
随着物联网领域的快速发展,时序数据的产生和处理需求不断增长。为了满足实时性、高效性和准确性的要求,数据库需要进行时序性能优化,以提供快速的数据写入、实时查询和高效的数据存储与处理能力。
本期直播介绍了时序数据和时序数据库特征以及基于 TSBS 时序测试标准分析,并基于此解析了 KaiwuDB 的时序模型架构和优化设计。
一、时序基础概念
1. 时序基础概念
时间序列数据是指带时间标签的数据,主要由电力、化工、气象、地理信息等行业的各类实时监测、检查与分析设备所采集、产生的数据。
为了便于解释基本概念,以微电网的太阳能发电板作为典型时序数据场景。假设每个发电板采集电流、电压、温度三个量,有多个太阳能板。
-
Measurement:一类设备的集合;
-
Data source:一个具体的设备;
-
Tags:一个设备的描述标签;
-
Timestamp:本条时序数据的采集时间。

2. 时序数据库的特点
时序数据库全称为时间序列数据库。时间序列数据库指主要用于处理带时间标签(按照时间的顺序变化,即时间序列化)的数据。
基本特点:
-
大数据量的处理;
-
高压缩比;
-
冗余重复数据的一份存储;
-
时间序列分区处理;
-
一般没有事务相关处理。

二、TSBS 测试标准说明
1. TSBS 测试标准
TimeScale 开源项目:
-
时序数据的生成和写入;
-
时序场景的典型查询。
两个典型的应用场景:
-
DevOps – 服务器 CPU 监控场景有序的时间序列数据;
-
IoT – 物联网卡车车队场景存在无序和缺失的时间序列数据。
2. DevOps 场景(CPU-only)
CPU-only 场景特点:
-
数据间隔均为 10 秒;
-
场景五数据量最大 1.8 亿条记录,场景四数据量最小 1800 万条记录;
-
场景四和场景五设备数量较多,仅覆盖 3 分钟时间跨度。

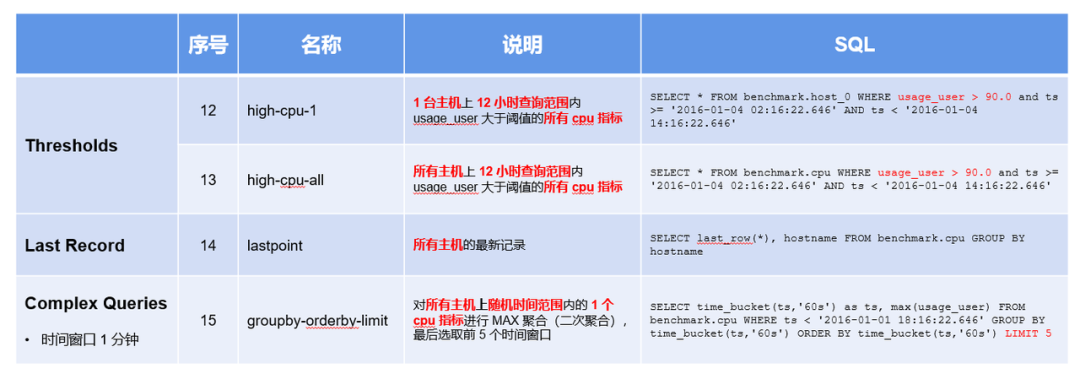
3. 不同分类的 TSBS 语句分析


三、KaiwuDB 多模数据库时序引擎
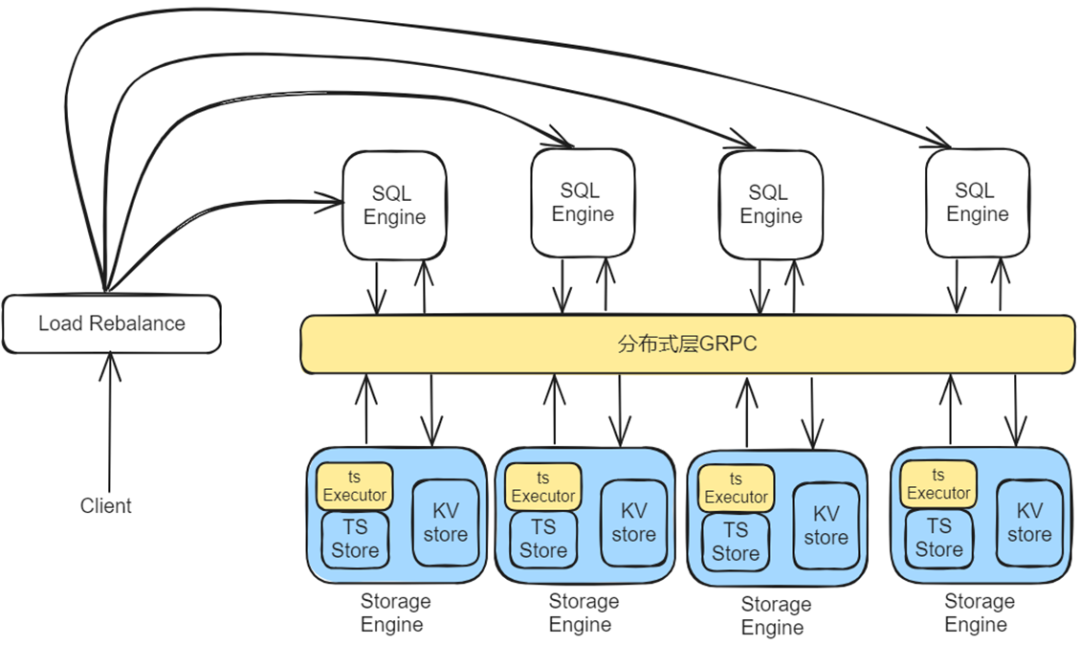
1. 基本执行架构
-
应用层;
-
SQL Engine;
-
分布式层;
-
Storage Engine。
一般没有事务相关处理。

2. 时序优化改造
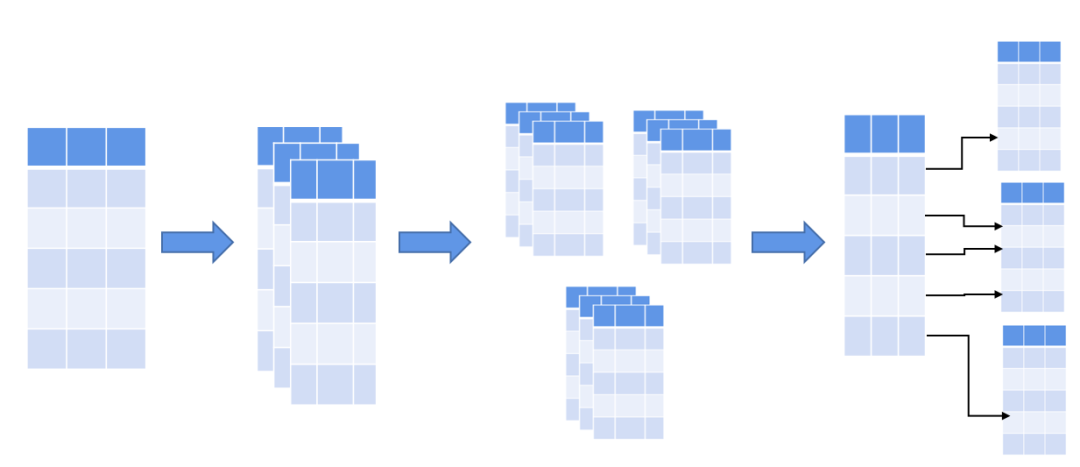
2.1 存储结构优化
针对时序数据的量大、递增、且部分数据为静态值的特点,存储结构做了如下演进:
-
大表,所有设备写入到一张表;
-
分表,一个设备一张表;
-
分区,按照时间划分数据区域;
-
合表,部分设备一组,静态属性合并存储,同时时间分区
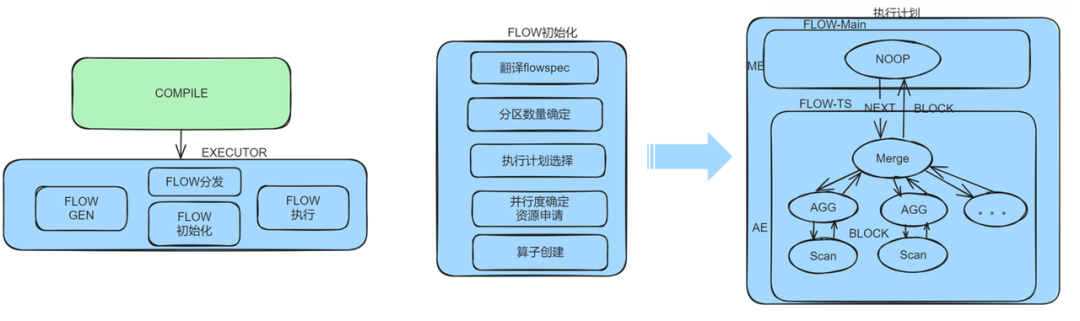
2.2 KaiwuDB 执行计算架构优化
针对时序模型,KaiwuDB 做了一系列执行架构调整:
-
执行器下放;
-
采用 mmap 技术,减少数据拷贝;
-
分区并行;
-
数据裁剪;
-
定制执行计划;
-
Timebucket 等特殊时序算子;
-
多级动态并行。
2.3 KaiwuDB 时序统计信息
KaiwuDB 的针对时序查询的特征,定制和实现了一套时序预计算统计信息。其特点如下:
-
时序表是一种特殊的复合表;
-
模板表对应 tag 表;
-
实例表只是对应 tag 表中的一条索引,而非完整表;
-
数据写入时可以动态创建 tag 项并写入数据;
-
tag 表支持基本的统计信息,例如包含 TSBS;
-
查询支持通用数据读取;
-
特殊查询能够下推,例如多 tag 查询下推,单个 tag 特定聚合数据;
-
数据块按照时间分区,增加块的统计信息。
