目录
本文是正式进入C语言学习的一道「开胃小菜」,并没有涉及具体的语法,目的是让读者对编程的基本知识有所了解,并且告诉读者如何少走弯路。大家在阅读本文教程的时候请放松心情,不用死记硬背,理解即可。
一、计算机组成原理之计算机系统概述
参考文章:https://blog.csdn.net/xw1680/article/details/132596122
二、程序语言发展历史
我们平时生活中说的是汉语,是 中国语言,只要把我们的要求告诉朋友们或者父母,他们就会知道我们表达的意思,进而满足我们的要求,我们使用 中国语言 来让他人明白、理解我们要做的事情。
中国语言 有固定的格式,每个汉字代表的意思不同(中国文化博大精深,暗语),我们必须正确的表达,别人才能理解我们的意思。如下:
例如: 刘老师,你真的好帅呀!
如果我们说 的好帅呀真你,老刘师,刘老师听了之后就会觉得奇怪,听不懂我们的意思,或者理解错误,责备我们。我们通过有固定格式和固定词汇的 语言 来 "控制" 他人,让他人为我们做事情。语言有很多种,包括汉语、英语、法语、韩语等,虽然他们的词汇和格式都不一样,但是可以达到同样的目的,我们可以选择任意一种语言去 "控制" 他人。同样,我们也可以通过 "语言" 来控制计算机,让计算机为我们做事情,这样的语言就叫做 编程语言(Programming Language)。下面就介绍编程语言的 发展历史:
① 机器语言: 因为计算机只认指令,在早些年前,就有机器语言,它以一种指令集体系结构存在,数据能够被计算机 CPU 直接解读,不需要进行任何的翻译。计算机使用的是由 0和1二进制数 组成的一串指令,如下图所示:
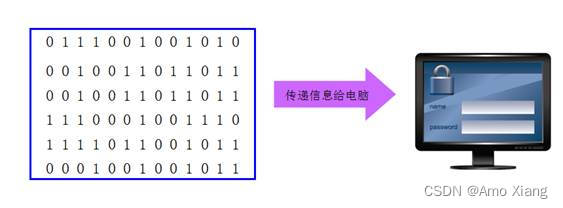
和自然语言完全不同,难于记忆和理解,工作量大,效率低,无法移植。
② 汇编语言: 机器语言的存在正好满足了计算机的要求。但是编程人员使用机器语言很痛苦,于是汇编语言就应运而生了。汇编语言是用英文字母或符号串来替代机器语言的二进制码 (即通过一组简单的的符号来表示机器指令,更接近于自然语言,更容易理解和使用),这样就把不易理解和使用的机器语言变成了汇编语言。因此,使用汇编语言就比机器语言便于阅读和理解程序。如下所示是汇编指令:
mov ax,2000
mov ss,ax
mov sp,10
mov ax,3213
push ax
mov ax,3366
push ax
③ 高级语言: 汇编语言也有弊端,它的助记符多且难记(开发工作量大、难度高),而且汇编语言依赖于硬件系统(无法移植),于是,人们又发明了高级语言,高级语言的语法和格式类似于英文,远离了对硬件的直接操作。高级语言并不是某一种具体的语言,如下图所示:
如上图所示,包括流行的C语言、Java、C++、Python等,本专栏我们不深入探讨其他编程语言,只谈C语言,这里简单了解下每种语言擅长的方面,例如:
| 编程语言 | 主要用途 |
|---|---|
| C/C++ | C++ 是在C语言的基础上发展起来的,C++ 包含了C语言的所有内容,C语言是C++的一个部分,它们往往混合在一起使用,所以统称为 C/C++。C/C++主要用于PC软件开发、Linux开发、游戏开发、单片机和嵌入式系统。 |
| Java | Java 是一门通用型的语言,可以用于网站后台开发、Android 开发、PC软件开发,近年来又涉足了大数据领域(归功于 Hadoop 框架的流行)。 |
| C# | C# 是微软开发的用来对抗 Java 的一门语言,实现机制和 Java 类似,不过 C# 显然失败了,目前主要用于 Windows 平台的软件开发,以及少量的网站后台开发。 |
| Python | Python 也是一门通用型的语言,主要用于系统运维、网站后台开发、数据分析、人工智能、云计算等领域,近年来势头强劲,增长非常快。 |
| PHP | PHP 是一门专用型的语言,主要用来开发网站后台程序。 |
| JavaScript | JavaScript 最初只能用于网站前端开发,而且是前端开发的唯一语言,没有可替代性。近年来由于 Node.js 的流行,JavaScript 在网站后台开发中也占有了一席之地,并且在迅速增长。 |
| Go语言 | Go语言是 2009 年由 Google 发布的一款编程语言,成长非常迅速,在国内外已经有大量的应用。Go 语言主要用于服务器端的编程,对 C/C++、Java 都形成了不小的挑战。 |
| Objective-C Swift | Objective-C 和 Swift 都只能用于苹果产品的开发,包括 Mac、MacBook、iPhone、iPad、iWatch 等。 |
| 汇编语言 | 汇编语言是计算机发展初期的一门语言,它的执行效率非常高,但是开发效率非常低,所以在常见的应用程序开发中不会使用汇编语言,只有在对效率和实时性要求极高的关键模块才会考虑汇编语言,例如操作系统内核、驱动、仪器仪表、工业控制等。 |
可以将上表中不同的编程语言比喻成各国语言,为了表达同一个意思,可能使用不同的语句。例如,表达 刘老师你好 的意思:
汉语: 刘老师你好
英语: Hello, Miss Liu
韩语: 유 선생님, 안녕하세요.
在编程语言中,同样的操作也可能使用不同的语句。例如,在屏幕上显示 刘老师你好:
puts("刘老师你好"); //C语言
console.log("刘老师你好");//javascript语言
System.out.println("刘老师你好");//java语言
print("刘老师你好") //python语言
高级语言类似于人类语言,由直观的词汇组成,我们很容易就能理解它的意思,例如在C语言中,我们使用 puts(puts 是 output string(输出字符串) 的缩写) 这个词让计算机在屏幕上显示出文字;使用 puts 在屏幕上显示 刘老师你好:
puts("刘老师你好");
我们把要显示的内容放在 (" 和 ") 之间,并且在最后要有 ;。 你必须要这样写,这是固定的格式。
总结: 编程语言是用来控制计算机的 一系列指令(Instruction),它有固定的格式和词汇(不同编程语言的格式和词汇不一样),我们必须经过学习才会使用,才能控制计算机。如果不严格遵守编程语言的语法规则,就会出错,达不到我们的目的。
拓展:编译型语言和解释型语言的区别?
我们常常使用的计算机是不能理解高级语言的,更不能直接执行高级语言,它只能直接理解机器语言,所以使用任何高级语言编写的程序若想被计算机运行,都必须将其转换成计算机语言,也就是机器码。操作系统提供了两种转换方法:1. 编译 2. 解释。
所以高级语言也分为 编译型语言和解释型语言。 主要区别在于,前者源程序编译后即可在该平台运行,后者是在运行期间才编译。所以前者运行速度快,后者跨平台性好。
编译性语言特点: 针对不同的平台,需要使用对应的编译器,它可以将高级语言源代码一次性的编译成可被该平台硬件执行的机器码,并包装成该平台所能识别的可执行性程序的格式。总结: 与特定的平台有关,在其他平台使用,需要想办法移植。可以编译成平台相关的机器语言文件,运行时脱离开发环境,运行效率高;
解释性语言特点: 解释器是对源程序逐行解释成特定平台的机器码并立即执行。是代码在执行时才被解释器一行行动态翻译和执行,而不是在执行之前就完成翻译。总结: 解释型语言每次运行都需要将源代码解释称机器码并执行,效率相对较低,但是书写简单。不同的平台只要提供相应的解释器,就可以运行源代码,所以可以方便源程序移植;
程序设计的步骤:
说明:无论是高级程序设计语言还是专用程序设计语言,都不能被计算机系统直接识别,用这些语言所编写的程序代码称为源程序,源程序需要通过预先设计好的专用程序进行转换,转换为计算机系统可以识别的机器指令,然后才能交由计算机系统执行。
C语言(C Language) 是高级程序设计语言的一种,学习C语言,主要是学习它的格式和词汇。下面是一个C语言的完整例子,它会让计算机在屏幕上显示 刘老师,您好!。这个例子主要演示C语言的一些固有格式和词汇,看不懂的读者不必深究,也不必问为什么是这样,后续会逐步给大家讲解。
#include <stdio.h>
int main(){
puts("刘老师,您好!");
return 0;
}
这些具有 特定含义的词汇、语句,按照特定的格式组织在一起,就构成了 源代码(Source Code),也称 源码或代码(Code)。
那么,C语言肯定规定了源代码中每个词汇、语句的含义,也规定了它们 该如何组织在一起,这就是 语法(Syntax)。 它与我们学习英语时所说的 语法 类似,都规定了如何将特定的词汇和句子组织成能听懂的语言。编写源代码的过程就叫做 编程(Program)。 从事编程工作的人叫 程序员(Programmer)。 程序员也很幽默,喜欢自嘲,经常说自己的工作辛苦,地位低,像农民一样,所以称自己是 码农,就是写代码的农民。也有人自嘲称是 程序猿/程序媛。

三、为什么要学习C语言
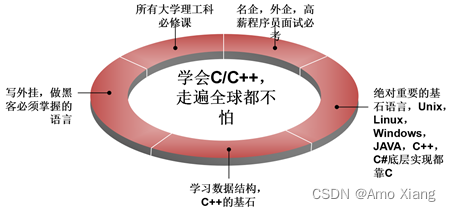
在第二小节中我们介绍了 程序语言发展历史,那么这么多的高级语言,为什么我们要先学习C语言呢,理由如下:
① C语言具有可移植性好、跨平台的特点,用C编写的代码可以在不同的操作系统和硬件平台上编译和运行。C语言的原始设计目的,是将 Unix 系统移植到其他计算机架构,这使得它从一开始就非常注重可移植性。
② C语言在许多领域应用广泛。掌握C语言可以让你有更多就业机会。
操作系统:C 广泛用于开发操作系统,如 Unix、Linux 和Windows。
嵌入式系统:C 是一种用于开发嵌入式系统(如微控制器、微处理器和其他电子设备)的流行语言。
系统软件:C用于开发设备驱动程序、编译器和汇编器等系统软件。
网络:C 语言广泛用于开发网络应用程序,例如 Web 服务器、网络协议和网络驱动程序。
数据库系统:C 用于开发数据库系统,例如 Oracle、MySQL 和PostgreSQL。
游戏:由于 C 能够处理低级硬件交互,因此经常用于开发计算机游戏。
人工智能:C 用于开发人工智能和机器学习应用程序,例如神经网络和深度学习算法。
科学应用:C 用于开发科学应用程序,例如仿真软件和数值分析工具。
金融应用:C用于开发股票市场分析和交易系统等金融应用。
③ C语言能够直接对硬件进行操作、管理内存、跟操作系统对话,这使得它是一种非常接近底层的语言,非常适合写需要跟硬件交互、有极高性能要求的程序。
④ 学习C语言有助于快速上手其他编程语言,比如C++(原先是C语言的一个扩展,在C语言的基础上嫁接了面向对象编程)、C#、 Java、PHP、Javascript、Perl、Python 等,这些语言都继承或深受C语言的影响和启发。说C语言是现代编程语言的开山鼻祖毫不夸张,它改变了编程世界。
在世界编程语言排行榜中,C语言、Java 和 C++ 长期霸占着前三名,加上近几年爆火的 Python,四门语言的市场占用率之和接近 50%,拥有绝对优势,如下表所示:
网友一言话C: https://www.nowcoder.com/stack/209

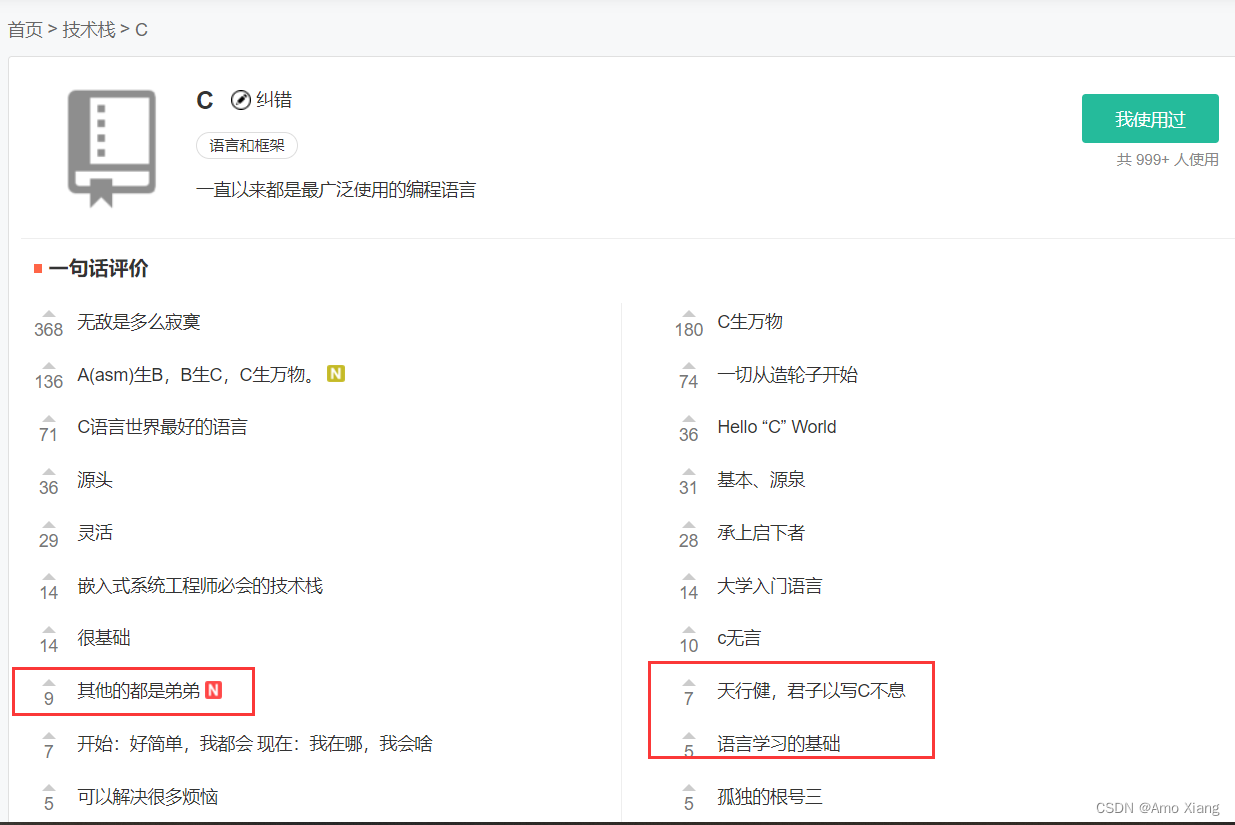
⑤ C语言长盛不衰。至今,依然是最广泛使用、最流行的编程语言之一。包括很多大学将C语言作为计算机教学的入门语言,拥有庞大而活跃的用户社区,这意味着有许多资源和库可供开发人员使用。
⑥ C语言是菜鸟和大神的分水岭。
对于大部分程序员,C语言是学习编程的第一门语言,很少有不了解C的程序员。C语言除了能让你了解编程的相关概念,带你走进编程的大门,还能让你明白程序的运行原理,比如,计算机的各个部件是如何交互的,程序在内存中是一种怎样的状态,操作系统和用户程序之间有着怎样的
爱恨情仇, 这些底层知识决定了你的发展高度,也决定了你的职业生涯。如果你希望成为出类拔萃的人才,而不仅仅是码农,这么这些知识就是不可逾越的。也只有学习C语言,才能更好地了解它们。有了足够的基础,以后学习其他语言,会触类旁通,很快上手,7 天了解一门新语言不是神话。
所有的程序都在拼尽全力节省内存,都在不遗余力提高内存使用效率,计算机的整个发展过程都在围绕内存打转,不断地优化内存布局,以保证可以同时运行多个程序。不了解内存,就学不会进程和线程,就没有资格玩中大型项目,没有资格开发底层组件,没有资格架构一个系统,命中注定你就是一个菜鸟,成不了什么气候。
从C语言到内存,从内存到进程和线程,环环相扣:不学C语言就吃不透内存,不学内存就吃不透进程和线程。「内存 + 进程 + 线程」这几个最基本的计算机概念是菜鸟和大神的分水岭,也只有学习C语言才能透彻地理解它们。Java、C#、PHP、Python、JavaScript 程序员工作几年后会遇到瓶颈,有很多人会回来学习C语言,重拾底层概念,让自己再次突破。
⑦ 简单易学。和 Java、C++、Python、C#、JavaScript 等高级编程语言相比,C语言涉及到的编程概念少,附带的标准库小,所以整体比较简洁,容易学习,非常适合初学者入门。

四、学习C语言的常见困惑
本小节主要是解答初学者的疑惑,没有信心的读者看了会吃一颗定心丸,浮躁的读者看了会被泼一盆冷水。
4.1 学编程难吗?多久能入门?
编程是一门技术,我也不知道它难不难,我只知道,只要你想学,肯定能学会。每个人的逻辑思维能力不同,兴趣点不同,总有一部分人觉得容易,一部分人觉得吃力。在我看来,技术就是一层窗户纸,是有道理可以遵循的,最起码要比搞抽象的艺术容易很多。但是,隔行如隔山,学好编程也不是一朝一夕的事,想 吃快餐 的读者可以退出编程界了,浮躁的人搞不了技术。
在技术领域,编程的入门门槛很低,互联网的资料很多,只要你有一台计算机,一根网线,具备初中学历,就可以学习,投资在 7000RMB 左右。不管是技术还是非技术,要想有所造诣,都必须潜心钻研,没有几年功夫不会鹤立鸡群。所以请先问问你自己,你想学编程吗,你喜欢吗,如果你觉得自己对编程很感兴趣,想了解软件或网站是怎么做的,那么就不要再问这个问题了,尽管去学就好了。
4.2 多久能学会编程?
这是一个没有答案的问题。每个人投入的时间、学习效率和基础都不一样。如果你每天都拿出大把的时间来学习,那么两三个月就可以学会C/C++,不到半年时间就可以编写出一些软件。但是有一点可以肯定,几个月从小白成长为大神是绝对不可能的。要想出类拔萃,没有几年功夫是不行的。学习编程不是看几本书就能搞定的,需要你不断的练习,编写代码,积累零散的知识点,代码量跟你的编程水平直接相关,没有几万行代码,没有拿得出手的作品,怎能称得上 大神。 每个人程序员都是这样过来的,开始都是一头雾水,连输出九九乘法表都很吃力,只有通过不断练习才能熟悉,这是一个强化思维方式的过程。知识点可以在短时间内了解,但是思维方式和编程经验需要不断实践才能强化,这就是为什么很多初学者已经了解了C语言的基本概念,但是仍然不会编写代码的原因。
程序员被戏称为 码农, 意思是写代码的农民,要想成为一个合格的农民,必须要脚踏实地辛苦耕耘。也不要压力太大,一切编程语言都是纸老虎,一层窗户纸,只要开窍了,就容易了。一个人要想在某一方面有所成就,就必须有 10000小时 浸泡 在这件事情上,最终一定会有所收获。

很多领域都是「一年打基础,两年见成效,三年有突破」,但是很多人在不到一年的时间里就放弃了,总觉得这个行业太难,不太适合自己。轻言放弃是很可怕的,你要知道,第一次放弃只是浪费了时间,第二次放弃会打击你的信心,第三次放弃会摧毁你的意志,你就再也没有尝试的勇气了,蹉跎人生 就是这么来的。你也不要羡慕那些富二代官二代,你以为人生就是一次百米短跑,你赢了就是赢了,其实人生是一场接力赛,你的父辈祖辈都得赢,那些富二代官二代从好几十年以前就开始积累了。所以,沉下一颗心来,从现在开始积累吧,有执念的人最可怕。
4.3 英语基础不好可以学会编程吗?
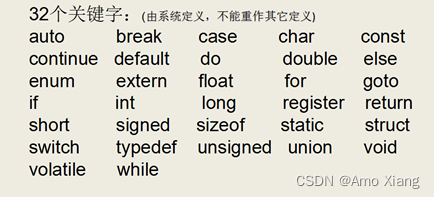
首先,学习编程需要你有英语基础;但是,要求并不高,初中水平完全可以胜任。编程语言起源于美国,是由英文构成的,其中包括几十个英文的关键字以及几百个英文的函数,除非需要对文本进行处理,否则一般不会出现中文。但是,它们都是孤立的单词,不构成任何语句,不涉及任何语法。几十个关键字不多,用得多了自然会记住,相信大家也不会担心。下面是C语言中的 32 个关键字:
几百个函数就没人能记住了(包括我),也不用记住,查询文档即可,每种编程语言都会提供配套的文档。常用到的函数也就几十个,记住它们就足够应付日常开发了,生僻的函数查询文档即可。此外,我推荐大家安装有道词典,它的划词取词功能非常棒,选中一个单词或者句子能够及时翻译,这对大家记忆和理解代码非常有帮助。
对于英文资料
如果你希望达到很高的造诣,希望被人称为
大神, 那么肯定要阅读英文的技术资料(不是所有资料都被翻译成了中文),初中水平就有点吃力了。不过,长期阅读英文会提高你的英文水平,只要你坚持一段时间,即使只有初中水平,我相信借助有道词典也会提高很快。推荐一本书:程序员的英语
4.4 数学基础不好可以学编程吗?
谈到数学,那真是多虑了,它根本不构成障碍,会加减乘除就能学编程。编程语言确实涉及到很多算法,有一些还需要高等数学知识,但是,这些算法都已经被封装好了,你直接拿来用就可以,根本不用你重复造轮子。另外,这些算法都是在很深的底层为我们默默的工作,初级程序员根本不会涉及到算法,即使是别人已经封装好的算法,一般也没有机会使用,所以,你就别瞎操心了。
五、C语言和C++到底有什么关系?
C++ 读作 C加加,是 C Plus Plus 的简称。顾名思义,C++是在C的基础上增加新特性,玩出了新花样,所以叫 C Plus Plus,就像 iPhone 6S 和 iPhone 6、Win10 和 Win7 的关系。
C语言是1972年由美国贝尔实验室研制成功的,在当时算是高级语言,它的很多新特性都让汇编程序员羡慕不已,就像今天的Go语言,刚出生就受到追捧。C语言也是 时髦 的语言,后来的很多软件都用C语言开发,包括 Windows、Linux 等。但是随着计算机性能的飞速提高,硬件配置与几十年前已有天壤之别,软件规模也不断增大,很多软件的体积都超过 2G,例如 PhotoShop、Visual Studio 等,用C语言开发这些软件就显得非常吃力了,这时候C++就应运而生了。C++ 主要在C语言的基础上增加了面向对象和泛型的机制,提高了开发效率,以适用于大中型软件的编写。
C++和C的血缘关系: 早期并没有 C++ 这个名字,而是叫做 带类的C。带类的C 是作为C语言的一个扩展和补充出现的,目的是提高开发效率,如果你有 Java Web 开发经验,那么你可以将它们的关系与 Java 和 JSP 的关系类比。这个时期的C++非常粗糙,仅支持简单的面向对象编程,也没有自己的编译器,而是通过一个预处理程序(名字叫 cfront),先将C++代码 翻译 为C语言代码,再通过C语言编译器合成最终的程序。随着C++的流行,它的语法也越来越强大,已经能够很完善的支持面向对象编程和泛型编程。但是一直也没有诞生出新的C++编译器,而是对原来C编译器不断扩展,让它支持C++的新特性,所以我们通常称为C/C++编译器,因为它同时支持C和C++,例如 Windows 下的微软编译器(cl.exe),Linux 下的 GCC 编译器。也就是说,你写的C、C++代码都会通过一个编译器来编译,很难说C++是一门独立的语言,还是对C的扩展。
从 学院派 的角度来说,C++支持面向过程编程、面向对象编程和泛型编程,而C语言仅支持面向过程编程。就面向过程编程而言,C++和C几乎是一样的,所以学习了C语言,也就学习了C++的一半,不需要从头再来。后续我的教程也是这样安排的:
- 先讲解C语言,不希望学习C++的读者可以就此止步。
- 再讲解C++,主要包括C++和C的一些差别,以及面向对象编程和泛型编程。
没有任何编程基础的读者,建议先从C语言学起,不要贪多嚼不烂。等你熟悉了C语言,能编写出上百行的代码,就对编程有些概念了,这个时候再去了解C++究竟在C语言基础上增加了什么,你就站在了一定的高度。有编程基础的读者,相信你自己能做出正确的判断。
六、计算机组成原理之数据的表示和运算
参考文章:https://blog.csdn.net/xw1680/article/details/132417469
七、程序的运行
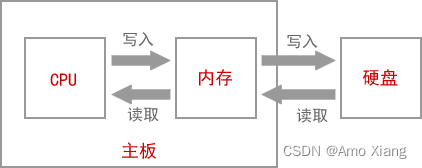
如果你的电脑上安装了微信,你希望和好友聊天,会双击微信图标,打开微信软件,输入账号和密码,然后登录就可以了。那么,微信是怎么运行起来的呢?首先,有一点你要明确,你安装的微信软件是保存在硬盘中的。双击微信图标,操作系统就会知道你要运行这个软件,它会在硬盘中找到你安装的微信软件,将数据(安装的软件本质上就是很多数据的集合)复制到内存。对!就是复制到内存!微信不是在硬盘中运行的,而是在内存中运行的。为什么呢?因为内存的读写速度比硬盘快很多。
对于读写速度,内存 > 固态硬盘 > 机械硬盘。机械硬盘是靠电机带动盘片转动来读写数据的,而内存条通过电路来读写数据,电机的转速肯定没有电的传输速度 (几乎是光速) 快。虽然固态硬盘也是通过电路来读写数据,但是因为与内存的控制方式不一样,速度也不及内存。
所以,不管是运行微信还是编辑 Word 文档,都是先将硬盘上的数据复制到内存,才能让CPU来处理,这个过程就叫作载入内存(Load into Memory)。完成这个过程需要一个特殊的程序(软件),这个程序就叫做加载器(Loader)。CPU直接与内存打交道,它会读取内存中的数据进行处理,并将结果保存到内存。如果需要保存到硬盘,才会将内存中的数据复制到硬盘。
例如,打开 Word 文档,输入一些文字,虽然我们看到的不一样了,但是硬盘中的文档没有改变,新增的文字暂时保存到了内存,Ctrl+S 才会保存到硬盘。因为内存断电后会丢失数据,所以如果你编辑完 Word 文档忘记保存就关机了,那么你将永远无法找回这些内容。
虚拟内存: 如果我们运行的程序较多,占用的空间就会超过内存(内存条)容量。例如计算机的内存容量为2G,却运行着10个程序,这10个程序共占用3G的空间,也就意味着需要从硬盘复制 3G 的数据到内存,这显然是不可能的。
操作系统(Operating System,简称 OS) 为我们解决了这个问题:当程序运行需要的空间大于内存容量时,会将内存中暂时不用的数据再写回硬盘;需要这些数据时再从硬盘中读取,并将另外一部分不用的数据写入硬盘。这样,硬盘中就会有一部分空间用来存放内存中暂时不用的数据。这一部分空间就叫做虚拟内存(Virtual Memory)。3G - 2G = 1G,上面的情况需要在硬盘上分配 1G 的虚拟内存。
硬盘的读写速度比内存慢很多,反复交换数据会消耗很多时间,所以如果你的内存太小,会严重影响计算机的运行速度,甚至会出现 卡死 现象,即使CPU强劲,也不会有大的改观。如果经济条件允许,建议将内存升级为 32G,在 win7、win8、win10 下运行软件就会比较流畅了。总结:CPU直接从内存中读取数据,处理完成后将结果再写入内存。CPU、内存、硬盘和主板的关系如下图所示:
八、字符编码
8.1 ASCII编码
计算机是以二进制的形式来存储数据的,它只认识 0 和 1 两个数字,我们在屏幕上看到的文字,在存储之前都被转换成了二进制(0和1序列),在显示时也要根据二进制找到对应的字符。
可想而知,特定的文字必然对应着固定的二进制,否则在转换时将发生混乱。那么,怎样将文字与二进制对应起来呢?这就需要有一套规范,计算机公司和软件开发者都必须遵守,这样的一套规范就称为 字符集(Character Set) 或者 字符编码(Character Encoding)。
严格来说,字符集和字符编码不是一个概念,字符集定义了文字和二进制的对应关系,为字符分配了唯一的编号,而字符编码规定了如何将文字的编号存储到计算机中。我们暂时先不讨论这些细节,姑且认为它们是一个概念,本节中也混用了这两个概念,未做区分。
字符集为每个字符分配一个唯一的编号,类似于学生的学号,通过编号就能够找到对应的字符。可以将字符集理解成一个很大的表格,它列出了所有字符和二进制的对应关系,计算机显示文字或者存储文字,就是一个查表的过程。在计算机逐步发展的过程中,先后出现了几十种甚至上百种字符集,有些还在使用,有些已经淹没在了历史的长河中,本小节要讲解的是一种专门针对英文的字符集—— ASCII 编码。
1、拉丁字母(开胃小菜)。 在正式介绍 ASCII 编码之前,我们先来说说什么是拉丁字母。估计也有不少读者和我一样,对于拉丁字母、英文字母和汉语拼音中的字母的关系不是很清楚。拉丁字母也叫罗马字母,它源自希腊字母,是当今世界上使用最广的字母系统。基本的拉丁字母就是我们经常见到的 ABCD 等26个英文字母。拉丁字母、阿拉伯字母、斯拉夫字母(西里尔字母)被称为世界三大字母体系。拉丁字母原先是欧洲人使用的,后来由于欧洲殖民主义,导致这套字母体系在全球范围内开始流行,美洲、非洲、澳洲、亚洲都没有逃过西方文化的影响。中国也是,我们现在使用的拼音其实就是拉丁字母,是不折不扣的舶来品。
后来,很多国家对 26 个基本的拉丁字母进行了扩展,以适应本地的语言文化。最常见的扩展方式就是加上变音符号,例如汉语拼音中的 ü,就是在u的基础上加上两个小点演化而来;再如,áà 就是在a的上面标上音调。总起来说: 基本拉丁字母就是 26 个英文字母;扩展拉丁字母就是在基本的 26 个英文字母的基础上添加变音符号、横线、斜线等演化而来,每个国家都不一样。
2、ASCII 编码。 计算机是美国人发明的,他们首先要考虑的问题是,如何将二进制和英文字母(也就是拉丁文)对应起来。当时,各个厂家或者公司都有自己的做法,编码规则并不统一,这给不同计算机之间的数据交换带来不小的麻烦。但是相对来说,能够得到普遍认可的有 IBM 发明的 EBCDIC 和此处要谈的 ASCII。我们先说 ASCII。ASCII 是 American Standard Code for Information Interchange 的缩写,翻译过来是 美国信息交换标准代码。看这个名字就知道,这套编码是美国人给自己设计的,他们并没有考虑欧洲那些扩展的拉丁字母,也没有考虑韩语和日语,我大中华几万个汉字更是不可能被重视。但这也无可厚非,美国人自己发明的计算机,当然要先解决自己的问题
ASCII 的标准版本于 1967 年第一次发布,最后一次更新则是在 1986 年,迄今为止共收录了 128 个字符,包含了基本的 拉丁字母(英文字母)、阿拉伯数字(也就是1234567890)、标点符号(,.!等)、特殊符号(@#$%^&等) 以及一些具有控制功能的字符(往往不会显示出来)。
在 ASCII 编码中,大写字母、小写字母和阿拉伯数字都是连续分布的(见 https://baike.baidu.com/item/ASCII?fromModule=lemma_search-box),这给程序设计带来了很大的方便。例如要判断一个字符是否是大写字母,就可以判断该字符的 ASCII 编码值是否在 65~90 的范围内。
EBCDIC 编码正好相反,它的英文字母不是连续排列的,中间出现了多次断续,给编程带来了一些困难。现在连 IBM 自己也不使用 EBCDIC 了,转而使用更加优秀的 ASCII。ASCII 编码已经成了计算机的通用标准,没有人再使用 EBCDIC 编码了,它已经消失在历史的长河中了。
标准 ASCII 编码共收录了 128 个字符,其中包含了 33 个控制字符(具有某些特殊功能但是无法显示的字符) 和 95 个可显示字符,查看:https://baike.baidu.com/item/ASCII?fromModule=lemma_search-box 该表列出的是标准的 ASCII 编码,它共收录了 128 个字符,用一个字节中较低的 7 个比特位(Bit)足以表示(27 = 128),所以还会空闲下一个比特位,它就被浪费了。如果还想了解每个控制字符的含义,请转到:http://c.biancheng.net/c/ascii/
8.2 GB2312编码和GBK编码
计算机是一种改变世界的发明,很快就从美国传到了全球各地,得到了所有国家的认可,成为了一种不可替代的工具。计算机在广泛流行的过程中遇到的一个棘手问题就是字符编码,计算机是美国人发明的,它使用的是 ASCII 编码,只能显示英文字符,对汉语、韩语、日语、法语、德语等其它国家的字符无能为力。
为了让本国公民也能使用上计算机,各个国家(地区) 也开始效仿 ASCII,开发了自己的字符编码。这些字符编码和 ASCII 一样,只考虑本国的语言文化,不兼容其它国家的文字。这样做的后果就是,一台计算机上必须安装多套字符编码,否则就不能正确地跨国传递数据,例如在中国编写的文本文件,拿到日本的电脑上就无法打开,或者打开后是一堆乱码。下表列出了常见的字符编码:

由于 ASCII 先入为主,已经使用了十来年了,现有的很多软件和文档都是基于 ASCII 的,所以后来的这些字符编码都是在 ASCII 基础上进行的扩展,它们都兼容 ASCII,以支持既有的软件和文档。兼容 ASCII 的含义是,原来 ASCII 中已经包含的字符,在国家编码(地区编码)中的位置不变(也就是编码值不变),只是在这些字符的后面增添了新的字符。
标准 ASCII 编码共包含了 128 个字符,用一个字节就足以存储(实际上是用一个字节中较低的 7 位来存储),而日文、中文、韩文等包含的字符非常多,有成千上万个,一个字节肯定是不够的(一个字节最多存储 28 = 256 个字符),所以要进行扩展,用两个、三个甚至四个字节来表示。在制定字符编码时还要考虑内存利用率的问题。我们经常使用的字符,其编码值一般都比较小,例如字母和数字都是 ASCII 编码,其编码值不会超过 127,用一个字节存储足以,如果硬要用多个字节存储,就会浪费很多内存空间。为了达到 既能存储本国字符,又能节省内存 的目的,Shift-Jis、Big5、GB2312 等都采用变长的编码方式:
对于原来的 ASCII 编码部分,用一个字节存储足以
对于本国的常用字符(例如汉字、标点符号等),一般用两个字节存储
对于偏远地区,或者极少使用的字符(例如藏文、蒙古文等),才使用三个甚至四个字节存储
总起来说,越常用的字符占用的内存越少,越罕见的字符占用的内存越多。
中文编码方案: GB2312 --> GBK --> GB18030 是中文编码的三套方案,出现的时间从早到晚,收录的字符数目依次增加,并且向下兼容。GB2312 和 GBK 收录的字符数目较少,用 1~2个字节存储;GB18030 收录的字符最多,用 1、2、4 个字节存储。
从整体上讲,GB2312 和 GBK 的编码方式一致,具体为:对于 ASCII 字符,使用一个字节存储,并且该字节的最高位是 0,这和 ASCII 编码是一致的,所以说 GB2312 完全兼容 ASCII。对于中国的字符,使用两个字节存储,并且规定每个字节的最高位都是 1。例如对于字母A,它在内存中存储为 01000001;对于汉字中,它在内存中存储为 11010110 11010000。由于单字节和双字节的最高位不一样,所以字符处理软件很容易区分一个字符到底用了几个字节。
GB18030 为了容纳更多的字符,并且要区分两个字节和四个字节,所以修改了编码方案,具体为:对于 ASCII 字符,使用一个字节存储,并且该字节的最高位是 0,这和 ASCII、GB2312、GBK 编码是一致的。对于常用的中文字符,使用两个字节存储,并且规定第一个字节的最高位是 1,第二个字节的高位最多只能有一个连续的 0(第二个字节的最高位可以是 1 也可以是 0,但是当它是 0 时,次高位就不能是 0 了)。注意对比 GB2312 和 GBK,它们要求两个字节的最高位为都必须为 1。对于罕见的字符,使用四个字节存储,并且规定第一个和第三个字节的最高位是 1,第二个和第四个字节的高位必须有两个连续的 0。例如对于字母A,它在内存中存储为 01000001;对于汉字中,它在内存中存储为 11010110 11010000;对于藏文གྱུ,它在内存中的存储为 10000001 00110010 11101111 00110000。
字符处理软件在处理文本时,从左往右依次扫描每个字节:
如果遇到的字节的最高位是 0,那么就会断定该字符只占用了一个字节
如果遇到的字节的最高位是 1,那么该字符可能占用了两个字节,也可能占用了四个字节,不能妄下断论,所以还要继续往后扫描
如果第二个字节的高位有两个连续的 0,那么就会断定该字符占用了四个字节
如果第二个字节的高位没有连续的 0,那么就会断定该字符占用了两个字节
可见,当字符占用两个或者四个字节时,GB18030 编码要检测两次,处理效率比 GB2312 和 GBK 都低。GBK 编码最牛掰: GBK 于 1995 年发布,这一年也是互联网爆发的元年,国人使用电脑越来越多,也许是 GBK 这头猪正好站在风口上,它就飞起来了,后来的中文版 Windows 都将 GBK 作为默认的中文编码方案。注意,这里我说 GBK 是默认的中文编码方案,并没有说 Windows 默认支持 GBK。Windows 在内核层面使用的是 Unicode 字符集(严格来说是 UTF-16 编码),但是它也给用户留出了选择的余地,如果用户不希望使用 Unicode,而是希望使用中文编码方案,那么这个时候 Windows 默认使用 GBK(当然,你可以选择使用 GB2312 或者 GB18030,不过一般没有这个必要)。实际上,中文版 Windows 下的很多程序默认使用的就是 GBK 编码,例如用记事本程序创建一个 txt 文档、在 cmd 或者控制台程序(最常见的C语言程序)中显示汉字、用 Visual Studio 创建的源文件等,使用的都是 GBK 编码。可以说,GBK 编码在中文版的 Windows 中大行其道。
8.3 Unicode字符集
ASCII、GB2312、GBK、Shift_Jis、ISO/IEC 8859 等地区编码都是各个国家为了自己的语言文化开发的,不具有通用性,在一种编码下开发的软件或者编写的文档,拿到另一种编码下就会失效,必须提前使用程序转码,非常麻烦。人们迫切希望有一种编码能够统一世界各地的字符,计算机只要安装了这一种文字编码,就能支持使用世界上所有的文字,再也不会出现乱码,再也不需要转码了,这对计算机的数据传递来说是多么的方便呀!就在这种呼吁下,Unicode 诞生了。Unicode 也称为统一码、万国码;看名字就知道,Unicode 希望统一所有国家的字符编码。Unicode 于 1994 年正式公布第一个版本,现在的规模可以容纳 100 多万个符号,是一个很大的集合。
有兴趣的读取可以转到 https://unicode-table.com/cn/ 查看 Unicode 包含的所有字符,以及各个国家的字符是如何分布的。
Windows、Linux、Mac OS 等常见操作系统都已经从底层(内核层面) 开始支持 Unicode,大部分的网页和软件也使用 Unicode,Unicode 是大势所趋。不过由于历史原因,目前的计算机仍然安装了 ASCII 编码以及 GB2312、GBK、Big5、Shift-JIS 等地区编码,以支持不使用 Unicode 的软件或者文档。内核在处理字符时,一般会将地区编码先转换为 Unicode,再进行下一步处理。本节我们多次说 Unicode 是一套字符集,而不是一套字符编码,它们之间究竟有什么区别呢?
严格来说,字符集和字符编码不是一个概念:
- 字符集定义了字符和二进制的对应关系,为每个字符分配了唯一的编号。可以将字符集理解成一个很大的表格,它列出了所有字符和二进制的对应关系,计算机显示文字或者存储文字,就是一个查表的过程。
- 而字符编码规定了如何将字符的编号存储到计算机中。如果使用了类似 GB2312 和 GBK 的变长存储方案(不同的字符占用的字节数不一样),那么为了区分一个字符到底使用了几个字节,就不能将字符的编号直接存储到计算机中,字符编号在存储之前必须要经过转换,在读取时还要再逆向转换一次,这套转换方案就叫做字符编码。
有的字符集在制定时就考虑到了编码的问题,是和编码结合在一起的,例如 ASCII、GB2312、GBK、BIG5 等,所以无论称作字符集还是字符编码都无所谓,也不好区分两者的概念。而有的字符集只管制定字符的编号,至于怎么存储,那是字符编码的事情,Unicode 就是一个典型的例子,它只是定义了全球文字的唯一编号,我们还需要 UTF-8、UTF-16、UTF-32 这几种编码方案将 Unicode 存储到计算机中。Unicode 可以使用的编码方案有三种,分别是:
UTF-8: 一种变长的编码方案,使用 1~6 个字节来存储
UTF-32: 一种固定长度的编码方案,不管字符编号大小,始终使用 4 个字节来存储
UTF-16: 介于 UTF-8 和 UTF-32 之间,使用 2 个或者 4 个字节来存储,长度既固定又可变
UTF 是 Unicode Transformation Format 的缩写,意思是 Unicode转换格式,后面的数字表明至少使用多少个比特位(Bit)来存储字符。
1、UTF-8,UTF-8 的编码规则很简单:如果只有一个字节,那么最高的比特位为 0,这样可以兼容 ASCII;如果有多个字节,那么第一个字节从最高位开始,连续有几个比特位的值为 1,就使用几个字节编码,剩下的字节均以 10 开头。具体的表现形式为:
0xxxxxxx: 单字节编码形式,这和 ASCII 编码完全一样,因此 UTF-8 是兼容 ASCII 的
110xxxxx 10xxxxxx: 双字节编码形式(第一个字节有两个连续的 1)
1110xxxx 10xxxxxx 10xxxxxx: 三字节编码形式(第一个字节有三个连续的 1)
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx: 四字节编码形式(第一个字节有四个连续的 1)
xxx 就用来存储 Unicode 中的字符编号。下面是一些字符的 UTF-8 编码实例(绿色部分表示本来的 Unicode 编号):
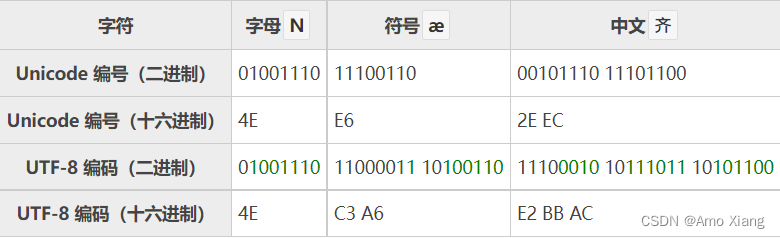
对于常用的字符,它的 Unicode 编号范围是 0 ~ FFFF,用 1~3 个字节足以存储,只有及其罕见,或者只有少数地区使用的字符才需要 4~6 个字节存储。
2、UTF-32, UTF-32 是固定长度的编码,始终占用 4 个字节,足以容纳所有的 Unicode 字符,所以直接存储 Unicode 编号即可,不需要任何编码转换。浪费了空间,提高了效率。
3、UTF-16, UFT-16 比较奇葩,它使用 2 个或者 4 个字节来存储。对于 Unicode 编号范围在 0 ~ FFFF 之间的字符,UTF-16 使用两个字节存储,并且直接存储 Unicode 编号,不用进行编码转换,这跟 UTF-32 非常类似。对于 Unicode 编号范围在 10000~10FFFF 之间的字符,UTF-16 使用四个字节存储,具体来说就是:将字符编号的所有比特位分成两部分,较高的一些比特位用一个值介于 D800~DBFF 之间的双字节存储,较低的一些比特位(剩下的比特位) 用一个值介于 DC00~DFFF 之间的双字节存储。如果你不理解什么意思,请看下面的表格:

位于 D800~0xDFFF 之间的 Unicode 编码是特别为四字节的 UTF-16 编码预留的,所以不应该在这个范围内指定任何字符。如果你真的去查看 Unicode 字符集,会发现这个区间内确实没有收录任何字符。UTF-16 要求在制定 Unicode 字符集时必须考虑到编码问题,所以真正的 Unicode 字符集也不是随意编排字符的。
对比以上三种编码方案,首先,只有 UTF-8 兼容 ASCII,UTF-32 和 UTF-16 都不兼容 ASCII,因为它们没有单字节编码。UTF-8 使用尽量少的字节来存储一个字符,不但能够节省存储空间,而且在网络传输时也能节省流量,所以很多纯文本类型的文件(例如各种编程语言的源文件、各种日志文件和配置文件等)以及绝大多数的网页(例如百度、新浪、163等)都采用 UTF-8 编码。
UTF-8 的缺点是效率低,不但在存储和读取时都要经过转换,而且在处理字符串时也非常麻烦。 例如,要在一个 UTF-8 编码的字符串中找到第 10 个字符,就得从头开始一个一个地检索字符,这是一个很耗时的过程,因为 UTF-8 编码的字符串中每个字符占用的字节数不一样,如果不从头遍历每个字符,就不知道第 10 个字符位于第几个字节处,就无法定位。不过,随着算法的逐年精进,UTF-8 字符串的定位效率也越来越高了,往往不再是槽点了。
UTF-32 是 以空间换效率,正好弥补了 UTF-8 的缺点,UTF-32 的优势就是效率高:UTF-32 在存储和读取字符时不需要任何转换,在处理字符串时也能最快速地定位字符。例如,在一个 UTF-32 编码的字符串中查找第 10 个字符,很容易计算出它位于第 37 个字节处,直接获取就行,不用再逐个遍历字符了,没有比这更快的定位字符的方法了。但是,UTF-32 的缺点也很明显,就是太占用存储空间了,在网络传输时也会消耗很多流量。我们平常使用的字符编码值一般都比较小,用一两个字节存储足以,用四个字节简直是暴殄天物,甚至说是不能容忍的,所以 UTF-32 在应用上不如 UTF-8 和 UTF-16 广泛。
UTF-16 可以看做是 UTF-8 和 UTF-32 的折中方案,它平衡了存储空间和处理效率的矛盾。对于常用的字符,用两个字节存储足以,这个时候 UTF-16 是不需要转换的,直接存储字符的编码值即可。
Windows 内核、.NET Framework、Cocoa、Java String 内部采用的都是 UTF-16 编码。UTF-16 是幕后的功臣,我们在编辑源代码和文档时都是站在前台,所以一般感受不到,其实很多文本在后台处理时都已经转换成了 UTF-16 编码。不过,UNIX 家族的操作系统(Linux、Mac OS、iOS 等) 内核都采用 UTF-8 编码,我们就不去争论谁好谁坏了。
宽字符和窄字符(多字节字符): 有的编码方式采用 1~n 个字节存储,是变长的,例如 UTF-8、GB2312、GBK 等;如果一个字符使用了这种编码方式,我们就将它称为多字节字符,或者窄字符。有的编码方式是固定长度的,不管字符编号大小,始终采用 n 个字节存储,例如 UTF-32、UTF-16 等;如果一个字符使用了这种编码方式,我们就将它称为宽字符。Unicode 字符集可以使用窄字符的方式存储,也可以使用宽字符的方式存储;GB2312、GBK、Shift-JIS 等国家编码一般都使用窄字符的方式存储;ASCII 只有一个字节,无所谓窄字符和宽字符。
九、程序员的薪水和发展方向大全
如果你是一名初学者,对编程非常感兴趣,想成为一名合格的程序员,那么本小节就是为你写的。
从初学者成长为一名合格的程序员需要一段时间的磨练,每个人付出的时间和做事的效率不同,我不好评判你需要多长时间才能学有所成。站在求职的角度,能开发出实用的软件、网站、APP等才叫学有所成。
9.1 程序员的发展方向
计算机涉及的知识非常广泛,不可能在短时间内全部学完,即使公司的 CTO 也不可能样样精通,初学者要选定一个方向,不要想着把客户端软件、网站、APP 都开发出来,这在短时间内是不现实的。相信我,你不是神!
① Windows开发: 主要是开发客户端(PC机上的软件),如QQ、迅雷、360、Chrome 等。能够进行 Windows 客户端开发的编程语言有多种,包括 C/C++、C#、VB、Java、Delphi、易语言等。这意味着,Windows 开发有多种学习路线,大家任选其一。不过,公司一般使用 C/C++、C#、Java,自己编写小工具也可以使用 VB、Delphi、易语言。
② 游戏开发(游戏客户端开发): 需要你有C/C++基础,再学习 Unreal(虚幻)、Frostbite(寒霜)、CryEngine(CE)等游戏引擎。如果你希望了解游戏引擎原理,让自己更加优秀,那么还需要学习图形库(例如 DirectX、OpenGL)和计算机图形学。
③ Linux 开发/游戏后台开发: 需要在 C/C++ 的基础上再学习 Linux 操作系统,主要包括 Linux 基本操作、Shell、文件系统、进程线程、内存、Socket 通信、内核等,甚至还需要与算法、Qt 等相结合。另外,也可以使用Go语言进行 Linux 开发,Go语言在全球已经有相当多的应用案例了。游戏的后台服务器大部分也是基于 Linux的,也会用到以上技能。
④ 单片机/嵌入式: 单片机/嵌入式是软件和硬件的结合,不仅要会写代码,还要了解硬件,所以入门门槛比较高,知识也比较庞杂,学习时间长。选择该方向最好有数字电路、模拟电路和汇编的基础,非常适合电子信息工程专业的同学。这个方向的同学,大部分去了中兴、华为等以生产电子产品为主的公司,工资虽然没有一般的程序员高,但也不错。
⑤ 算法: NB的程序员都在搞这些,一般不注重编程语言,而是侧重解决问题的方法和效率。工资比普通的程序员略高。
⑥ 网站开发: 也称 Web 开发,分为前端和后台。后台主要负责服务器端的编程,除了需要学习 Java、PHP、Python 等编程语言,还需要学习 MySQL、MongoDB、Oracle 等数据库。前端主要负责网页界面的设计以及特效的实现,需要学习 HTML、CSS、JavaScript 等。JavaScript 本来只能用于 Web 前端,它可以实现一些特效,或者和服务器通信,后来有人把 JavaScript 移植到了服务器上,并起名 Node.js,这样 JavaScript 也能进行 Web 后台开发了。也就是说,只要需要学习 JavaScript 一门语言,就可以搞定网站的前端和后台,成为全栈工程师。
⑦ 移动开发: 包括 IOS 和 Android,你可以开发 APP,也可以开发游戏,需要学习 Java(针对Android)、Objective-C(针对IOS)、Swift(针对IOS) 等。
⑧ 测试(QA): 一款产品问世需要大量的测试才能投放市场,QA(Quality Assurance,译为 品质保证) 人员就是为程序员把关的,如果程序员的作品不符合产品需求或者 Bug 太多,QA 有权驳回,这时就会影响程序员的绩效。QA 不但要能看懂代码(大概理解什么意思),还要掌握一定的测试技巧,更重要的是心思缜密,有耐心有毅力,女生比例很高。
⑨ 大数据: 需要掌握 Java、Python、R 或 Scala 编程语言,并学习 Linux 操作系统、Linux 集群搭建、数据库等,Hadoop、Spark、Hive 等大数据框架的学习是重点内容。
⑩ 人工智能/机器学习/深度学习: 除了需要掌握 Python、R 或 Java 编程语言,还需要学习数学(大都集中在微积分、线性代数、概率与统计几个领域)和算法(例如逻辑回归、深度神经网络、线性回归、K均值、协同过滤等),这是重点内容。
9.2 程序员的待遇
IT行业的待遇比很多行业要高,程序员尤为突出,刚刚毕业的大学生,进入百度、腾讯、阿里巴巴等这些大企业,年薪一般在15万以上,经验丰富的可以拿到20多万,30万的就是神一样的存在,有,但是极少。这是第一梯队,一般重点大学的毕业生才能进入,怎么也得是个一本吧。
拿到融资的创业公司、规模不大的公司、一些国企等给的待遇也不错,年薪也可以超过10万。很多小公司,老板一个人说了算,也没有融资,待遇一般都不会高,一个月几千块钱。这样的公司招人难,进入的门槛低,对学历的要求也可以忽略,能干点活就行。但是往往是这样的公司最折磨人,你什么都需要做,涨薪没有明文规定,老板经常画饼,还会威胁你说完不成任务就走人。每个城市的待遇也不一样,北京、上海、广州、杭州这些一线城市都有大公司,待遇最高;重庆、大连、西安这些二三线城市的待遇就一般了。
至此今天的学习就到此结束了,笔者在这里声明,笔者写文章只是为了学习交流,以及让更多学习C语言基础的读者少走一些弯路,节省时间,并不用做其他用途,如有侵权,联系博主删除即可。感谢您阅读本篇博文,希望本文能成为您编程路上的领航者。祝您阅读愉快!

好书不厌读百回,熟读课思子自知。而我想要成为全场最靓的仔,就必须坚持通过学习来获取更多知识,用知识改变命运,用博客见证成长,用行动证明我在努力。
如果我的博客对你有帮助、如果你喜欢我的博客内容,请点赞、评论、收藏一键三连哦!听说点赞的人运气不会太差,每一天都会元气满满呦!如果实在要白嫖的话,那祝你开心每一天,欢迎常来我博客看看。
编码不易,大家的支持就是我坚持下去的动力。点赞后不要忘了关注我哦!