一、Pod的自动伸缩
注:HPA和VPA不能同时使用。
HPA 主要关注整个应用程序水平方向的伸缩,通过调整 Pod 的副本数量来应对负载变化;
VPA 则关注 Pod 内部容器的垂直伸缩,通过调整容器的资源限制来优化资源利用和性能。
1.1 HPA
1.1.1 简介
HPA: Pod水平自动伸缩,根据Pod的CPU(原生支持)或内存(后期的新版本支持)的使用率为控制器管理的Pod资源副本数量实现自动扩缩容。
1.1.2 HPA的实现原理

利用metrics-server插件组件,定期的(默认为15s)收集Pod资源的平均CPU负载情况,根据HPA配置的CPU或内存的requests资源量百分比阈值来动态调整Pod的副本数量。
HPA扩容时 ,Pod副本数量上升会比较快;
HPA缩容时 ,Pod副本数量下降会比较慢(默认冷却时间为5m)。
1.1.3 相关命令
#获取特定命名空间(Namespace)下的HorizontalPodAutoscaler(HPA)资源列表
kubectl get hpa -n <命名空间>
#自动伸缩Kubernetes控制器资源
kubectl autoscale <控制器资源类型> <控制器资源名称> --min=<最小副本数> --max=<最大副本数> --cpu-percent=<requests资源量百分比阈值>
#详解
<控制器资源类型>: 控制器资源的类型,例如Deployment、ReplicaSet等。
<控制器资源名称>: 控制器资源的名称,指定你要进行自动伸缩的资源。
--min=<最小副本数>: 指定自动伸缩时的最小副本数。
--max=<最大副本数>: 指定自动伸缩时的最大副本数。
--cpu-percent=<requests资源量百分比阈值>: 指定自动伸缩的CPU利用率阈值百分比。当控制器资源的CPU利用率达到阈值时,将自动扩展副本数。
1.2 VPA
1.2.1 简介
VPA: Pod垂直自动伸缩 ,根据Pod容器的CPU和内存的使用率自动设置Pod容器的CPU和内存的requests资源量限制。
1.2.2 VPA的组件
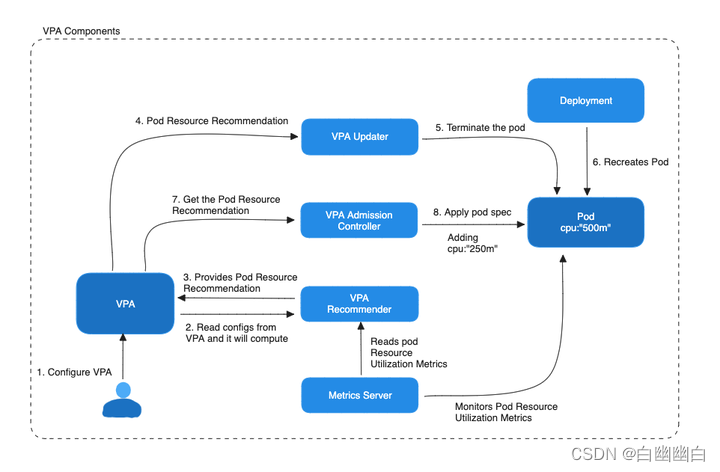
1)Recommender
recommender 会定期收集容器的资源使用数据,例如CPU 和内存的使用情况。
然后,它会应用一些策略和算法来计算容器的实际资源需求,并生成建议的资源请求配置。
这个建议配置包括容器应该请求多少 CPU 和内存资源,以满足其性能需求。建议配置通常存储在kubernetes的资源请求对象中。
2)Updater
updater会监视 kubernetes 中的资源请求对象,检测到recommender 生成的建议配置后,将其应用于容器的 pod 。
这将导致容器的资源请求值被更新为建议的值,从而确保容器拥有足够的资源来满足其性能需求。
3)Admission Controller
admission controller 拦截创建或修改 pod 的请求,并在提交到 kubernetes API 服务器之前检查这些请求。
如果 pod 的资源请求配置不符合 VPA 建议器生成的建议配置, admission controller 将阻止这个请求,并返回错误。
这确保了只有受 VPA 管理的 Pod 能够使用建议的资源配置。
1.2.3 VPA工作原理
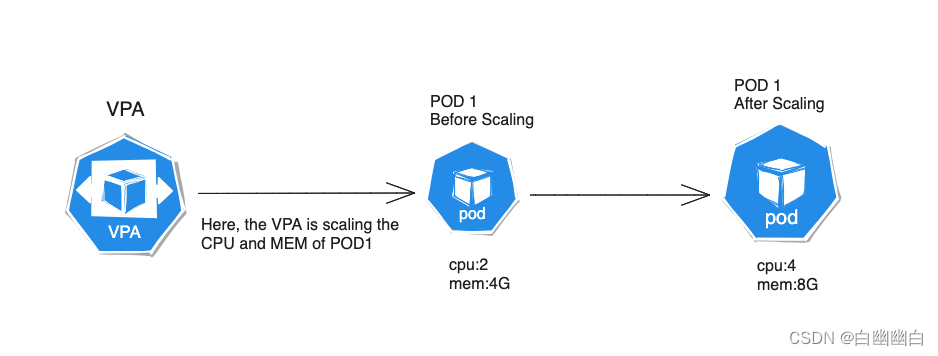
- 收集资源指标: VPA 通过与 Kubernetes 的 Metrics API 进行交互,获取关于容器和节点资源使用情况的指标数据。它可以收集 CPU 使用率、内存使用量等指标。
- 分析资源需求: VPA 将收集到的资源指标与用户定义的策略进行比较。策略可以是静态的,例如指定容器的最小和最大资源限制;或者是动态的,例如基于平均 CPU 使用率来调整容器的 CPU 分配。
- 生成建议:基于资源指标和策略的比较, VPA 生成针对每个容器的资源调整建议。这些建议可能包括增加或减少容器的 CPU 、内存等资源分配。
- 应用资源调整: VPA 将资源调整建议发送给 Kubernetes API 服务器,并通过修改 Pod 的规格 (Spec) 来应用资源调整。这可能涉及扩容或缩容 Pod ,调整容器的资源限制或请求等。
- 监测与迭代: VPA 持续监控 Pod 的资源使用情况,并根据需要进行进一步的资源调整。它可以根据实际情况动态地调整资源分配,以满足容器的需求。
总体而言, VPA 通过不断收集和分析资源指标,并根据定义的策略进行资源调整,实现了对容器资源的动态优化和自动化管理。这有助于提高资源利用率,减少资源浪费,并改善应用程序的性能和可靠性。
1.3 metrics-server简介
Metrics Server是一个 Kubernetes 插件,用于收集和提供集群中运行的 Pod 和 Node 的资源使用情况的度量数据。
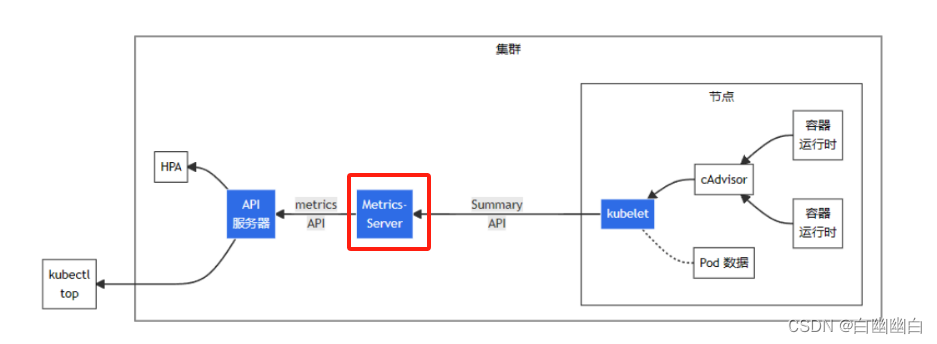
部署了metrics server插件后,能够使用kubectl top命令,可以查看 Pod、Node、命名空间以及容器的资源利用率(如 CPU 和内存)。
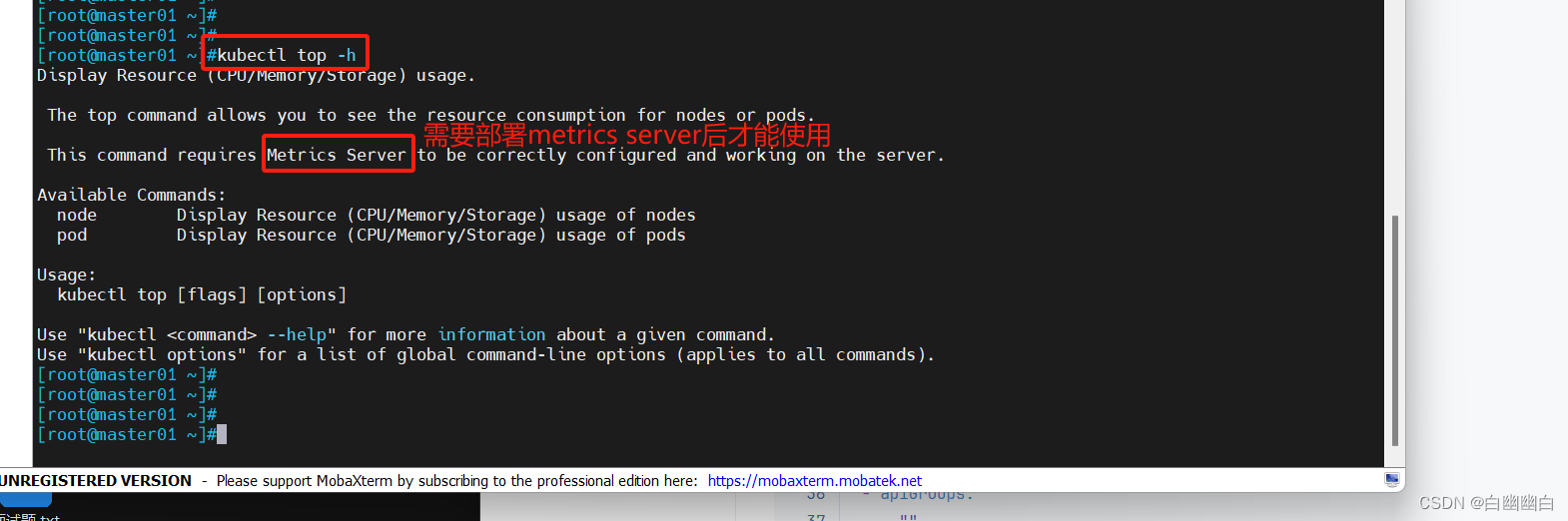
kubectl top node|pod
kubectl get hpa -n 命名空间
二、 HPA的部署与测试
2.1 部署metrics-server
Step1 编写metrics-server的配置清单文件
#工作目录
mkdri /opt/hpa
vim /opt/hpa/components.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
labels:
k8s-app: metrics-server
name: metrics-server
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
k8s-app: metrics-server
rbac.authorization.k8s.io/aggregate-to-admin: "true"
rbac.authorization.k8s.io/aggregate-to-edit: "true"
rbac.authorization.k8s.io/aggregate-to-view: "true"
name: system:aggregated-metrics-reader
rules:
- apiGroups:
- metrics.k8s.io
resources:
- pods
- nodes
verbs:
- get
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
k8s-app: metrics-server
name: system:metrics-server
rules:
- apiGroups:
- ""
resources:
- pods
- nodes
- nodes/stats
- namespaces
- configmaps
verbs:
- get
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
labels:
k8s-app: metrics-server
name: metrics-server-auth-reader
namespace: kube-system
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: extension-apiserver-authentication-reader
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
labels:
k8s-app: metrics-server
name: metrics-server:system:auth-delegator
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:auth-delegator
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
labels:
k8s-app: metrics-server
name: system:metrics-server
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:metrics-server
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
---
apiVersion: v1
kind: Service
metadata:
labels:
k8s-app: metrics-server
name: metrics-server
namespace: kube-system
spec:
ports:
- name: https
port: 443
protocol: TCP
targetPort: https
selector:
k8s-app: metrics-server
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
k8s-app: metrics-server
name: metrics-server
namespace: kube-system
spec:
selector:
matchLabels:
k8s-app: metrics-server
strategy:
rollingUpdate:
maxUnavailable: 0
template:
metadata:
labels:
k8s-app: metrics-server
spec:
containers:
- args:
- --cert-dir=/tmp
- --secure-port=4443
- --kubelet-preferred-address-types=InternalIP
- --kubelet-use-node-status-port
- --kubelet-insecure-tls
image: registry.cn-beijing.aliyuncs.com/dotbalo/metrics-server:v0.4.1
imagePullPolicy: IfNotPresent
livenessProbe:
failureThreshold: 3
httpGet:
path: /livez
port: https
scheme: HTTPS
periodSeconds: 10
name: metrics-server
ports:
- containerPort: 4443
name: https
protocol: TCP
readinessProbe:
failureThreshold: 3
httpGet:
path: /readyz
port: https
scheme: HTTPS
periodSeconds: 10
securityContext:
readOnlyRootFilesystem: true
runAsNonRoot: true
runAsUser: 1000
volumeMounts:
- mountPath: /tmp
name: tmp-dir
nodeSelector:
kubernetes.io/os: linux
priorityClassName: system-cluster-critical
serviceAccountName: metrics-server
volumes:
- emptyDir: {
}
name: tmp-dir
---
apiVersion: apiregistration.k8s.io/v1
kind: APIService
metadata:
labels:
k8s-app: metrics-server
name: v1beta1.metrics.k8s.io
spec:
group: metrics.k8s.io
groupPriorityMinimum: 100
insecureSkipTLSVerify: true
service:
name: metrics-server
namespace: kube-system
version: v1beta1
versionPriority: 100
Step2 部署
kubectl apply -f components.yaml
kubectl get pods -n kube-system | grep metrics-server
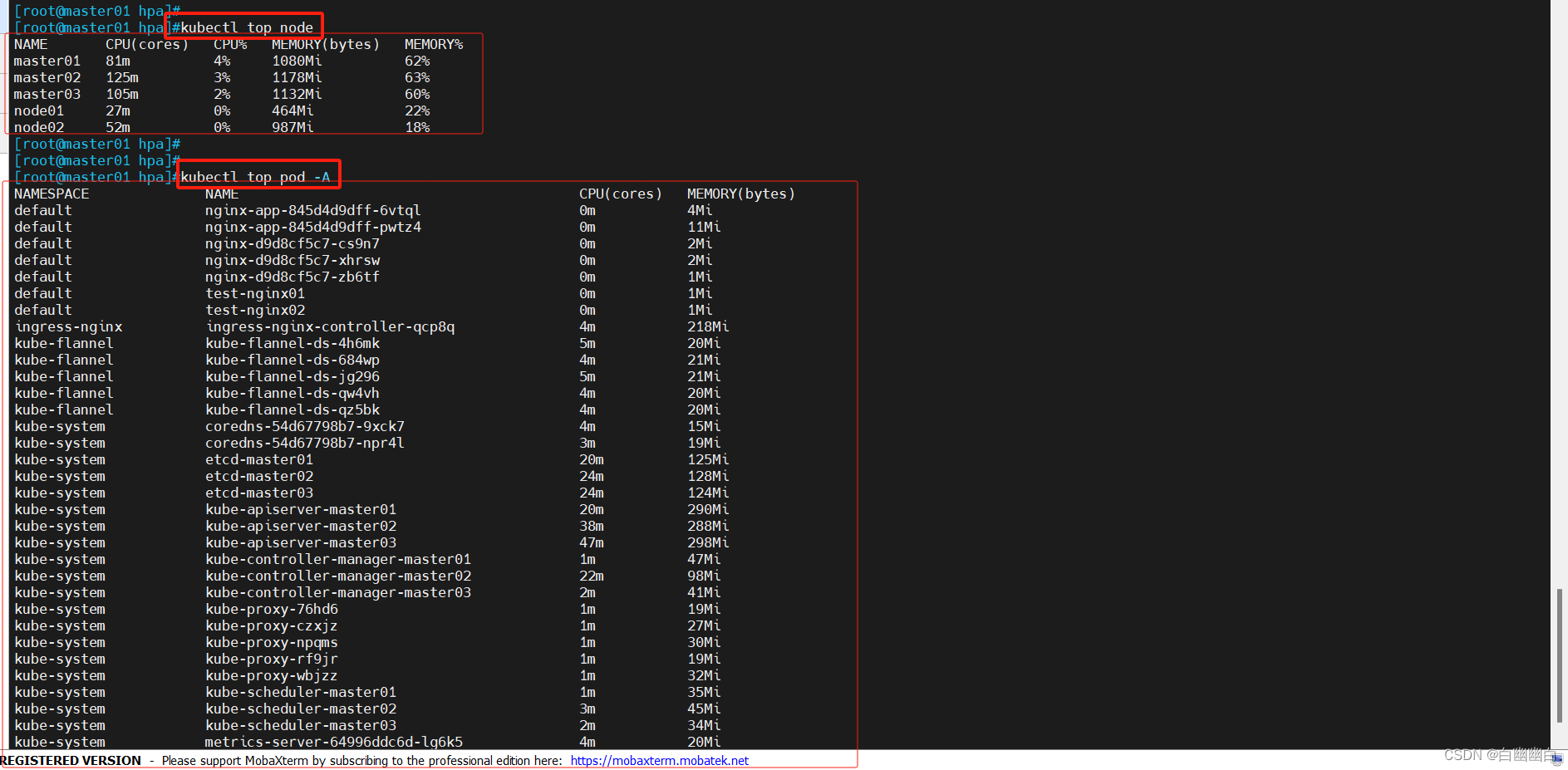
Step3 测试kubectl top命令
kubectl top node
kubectl top pods -A
hpa-example.tar 是谷歌基于 PHP 语言开发的,用于测试 HPA 的镜像,其中包含了一些可以运行 CPU 密集计算任务的代码。
2.2 部署HPA
Step1 部署测试应用
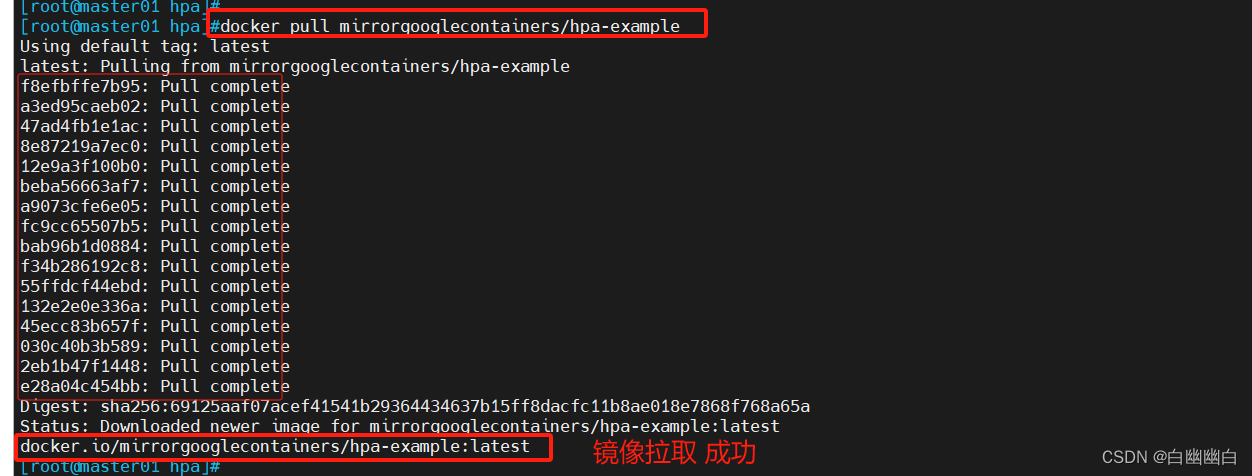
先拉取镜像
docker pull mirrorgooglecontainers/hpa-example
再编写资源配置清单文件
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
run: php-apache
name: php-apache
spec:
replicas: 1
selector:
matchLabels:
run: php-apache
template:
metadata:
labels:
run: php-apache
spec:
containers:
- image: mirrorgooglecontainers/hpa-example
name: php-apache
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
resources:
requests:
cpu: 200m
---
apiVersion: v1
kind: Service
metadata:
name: php-apache
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
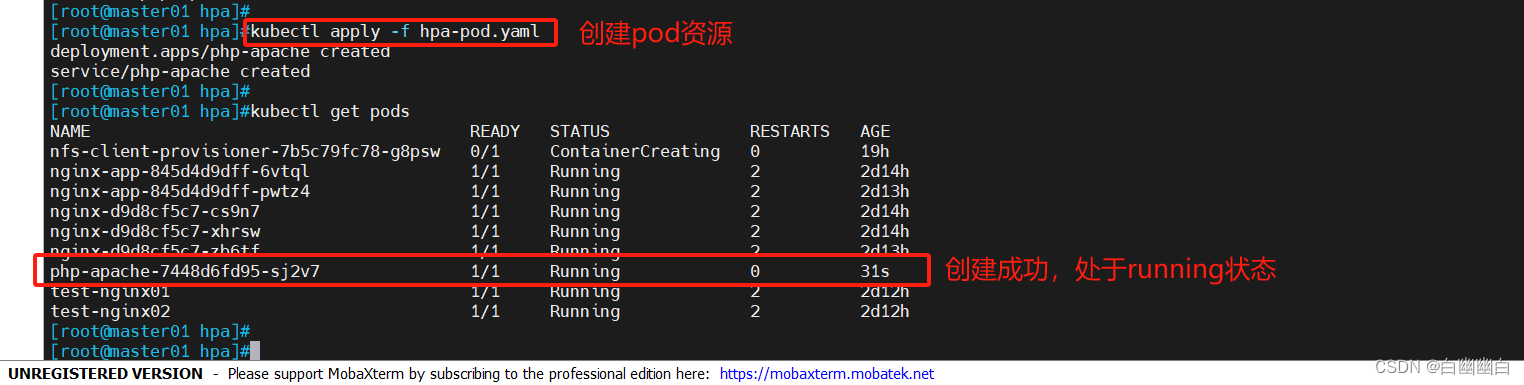
声明式创建
kubectl apply -f hpa-pod.yaml
kubectl get pods
Step2 创建HPA控制器
使用 kubectl autoscale 命令,设置 cpu 负载阈值为请求资源的 50%,指定最少负载节点数量为 1 个,最大负载节点数量为 10 个。
#创建HPA
kubectl autoscale deployment php-apache --cpu-percent=50 --min=1 --max=10
kubectl get hpa

可以看到,replicas 变动范围是最小 1,最大 10;目标 CPU 利用率(utilization)为 50%
kubectl top pods
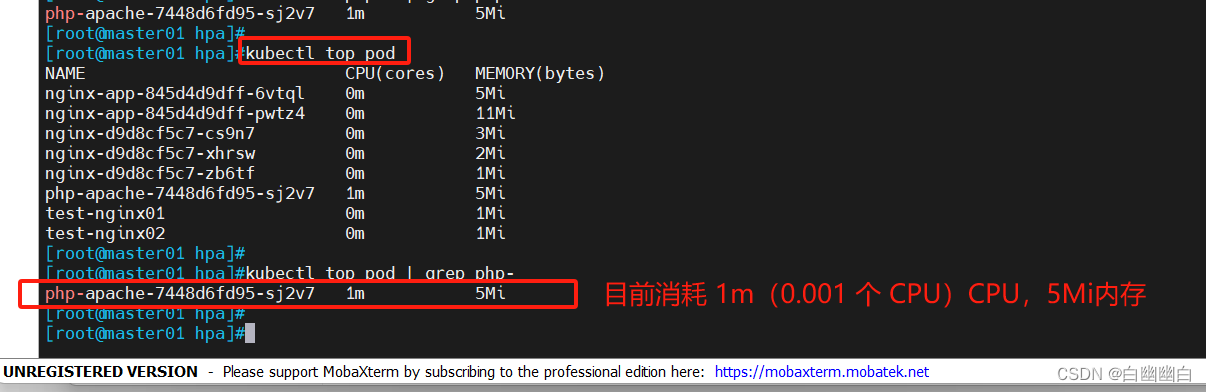
2.3 测试HPA
HPA可以根据应用程序的负载情况自动调整的副本数量。
2.3.1 HPA自动扩容测试
当应用程序的负载增加时,HPA会根据预先设置的规则自动扩展Pod的副本数量,以应对高流量或负载的增加。
kubectl run -i --tty load-generator --rm --image=busybox --restart=Never -- /bin/sh -c "while sleep 0.01; do wget -q -O- http://php-apache; done"
利用 busybox 镜像临时生成一个 pod,用 while 循环不停的访问 php-apache 的 service。
而 php-apache 中的 http://k8s.gcr.io/hpa-example 镜像已经配置了进行消耗 CPU 的计算网页,所以 php-apache pod 的 CPU 负载会很快增长。
#打开一个新的窗口,查看负载节点数目
kubectl get hpa -w


2.3.2 HPA自动回收测试
降低CPU负载,观察HPA的回收。
当应用程序的负载减少时,HPA会自动缩减Pod的副本数量。
在刚才运行增加负载的窗口运行<Ctrl> + C,终止命令

kubectl get hpa -w

思考:回收的时候,负载节点数量下降速度比较慢的原因?
防止因回收策略比较积极,而导致的K8s集群认为访问流量变小而快速收缩负载节点数量,从而会引发仅剩的负载节点又承受不了高负载的压力导致崩溃,最终影响业务的风险。
归根结底,还是为了保证业务的稳定性和正常运行。
三、Rancher管理工具
3.1 使用背景
管理单个K8S集群:kubectl(K8S命令行管理工具) 、dashboard(K8S官方出品的UI界面图形化管理工具) 。
同时管理多个K8S集群的工具:rancher、 kubesphere 、k9s。
3.2 Rancher简介
官网: https://docs.rancher.cn/
Rancher 是一个开源的企业级多集群 Kubernetes 管理平台,实现了 Kubernetes 集群在混合云+本地数据中心的集中部署与管理, 以确保集群的安全性,加速企业数字化转型。
3.3 Rancher 的安装及配置
| Server | Hostname | IP |
|---|---|---|
| 控制节点 | master01 | 192.168.2.100 |
| 工作节点 | node01 | 192.168.2.102 |
| 工作节点 | node02 | 192.168.2.103 |
| Rancher节点 | rancher | 192.168.2.107 |
Step1 安装Rancher
安装docker
yum install -y yum-utils device-mapper-persistent-data lvm2
#设置阿里云镜像源
yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
yum install -y docker-ce docker-ce-cli containerd.io
systemctl enable docker.service --now
详解见我的博客:【Docker从入门到入土 1】Docker架构、镜像操作和容器操作-CSDN博客
在所有 node 节点下载 rancher-agent 镜像
#所有 node 节点
docker pull rancher/rancher-agent:v2.5.7
在 rancher 节点下载 rancher 镜像
docker pull rancher/rancher:v2.5.7
启动Rancher平台
在本地机器上使用Rancher进行容器编排和管理。
docker run -d --restart=unless-stopped -p 80:80 -p 443:443 --privileged --name rancher rancher/rancher:v2.5.7
#--restart=unless-stopped 表示在容器退出时总是重启容器,但是不考虑在Docker守护进程启动时就已经停止了的容器
docker ps -a|grep rancher

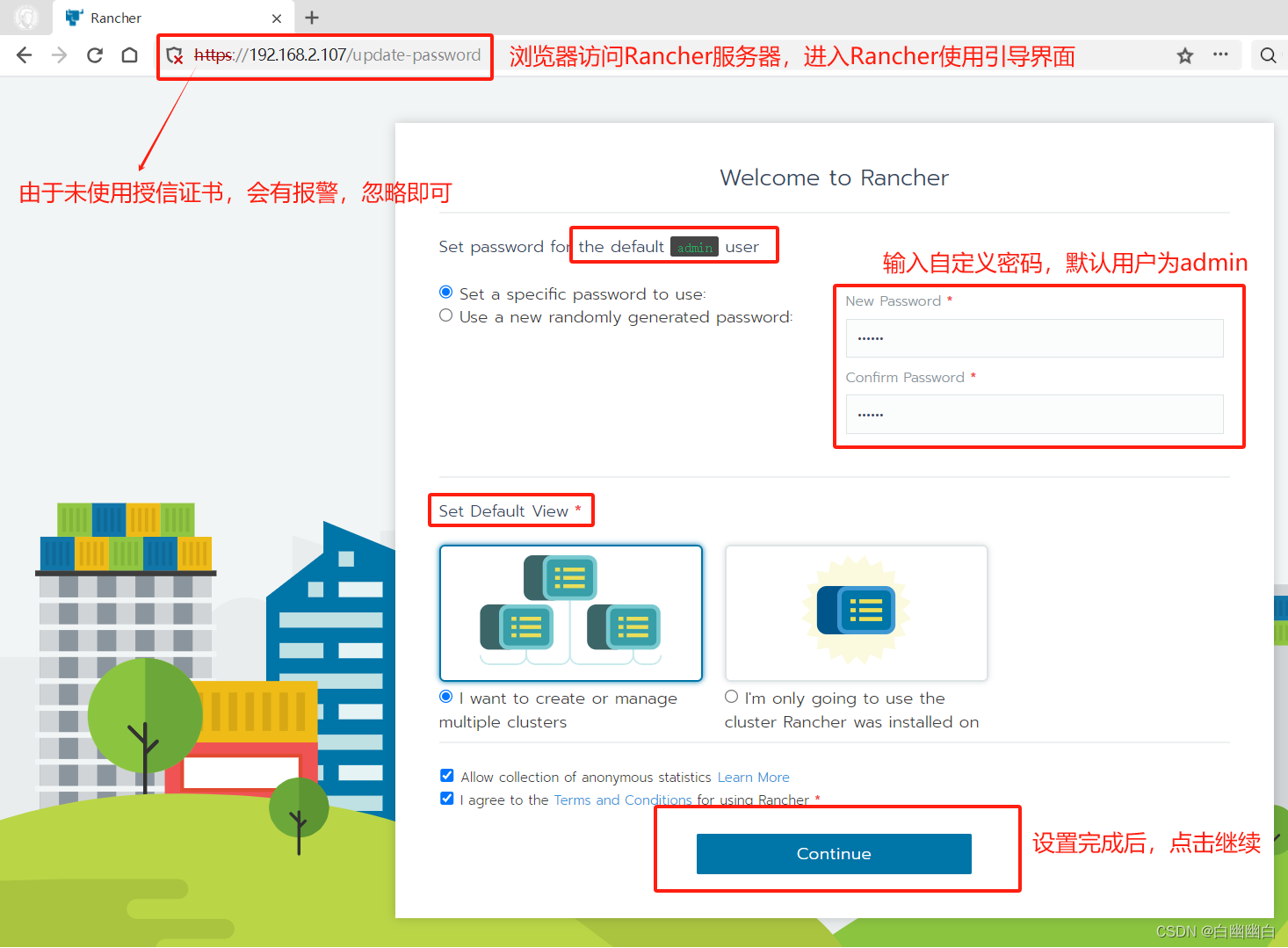
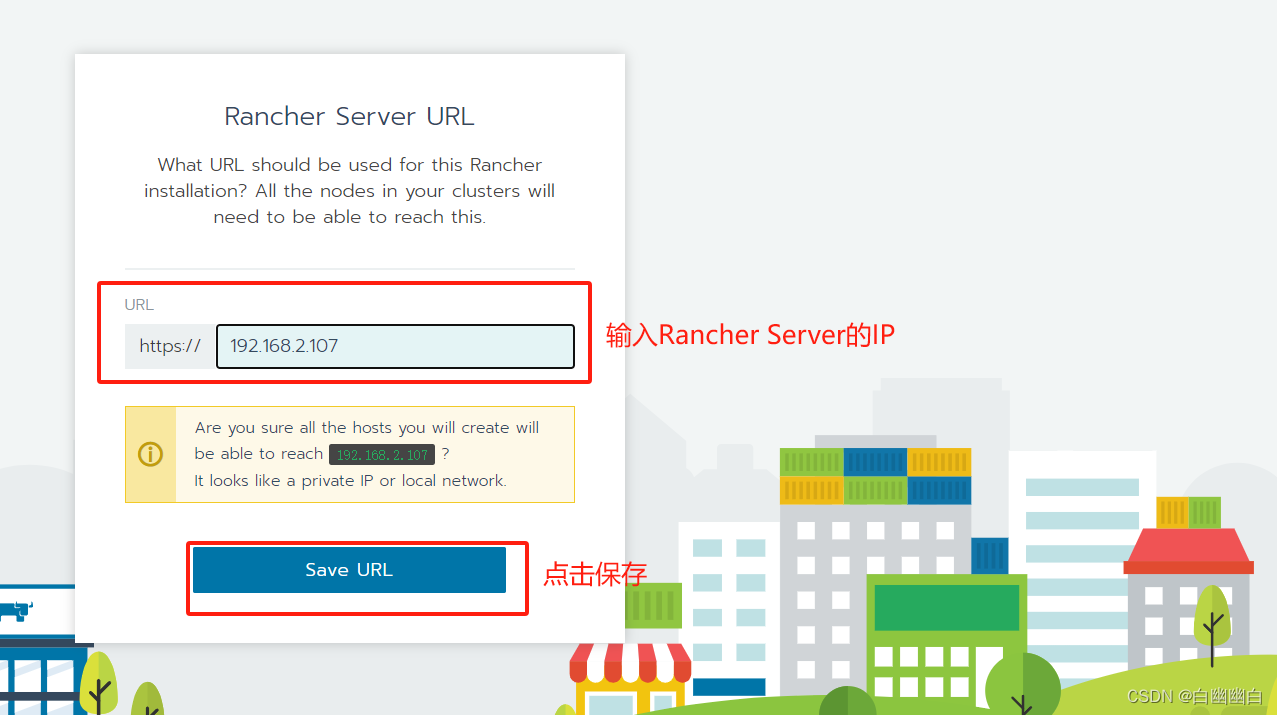
Step2 登录 Rancher 平台
需要先等一会儿,
浏览器访问 http://192.168.2.107
Step3 使用Rancher 管理已有的 k8s 集群
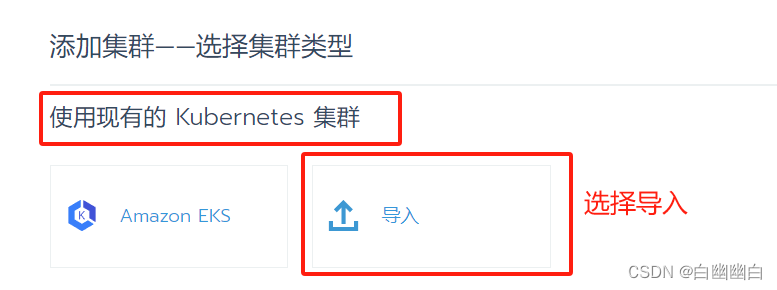
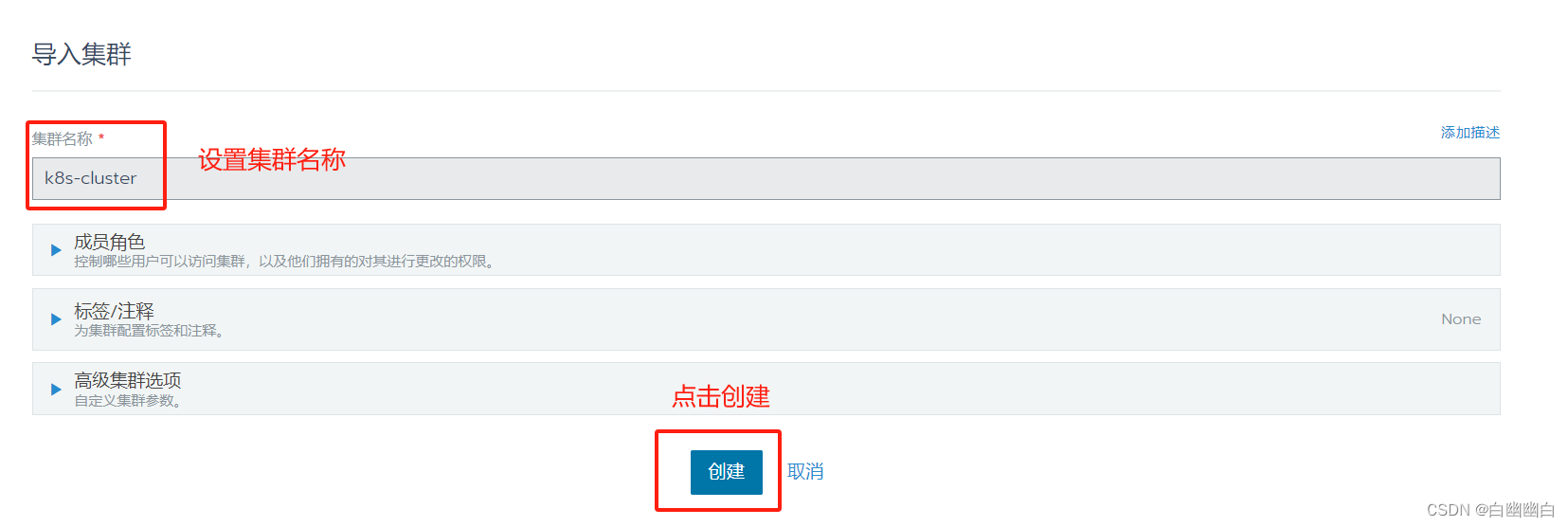
选择【添加集群】--->点击【导入】--->【集群名称】设置为 k8s-cluster--->点击【创建】
#选择复制第三条命令绕过证书检查导入 k8s 集群
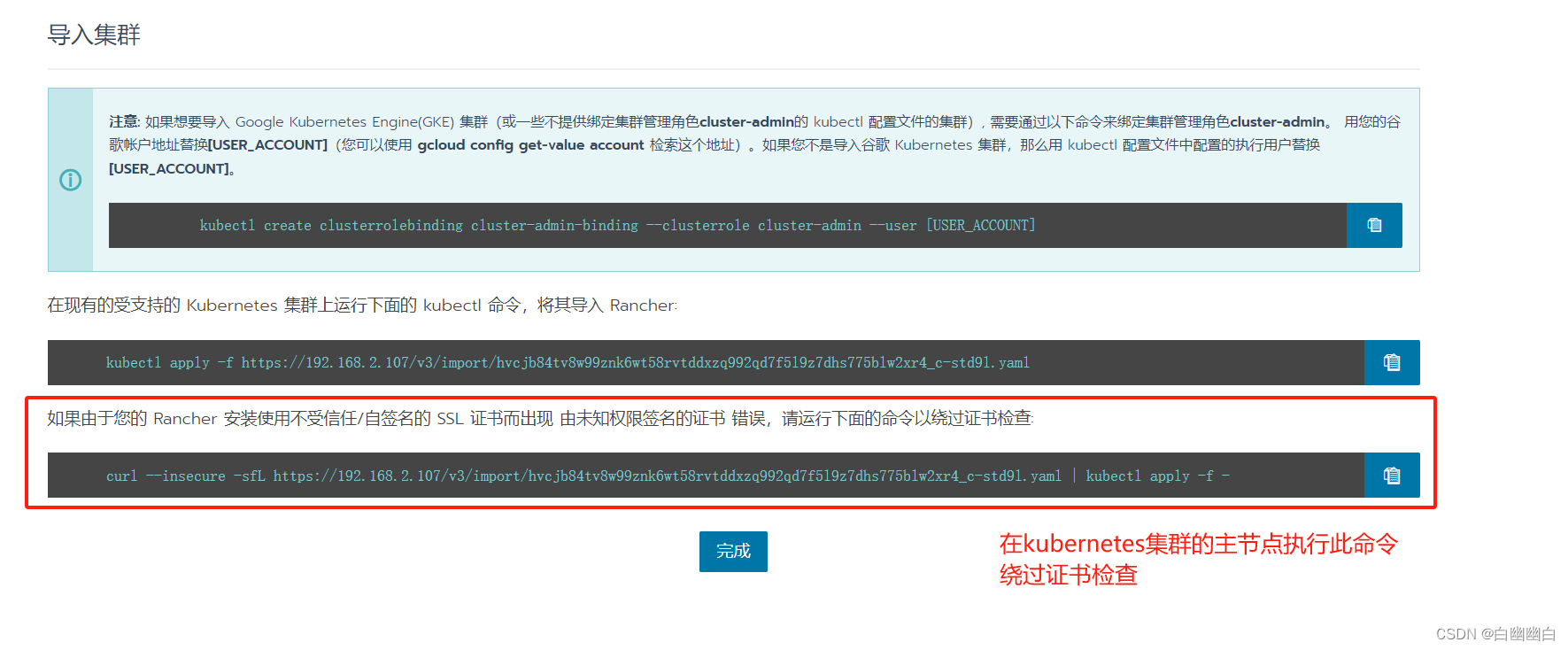
#在 k8s 控制节点 master01 上执行刚才复制的命令,如第一次执行报错,再执行一次即可
curl --insecure -sfL https://192.168.2.107/v3/import/hvcjb84tv8w99znk6wt58rvtddxzq992qd7f5l9z7dhs775blw2xr4_c-std9l.yaml | kubectl apply -f -

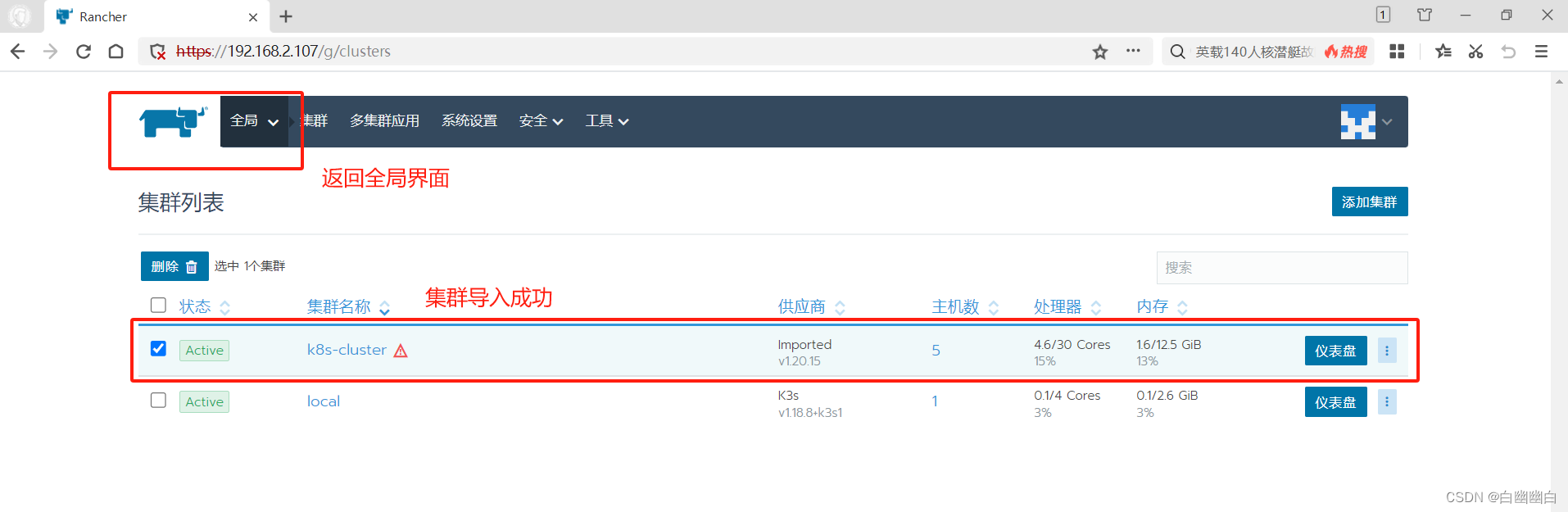
kubectl get ns
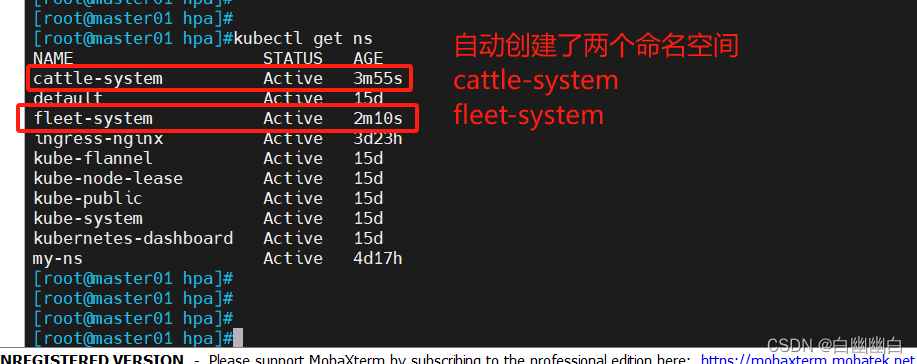
cattle-system是Rancher系统中的一个命名空间(Namespace),用于存储Rancher本身的管理组件和相关资源配置。
fleet-system是Rancher中的一个命名空间(Namespace),用于存储Fleet项目的相关资源配置,是由Rancher和Fleet系统自动生成的。
kubectl get pods -n cattle-system -o wide
kubectl get pods -n fleet-system -o wide

Step4 Rancher 部署监控系统
点击【启用监控以查看实时监控】—>【监控组件版本】选择 0.2.1,其他的默认即可—>点击【启用监控】。
启动监控时间可能比较长,需要等待10分钟左右

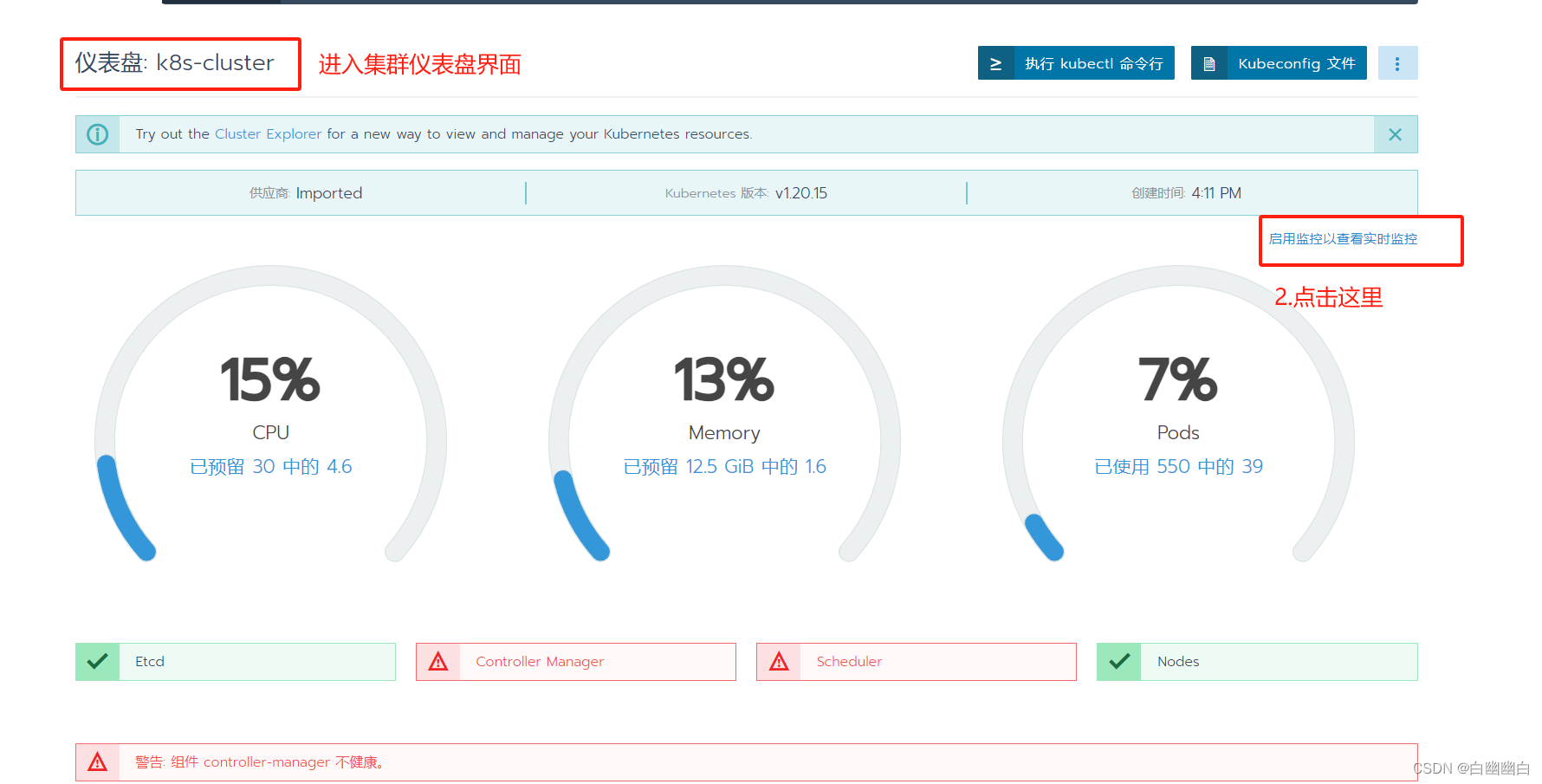
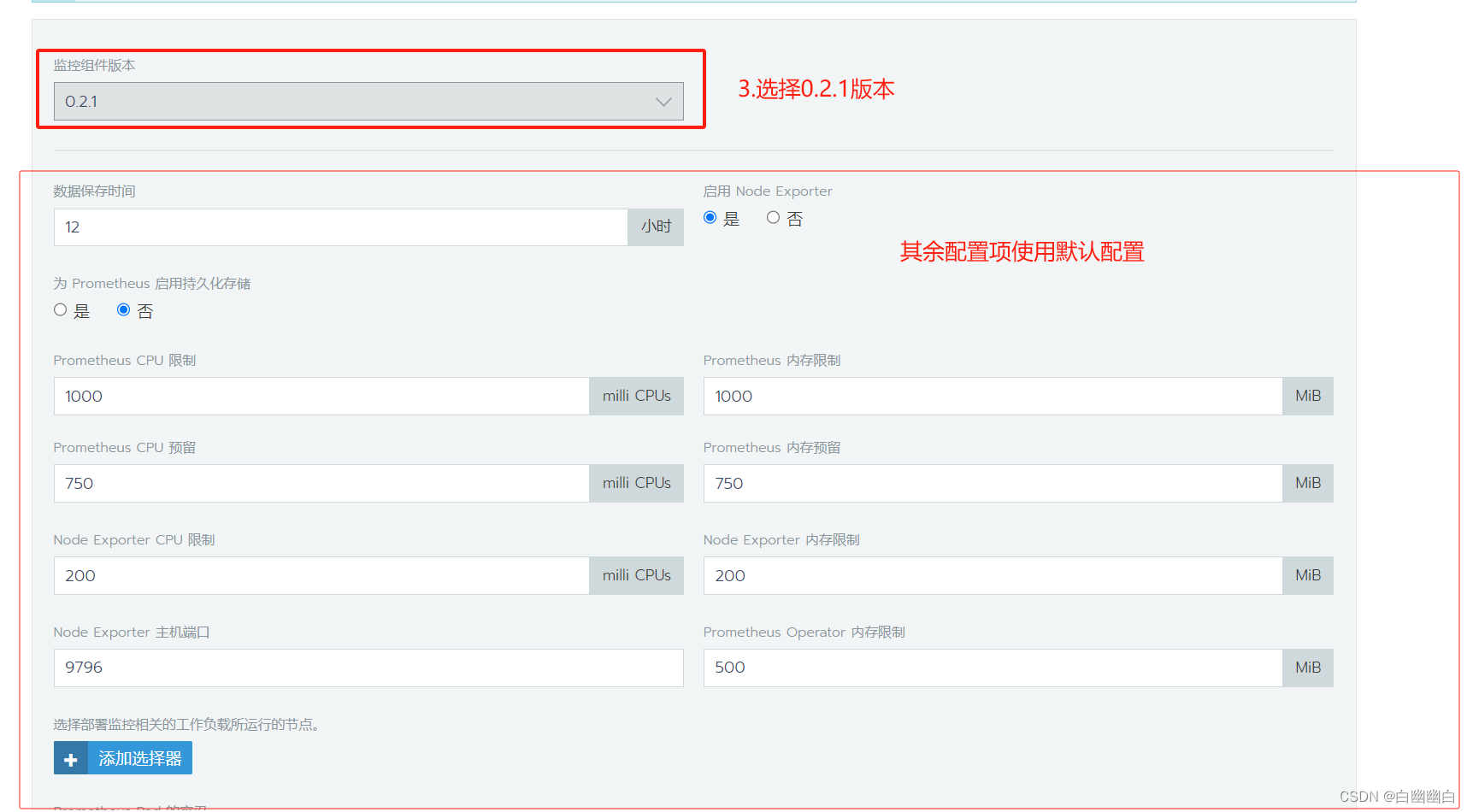
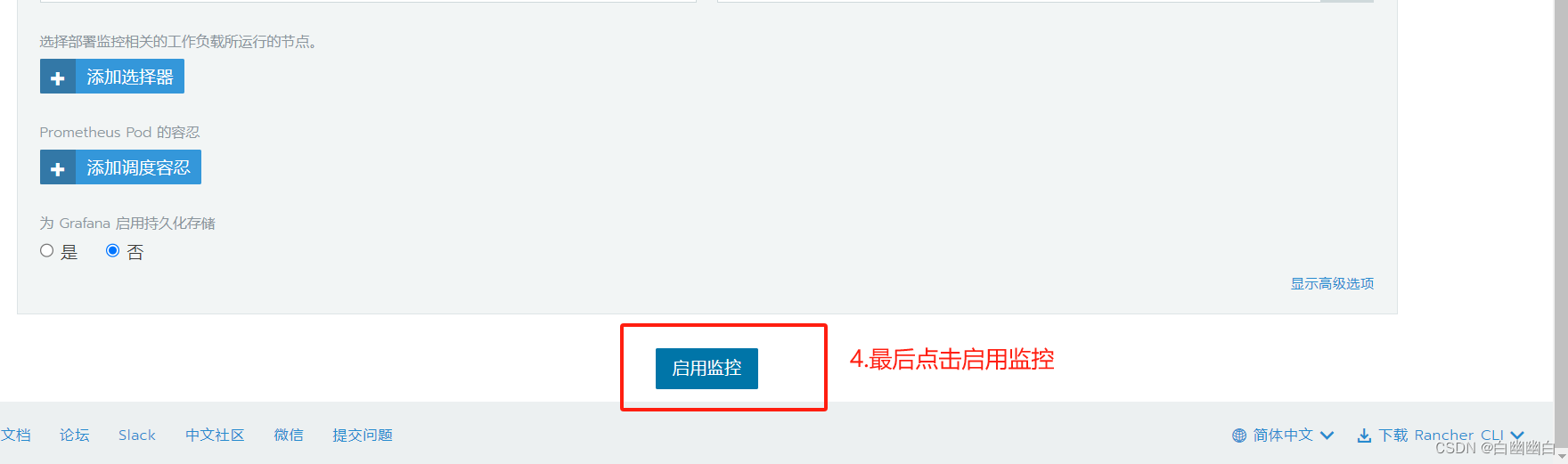

Step5 使用 Rancher 仪表盘管理 k8s 集群
以创建 nginx 服务为例。
进入集群仪表盘界面
创建命名空间 namespace
点击左侧菜单【Namespaces】--->点击右侧【Create】
【Name】输入 dev,【Description】选填可自定义
点击右下角【Create】

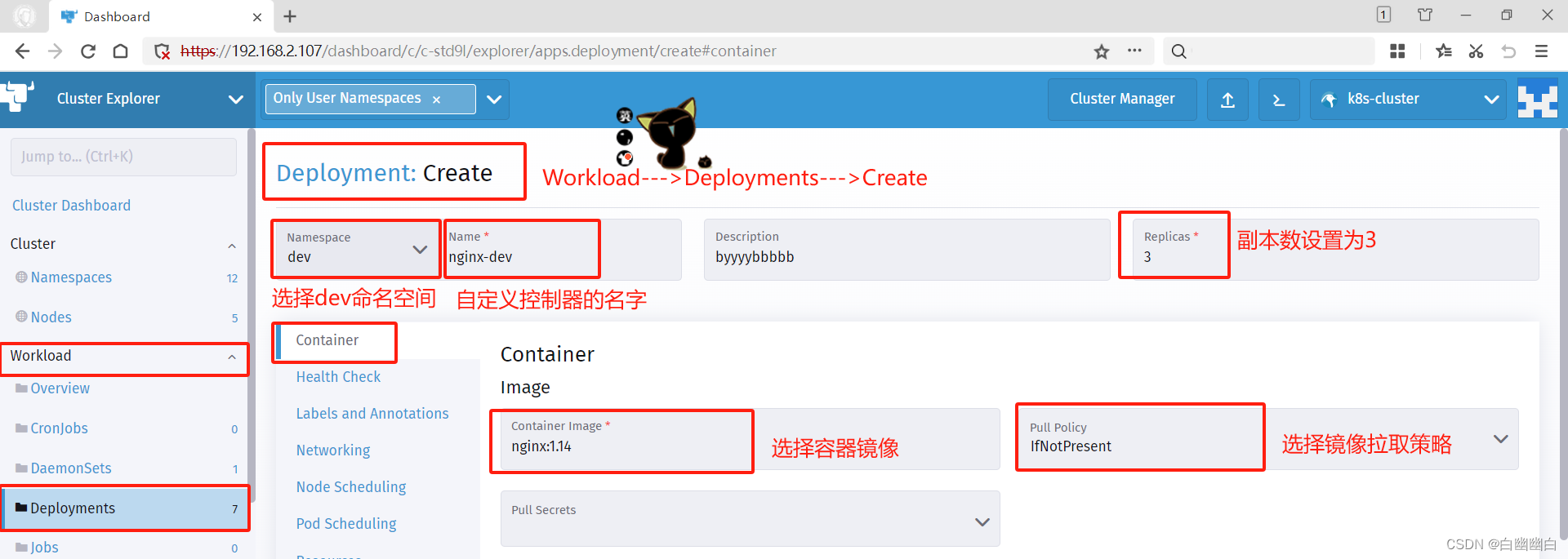
创建 Deployment 资源
点击左侧菜单【Deployments】--->点击右侧【Create】
【Namespace】下拉选择 dev,【Name】输入 nginx-dev,【Replicas】输入 3
点击中间选项【Container】
【Container Image】输入 nginx:1.14,【Pull Policy】选择 IfNotPresent
在【Pod Labels】下点击【Add Lable】,【Key】输入 app,【Value】输入 nginx
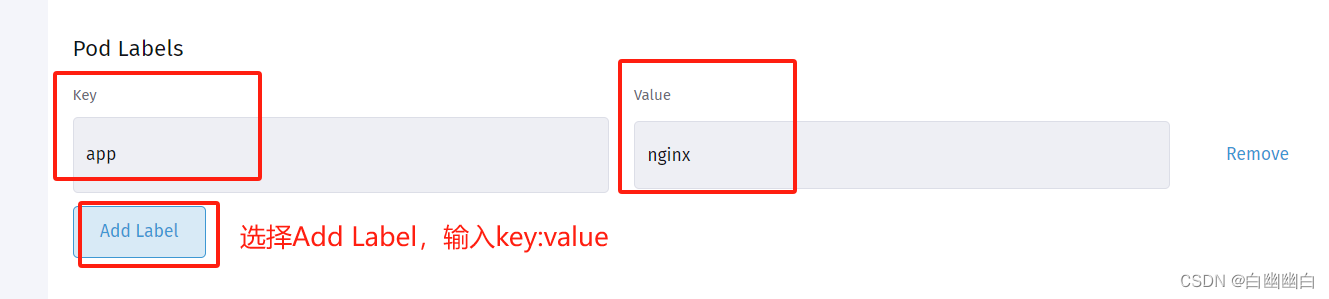
点击中间选项【Labels and Annotations】--->点击【Add Label】
【Key】输入 app,【Value】输入 nginx
点击右下角【Create】


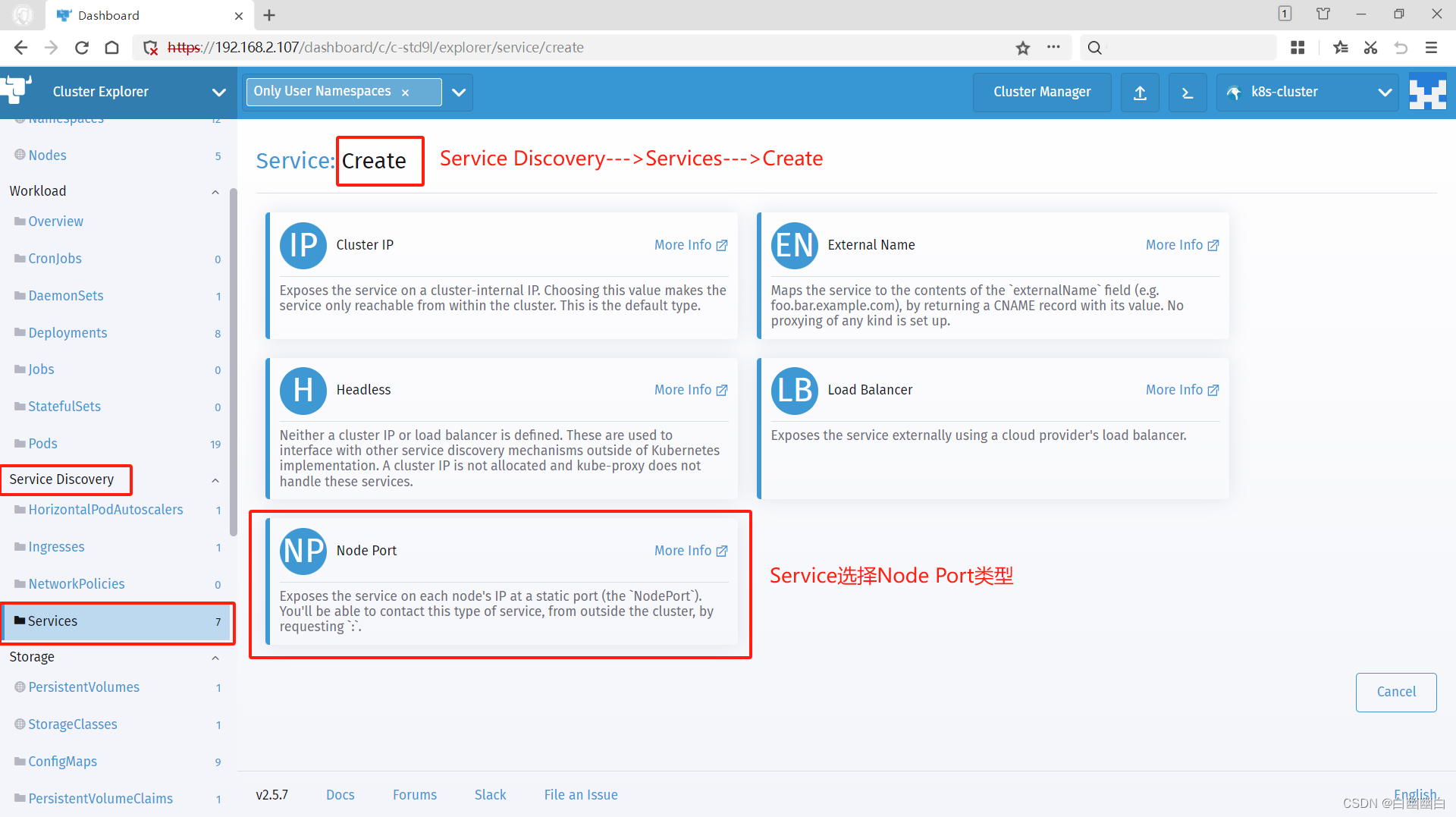
创建 service
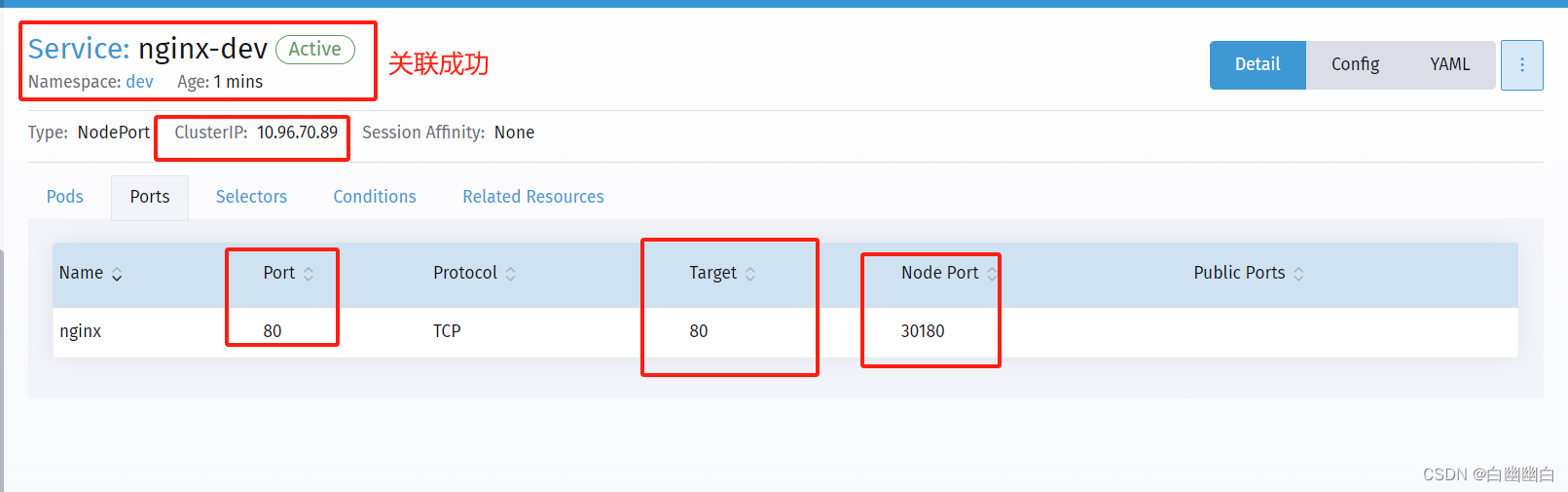
点击左侧菜单【Services】---> 点击右侧【Create】---> 点击【Node Port】
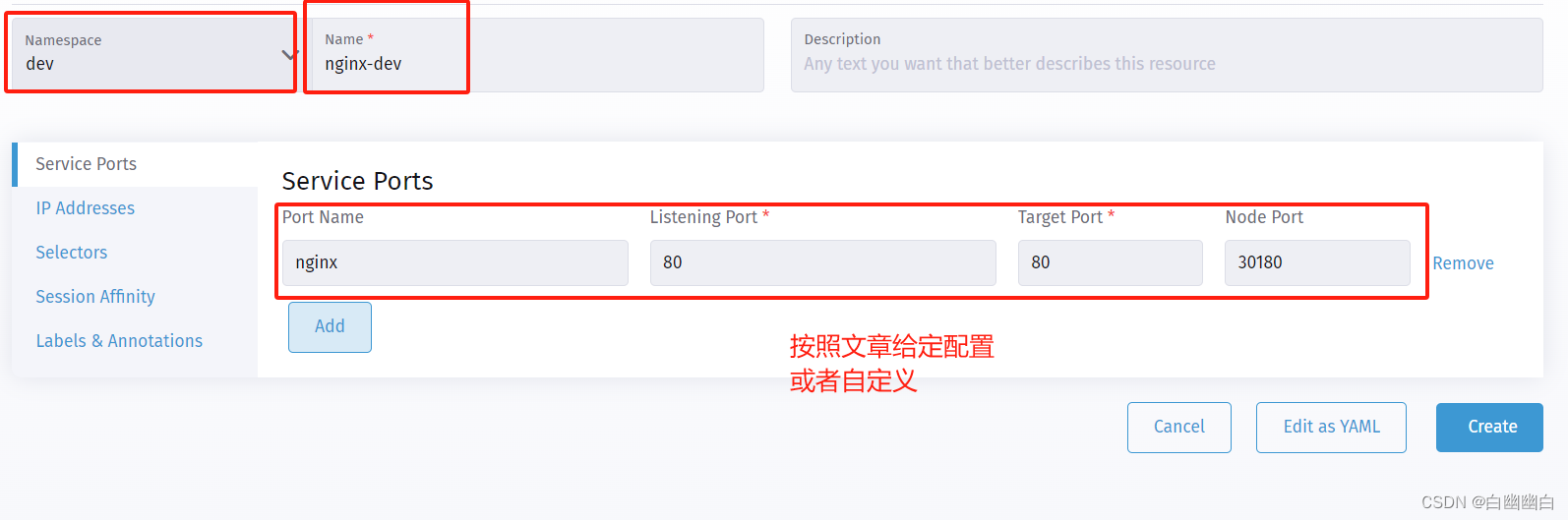
【Namespace】下拉选择 dev
【Name】输入 nginx-dev
【Port Name】输入 nginx
【Listening Port】输入 80
【Target Port】输入 80
【Node Port】输入 30180
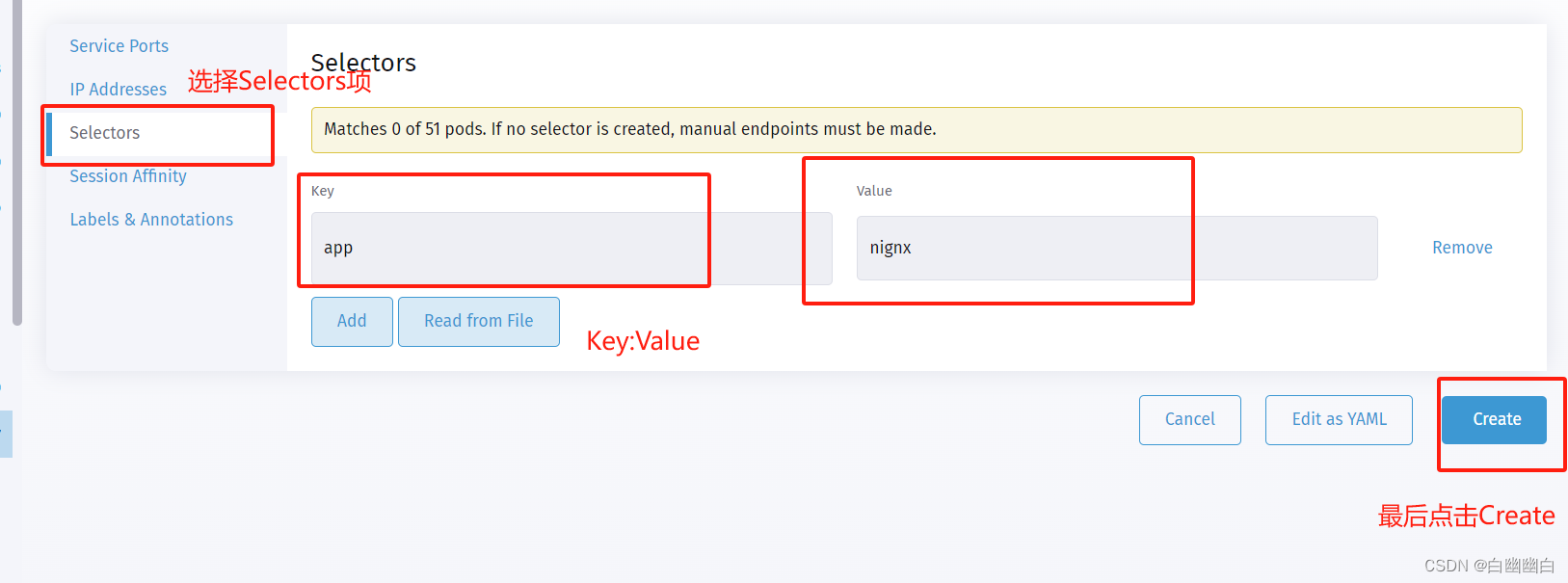
点击中间选项【Selectors】
【Key】输入 app
【Value】输入 nginx
点击右下角【Create】
点击【nginx-dev】查看 service 是否已关联上 Pod
#点击 service 资源的节点端口 30180/TCP,可以访问内部的 nginx 页面了