else if(fromHash > toHash) {
synchronized(toAccount) {
synchronized(fromAccount) {
new Helper().transfer();
}
}
} else {
synchronized(tieLock) {
synchronized(toAccount) {
synchronized(fromAccount) {
new Helper().transfer();
}
}
}
}
}
在极少数情况下,两个对象可能拥有相同的散列值,此时必须通过某种任意的方法来决定锁的顺序,而这可能又会重新引入死锁。为避免这种情况,可以使用”加时赛(TieBreaking)“锁。在获得两个Account锁之前,首先获得这个”加时赛“锁,从而保证每次只有一个线程以未知的顺序获得这两个锁,从而消除死锁发生的可能性,但这种技术会带来性能瓶颈。由于System.ientityHashCode中出现散列冲突的频率非常低,因此这项技术以最小的代价,换来了最大的安全性。
在真实系统中,有时压力测试也很难找出死锁问题,但死锁问题一旦发生,将引起极大的问题。而作为商业产品的应用程序每天要执行数十亿次获取锁-释放锁的操作,只要这数十亿次操作有一次发生了错误,就可能导致程序死锁。
协作对象之间发生的死锁
无论是锁顺序死锁,还是动态的锁顺序死锁,都是在同一个方法中获取两个锁。但有些死锁,两个锁不一定必须在同一个方法中获取。在相互协作对象之间的锁顺序死锁示例代码如下:
// 相互协作对象之间的锁顺序死锁
class Taxi {
@GuardBy("this") private Point location, destination;
private final Dispatcher dispatcher;
public Taxi(Dispatcher dispatcher) {
this.dispatcher = dispatcher;
}
public synchronized Point getLocation() {
return location;
}
public synchronized void setLocation(Point location) {
this.location = location;
if(location.equals(destination)) {
dispatcher.notifyAvailable(this);
}
}
}
class Dispatcher {
@GuardBy("this") private final Set<Taxi> taxis;
@GuardBy("this") private final Set<Taxi> availableTaxis;
public Dispatcher() {
taxis = new HashSet<Taxi>();
availableTaxis = new HashSet<Taxi>();
}
public synchronized void notifyAvailable(Taxi taxi) {
availableTaxis.add(taxi);
}
public synchronized Image getImage() {
Image image = new Image();
for(Taxi t : taxis) {
image.drawMarker(t.getLocation());
}
return image;
}
}
尽管任何方法都没有显式地获取两个锁,但setLocation和getImage等方法的调用者都会获得两个锁。调用setLocation方法的线程将先获得Taxi锁,然后获取Dispatcher锁,类似地,调用getImage方法的线程将先获得Dispatcher锁,然后获取Taxi锁。这与之前的锁顺序死锁情况相同。
尽管这种情况下查找死锁比较困哪,但仍有规律可循:如果在持有锁的情况下调用某个外部方法,那么就需要警惕死锁。更一般地,如果在持有锁时调用某个外部方法,那么将出现活跃性问题。在这个外部方法中可能获取其他锁,或阻塞时间过长,导致其他线程无法及时获得当前被持有的锁。(本质上来说,这是”请求-保持“场景的体现)
开放调用
由于方法调用相当于一种抽象屏障,因此必须了解在被调用方法中所执行的操作。但也正是由于不知道在被调用方法中执行的操作,因此在持有锁的时候对调用某个外部方法将难以分析,从而可能出现死锁。
如果在调用某个方法时,不需要持有锁,那么这种调用被称为开发调用(Open Call)。通过开发调用来避免死锁的方法,类似于采用封装机制来提供线程安全的方法:对一个使用了封装的程序进行线程安全分析,要比分析没有使用封装的程序容易得多。同理,分析一个完全依赖于开发调用程序的活跃性,要比分析那些不依赖开发调用的程序活跃性简单。
使用开发调用策略消除死锁风险的示例代码如下:
// 使用开放调用避免在相互协作的对象之间产生的死锁
@ThreadSafe
class Taxi {
@GuardBy("this") private Point location, destination;
private final Dispatcher dispatcher;
public Taxi(Dispatcher dispatcher) {
this.dispatcher = dispatcher;
}
public synchronized Point getLocation() {
return location;
}
public void setLocation(Point location) {
boolean reachedDestination;
synchronized (this) {
this.location = location;
reachedDestination = location.equals(destination);
}
if(reachedDestination) {
dispatcher.notifyAvailable(this);
}
}
}
@ThreadSafe
class Dispatcher {
@GuardBy("this") private final Set<Taxi> taxis;
@GuardBy("this") private final Set<Taxi> availableTaxis;
public Dispatcher() {
taxis = new HashSet<Taxi>();
availableTaxis = new HashSet<Taxi>();
}
public synchronized void notifyAvailable(Taxi taxi) {
availableTaxis.add(taxi);
}
public Image getImage() {
Set<Taxi> copyTaxis;
synchronized(this) {
copyTaxis = new HashSet<Taxi>(taxis);
}
Image image = new Image();
for(Taxi t : copyTaxis) {
image.drawMarker(t.getLocation());
}
return image;
}
}
有时,重新编写同步代码块以使用开发调用时会产生意想不到的结果,因为这会使得某个原子操作变成非原子操作。在许多情况下,使某个操作失去原子性是可接受的。然而,在某些情况下,丢失原子性会引发错误。此时,需要使用另一种技术来实现原子性。如在构造一个并发对象时,使得每次只有单个线程执行使用了开发调用的代码路径。
资源死锁
当多个线程在相同的资源集合上等待时,也会发生死锁,也即资源死锁。
另一种基于资源的死锁形式是线程饥饿死锁(Thread-Starvation Deadlock)。
死锁的避免与诊断
避免死锁的本质是破坏死锁产生的其中一个或多个必要条件。
支持定时的锁
显式使用Lock类中的定时tryLock功能来替代内置锁机制,可以检测死锁和从死锁中恢复过来。当使用内置锁时,只要没有获得锁,那么将永远等待下去,而显式锁则可以指定一个超时时限,在等待超过该时间后tryLock会返回一个失败信息。
使用定时锁可以在获取锁超时时,释放这个锁,然后回退并在一段时间后再次尝试,从而消除死锁发生的条件,使程序恢复过来。定时的锁本质上是破坏死锁必要条件中的”不可剥夺条件“。注意,使用定时锁解决死锁问题时,只有在同时获取两个锁时才有效,如果在嵌套的方法调用中请求多个锁,那么即使直到已经持有外层的锁,也无法释放它。
通过线程转储来分析死锁
虽然防止死锁的主要责任在于程序开发人员(无论是类库还是基于类库开发的应用),但JVM仍通过线程转储(Thread Dump)来帮助记录死锁相关信息。线程转储包括各个运行中的线程的栈追踪信息(类比于发生异常时的栈追踪信息)。线程转储还包括加锁信息(如每个线程持有哪些锁,在哪些栈帧中获得这些锁,以及被阻塞线程在等待获取哪个锁等等)。
在生成线程转储之前,JVM将在等待关系图中通过搜索循环来找出死锁。如果发现了一个死锁,则获取相应的死锁信息(如在死锁中涉及的锁和线程,以及这个锁获取的程序代码位置)。
UNIX平台下可以通过向JVM进程发送SIGQUIT信号(kill -3)或者按下Ctrl-\键,在Windows平台中按下Ctrl-Break键。许多IDE也已支持请求线程转储操作。
注意,不同Java版本对显式锁的线程转储信息支持不同。在Java 5.0不支持与Lock相关的转储信息,在线程转储中不会出现显式的Lock。虽然Java 6包含对显式Lock的线程转储和死锁检测等支持,但显式锁的信息精确度要低于内置锁。内置锁与获取它们所在的线程的栈帧是相关联的,显式锁至于获取它的线程相关联。
饥饿(Starvation)
当线程由于无法访问它所需要的资源而不能继续执行时,就发生了”饥饿“。引发饥饿的最常见的资源就是CPU时钟周期。引起饥饿的常见方式有两种:(1)对线程的优先级使用不当;(2)在持有锁时执行一些无法结束的结构(如无限循环,或者无限制地等待某个资源)。
通常,尽量不要改变线程的优先级。只要改变了线程的优先级,程序的行为就将与平台相关,并且导致发生饥饿问题的风险。在大多数并发应用程序中,都可以使用默认的线程优先级。
低响应性
有些应用程序需要避免糟糕的响应性,如GUI应用。在GUI应用中,如果使用了后台线程,那么这种问题是很常见的。尽管将执行时间较长的任务放到后台线程中执行可以使用用户不会失去界面响应。但CPU密集型的后台任务仍可能对响应性造成影响,因为它们会与事件线程共同竞争CPU的时钟周期。(这种场景下,可以通过线程优先级提高前台程序的响应性)
不良的锁管理也可能导致糟糕的响应性。如果某个线程长时间占用一个锁(如正在对一个大容器进行迭代,并且每个元素进行计算密集的处理),而其他想要获取访问这个容器的线程就必须长时间等待。
信号丢失
信号丢失是指:线程必须等待一个已经为真的条件,但在开始等待之前没有检查条件谓词。丢失的信号是另一种形式的活跃性故障。一旦丢失信号,线程将等待一个已经发生过的事件。如果线程A通知了一个条件队列,而线程B随后在这个条件队列上等待,那么线程B将不会立即醒来,而是需要另一个通知来唤醒。
所以,如果线程必须等待一个为真的条件,在开始等待前,需检查提条件谓词。
活锁(LiveLock)
活锁指的是任务或者执行者没有被阻塞,但由于某些条件没有满足,导致一直重复执行相同的动作而且总会失败。
活锁通常发生在处理事务消息中,如果不能成功处理某个消息,那么消息处理机制将回滚事务,并将它重新放到队列的开头。这样,错误的事务被一直回滚重复执行,这种形式的活锁通常是由过度的错误恢复代码造成的,因为它错误地将不可修复的错误认为是可修复的错误。
当多个相互协作的线程都对彼此进行响应从而修改各自的状态,并使得任何一个线程都无法继续执行时,就导致了活锁。这就像两个过于礼貌的人在路上相遇,他们彼此让路,然后在另一条路上相遇,然后他们就一直这样避让下去。例如线程 1 可以使用资源,但它很礼貌,让其他线程先使用资源,线程 2 也可以使用资源,但它同样很绅士,也让其他线程先使用资源。就这样你让我,我让你,最后两个线程都无法使用资源。
要解决这种活锁问题,需要在重试机制中引入随机性。例如在网络上,如果两台机器尝试使用相同的载波发送数据包,那么这些数据包会发生冲突。这两台机器在检测到冲突后,都会选择重发。如果两台机器都都选择 1 秒后重发,那么还是会冲突。为避免这种情况发生,需要它们分别等待一段随机时间。以太协议定义了在重复发生冲突时,采用指数方式回退机制,从而降低多台冲突机器上发生阻塞和反复失败的风险。在并发应用中,通过等待随机长度的时间和回退可以有效地避免活锁的发生。
性能
线程的最主要目的是提高程序的运行性能。(线程通过并发来提高性能)
多线程虽然能提升性能,但同样也会增加复杂性,因此也就增加了在安全性(是指不发生任何错误的行为)和活跃性(是指某个良好的行为终究会发生)上发生失败的风险。更糟糕的是,虽然初衷是提升性能,但会带来其他新的性能问题,如线程之间的协调(如加锁,触发信号以及内存同步等),上下文切换开销,线程的创建与销毁,以及线程调度等。
虽然提升性能总能令人满意,但始终要把安全性放在第一位。首先要保证程序能正确执行,然后仅当程序的性能需求和测试结果要求程序执行得更快时,才应设法提升它的运行速度。而不是在一开始就尝试将程序的性能提升至极限。
性能概述
提升性能意味着使用更少的资源做更多的事情。(提高性价比)“资源”的含义很广,如CPU时钟周期、内存、网络带宽、I/O带宽、数据库请求、磁盘空间以及其他资源。
尽管使用多线程的目标是提升整体性能,但与单线程相比,使用多个线程总会引入一些额外的性能开销。造成这些开销的操作包括:线程之间的协调(如加锁,触发信号以及内存同步等),增加的上下文切换开销,线程的创建与销毁,以及线程调度等。如果过度的使用线程,那么这些开销甚至超过由于提升吞吐量、响应性或计算能力所带来的性能提升。另外,一个并发设计糟糕的应用,其性能甚至比实现相同功能的串行程序的性能还要差。
要想通过并发来获得更好的性能,需要努力做好两件事:(1) 更有效地利用现有资源;(2)在出现新的处理资源时,使程序尽可能快地利用这些新资源。 这样的话,对于计算密集型任务,就可以通过增加处理器来提高性能。
使用线程常常是为了充分利用多核的能力,因此在并发程序的性能讨论中,将侧重点放在吞吐量和可伸缩性上,而不是服务时间。根据Amdahl定律,程序的可伸缩性取决于在所有代码中必须被串行执行的代码比例。因为Java程序中串行操作的主要来源是独占式访问(锁或资源),因此通常可以通过以下方式来提高可伸缩性:减少锁的持有时间,降低锁的粒度,采用非独占的锁或非阻塞锁来代替独占锁。
性能和可伸缩性
应用程序的性能可以采用多个指标来衡量。其中一些指标(如服务时间、等待时间、延迟(指请求从发出到完成之间的时间))用来衡量程序的“运行速度”,即某个指定的任务单元需要“多快”才能处理完成。另一个指标(如可伸缩性、生产量、吞吐量(指一组并发任务中已完成任务所占的比例))用于程序的“处理能力”,即在计算资源一定的情况下,能完成“多少”工作。注意,性能的这两个方面————“多快”和“多少”,是完全独立的,有时候甚至是相互矛盾的。不同应用程序对性能的重视方面可能不同。如对于服务器应用程序,“多少”往往比“多快”更受重视。在交互式应用程序中,延迟或许更加重要。这里重点介绍“可伸缩性”方面的性能。
可伸缩性是指:当增加计算资源时(如CPU、内存、存储容量或I/O带宽),程序的吞吐量或处理能力能相应地增加。
在并发程序中针对可伸缩性进行设计和调整时所采用的方法与传统的性能调优方法截然不同。在传统的性能调优时,其目的是用更小的代价完成相同的工作,如使用缓存、降低算法的时间复杂度等。而在进行可伸缩性调优时,其目的是设法将问题的计算并行化,从而能利用更多的计算资源来完成更多的工作。(可伸缩性调优的本质是在保证程序安全性和活跃性的同时,提高计算并行化)
评估性能权衡因素
在几乎所有的工程决策中都会涉及某种形式的权衡。当进行决策时,有时会通过增加某种形式的成本来降低另一种形式的开销(如增加内存使用量以降低服务时间,牺牲空间来换取时间),也会通过增加开销来换取安全性。很多性能优化措施通常都是以牺牲可读性或可维护性行为代价————代码越“聪明”或越“晦涩”,就越难理解和维护。有时,优化措施会破坏面向对象的设计原则,如打破封装性,或带来更高的错误风险,因为通常越快的算法就越复杂。
在大多数性能决策中都包含多个变量,并且非常依赖运行环境。在进行任何与性能相关的决策时,都应该考虑这些变量。在进行可伸缩性的性能优化时,推荐使用保守的优化方法。因为对性能的提升可能是并发错误的最大来源。因为并发错误是难以追踪和消除的错误,因此对于任何可能会引入这类错误的措施,都需要谨慎实施。有人认为“同步机制太慢”,因而采用一些看似聪明实则危险的方法来减少同步的使用,这也通常作为不遵守同步规则的一个常见借口。
更遭的是,尽管初衷可能是用安全性来换取性能,但最终可能什么也得不到。因为不同的开发人员的并发编程能力不同,所以可能会存在错误的直觉。此外,在对性能调优时,一定要有明确的性能需求(这样才能知道什么时候需要调优,以及什么时候停止调优),以及一个测试程序以及真实的配置和负载等环境。性能调优后,需要再次测量以验证是否到达了预期的性能提升目标。简言之,以测试为基准,不要猜测。(猜测具有主观性)
在市场上有一些成熟的分析工具可以用于评估性能以及找出性能瓶颈,但没必要花费太多资金找出程序的功能。
Amdahl定律
Amdahl定律的描述是:在增加计算资源的情况下,程序在理论上能够实现最高加速比,这个值取决于程序中可并行组件与串行组件所占的比重。 假设F是必须串行执行的部分,那么根据Amdahl定律,在包含N个处理器的机器中,最高的加速比为:
Speedup ≤ 1/(F + (1-F)/N)
当N趋近无穷大时,最大的加速比趋近于1/F。因此,如果程序有50%的计算需要串行执行,那么最高的加速比只能是2。
在所有的并发程序中都包含一些串行部分。如对并行结果进行处理。
Amdahl定律应用
直接使用:如果能准确估计出执行过程中串行部分所占的比例,那么Amdahl定律就能量化当有更多计算资源可用时的加速比。但是由于直接测量串行部分的比例比较困难,所以很少能在实际应用中基于Amdahl定律计算加速比。
间接使用:在优化可伸缩性的性能时,会使用两种降低锁粒度的技术:锁分解(将一个锁分解为两个锁)和锁分段(将一个锁分解为多个锁)。当通过Amdahl定律来分析这两种技术时,相比锁分解技术,锁分段技术更能充分利用多处理器的能力。因为锁分段技术的分段数据可随着处理器数量的增加而增加。
多线程开销
使用多线程后,总会引入一些额外的性能开销。造成这些开销的操作包括:线程之间的协调(如加锁,触发信号以及内存同步等),增加的上下文切换开销,线程的创建与销毁,以及线程调度等。对于为提升性能而引入的线程来说,并行带来的性能提升必须超过并发导致的开销。
上下文切换
如果可运行的线程数大于CPU的数量,那么操作系统最终会将某个正在运行的线程调度出来,从而使其他线程能够使用CPU。这将导致一次上下文切换。在这个过程中,将保存当前运行线程的执行上下文,并将新调度过来的线程的执行上下文设置为当前上下文。
切换上下文需要一定的开销,而在线程调度过程中,需要访问由操作系统和JVM共享的数据结构。除了对CPU时钟周期的占用,当一个新的线程被切换进来时,它所需的数据可能不在当前处理器的缓存中,因此上下文切换将导致一些缓存缺失,因而线程在首次调度运行时,会更加缓慢。这就是为什么调度器会为每个可运行的线程分配一个最小执行时间,即使有多个线程正在等待执行:它将上下文切换的开销分摊到更多不会中断的执行时间上,从而提高整体的吞吐量(以损失响应性为代价)。
当线程由于等待某个竞争的锁而被阻塞时,JVM通常会将这个线程挂起,并允许它被交换出去。如果线程频繁地发生阻塞,那么它们将无法使用完整的调度时间片。当阻塞增加时,对CPU密集型的程序来说,会发生越多的上下文切换,从而增加调度开销,并因此而降低吞吐量。
内存同步
同步操作的性能开销包括多个方面。以Synchronized和volatile提供可见性保证使用的内存栅栏(Memory Barrier)来说,内存栅栏可以刷新缓存,使缓存无效,刷新硬件的写缓存,以及停止执行管道。内存栅栏会对性能带来间接影响,因为它会抑制一些编译器优化操作。在内存栅栏中,大多数操作都是不能被重排序的。
在评估同步操作带来的性能影响时,要区分有竞争的同步(互斥同步)和无竞争的同步(客观同步)。无竞争同步的开销不为零,但它对应用程序整体性能的影响微乎其微。
现代JVM能通过优化来去掉一些不会发生竞争的锁,从而减少不必要的同步开销。(锁消除)
一些更完备的JVM能通过逸出分析(Escape Analysis)来找出不会发布到堆的本地对象引用,并将其变为线程本地变量,从而消除锁获取操作。
即使不进行逸出分析,编译器也可执行锁粒度粗化(Lock Coarsening)操作,即将邻近的同步代码块用同一个锁合并起来。这不仅可较少同步开销,同时还能使优化器处理更大的代码块,从而可能实现进一步的优化。
某些线程的同步可能会影响其他线程的性能。同步会增加共享内存总线上的通信量,总线的带宽是有限的,并且所有的处理器都将共享这条总线。如果有多个线程竞争同步带宽,那么所有使用了同步的线程都会受到影响。
阻塞
当在锁上发生竞争时,竞争失败的线程肯定会阻塞,JVM在实现阻塞行为时,可以采用自旋等待或者通过操作系统挂起被阻塞的线程。这两种方式的效率高低,要取决于上下文切换到开销以及在成功获取锁之前需要等待的时间。如果等待的时间较短,则适合采用自旋等待方式,而如果等待时间长,则适合采用线程挂起方式。
当线程无法获取某个锁或由于在某个条件等待或在I/O操作上阻塞时,需要被挂起,在这个过程中将包含两次额外的上下文切换,以及所有必要的操作系统和缓存操作:被阻塞的线程在其执行时间片还未用完之前就被交换出去,而在随后当要获取的锁或其他资源可用时,又再次被切换回来。(阻塞会导致两次上下文切换)
减少锁的竞争
串行操作会降低可伸缩性,上下文切换回降低性能。在锁上发生竞争时将同时导致这两种问题,因此减少锁的竞争能够提高性能和可伸缩性。
在并发程序中,对可伸缩性的最主要威胁就是独占方式的资源锁。
有两个因素将影响在锁上发生竞争的可能性:锁的请求频率以及每次持有该锁的时间。如果两者的乘积很小,那么大多数获取锁的操作都不会发生竞争,因此在该锁上的竞争也不会对可伸缩性造成严重影响。反之,则或导致获取该锁的线程阻塞并等待。
有三种方式可以降低锁的竞争程度:
(1) 减少锁的持有时间;
(2) 降低锁的请求频率;
(3) 使用带有协调机制的独占锁(如ReentrantReadAndWriteLock,原子变量等),这些机制允许更高的并发性。
缩小锁的范围(“快进快出”)
降低发生竞争可能性的一种有效方式就是尽可能缩短锁的持有时间。如果将一个“高度竞争”的锁持有过长时间,那么会限制可伸缩性。可以通过尝试缩小锁的作用范围,来减少在持有锁需要执行的指令数量。根据Amdahl定律,这样消除了限制可伸缩性的一个因素,因为串行代码的总量减少了。
尽管缩小同步代码块能提高可伸缩性,但同步块也不能太小————一些需要采用原子方式执行的操作必须包含在一个同步块中。此外,同步需要一定的开销,当把一个同步代码块分解为多个同步代码块时,反而会对性能提升产生负面影响。在分解同步代码块时,理想的平衡点将与平台相关。但在实际情况中,仅当可以将一些“大量”的计算或阻塞操作从同步代码块中移出时,才应考虑同步代码块的大小。
减少锁的粒度
另一种减小锁的持有时间的方式是降低线程请求锁的频率。通过减小锁操作的粒度,从而改变之前由单个锁保护的情况,可以实现更高的可伸缩性。然而,使用的锁越多,发生死锁的风险也就越高。
如果一个锁需要保护多个相互独立的状态变量,那么可将这个锁分解为多个锁,并且每个锁只保护一个变量,从而提升可伸缩性,并最终降低每个锁被请求的频率。
锁分解和锁分段技术就是通过减小锁操作的粒度来提高整体的可伸缩性。
如果在锁上存在适中且不是很激烈的竞争时,通过将一个锁分解为两个锁,能最大限度地提升性能。如果对竞争并不激烈的锁进行分解,那么在性能和吞吐量等方面带来的提升将非常有限,但也会提升性能,但随着竞争变得激烈,而下降到拐点值。对竞争适中的锁进行分解时,实际上是将这些锁转变为非竞争的锁,从而有效地提高性能和可伸缩性。
在某些情况下,可将锁分解技术进一步扩展为对一组独立对象上的锁进行分解,这种情况被称为锁分段。但锁分段有一个劣势:要获取多个锁来实现独占式访问将变得更加困难,且开销更高。对有些需要获得所有锁的方法来说,很难要求同时获得所有锁,如clear方法。
当每个操作都请求多个变量时,锁的粒度将很难降低。这是在性能和可伸缩性之间相互制衡的另一个方面。一些常见的优化措施,如将一些反复计算的结果缓存起来,都会引入一些”热点域(Hot Field)“,而这些热点域往往会限制可伸缩性。
替代独占锁
第三种降低竞争锁的影响的技术是放弃使用独占锁,从而有助于使用一种友好并发的方式来管理共享状态。如使用并发容器、读-写锁、不可变对象以及原子变量。
原子变量提供一种方式来降低更新“热点域”时的开销,如静态计数器、序列发生器等。
减少上下文切换开销
通过将I/O操作从处理请求的线程中分离出来,可以缩短处理请求的平均服务时间。另一方面,可以减少请求的时间,进而减少发生阻塞的概率。从某种意义上来说,我们只是将工作分散开来,并将I/O操作移到另一个用户感知不到开销的线程上。这将提升整体的吞吐量,因为在调度中消耗的资源更少,上下文切换次数更少,并且锁的管理也更简单。
参考
《JAVA并发编程实战》(Brian Goetz, Joshua Bloch, David Holmes, Tim Peierls, Joseph Bowbeer, Doug Lea 著, 韩锴, 方妙 译
《Java编程思想》(第四版) Bruce Eckel [译]陈昊鹏
https://www.baidu.com/ 百度AI搜索
https://www.zybuluo.com/946898963/note/1065387
https://zhuanlan.zhihu.com/p/47060976 Java线程池的工作原理
https://www.jianshu.com/p/a166944f1e73 Java线程池原理
https://cloud.tencent.com/developer/article/1638175 Java 中正确使用线程池
https://www.jianshu.com/p/0478e283cfef Java线程池
https://toutiao.io/posts/bnn6b7u 线程池中线程回收
https://www.cnblogs.com/kingsleylam/p/11241625.html 简单分析ThreadPoolExecutor回收工作线程的原理
https://www.jianshu.com/p/7ab4ae9443b9 Java线程池的使用
https://zhuanlan.zhihu.com/p/94325810 多线程面试题
https://blog.csdn.net/weixin_43975771/article/details/113099180
http://www.jasongj.com/java/concurrenthashmap/ ConcurrentHashMap的演进
https://www.itqiankun.com/article/concurrenthashmap-principle ConcurrentHashMap与分段锁
http://www.codeceo.com/article/java-hashmap-concurrenthashmap.html Java HashMap 和 ConcurrentHashMap
https://blog.csdn.net/hd12370/article/details/82814348 死锁
https://www.cnblogs.com/msymm/p/9873551.html java之vector详细介绍
https://www.cnblogs.com/lchzls/p/6714335.html JAVA中HashMap和Hashtable区别
https://blog.csdn.net/wangxing233/article/details/79452946 HashMap 与HashTable的区别
https://zhuanlan.zhihu.com/p/21673805 Java 8系列之重新认识HashMap
https://blog.csdn.net/u012723673/article/details/80682208 Java volatile关键字最全总结:原理剖析与实例讲解
https://juejin.cn/post/6844903520760496141 面试官最爱的volatile关键字
https://blog.csdn.net/chenssy/article/details/54883355 【死磕Java并发】-----深入分析synchronized的实现原理
https://www.hollischuang.com/archives/1883 深入理解多线程(一)——Synchronized的实现原理
https://blog.csdn.net/javazejian/article/details/72828483 深入理解Java并发之synchronized实现原理
http://www.cnblogs.com/paddix/p/5367116.html Java并发编程:Synchronized及其实现原理
https://blog.csdn.net/qq_42080839/article/details/109848719 Java并发深度总结:synchronized 关键字
https://blog.csdn.net/gatieme/article/details/51481863 内核线程、轻量级进程、用户线程三种线程概念解惑
https://lanqiu5ge.github.io/2018/02/27/Java多线程系列 -- 01. Java线程状态及切换/ Java多线程系列 – 01. Java线程状态及切换
https://www.cnblogs.com/paddix/p/5405678.html Java并发编程:Synchronized底层优化(偏向锁、轻量级锁)
https://www.cnblogs.com/wade-luffy/p/5969418.html 偏向锁,轻量级锁,自旋锁,重量级锁的详细介绍
https://blog.csdn.net/pange1991/article/details/53860651 Java线程的6种状态及切换(透彻讲解)