
Halo,这里是Ppeua。平时主要更新C语言,C++,数据结构算法…感兴趣就关注我吧!你定不会失望。

0. 数据在内存中的分布
我们熟知的栈区堆区等在内存中的分布是怎样的呢?
地址空间中有着这几样区域:
- 代码区
- 字符常量区
- 已初始化全局变量
- 未初始化全局变量
- 堆区
- 栈区
- 命令行参数
- 内核空间
他们在内存中的分布是由上到下,满足下面这个模型.
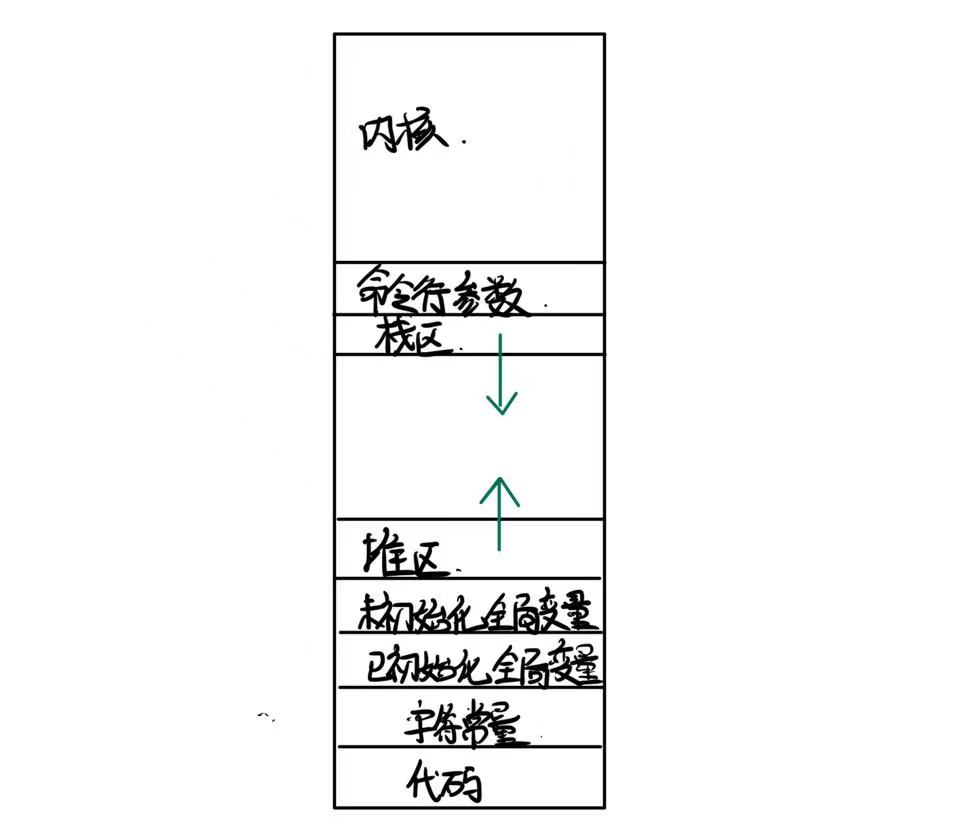
代码区在低地址空间.地址从下往上增长. 堆区向上申请地址,栈区向下申请地址
我们可以来验证一下这个布局正确与否
#include<stdlib.h>
#include<stdio.h>
#include<unistd.h>
int gval=100;
int initgval=100;
int uninitgval;
int main()
{
printf("code address :%p\n",main);
const char* str="hhhhh";
printf("str address : %p\n",str);
int a=0;
int b=0;
int c=0;
static int sta=0;
printf("initgval:%p\n",&initgval);
printf("uninitgval:%p\n",&uninitgval);
printf("static:%p\n",&sta);
printf("stack address:%p\n",&a);
printf("stack address:%p\n",&b);
printf("stack address:%p\n",&c);
int* heapadd1=(int*)malloc(100);
int* heapadd2=(int*)malloc(100);
printf("stack address:%p\n",&heapadd1);
printf("stack address:%p\n",&heapadd2);
printf("heap address:%p\n",heapadd1);
printf("heap address:%p\n",heapadd2);
return 0;
}
我们使用main函数地址来表示代码区,const char* str代表字符常量区.最后发现

大部分和我们之前所说一致.
我们可以发现static修饰的变量为什么能在函数结束时被保存下来呢?因为其存放在了全局变量去,
但栈似乎并不是往下增长的.这是由于操作系统的操作导致的,不同的操作系统可能测试出来的结果并不相同.但内存分布是相同的.
1. 虚拟地址与真实物理地址
我们使用fork函数创建一个子进程,在子进程中改变与父进程同名的变量.父进程中该变量会被改变嘛?
#include<stdlib.h>
#include<stdio.h>
#include<unistd.h>
int main()
{
int val=100;
pid_t id = fork();
if(id==0)
{
val=99;
printf("i am a childre process val is: %d address is %p\n",val,&val);
sleep(1);
}
else
printf("i am a father process val is: %d address is %p\n",val,&val);
return 0;
}
编译执行会出现下面的结果

我们可以发现 子进程将val变量值更改了,而父进程却不受影响.但他们两个指向的是同一个地址空间.
相同的地址空间怎会存储两个不一样的值呢? 他们使用的都是虚拟地址空间,而虚拟空间与真实地址空间中存在映射关系.
2. 进程地址空间
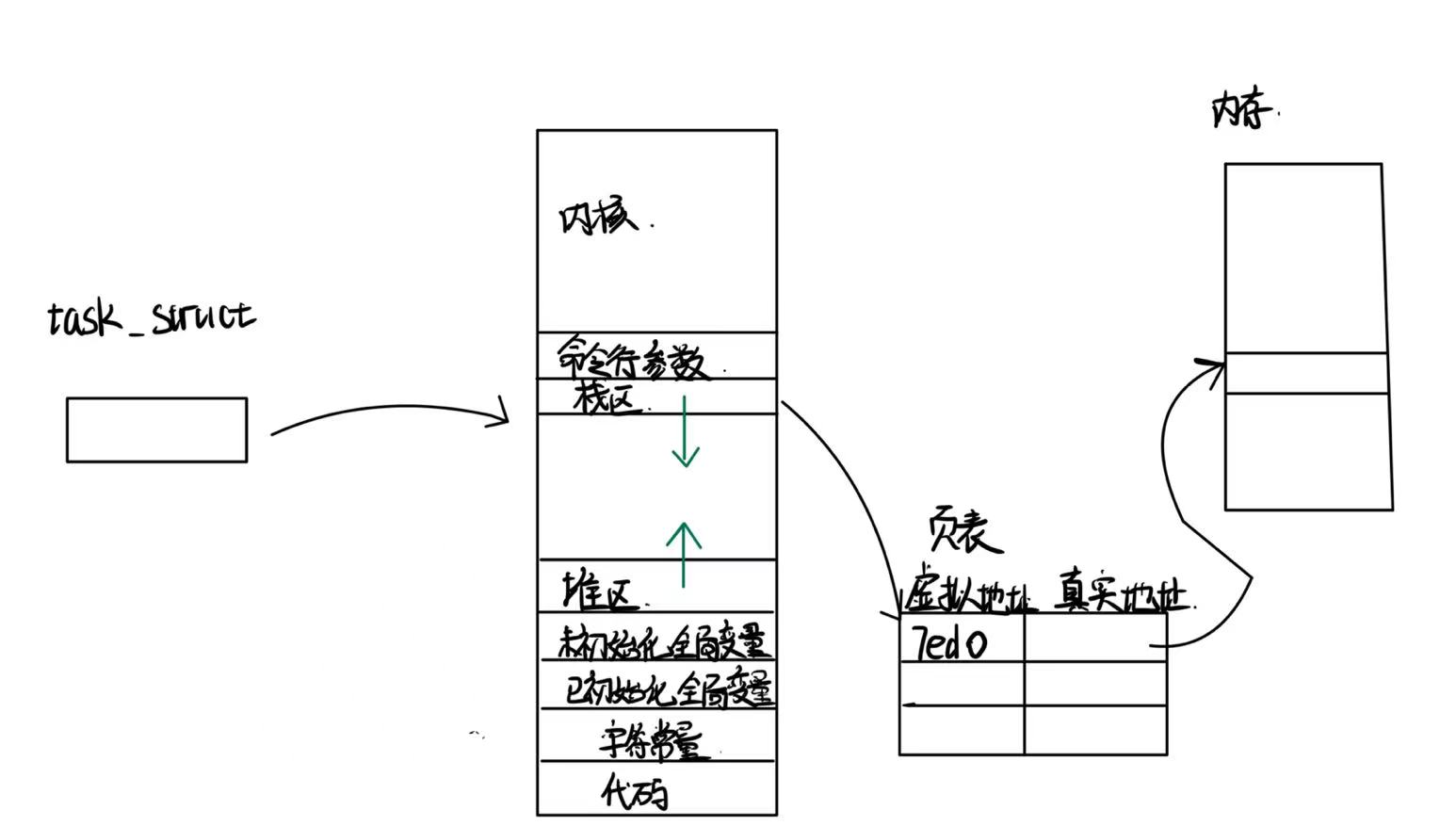
每个进程都会拥有一个这样的内存分布+页表.
上面的情况是:子进程复制了父进程的页表与内存分布.其中子进程的页表与父进程的页表虚拟地址真实地址都相同.当向一个共享的变量写入数据时,会发生写时拷贝.在内存中重新给子进程申请一片空间,在这里进行写入.但是虚拟地址不变,只是改变了虚拟地址与物理地址的映射关系.
重新开辟空间这一操作,对于左边的虚拟地址,或者说对于进程来说是不可知的.这满足了软件中的解耦合设计.左边的进程管理只需要管理好进程,不需要去操作内存.
2.1 进程地址空间概念
在PCB中也即在Task_Struct中会存在一段mem结构体指针.mem结构体中存了每个区域(代码、堆区…)的起始与终止位置
对线性空间进行区域划分.
我们来看看Linux内核2.6.1中关于这段的具体描述
struct mm_struct{

}
每一个段区域中每个最小单位都有自己的地址可以 供进程直接使用
这样做可以让进程以相同的方式看待内存,不必去管内存中哪里为空,当下需要将数据放到哪里.只需要管好自己的内存分布即可.
我们之前如果想要去修改一个常量区的字符,或者指针越界访问,操作系统会抛出警告.那么这是如何做到的呢?
通过页表.页表中有一个标志位,可以标志当前存入的数据的属性.当我们通过页表去访问内存时,操作系统会去检查本次操作是否合法.进而保护物理内存
每个进程是完全独立的,每个进程都认为自己拥有了所有的内存.进程需要使用内存时通过操作系统向内存模块进行申请.这样的设计让内存模块与进程模块实现了解耦合
**进程PCB中具有几个属性描述了当前内存分布以及页表所在的空间.当进程被放在CPU上时,会将这些信息提供给CPU.反之,从内存中拿下时,也会将这些信息带走.**所以每个进程间都是互相独立的.
2.2 进程->页表->内存
我们平常玩游戏,一个游戏的大小大多时候是远大于我们的内存的.显然不可能一次性将全部的内容加载到内存当中.那么我们怎么保证当前进程所访问的内容在使用时一定存在呢?
- 操作系统对大文件以一种惰性加载的方式实现分批加载
进程通常假设自己要使用的资源已经全部加入到内存当中.(解耦合暗示了是否加载到真实的物理地址中进程并不关心),之后为这些资源分配虚拟的地址空间.
当进程访问这些虚拟的地址空间时,操作系统会检查虚拟空间对应的物理内存是否存在?
若不存在则发生却缺页中断,该进程被挂起.此时CPU向内存管理模块去申请对应的资源.待准备完毕再反馈给进程
所以现代操作系统不做任何浪费空间和时间的事情
