一、Pod概述
1.1 Pod的定义
Pod是kurbernets集群中最小的创建和运行管理单元,一个 Pod 又由多个容器组成。
1.2 一个Pod能包含几个容器?
1个pause容器(基础容器/父容器/根容器)
1个或者多个应用容器(业务容器)
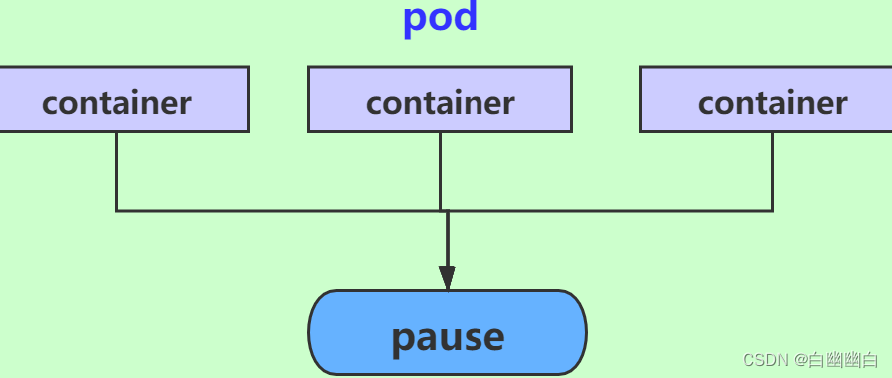
通常一个Pod最好只包含一个应用容器,一个应用容器最好也只运行一个业务进程。
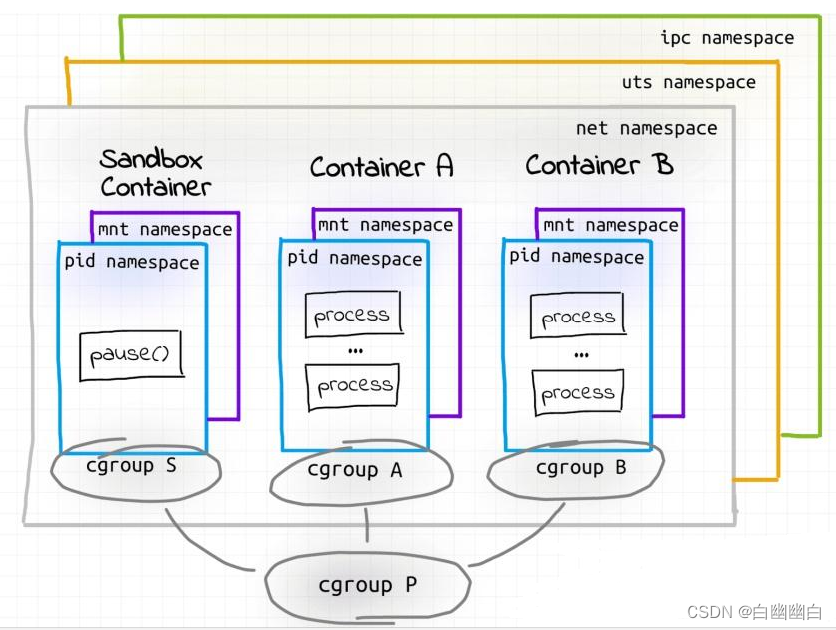
同一个Pod里的容器都是运行在同一个node节点上的,并且共享 net、mnt、uts、 pid、 ipc 命名空间。
1.3 Pod的分类
1.3.1 控制器管理的Pod
1)由scheduler进行调度的;
2)被控制器管理的;
3)有自愈能力,一旦Pod挂掉了,会被控制器重启拉起;
4)有副本管理、滚动更新等功能。
#创建命令
kubectl create deployment/statefulset/daemonset ....
1.3.2 自主式Pod
1)由scheduler进行调度的;
2)不被控制器管理的;
3)没有自愈能力,一旦Pod挂掉了,不会被重启拉起;
4)没有副本管理、滚动更新功能。
#创建命令
kubectl run ....
1.3.3 静态Pod
1)不由schedule调度,是由kubelet自行管理;
2)始终和kubelet运行在同一个node节点上,不能直接删除。
静态Pod的yaml配置文件目录默认存放 于/etc/kubernetes/manifests目录。
在此目录下创建或者删除yaml配置文件,kubelet会自动创建或删除静态Pod。
1.4 Pod中容器的分类
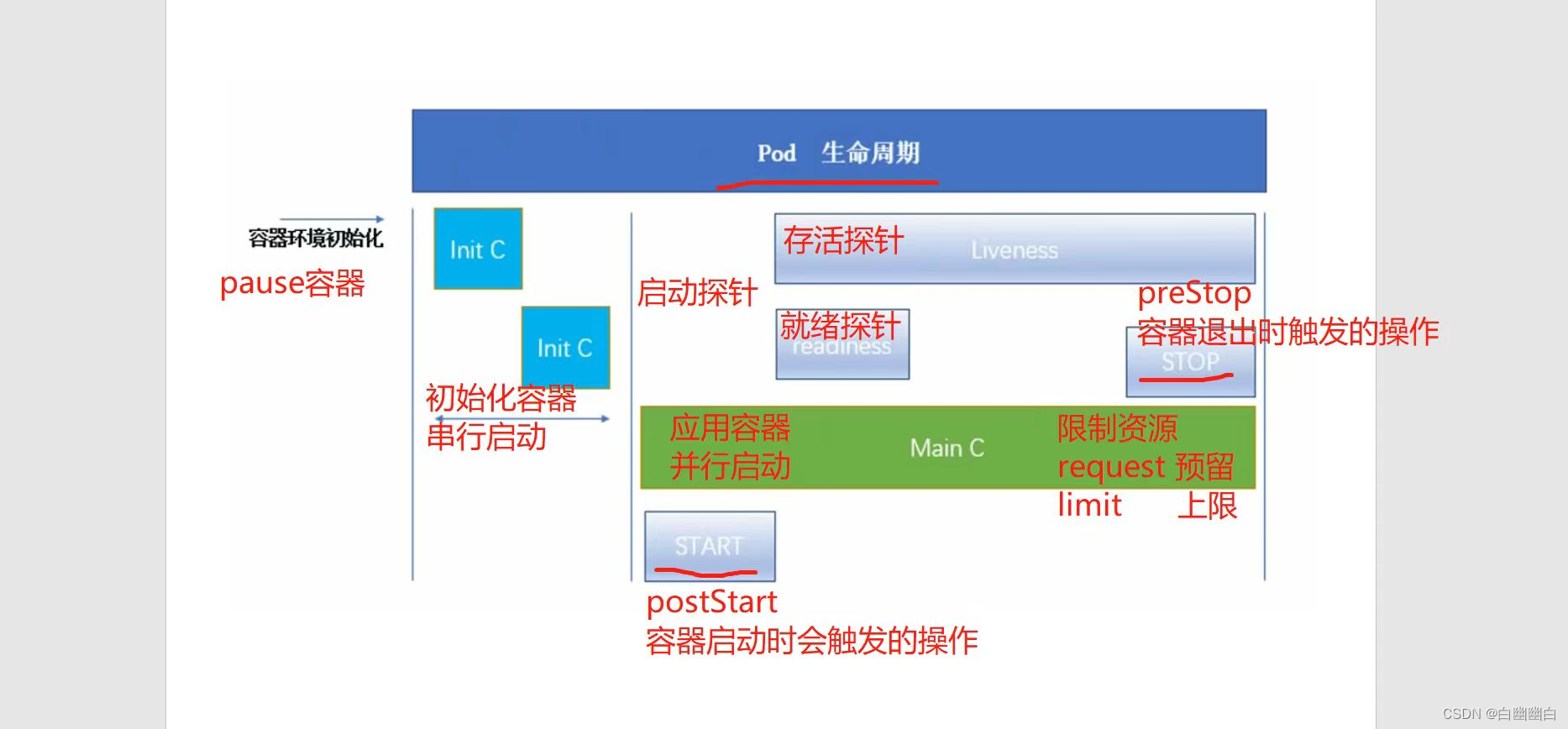
1.4.1 Pause容器
Pause容器,基础容器/父容器/根容器。
作用:
1)作为linux命名空间(net mnt uts pid ipc)共享的基础,给Pod里的其它容器提供网络、存储资源的共享;
2)作为pid=1的init进程管理整个Pod容器组的生命周期。
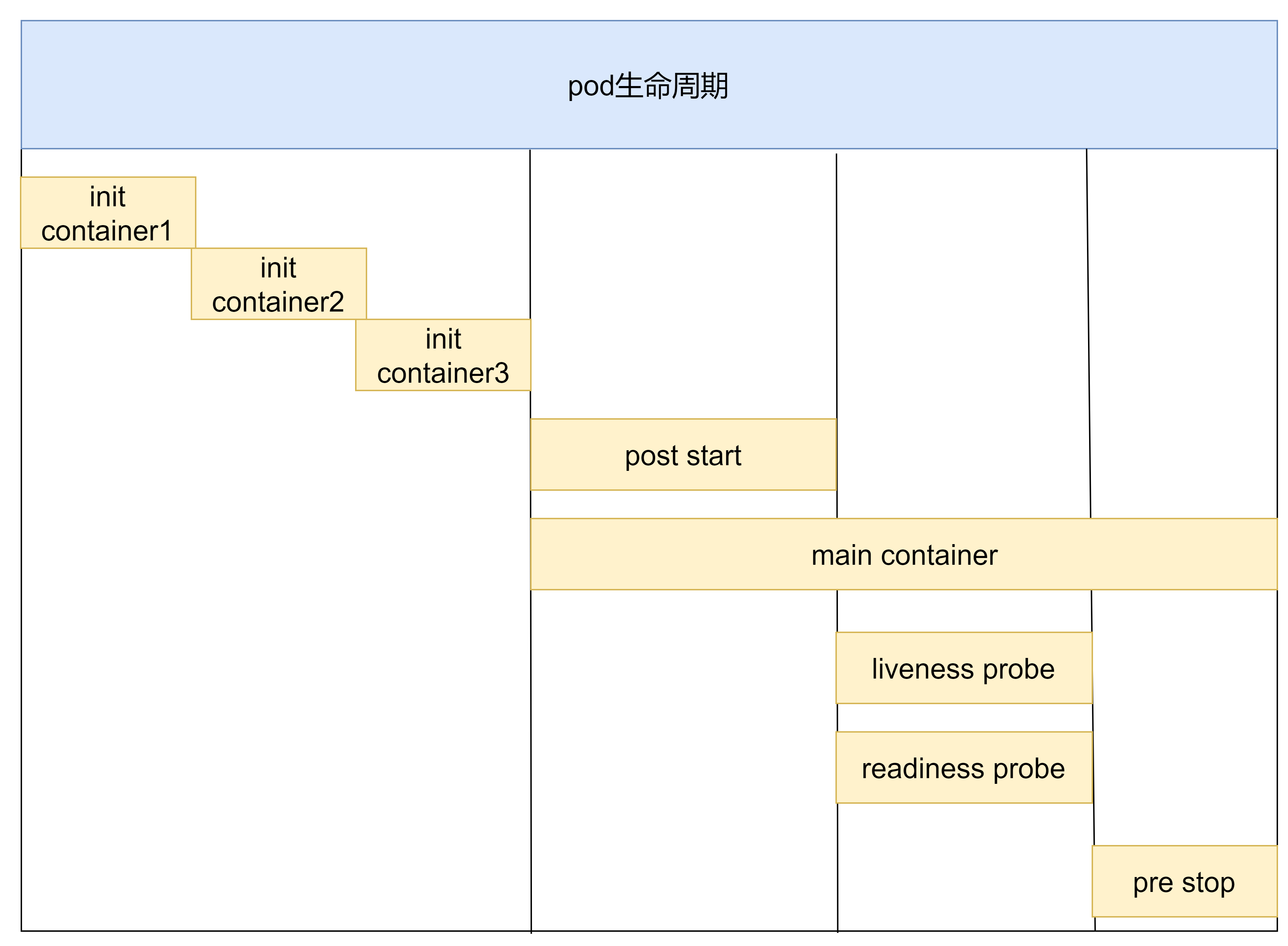
1.4.2 初始化容器
Init Container ,初始化容器。
作用:
1)为应用容器启动前提供运行依赖环境或者工具包;
2)可以阻塞或者延迟应用容器的启动
特性:Pod有多个init容器时,是串行启动的,即要在上一个init容器成功的完成启动、运行、退出后,才会启动下一个init容器。
1.4.3 应用容器
应用容器(Main Container) ,也叫业务容器。
作用: 提供应用程序业务
特性:Pod有多个应用容器时,是并行启动的,即应用容器要在所有init容器都成功的完成启动、运行、退出后才会启动。
1.5 Pod常见的状态
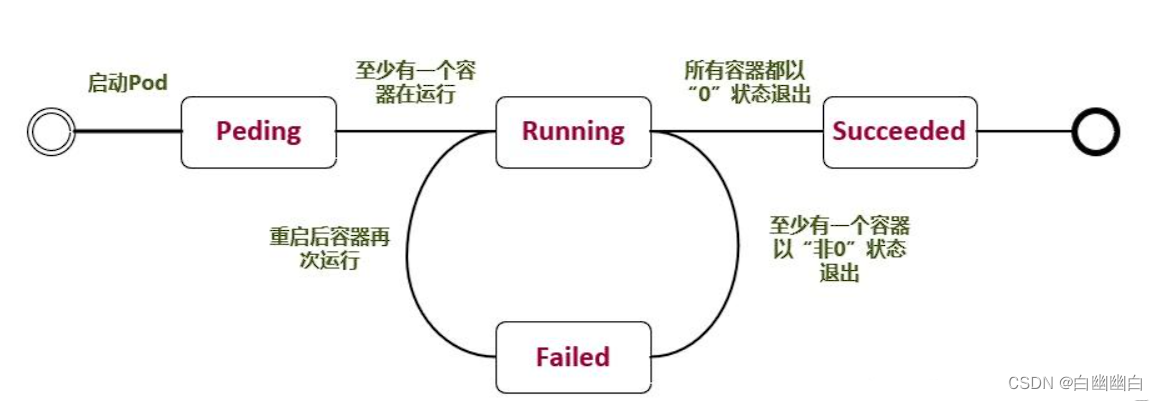
| 状态 | 状态名 | 描述 |
|---|---|---|
| Pending | 挂起 | Pod已经创建 但是Pod还处于包括未完成调度到node节点的过程或者还处于在镜像拉取过程中、存储卷挂载失败的情况 |
| Running | Pod所有容器已被创建,且至少有一个容器正在运行 | |
| Succeeded | 容器成功退出 | Pod所有容器都已经成功退出,且不再重启。(completed) |
| Failed | 容器失败退出 | Pod所有容器都退出,且至少有一个容器是异常退出的。(error) |
| Unknown | 未知状态 | master节点的controller manager无法获取到Pod状态 通常是因为master节点的apiserver与Pod所在node节点的kubelet通信失联导致的(比如kubelet本身出故障) |
总结: Pod遵循预定义的生命周期,起始于Pending阶段,如果至少其中有一个主容器正常运行,则进入Running阶段,之后取决于Pod是否有容器以失败状态退出而进入Succeeded或者Failed阶段。
二、Pod中的策略
2.1 镜像拉取策略
Kubernetes 是一个容器编排平台,用于管理和运行容器化应用程序,在 Kubernetes 中,容器是通过镜像创建的,而镜像可以从容器注册表中拉取。

imagePullPolicy 是一个用于定义 Kubernetes Pod 中容器镜像拉取策略的属性。
当 Pod 创建或重新启动时,Kubernetes 会根据 imagePullPolicy 属性确定容器镜像的拉取策略。
| 值 | 描述 |
|---|---|
ifNotPresent |
优先使用本地已存在的镜像,如果本地没有则从仓库拉取镜像。是标签为非latest的镜像的默认拉取策略 |
Always |
总是从仓库拉取镜像,无论本地是否已存在镜像。是标签为latest或无标签的镜像的默认拉取策略 |
Never |
仅使用本地镜像,总是不从仓库拉取镜像 |
默认情况下,imagePullPolicy 的值为 Always,这意味着 Kubernetes 在创建或重新启动 Pod 时,始终尝试拉取最新的镜像。
2.2 Pod中容器的重启策略
重启策略restartPolicy(与containers字段同一层级)。
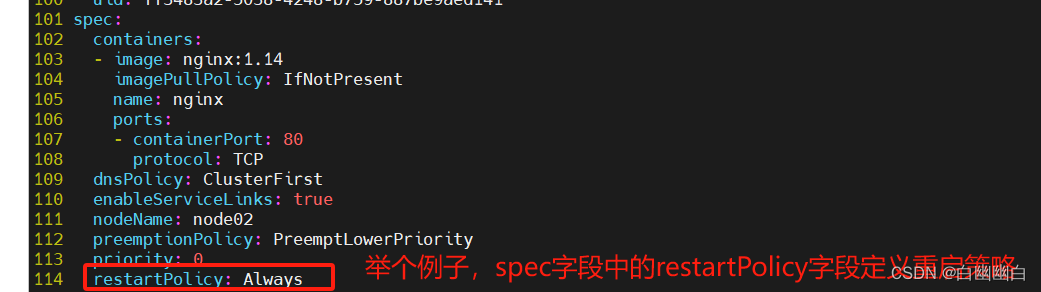
1)Always
当Pod容器退出时,总是重启容器,无论容器退出状态码如何。是默认的容器重启策略。
2)OnFailure
当Pod容器异常退出时(容器退出状态码为非0),才会重启容器;正常退出的容器(容器退出状态码为0)不会重启。
3)Never
当Pod容器退出时,总是不重启容器,无论容器退出状态码如何
三、Pod容器的资源限制 (面试必问)
官方文档:为 Pod 和容器管理资源 | Kubernetes
3.1 基于Requests和Limits的Pod调度机制
-
当为 Pod 中的容器指定了 request 资源时,代表容器运行所需的最小资源量,调度器就使用该信息来决定将 Pod 调度到哪个节点上。
-
当为容器指定了 limit 资源时,kubelet 就会确保运行的容器不会使用超出所设的 limit 资源量。
-
调度器在调度时,首先要确保调度后该节点上所有Pod的CPU和内存的Requests总和,不超过该节点能提供给Pod使用的CPU和Memory的最大容量值。
-
可能某节点上的实际资源使用量非常低,但是已运行Pod配置的Requests值的总和非常高,再加上需要调度的Pod的Requests值,会超过该节点提供给Pod的资源容量上限,这时Kubernetes仍然不会将Pod调度到该节点上。
-
如果Kubernetes将Pod调度到该节点上,之后该节点上运行的Pod又面临服务峰值等情况,就可能导致Pod资源短缺。
3.2 Pod容器的资源限制
与image字段同一层级
`resources.requests.cpu|memory|hugepages-<size>|ephemeral-storage|gpu(需要第三方插件支持)` #设置Pod容器创建时需要预留的资源量
`resources.limits.cpu|memory|hugepages-<size>|ephemeral-storage|gpu(需要第三方插件支持)` #设置Pod容器能够使用的最大资源量
3.3 资源量单位
Kubernetes的计算资源单位是大小写敏感的。
1.CPU
| 资源量 | 单位 |
|---|---|
| CPU核(Cores)数/个数 | 1 、2 、 0.1 、0.5、 1.25 |
| CPU豪核(mCores) | 1000m、 2000m 、 100m 、 500m 、1250m |
例如:一个Pod分配 0.5 核 CPU,表示它占用了系统总CPU能力的一半。
2.内存
内存的Requests和Limits计量单位是字节数,使用整数或者定点整数加上国际单位制(InternationalSystem of Units)来表示内存值。
KiB与MiB是以二进制表示的字节单位,常见的KB与MB则是以十进制表示的字节单位。
◎ 1 KB(KiloByte)= 1000 Bytes = 8000 Bits;
◎ 1 KiB(KibiByte)= 210Bytes = 1024 Bytes = 8192 Bits。因此,128974848、129e6、129M、123Mi的内存配置是一样的。
| 资源量 | 单位 | 描述 |
|---|---|---|
| 内存 (memory) | KiB与MiB、KB与MB | 用于表示容器可用的内存大小 |
| 临时存储 (ephemeral-storage) | KiB与MiB 、KB与MB | 表示容器可以使用的临时存储空间大小,通常用于临时存储数据、日志等 |
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: my-container
image: my-image
resources:
requests:
memory: "1Gi"
ephemeral-storage: "100Gi"
limits:
memory: "2Gi"
ephemeral-storage: "200Gi"
#上面的示例中,容器请求 1GB 内存和 100GB 临时存储空间,同时容器的上限为 2GB 内存和 200GB 临时存储空间。
3.4 大页内存
hugepages-2Mi 是 Linux 内核提供的一种机制,用于管理大页内存,即 2MB 页大小的内存。
大页内存的使用可以提升内存访问效率,特别是对于需要大量内存的应用程序,如数据库等。
在 Pod 的 YAML 文件中,可以通过设置 hugepages-2Mi 资源请求和限制来指定应用程序需要的大页内存数量。
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: my-container
image: my-image
resources:
requests:
hugepages-2Mi: 4Gi
limits:
hugepages-2Mi: 8Gi
#容器请求 4GB 的 HugePages-2Mi 内存
#同时容器的限制为 8GB 的 HugePages-2Mi 内存
注意,请求和限制的值必须是 HugePages-2Mi 页的整数倍。
容器可以通过挂载 HugePages-2Mi 文件系统来访问 HugePages-2Mi 内存。
mkdir /mnt/huge
mount -t hugetlbfs -o pagesize=2M none /mnt/huge
#在容器内创建 /mnt/huge 目录并挂载 HugePages-2Mi 文件系统
#容器可以将内存分配给 /mnt/huge 目录,并通过 mmap() 系统调用映射 HugePages-2Mi 内
3.5 相关命令
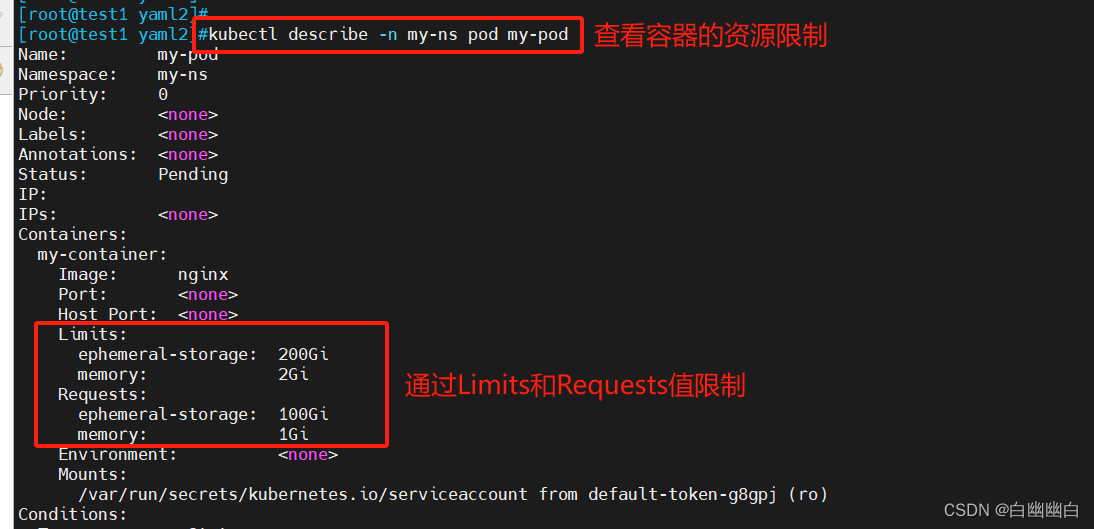
#查看Pod中的每个容器的资源限制的配置
kubectl describe [-n 命名空间] pod <pod名称>
#查看node节点的每个Pod和总的资源限制情况
kubectl describe node <node名称>

3.6 举个例子
计算资源使用情况监控
apiVersion: v1
kind: LimitRange
metadata:
name: mylimits
spec:
limits:
- type: Pod # pod 的max、min、maxLimitRequestRatio
max:
cpu: "4"
memory: 2Gi
min:
cpu: 200m
memory: 6Mi
maxLimitRequestRatio:
cpu: "3"
memory: "2"
- type: Container #container 级别的default、defaultRequest、max、min、maxLimitRequestRatio
default:
cpu: 300m
memory: 200Mi
defaultRequest:
cpu: 200m
memory: 100Mi
max:
cpu: "2"
memory: 1Gi
min:
cpu: 100m
memory: 3Mi
maxLimitRequestRatio:
cpu: "5"
memory: "4"
#创建方式
kubectl create -f <yaml文件名> --namespace=<namespaces名>
a. container 的参数:
max、min: 指的是单个container 的最大值和最小值限制.
maxLimitRequestRatio: 指的是MaxLimit/Requests Ratio的比值。
可以设置Default Request和Default Limit参数,值得是默认Pod中所有未指定Request/Limits值的容器的默认Request/Limits值。
Min ≤ Default Request ≤ Default Limit ≤Max。
b. Pod 参数:
max、min: 指的是Pod中所有容器的Requests值的总和最大值和最小值。
maxLimitRequestRatio:Pod中所有容器的Limits值总和与Requests值总和的比例上限。
Pod不能设置Default Request和Default Limit参数。
#注意
a.Container 设置了max ,容器必须设置limits。Pod内容器未设置Limits,将使用Default Limit,如果也未设置Default,则无法成功创建。
设置了max,那么容器需要limits > DefaultsLimits > 无法成功创建。
b. Container 设置了Min,集群中容器必须设置Requests,如果未设置Request,将使用defaultRequest,如果也为配置DefaultRequest,会默认等于该容器的Limits,如果Limits也未定义,就会报错。
设置了min, 那么 需要Requests > DefaultRequest> Limits > 报错。依次使用字段。
c. Pod里任何容器的Limits与Requests的比例都不能超过Container的Max Limit/RequestsRatio;Pod里所有容器的Limits总和与Requests的总和的比例不能超过Pod的Max Limit/RequestsRatio。
执行效果
- 命名空间中LimitRange只会在Pod创建或者更新时执行检查。
- 如果手动修改LimitRange为一个新的值,那么这个新的值不会去检查或限制之前已经在该命名空间中创建好的Pod。
- 如果在创建Pod时配置的资源值(CPU或者内存)超过了LimitRange的限制,那么该创建过程会报错,在错误信息中会说明详细的错误原因。
补充:Pod中容器会触发oom错误的原因
如果Pod容器中进程使用的内存超过limits.memory设置的资源量,会引发内存不足(OOM)错误
四、Pod容器的健康检查
探针(Probe)
4.1 使用背景
因为 k8s 中采用大量的异步机制、以及多种对象关系设计上的解耦,当应用实例数 增加/删除、或者应用版本发生变化触发滚动升级时,系统并不能保证应用相关的 service、ingress 配置总是及时能完成刷新。
在一些情况下,往往只是新的 Pod 完成自身初始化,系统尚未完成 Endpoint、负载均衡器等外部可达的访问信息刷新,老得 Pod 就立即被删除,最终造成服务短暂的额不可用,这对于生产来说是不可接受的。
所以 k8s 就加入了一些存活性探针:startupProbe、livenessProbe、readinessProbe。
4.2 Pod容器的健康检测方式(三种探针)
4.2.1 Liveness Probe(存活探针)
探测容器是否在正常运行。
如果探测失败则kubelet杀掉容器,并根据容器重启策略决定是否重启容器
4.2.2 Readiness Probe(就绪探针)
探测Pod是否进入就绪状态(ready状态栏是否100%比例),并做好接收service请求的准备。
如果探测失败则Pod变成未就绪状态(ready状态栏不是100%比例),service资源会删除所关联的Pod的端点,并不会转发请求给未就绪的Pod
4.2.3 Startup Probe(启动探针)
探测容器内的应用进程是否启动成功。
在启动探针探测成功之前,存活探针和就绪探针都会暂时处于无效状态,直到启动探针探测成功。
如果探测失败,kubelet会杀掉容器,并根据容器重启策略决定是否重启容器。
4.3 Probe支持的三种检查方法
4.3.1 exec方式
在容器中执行linux命令;
如果命令返回码为0则认为探测成功。
如果命令返回码为非0值则认为探测失败。
4.3.2 tcpSocket方式
向PodIP和指定的端口发送tcp连接请求。
如果端口正确且tcp连接成功则认为探测成功。
如果tcp连接失败则认为探测失败。
4.3.3 httpGet方式
向Pod IP和指定的端口及URL路径发送HTTP GET请求;
如果HTTP响应状态码为2XX、3XX则认为探测成功。
如果HTTP响应状态码为4XX 、5XX则认为探测失败。
4.4 探测参数和探测结果
| 探测参数 | 描述 | |
|---|---|---|
initialDelaySeconds |
指定容器启动后延迟探测的秒数 | 默认是 0 秒,最小值是 0 |
periodSeconds |
指定每次探测间隔的秒数 | 默认是 10 秒,最小值是 1 |
failureThreshold |
探测连续失败判断整体探测失败的次数 | 默认值是 3,最小值是 1 |
timeoutSeconds |
指定探测超时等待的秒数 | 默认值是 1 秒,最小值是 1 |
| 探测结果 | 描述 | |
|---|---|---|
| Success | 成功 | 表示容器通过了检测 |
| Failure | 失败 | 表示容器未通过检测 |
| Unknown | 未知 | 表示检测没有正常进行 |
五、健康检查应用实例
官方示例:Configure Liveness, Readiness and Startup Probes | Kubernetes
5.1 LivenessProbe 探针
使用示例
示例1:exec方式
思路整理
1)容器在初始化后,执行命令;
/bin/sh -c "touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600"`
#创建一个 /tmp/healthy 文件
#然后执行睡眠命令,睡眠 30 秒
#到时间后执行删除 /tmp/healthy 文件命令
2)设置的存活探针检检测方式为执行 shell 命令;
用 cat 命令输出 healthy 文件的内容,如果能成功执行这条命令一次(默认 successThreshold:1),存活探针就认为探测成功。
由于没有配置(failureThreshold、timeoutSeconds),所以执行(cat /tmp/healthy)并只等待 1s,如果 1s 内执行后返回失败,探测失败。
3)判断方式:
在前 30 秒内,由于文件存在,所以存活探针探测时执行 cat /tmp/healthy 命令成功执行。
30 秒后 healthy 文件被删除,所以执行命令失败,Kubernetes 会根据 Pod 设置的重启策略来判断,是否重启 Pod。
编写配置清单文件
vim liveness-exec.yaml
apiVersion: v1
kind: Pod
metadata:
name: liveness-exec
labels:
app: liveness
spec:
containers:
- name: liveness
image: busybox
args: #创建测试探针探测的文件
- /bin/sh
- -c
- touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600
livenessProbe:
initialDelaySeconds: 10 #延迟检测时间
periodSeconds: 5 #检测时间间隔
exec: #使用命令检查
command: #指令,类似于运行命令sh
- cat #sh 后的第一个内容,直到需要输入空格,变成下一行
- /tmp/healthy #由于不能输入空格,需要另外声明,结果为sh cat"空格"/tmp/healthy
创建Pod并观察健康探测状况
#创建
kubectl create -f liveness-exec.yaml

#详细信息
kubectl describe pods liveness-exec

示例2:httpGet方式
思路
1)在 pod 启动后,初始化等待 20s 后,livenessProbe 开始工作,去请求 http://Pod_IP:8081/ping 接口,考虑到请求会有延迟,所以给这次请求操作一直持续 5s;
2)如果 5s 内访问返回数值在>=200 且<=400 代表第一次检测 success,如果是其他的数值,或者 5s 后还是假死状态,执行类似(ctrl+c)中断,并反回 failure 失败。
等待 10s 后,再一次的去请求 http://Pod_IP:8081/ping 接口。
3)判断方式
如果有连续的 2 次都是 success,代表无问题;
如果期间有连续的 5 次都是 failure,代表有问题,直接重启 pod,此操作会伴随 pod 的整个生命周期。
编写资源配置清单文件
vim liveness-http.yaml
apiVersion: v1
kind: Pod
metadata:
name: liveness-http
labels:
test: liveness
spec:
containers:
- name: liveness
image: nginx:latest
livenessProbe:
failureThreshold: 5 #检测失败5次表示未就绪
initialDelaySeconds: 20 #延迟加载时间
periodSeconds: 10 #重试时间间隔
timeoutSeconds: 5 #超时时间设置
successThreshold: 1 #检查成功1次表示就绪
httpGet:
scheme: HTTP
port: 8081
path: /ping
Kubernetes 将使用 HTTP GET 请求来探测容器中的 /ping 路径,并在每隔 10 秒进行一次探测。
如果容器返回成功的响应(HTTP 状态码为 2xx),则认为该容器是存活和就绪的。
如果连续失败 5 次,容器将被标记为未准备就绪
kubectl create -f
kubectl describe pod liveness-http

示例3:通过 TCP 方式做健康探测
思路
1)在容器启动 initialDelaySeconds 参数设定的时间后,kubelet 将发送第一个livenessProbe 探针,尝试连接容器的 80 端口,类似于 telnet 80 端口;
2)每隔 20 秒(periodSeconds)做探测,如果连接失败则Pod 重启容器;
3)如果容器的存活探针在连续 2 次检查中失败,则容器将被认为是不健康的,并且 Kubernetes 将尝试重启该容器,或将其从集群中删除。
编写配置清单文件
vim liveness-tcp.yaml
apiVersion: v1
kind: Pod
metadata:
name: liveness-tcp
labels:
app: liveness
spec:
containers:
- name: liveness
image: nginx
livenessProbe:
initialDelaySeconds: 15
periodSeconds: 20
tcpSocket:
port: 80
failureThreshold: 2
测试
kubectl apply -f liveness-tcp.yaml
kubectl describe pod liveness-tcp

5.2 ReadinessProbe 探针使用示例
ReadinessProbe 探针使用方式和 LivenessProbe 探针探测方法一样,也是支持三种,只是一个是用于探测应用的存活,一个是判断是否对外提供流量的条件。
vim readiness-exec.yaml
apiVersion: v1
kind: Pod
metadata:
name: readiness-exec
labels:
app: readiness-exec
spec:
containers:
- name: readiness-exec
image: busybox
args: #创建测试探针探测的文件
- /bin/sh
- -c
- touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600
livenessProbe:
initialDelaySeconds: 10
periodSeconds: 5
exec:
command:
- cat
- /tmp/healthy
---
apiVersion: v1
kind: Pod
metadata:
name: readiness-http
labels:
app: readiness-http
spec:
containers:
- name: readiness-http
image: test.com/test-http-prober:v0.0.1
ports:
- name: server
containerPort: 8080
- name: management
containerPort: 8081
readinessProbe:
initialDelaySeconds: 20
periodSeconds: 5
timeoutSeconds: 10
httpGet:
scheme: HTTP
port: 8081
path: /ping
---
apiVersion: v1
kind: Pod
metadata:
name: readiness-tcp
labels:
app: readiness-tcp
spec:
containers:
- name: readiness-tcp
image: nginx
livenessProbe:
initialDelaySeconds: 15
periodSeconds: 20
tcpSocket:
port: 80
5.3 StartupProbe 探针使用示例
思路
1)在容器启动 initialDelaySeconds (5 秒) 参数设定的时间后,kubelet 将发送第一个 StartupProbe 探针,尝试连接容器的 80 端口。;
2)如果连续探测失败没有超过 3 次 (failureThreshold) ,且每次探测间隔为 5 秒 (periodSeconds) 和探测执行时间不超过超时时间 10 秒/每次 (timeoutSeconds),则认为探测成功,反之探测失败,kubelet 直接杀死 Pod。
文件编写及测试
vim startup.yaml
apiVersion: v1
kind: Pod
metadata:
name: startup
labels:
app: startup
spec:
containers:
- name: startup
image: nginx
startupProbe:
failureThreshold: 3 # 失败阈值,连续几次失败才算真失败
initialDelaySeconds: 5 # 指定的这个秒以后才执行探测
timeoutSeconds: 10 # 探测超时,到了超时时间探测还没返回结果说明失败
periodSeconds: 5 # 每隔几秒来运行这个
httpGet:
path: /test
port: 80
六、Pod应用容器生命周期的启动动作和退出动作
lifecycle.postStart 设置Pod中的应用容器启动时额外执行的操作
lifecycle.preStop 设置Pod中的应用容器被kubelet杀掉退出时执行的操作(不包含容器自行退出的情况)