总的来说问题还有许多,希望感兴趣的同学朋友多多交流。
最近对强化学习比较感兴趣,发现强化学习工作较多的地方是无人驾驶决策规划这一块,我自己对这方面也比较感兴趣,就想做一个超车模型,设计交互环境如下,让图中的红车以最快的速度超越其他障碍车。

我的思路是用dqp来解决这类超车问题,将连续的4个截图作为一个状态空间,并用LeNet网络来逼近值函数,但发现效果不好,我以为是LeNet过于简单无法识别出车的模型,本想换更复杂的卷积网络,但后来怕计算量变大,等结果的时间变长,于是又用圆形和方形物体来分别表示player_car和obscale_car,其他不变,但是训练效果还是不好(不知道是不是哪里参数调错了,后来发现可能是保留了pooling层,由于pooling层具有平移不变性,使网络对图像中物体的位置信息不敏感,这对于图像分类是有用的,但在当前问题中车的位置对确定潜在奖励很重要,所以不使用pooling层)。
后来听人说可以采用专家轨迹来提升训练效果,于是我又自己玩游戏记录了大约2200个状态、动作和奖励,带进模型中训练发现效果还是不好,应该是专家轨迹太少了吧,下次多录些,但真的好费事,也不符合强化学习自己犯错自己得奖的风格。
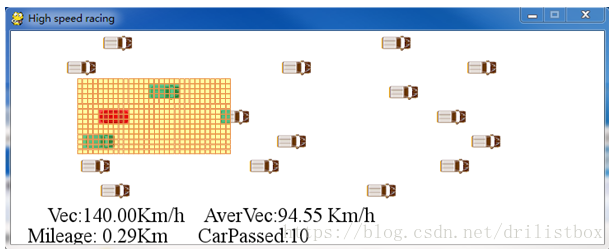
恰巧的是,我在网上看到mit的自动驾驶公开课中一个有趣的项目:DeepTraffic,界面如下:跟我目标一样,然后我参照了deeptraffic的思想,改用栅格的方法来表示模型空间。
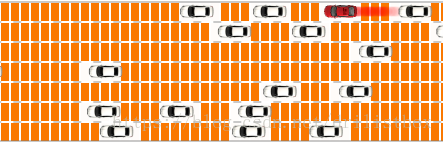
改用栅格的方法来表示模型空间后问题示意如下:栅格区域大小可以人为设定,其中每辆车占3*6个栅格,每个车道宽5个栅格。然后最重要的思路来了:每个车可观测的空间区域是有限的,我这里设定前向观测20个栅格,后向观测10个栅格,侧向观测1个车道(加上自身一共3个车道),可观测区域越大超车效果应该更好,这样状态空间就会下很多,计算速度也快很多。
我将障碍车所在的栅格值设为-1,玩家车所在的栅格设为2,其他空白区域设为0。可以获得如下矩阵:
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 2 2 2 2 2 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1
0 0 0 0 2 2 2 2 2 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1
0 0 0 0 2 2 2 2 2 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
将连续的4个矩阵reshape为向量作为输入。动作有5个:改左车道、改右车道、加速、减速、保持直线(速度不变)。然后对应的reward如下:(我是个新手,感觉reward的设置可能有些问题,希望大家可以给予意见):
改左车道:reward = 0
改右车道:reward = 0
加速:reward = 0.1*(当前速度-最小速度)
减速:reward = 0.05*(当前速度-最小速度)
【需要注意的是,减速时速度减小量对playerCar的跟车效果是有影响的,然后reward的设置好像也有影响,目前还不知道如何设最好,如果大家感兴趣,可以自己设了试试】
保持直线(速度不变):reward = 0.1
撞车:reward = -3
好了,训练了3w多步后效果还是很不错的,但是还有几个问题:
1. 损失一直不收敛:
DQN在训练过程中由于会遇到许多新的状态动作,所以在计算TD的参数θ没有变化的一个周期内loss应该是越来越小的,但总的来说loss却不是收敛的,理论上将当所有的状态动作都收集全后再对模型进行训练的过程中,loss应该是越来越小的,但我没算到这样的结果。。。。。。
2. 小车有时会连续变换车道,而且有时会存在抖动,不知道这是什么问题,是不是只要重新设定奖励,比如:
Reward += 0.2*(车道宽度的一半 – playerCar距车道路中心的距离)
然后最主要的DQN的原理就不扯了,网上一堆,如果你入门了,这个肯定会,如果是新手,推荐看郭宪博士的深入浅出强化学习,好书,然后这边书进去之后你会了解到其它好的中英文学习资料。
效果视频文件:https://pan.baidu.com/s/175pY9i6W4G-rF3nynTtgVQ
代码文件:https://github.com/drilistbox/HighSpeedRacing