目录
一、文件流实验
使用SparkStreaming 监听文件系统(即目录),在设定的时间间隔内有文件变化,则会读取数据进行处理。
步骤:
1.监听HDFS文件系统并进行词频统计
1.1 命令行监听 HDFS 文件系统
(1)输入 pyspark 打开 Spark Shell 窗口。逐行输入代码。

(2)打开linux命令行黑窗口,使用hadoop命令:hdfs dfs -put 文件名的方式上传文本文件至代码对应的目录的位置。

(3)上传后可查看 sparkshell 的窗口中的输出日志。

1.2 编写独立应用程序,监听HDFS 文件系统并进行词频统计
(1)新建一个testhdfs.py文件。输入如下代码:

(2)执行命令spark-submit hdfstest.py

注:warn表示上一次打开spark时占用端口未关闭,退出后用jps
查看占用端口号并用kill命令关闭。
(3)上传文本内容到指定目录。

(4)查看日志文件

2、监听本地 Linux 文件系统并进行词频统计
2.1监听本地Linux文件系统
(1)输入 pyspark 打开 Spark Shell 窗口,逐行输入代码。
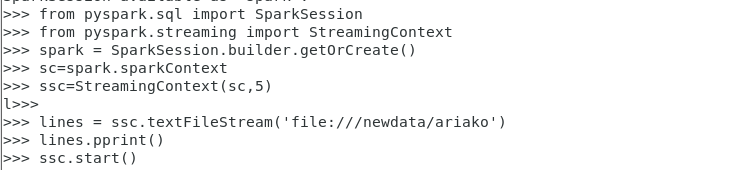
(2)创建文本文件,将文本文件移动到代码中对应的文件夹位置。

(3)移动后查看 sparkshell 的窗口中的输出日志:

(4)Ctr+c 或 Ctr+z 或关闭窗口,结束程序运行。

2.2监听本地的linux文件系统并进行词频统计
(1)新建一个filetest.py文件。输入如下代码:

(2)执行命令spark-submit filetest.py

(3)在对应目录下创建文本文件,修改文本内容。

(4)查看日志文件

二、套接字流实验
实现对套接字的监听和词频统计。
(1)创建Socket文件夹,在该文件夹下创建Sockettest.py文件。输入如下代码:
from __future__ import print_function
import sys
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
if __name__ == "__main__":
if len(sys.argv) != 3:
print("Usage: Sockettest.py <hostname> <port>", file=sys.stderr)#文件名Sockettest.py
exit(-1)
conf = SparkConf()
conf.setAppName('PythonStreamingNetworkWordCount')
conf.setMaster('local[2]')
sc = SparkContext(conf = conf)#conf开始的四行与参考不同
ssc = StreamingContext(sc, 1)
lines = ssc.socketTextStream(sys.argv[1], int(sys.argv[2]))
counts = lines.flatMap(lambda line: line.split(" "))\
.map(lambda word: (word, 1))\
.reduceByKey(lambda a, b: a+b)
counts.pprint()
ssc.start()
ssc.awaitTermination()
(2)执行如下代码:
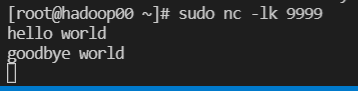
sudo nc -lk 9999
(3)打开第二个终端作为监听窗口(即该客户端会立刻收到第一个客户端nc窗口输入的内容数据),执行如下代码:
spark-submit Sockettest.py localhost 9999
(4)在第一个终端窗口nc窗口中输入一些单词:
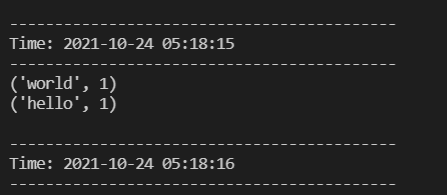
(5)监听窗口会自动获得单词数据流信息,在监听窗口每隔1秒就会打印出词频统计信息。查看监听窗口:
三、参考
Spark入门:Spark Streaming简介(Python版)
Spark入门:DStream操作概述(Python版)
Spark2.1.0+入门:套接字流(DStream)(Python版)
Spark2.1.0+入门:文件流(DStream)(Python版)