今年初大模型火了以后,我也产生了一个新想法:把我公众号积累的文章做成一个知识库,让著名的张大胖做“智能客服”,小伙伴们可以用和张大胖对话的方式,获取里边讲的各种知识。
这样沉淀在公众号的近千篇原创文章就可以发挥价值了!
要不然,很多文章读者都找不到,经常在后台问我,我也没有好办法,因为公众号的特点就是推送、展示最近的文章,有价值的老文章都被埋没了。
当然,这个知识库不是传统的基于“关键字”的搜索方式,这样比较局限,我想的是实现基于“语义”的搜索和对话。比如两篇文章,关键词不同,但是讲的是同样一件事,它们都应该被搜出来。
这种“语义”搜索具体该怎么实现呢?说起来很简单,用向量数据库。
向量这个词听起来专业性很强,简单说就是一组有序的数值。比如我有四个词,它们的向量分别是这样的:
喵:[0.9, 0.1]
汪:[0.1, 0.9]
猫:[0.8, 0.2]
狗:[0.2, 0.8]
画成二维坐标系就变成了这样:

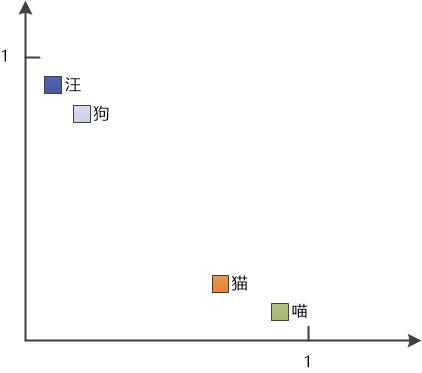
你一眼就能看出来,“喵”和“猫”具有相似的向量表示,因为它们俩的“距离”比较近。
“汪”和“狗”的向量也相似,它俩的“距离”也比较近。
这就意味着,我们成功地捕捉到了这四个词之间的语义关系。
如果把这四个词和它们对应的向量都存到向量数据库中,当你用“猫”来搜索的时候,不但能找到“猫”,还能找到距离它很近的“喵”,很不错吧。
那如何把文本变成向量呢?
这个过程叫做Embedding,程序员自己去实现是很复杂的,一般是调用训练好的模型来实现。
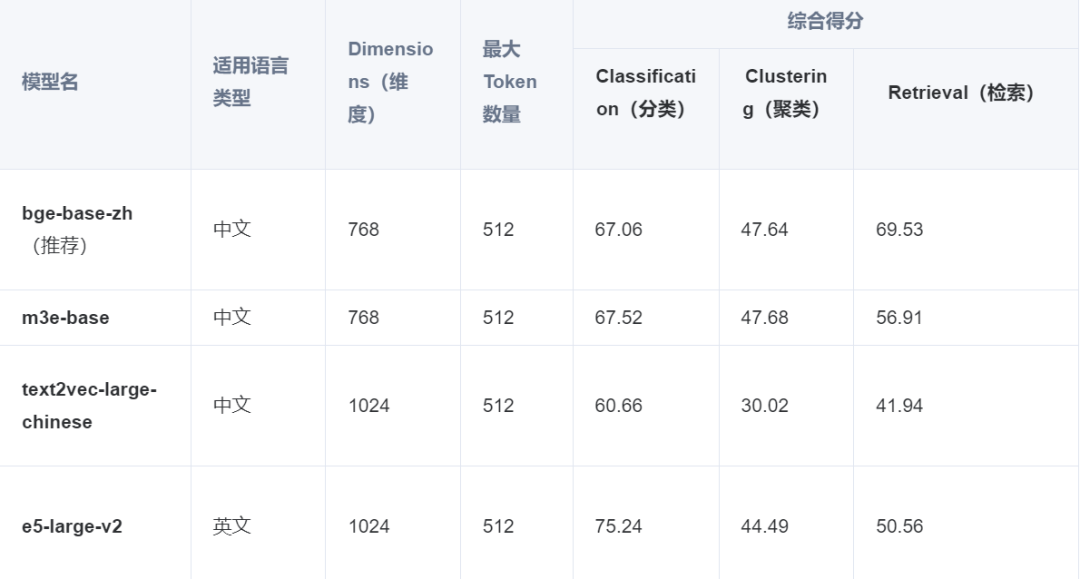
我们可以依据数据集的语言类型、向量维度、以及综合性能得分选择合适的模型:
理论的问题解决了,但是实现起来很麻烦,需要对文章进行结构解析,摘要提取,分段,分词,用Embedding模型做转换,保存到某向量数据库。
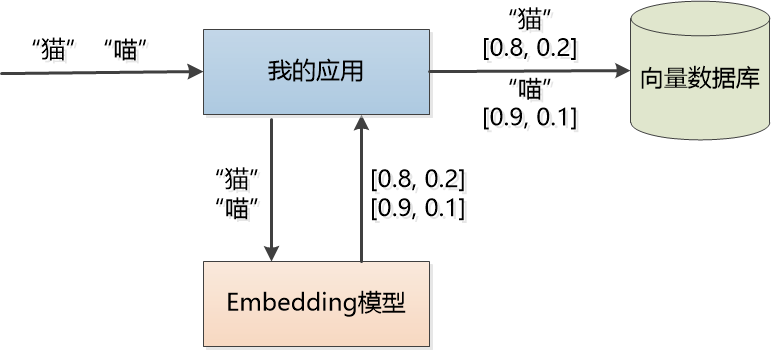
在搜索的时候,还得先把用户的输入也转换成向量,再到向量数据库用某种算法(如内积、欧式距离、余弦相似度)去计算,找到语义上相似的段落返回。
如果你的数据量比较大,还得考虑数据的分片、高可用性等各种分布式系统的东西,难度陡然上升。
有没有一种办法,把复杂的处理过程封装起来,提供一个端到端的能力,让我直接把文本导入,别管什么向量,Embedding等内容就可以用起来呢?最好有这样的云服务,让我直接使用。
我搜了一下,发现腾讯云向量数据库真是提供了这样的功能。
对程序员来说,可以通过和关系数据库对比的方式来理解向量数据库:
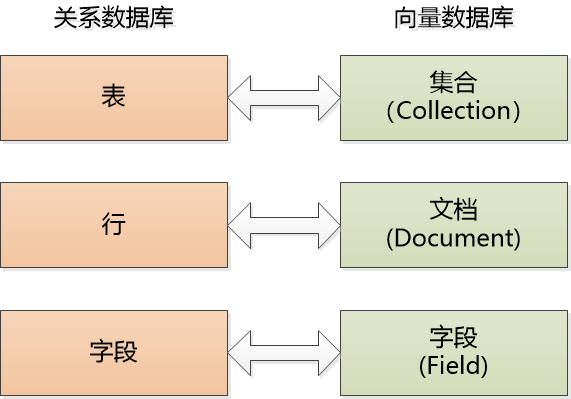
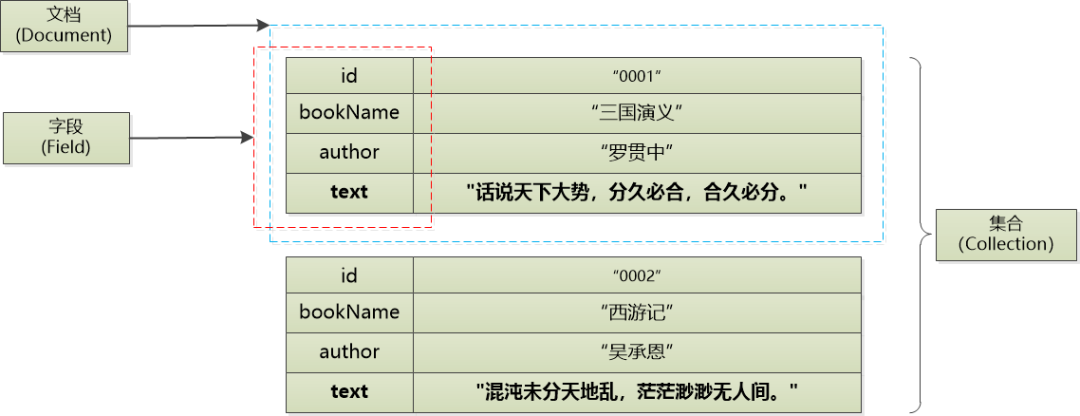
假设我要把上面的文档保存到数据库中,那在创建集合(Collection)的时候,告诉腾讯云向量数据库,把text对应的字段用Embedding做向量化就可以了。
腾讯云向量数据库会自动调用模型,把text字段生成向量,和原始文本文档一起,保存到数据库中。
{
"id": "0001",
"vector": [
-0.5230354070663452,
-0.782520055770874,
-0.7537766098976135,
0.11003035306930542,
-0.5210883617401123,
0.22735075652599335,
......
-0.6289583444595337
],
"text": "话说天下大势,分久必合,合久必分。",
"author": "罗贯中",
"bookName": "三国演义"
}
这个Embedding模型生成的向量可不是只有二维,而是有768个维度。
为了方便使用,腾讯云向量数据库还提供了HTTP接口,来实现“CRUD”操作,复杂的细节都被屏蔽,程序员就可以开心地使用了。

不用担心你的数据量大,因为腾讯云向量数据库采用分布式部署架构,可以将数据拆分成多个分片,分配到不同的节点上进行存储和处理,每个分片还可以在其他节点上同步创建多个副本,保证数据库的可扩展性和高可用性。
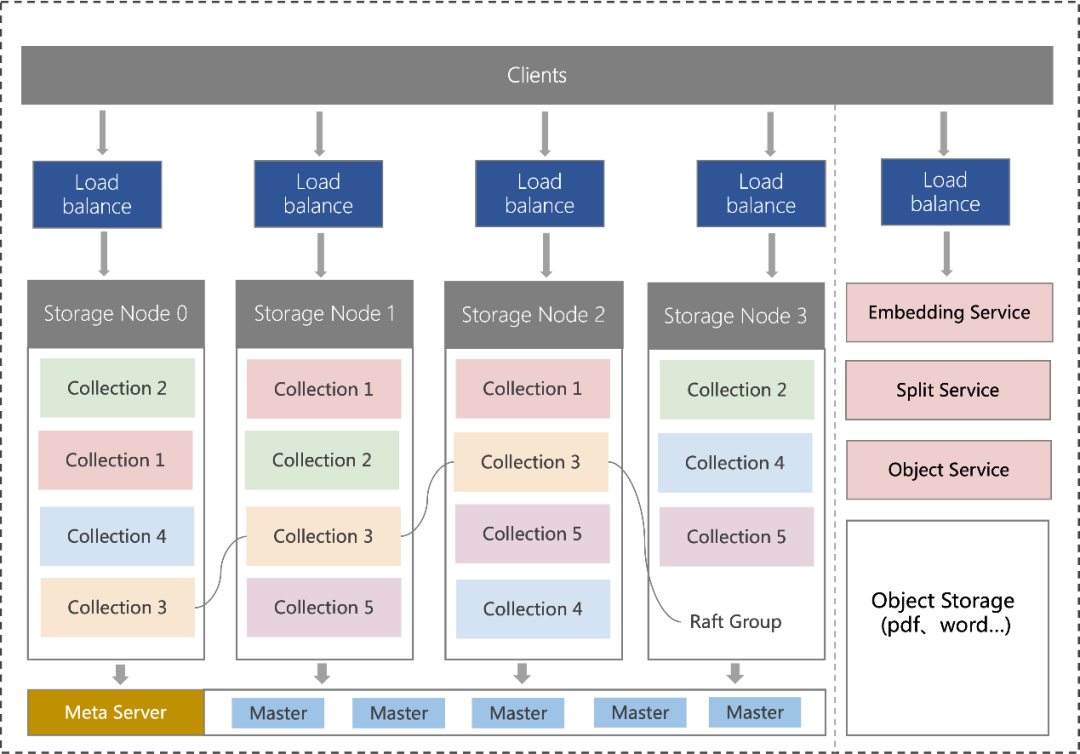
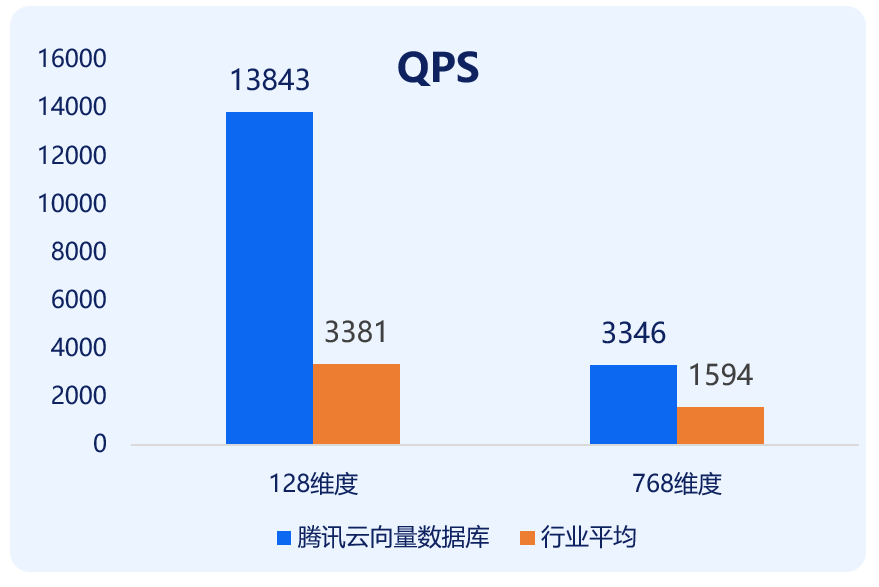
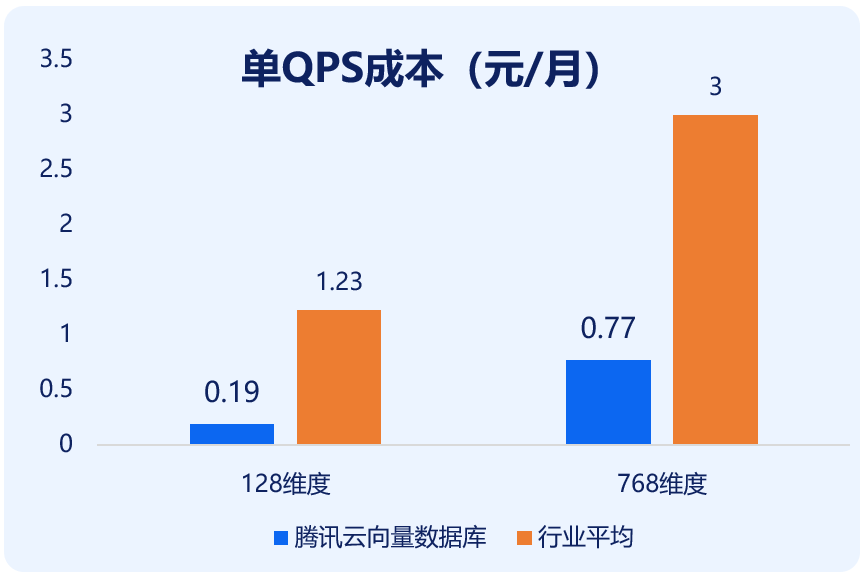
出色的架构设计,让腾讯云向量数据库的性能大幅提升的同时,成本也大幅下降。
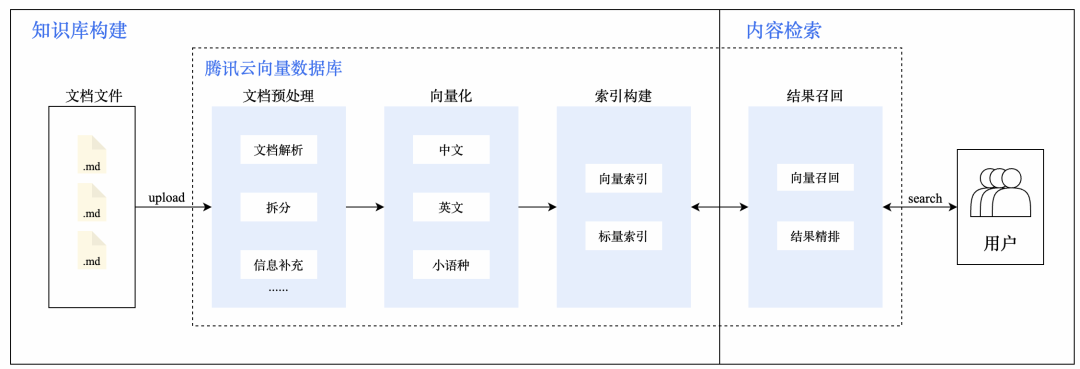
腾讯云向量数据库也提供了一站式的整体解决方案,帮客户解决从文档的预处理,到向量化模型的选择,到索引自动构建,到最终的结果排序整个端到端解决方案,极大的降低客户的使用门槛。
自从2019年自研向量数据库以来,腾讯云的向量数据库接入了腾讯集团40+业务,每天超过1600亿次的请求调用,今年8月公测以后,外部企业客户也接入了超过1000家。他们有的用向量数据库实现了智能客服的升级,有的基于向量数据库接入了大模型,构建了自己的AI业务。

经过一番考察,腾讯云向量数据库可以完美地满足我的需求了,接下来只需要把我的公众号文章下载下来,定义好字段,索引,保存到向量数据库中就行。但这一步也不好弄,如果腾讯云直接提供文章下载/抓取服务就好了!
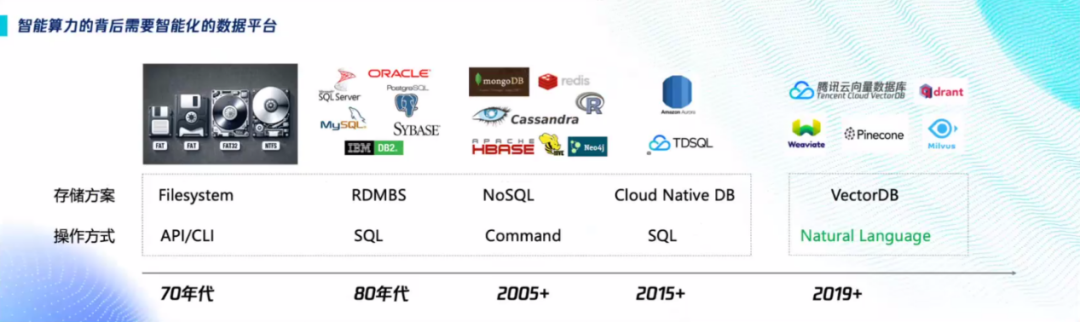
回顾过去几十年应用程序开发的历程,不管是大型机,小型机,还是后来的PC,手机,都需要程序员写出专业的代码,用特定的编程语言,开发应用程序来和这些算力进行交互。现在AGI时代来临,任何人都可以通过自然语言把这些算力给调度起来,这是一种革命性的变化。

在这种变化的底层是存储方式的变化,从早期的文本存储,到关系数据库,NoSQL。如今的向量数据库正是支持自然语言调度算力的核心,这也是向量数据库为什么如此流行的重要原因。
在计算范式发生变化的时代,我们每个程序员都要重点关注,向量数据库是其中的一环,强烈建议小伙伴们都去看一看,了解它的技术特点和能力,看看如何利用起来,给个人或者公司带来更大的价值。
在11月15日的Techo Day腾讯技术开放日中,腾讯云发布了业界“首个”向量数据库技术标准,揭秘了“业界最高召回率+千亿级向量规模”的重磅方案,相关的资料和课件都整合成了一份《腾讯云工具指南》,这份资料技术含量很高,可以帮助学习了解向量数据库的技术优势和价值应用。
资料包含数据库的发展趋势和产品价值解读,还有实打实的向量数据库应用案例和解决方案,感兴趣的小伙伴,建议不要错过这个福利!

(长按即可识别)
此外,腾讯云向量数据库x百川智能【AGI启航计划】正式启动,向量数据库免费实例+ Baichuan2400万免费Tokens限量领取,帮助您快速搭建RAG应用,点击“阅读原文”即可获取,Chat With Your Data!