文章目录
分布式锁
- 分布式锁:在分布式环境下,保护跨进程、跨主机、跨网络的共享资源,实现互斥访问,保证一致性;在zk中,锁就是一个数据节点
- 普通实现:注册临时节点,谁注册成功谁获取锁,其他监听该节点的删除事件,一旦被删除,通知其他客户端,再次重复该流程;此为最简单的实现,但容易引发羊群效应。这种情况下,大量客户端在短时间内对 ZooKeeper 服务器发起请求,可能超出了服务器的处理能力,导致延迟增加、响应时间变长,甚至导致服务不可用。
- “羊群效应”(Herd Effect)是指当大量客户端同时对某一事件或资源发起请求时,这些请求会出现在相对较短的时间内集中到服务器上,从而导致服务器过载或性能下降的现象。在ZooKeeper中,这种效应可能会导致严重的性能问题,甚至使整个系统崩溃。
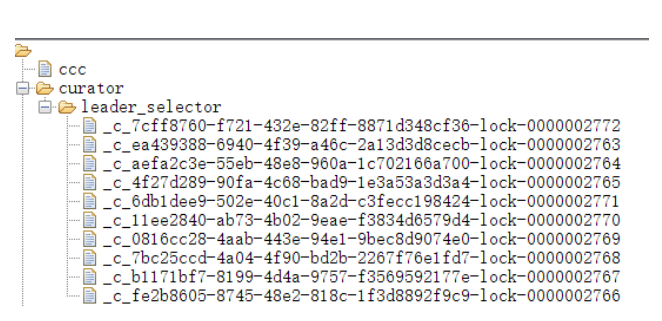
- 所有服务要获取锁时都去zookeeper中注册一个临时顺序节点,并将基本信息写入临时节点
- 所有服务获取节点列表并判断自己的节点是否是最小的那个,谁最小谁就获取了锁
- 未获取锁的客户端添加对前一个节点删除事件的监听
- 锁释放/持有锁的客户端宕机 后,节点被删除
- 下一个节点的客户端收到通知,重复上述流程
分布式锁-读写锁
- 共享锁:读锁。如果事务T1对数据对象O1加上共享锁,那么当前事务只能对O1进行读取操作,其他事务也只能对这个数据对象加共享锁,直到该数据对象上的所有共享锁都被释放
- 排它锁:写锁或独占锁。如果事务T1对数据对象O1加上了排他锁,那么在整个加锁期间,只允许事务T1对O1进行读取或更新操作,其他任务事务都不能对这个数据对象进行任何操作,直到T1释放排他锁
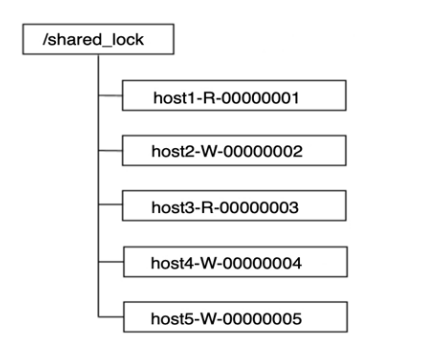
可以将临时有序节点分为读锁节点和写锁节点
- 对于读锁节点而言,只关心前一个写锁节点的释放。如果前一个写锁释放了,则多个读锁节点对应的线程可以并发地读取数据
- 对于写锁节点而言,只关心前一个节点的释放,而不需要关心前一个节点是写锁节点还是读锁节点。因为为了保证有序性,写操作必须要等待前面的读操作或者写操作执行完成。
分布式锁-Curator实现

➢InterProcessMutex:分布式可重入排它锁(可重入可以借助LocalMap存计数器)
➢InterProcessSemaphoreMutex:分布式排它锁
➢InterProcessMultiLock:将多个锁作为单个实体管理的容器
➢InterProcessReadWriteLock:分布式读写锁
ZK集群管理
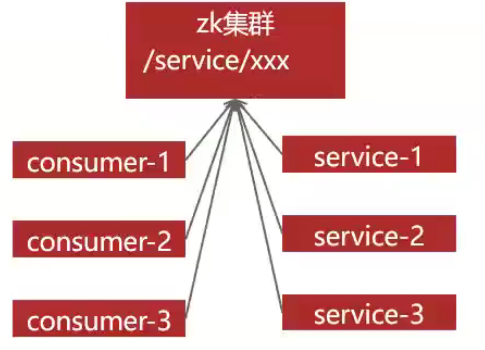
- 配置管理:指集群中的机器拥有某些配置,并且这些配置信息需要动态地改变,那么我们就可以使用发布订阅模式把配置做统一的管理,让这些机器订阅配置信息的改变,但是配置改变时这些机器得到通知并更新自己的配置。
- 服务注册,服务发现:指对集群中的服务上下线做统一管理,每个工作服务器都可以作为数据的发布方,向集群注册自己的基本信息,而让某些监控服务器作为订阅方,订阅工作服务器的基本信息。当工作服务器的基本信息改变时,如服务上下线、服务器的角色或服务范围变更,那么监控服务器可以得到通知并响应这些变化
zookeeper 集群
zookeeper 集群节点个数配置
- 为什么zookeeper节点推荐配奇数?
- 容错率:需要保证集群能够有半数进行投票
- 2台服务器,至少2台正常运行才行(2的半数为1,半数以上最少为2),正常运行1台服务器都不允许挂掉,但是相对于单节点服务器,2台服务器还有两个单点故障,所以直接排除了。
- 3台服务器,至少2台正常运行才行(3的半数为1.5,半数以上最少为2),正常运行可以允许1台服务器挂掉
- 4台服务器,至少3台正常运行才行(4的半数为2,半数以上最少为3),正常运行可以允许1台服务器挂掉
- 5台服务器,至少3台正常运行才行(5的半数为2.5,半数以上最少为3),正常运行可以允许2台服务器挂掉
- 防脑裂:脑裂集群的脑裂通常是发生在节点之间通信不可达的情况下,集群会分裂成不同的小集群,小集群各自选出自己的leader节
点,导致原有的集群出现多个leader节点的情况,这就是脑裂- 3台服务器,投票选举半数为1.5,一台服务裂开,和另外两台服务器无法通行,这时候2台服务器的集群(2票大于半数1.5票),所以可以选举出leader,而 1 台服务器的集群无法选举。
- 4台服务器,投票选举半数为2,可以分成 1,3两个集群或者2,2两个集群,对于 1,3集群,3集群可以选举;对于2,2集群,则不能选择,造成没有leader节点。
- 5台服务器,投票选举半数为2.5,可以分成1,4两个集群,或者2,3两集群,这两个集群分别都只能选举一个集群,满足zookeeper集群搭建数目。
zookeeper 选举
- Paxos算法是基于消息传递且具有高度容错特性的一致性算法,其解决的问题是在分布式系统中如何就某个值(决议)达成一致,paxos是一个分布式选举算法
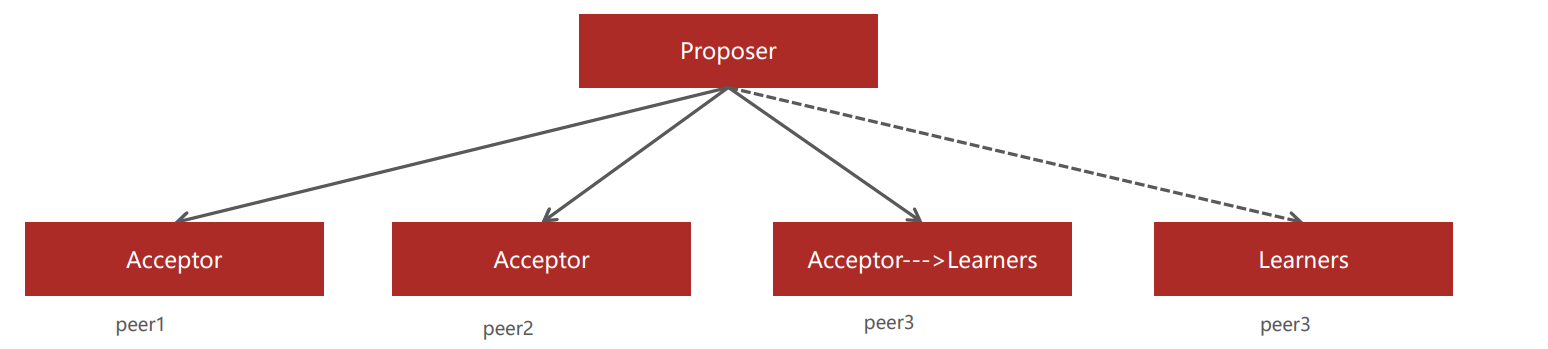
- 该算法的三种角色
➢ Proposer:提案(决议)发起者
➢ Acceptor:提案接收者,可同意或不同意
➢ Learners:虽然不同意提案,但也只能被动接收学习;或者是后来的,只能被动接受提案遵循少数服从多数的原则,过半原则。
ZAB协议
- ZooKeeper使用的是ZAB协议作为数据一致性的算法, ZAB(ZooKeeper Atomic Broadcast ) 全称为:原子消息广播协议。在Paxos算法基础上进行了扩展改造而来的,ZAB协议设计了支持原子广播、崩溃恢复,ZAB协议保证Leader广播的变更序列被顺序的处理。
四种状态,其中三种跟选举有关,选举时也是半数以上通过才算通过
➢ LOOKING:系统刚启动时或者Leader崩溃后正处于选举状态
➢ FOLLOWING:Follower节点所处的状态,同步leader状态,参与投票
➢ LEADING:Leader所处状态
➢ OBSERVING,观察状态,同步leader状态,不参与投票
zookeeper 选举
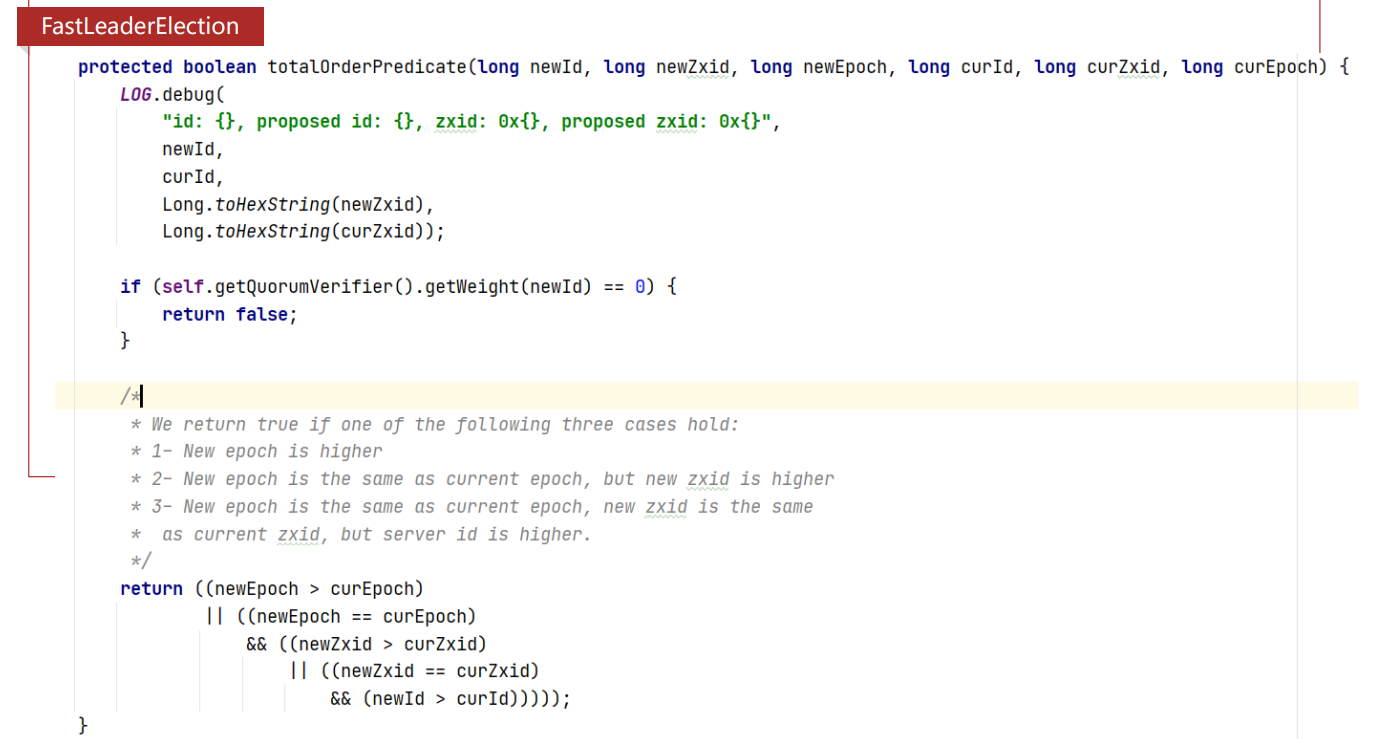
zookeeper 集群数据读写
- 读请求:当Client向zookeeper发出读请求时,无论是Leader还是Follower,都直接返回查询结果
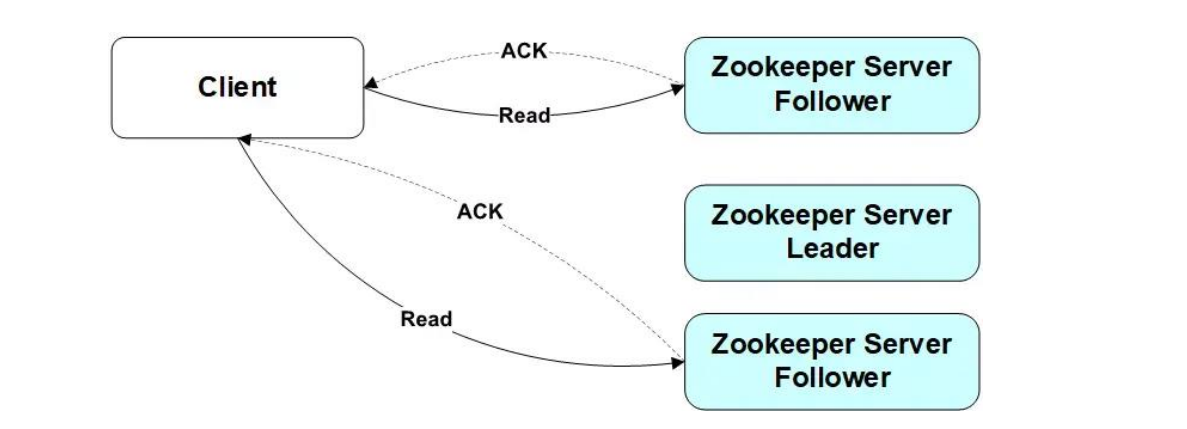
-
写请求->leader
- Client向Leader发出写请求,Leader将数据写入到本节点,并将数据发送到所有的Follower节点,等待Follower节点返回,当Leader接收到一半以上节点(包含自己)返回写成功的信息之后,返回写入成功消息给client。
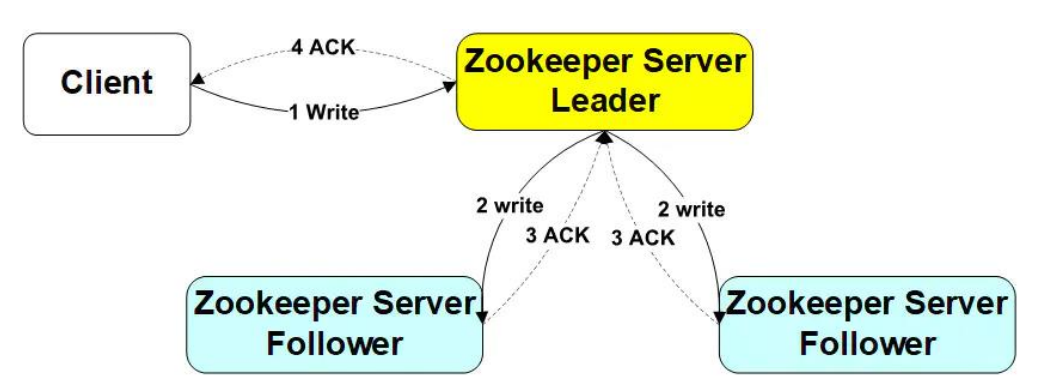
- Client向Leader发出写请求,Leader将数据写入到本节点,并将数据发送到所有的Follower节点,等待Follower节点返回,当Leader接收到一半以上节点(包含自己)返回写成功的信息之后,返回写入成功消息给client。
-
写请求->follwer
- Client向Follower发出写请求,Follower节点将请求转发给Leader,Leader将数据写入到本节点,并将数据发送到所有的Follower节点,等待Follower节点返回,当Leader接收到一半以上节点(包含自己)返回写成功的信息之后,返回写入成功消息给原来的Follower,原来的Follower返回写入成功消息给Client。
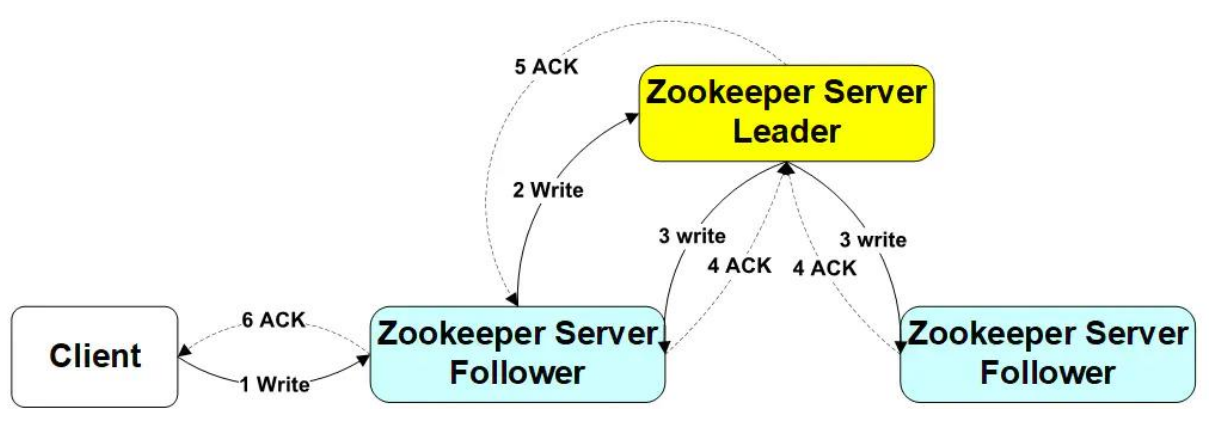
- Client向Follower发出写请求,Follower节点将请求转发给Leader,Leader将数据写入到本节点,并将数据发送到所有的Follower节点,等待Follower节点返回,当Leader接收到一半以上节点(包含自己)返回写成功的信息之后,返回写入成功消息给原来的Follower,原来的Follower返回写入成功消息给Client。