作者 | 马祎炜 编辑 | 我爱计算机视觉
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【全栈算法】技术交流群
本文只做学术分享,如有侵权,联系删文
本篇分享论文X-Dreamer: Creating High-quality 3D Content by Bridging the Domain Gap Between Text-to-2D and Text-to-3D Generation,通过弥合 Text-to-2D 和 Text-to-3D 生成领域之间的差距来创建高质量的 3D 资产。
论文地址:https://arxiv.org/abs/2312.00085
项目主页:https://xmu-xiaoma666.github.io/Projects/X-Dreamer/
Github主页:https://github.com/xmu-xiaoma666/X-Dreamer
视频介绍
Introduction
近年来,在预训练的扩散模型[1, 2, 3]的开发推动下,自动text-to-3D内容创建取得了重大进展。其中,DreamFusion [4] 引入了一种有效的方法,该方法利用预训练的2D扩散模型 [5] 从文本中自动生成3D资产,从而无需专门的3D资产数据集。DreamFusion引入的一项关键创新是分数蒸馏采样 (SDS) 算法。该算法利用预训练的2D扩散模型对单个3D表示进行评估,例如NeRF [6],从而对其进行优化,以确保来自任何摄像机视角的渲染图像与给定文本保持较高的一致性。受开创性SDS算法的启发,出现了几项工作 [7,8,9,10,11],通过应用预训练的2D扩散模型来推进text-to-3D生成任务。
虽然text-to-3D的生成通过利用预训练的text-to-2D的扩散模型已经取得了重大进展,但是2D图像和3D资产之间仍存在很大的领域差距。这种区别在图1中清楚地展示出来。首先,text-to-2D模型产生与相机无关的生成结果,专注于从特定角度生成高质量图像,而忽略其他角度。
相比之下,3D内容创建与相机参数 (如位置、拍摄角度和视场) 错综复杂地联系在一起。因此,text-to-3D模型必须在所有可能的相机参数上生成高质量的结果。此外,text-to-2D生成模型必须同时生成前景和背景元素,同时保持图像的整体连贯性。相反,text-to-3D生成模型只需要集中在创建前景对象上。这种区别允许text-to-3D模型分配更多的资源和注意力来精确地表示和生成前景对象。
因此,当直接采用预训练的2D扩散模型进行3D资产创建时,text-to-2D和text-to-3D生成之间的域差距构成了显著的性能障碍。
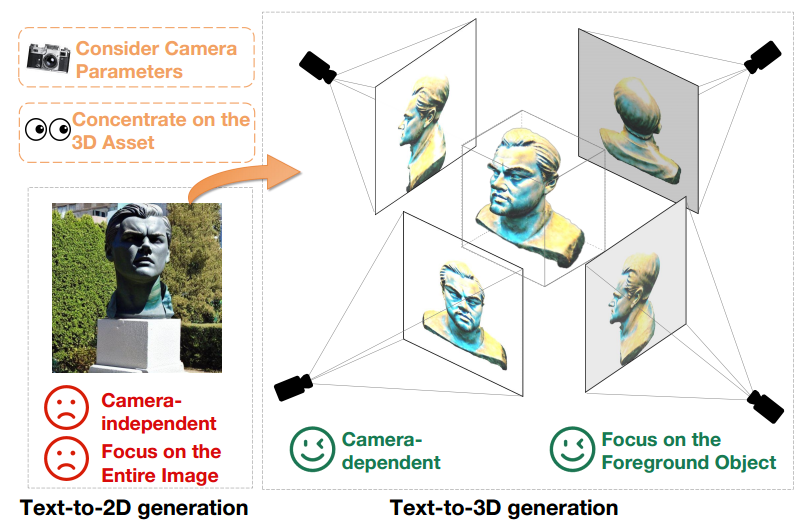
为了解决这个问题,论文提出了X-Dreamer,这是一种用于高质量text-to-3D内容创建的新颖方法,可以有效地弥合text-to-2D和text-to-3D生成之间的领域差距。X-Dreamer的关键组成部分是两种创新设计: Camera-Guided Low-Rank Adaptation (CG-LoRA) 和Attention-Mask Alignment (AMA) 损失。
首先,现有方法 [7,8,9,10] 通常采用2D预训练扩散模型 [5,12] 来进行text-to-3D生成,缺乏与相机参数的固有联系。为了解决此限制并确保X-Dreamer产生直接受相机参数影响的结果,论文引入了CG-LoRA来调整预训练的2D扩散模型。值得注意的是,在每次迭代期间CG-LoRA的参数都是基于相机信息动态生成的,从而在text-to-3D模型和相机参数之间建立鲁棒的关系。
其次,预训练的text-to-2D扩散模型将注意力分配给前景和背景生成,而3D资产的创建需要更加关注前景对象的准确生成。为了解决这一问题,论文提出了AMA损失,使用3D对象的二进制掩码来指导预训练的扩散模型的注意力图,从而优先考虑前景对象的创建。通过合并该模块,X-Dreamer优先考虑前景对象的生成,从而显著提高了生成的3D内容的整体质量。
X-Dreamer对text-to-3D生成领域做出了如下贡献:
论文提出了一种新颖的方法,X-Dreamer,用于高质量的text-to-3D内容创建,有效地弥合了text-to-2D和text-to-3D生成之间的主要差距。
为了增强生成的结果与相机视角之间的对齐,论文提出了CG-LoRA,利用相机信息来动态生成2D扩散模型的特定参数。
为了在text-to-3D模型中优先创建前景对象,论文引入了AMA损失,利用前景3D对象的二进制掩码来引导2D扩散模型的注意图。
Approach
X-Dreamer包括两个主要阶段: 几何学习和外观学习。对于几何学习,论文采用DMTET作为3D表示,并利用3D椭球对其进行初始化,初始化时的损失函数采用均方误差 (MSE) 损失。随后,论文使用分数蒸馏采样 (SDS) 损失和论文提出的AMA损失来优化DMTET和CG-LoRA,以确保3D表示和输入文本提示之间的对齐。对于外观学习,论文利用双向反射分布函数 (BRDF) 建模。具体来说,论文利用具有可训练参数的MLP来预测表面材料。类似于几何学习阶段,论文使用SDS损失和AMA损失来优化MLP和CG-LoRA的可训练参数,以实现3D表示和文本提示之间的对齐。图2展示了X-Dreamer的详细构成。
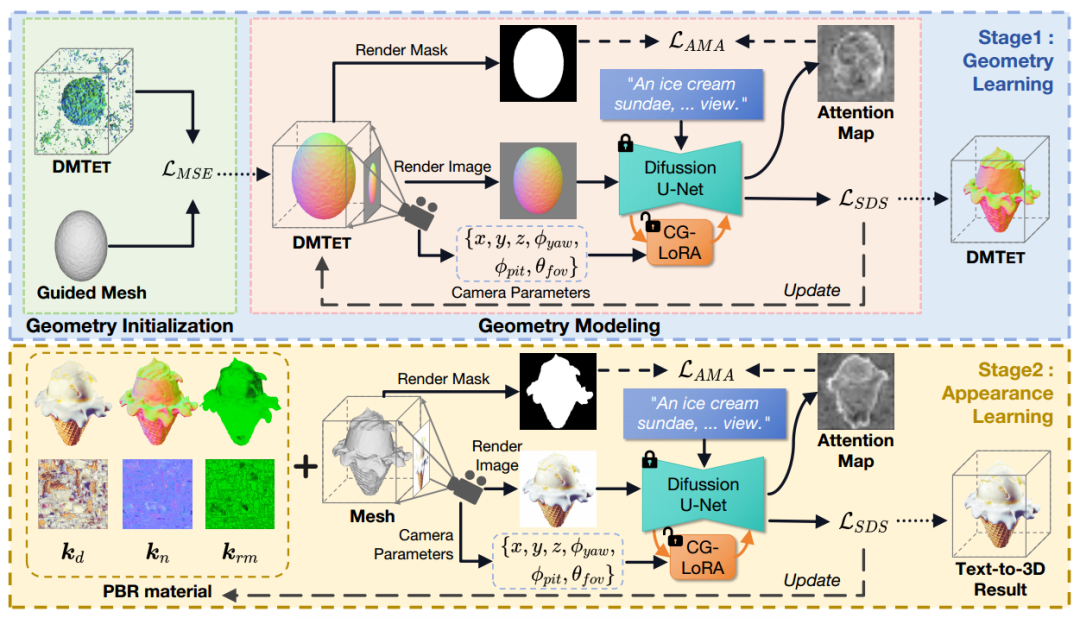
Geometry Learning(几何学习)
在此模块中,X-Dreamer 利用 MLP 网络将DMTET参数化为 3D 表示。为了增强几何建模的稳定性,本文使用3D椭球体作为DMTET的初始配置。
对于属于四面体网格的每个顶点,本文训练来预测两个重要的量:SDF值和变形偏移量。为了将初始化为椭球体,本文采样了均匀分布在椭球体内的N个点,并计算相应的SDF值。
随后,利用均方误差(MSE)损失来优化。该优化过程确保有效地初始化DMTET,使其类似于3D椭球体。MSE损失的公式如下:
初始化几何图形后,将DMTET的几何图形与输入文本提示对齐。具体的操作方法是通过使用差分渲染技术,在给定随机采样的相机姿势c的情况下,从初始化的DMTET生成法线映射n和对象的掩码m。随后,将法线映射n输入到具有可训练CG-LoRA嵌入的冻结的Stable Diffusion模型(SD)中,并使用SDS损失更新中的参数,定义如下:
其中,表示SD的参数,为在给定噪声水平和文本嵌入的情况下的SD的预测噪声。此外,,其中,表示从正态分布采样的噪声。、和的实现基于DreamFusion[4]。
此外,为了将SD集中于生成前景对象,X-Dreamer引入了额外的AMA损失,以将对象掩码m与SD的注意力图对齐,如下所示:
其中表示注意力层的数量,是第i个注意力层的注意力图。函数用于调整渲染出来的3D对象掩码的大小,确保它的尺寸与注意力图的尺寸对齐。
Appearance Learning(外观学习)
在获得3D对象的几何结构后,本文的目标是使用基于物理的渲染(PBR)材料模型来计算3D对象的外观。材料模型包括扩散项,粗糙度和金属项,以及法线变化项。对于几何体表面上的任一点,利用由参数化的多层感知机(MLP)来获得三个材料项,具体可以表示如下:
其中,表示利用哈希网格技术进行位置编码。之后,可以使用如下公式计算渲染图像的每个像素:
其中,表示从方向渲染3D物体表面的点的像素值。表示由满足条件的入射方向集合定义的半球,其中表示入射方向,表示点处的表面法线。对应于来自现成环境图的入射光,是与材料特性(即)相关的双向反射分布函数(BRDF)。通过聚合所有渲染的像素颜色,可以获得渲染图像。与几何学习阶段类似,将渲染图像输入SD,利用SDS损失和AMA损失优化 。
Camera-Guided Low-Rank Adaptation(CG-LoRA)
为了解决text-to-2D和text-to-3D的生成任务之间存在的领域差距而导致的次优的3D结果的生成,X-Dreamer提出了Camera-Guided Low-Rank Adaptation。如图3所示,利用摄像机参数和方向感知文本来指导CG-LoRA中参数的生成,使X-Dreamer能够有效地感知摄像机的位置和方向信息。

具体的,给定文本提示和相机参数[^1],首先使用预训练的文本CLIP编码器和可训练的MLP,将这些输入投影到特征空间中:
其中,和分别是是文本特征和相机特征。之后,使用两个低秩矩阵将和投影到CG-LoRA中的可训练降维矩阵中:
表示一维向量。表示二维矩阵。
其中,和是CG-LoRA的两个降维矩阵。函数用于将张量的形状从 变换为 。[^2] 和是两个低秩矩阵。
因此,可以将它们分解为两个矩阵的乘积,以减少实现中的可训练参数,即 ; , 其中 ,,,
,是一个很小的数字(如:4)。
根据LoRA的构成,将维度扩展矩阵初始化为零,以确保模型开始使用SD的预训练参数进行训练。因此,CG-LoRA的前馈过程公式如下:
其中, 表示预训练的SD模型的冻结参数,是级联运算。在本方法的实现中,将CG-LoRA集成到SD中注意力模块的线性嵌入层中,以有效地捕捉方向和相机信息。
Attention-Mask Alignment Loss(AMA Loss)
SD被预训练以生成2D图像,同时考虑了前景和背景元素。然而,text-to-3D的生成需要更加重视前景对象的生成。鉴于这一要求,X-Dreamer提出了Attention-Mask Alignment Loss(AMA损失),以将SD的注意力图与3D对象的渲染的掩码图像对齐。
具体的,对于预训练的SD中的每个注意力层,本方法使用查询图像特征 和关键CLS标记特征 来计算注意力图。计算公式如下:
其中, 表示多头注意力机制中的头的数量,表示注意力图,之后,通过对所有注意力头中注意力图的注意力值进行平均来计算整体注意力图的值。
由于使用softmax函数对注意力图值进行归一化,因此当图像特征分辨率较高时,注意力图中的激活值可能变得非常小。但是,考虑到渲染的3D对象掩码中的每个元素都是0或1的二进制值,因此将注意力图与渲染的3D对象的掩码直接对齐不是最佳的。为了解决这个问题,论文提出了一种归一化技术,该技术将注意力图中的值映射到(0,1)之间。此归一化过程的公式如下:
其中, 代表一个小的常数值(例如),来防止分母中出现0。最后,使用AMA损失将所有注意力层的注意力图与3D对象的渲染的掩码对齐。
Experiments
论文使用四个Nvidia RTX 3090 GPU和PyTorch库进行实验。为了计算SDS损失,利用了通过Hugging Face Diffusers实现的Stable Diffusion模型。对于DMTET和material编码器,将它们分别实现为两层MLP和单层MLP,隐藏层维度为32。
从椭球体开始进行text-to-3D的生成
论文展示了X-Dreamer利用椭球作为初始几何形状的text-to-3D的生成结果,如图4所示。结果证明X-Dreamer具有生成高质量和照片般逼真的3D对象的能力,生成的3D对象与输入的文本提示准确对应。

从粗粒度网格开始进行text-to-3D的生成
虽然可以从互联网上下载大量粗粒度网格,但由于缺乏几何细节,直接使用这些网格创建3D内容往往会导致性能较差。然而,与3D椭球体相比,这些网格可以为X-Dreamer提供更好的3D形状先验信息。因此,也可以使用粗粒度引导网格来初始化DMTET,而不是使用椭球。如图5所示,X-Dreamer可以基于给定的文本生成具有精确几何细节的3D资产,即使所提供的粗粒度网格缺乏细节。

定性比较
为了评估X-Dreamer的有效性,论文将其与四种SOTA方法进行比较: DreamFusion [4],Magic3D [8],Fantasia3D [7] 和ProlificDreamer [11],如图6所示。当与基于SDS的方法进行比较时 [4,7,8],X-Dreamer在生成高质量和逼真的3D资产方面优于他们。此外,与基于VSD的方法 [11] 相比,X-Dreamer产生的3D内容具有相当甚至更好的视觉效果,同时需要的优化时间明显减少。具体来说,X-Dreamer的几何形状和外观学习过程只需要大约27分钟,而ProlificDreamer则超过8小时。

消融实验
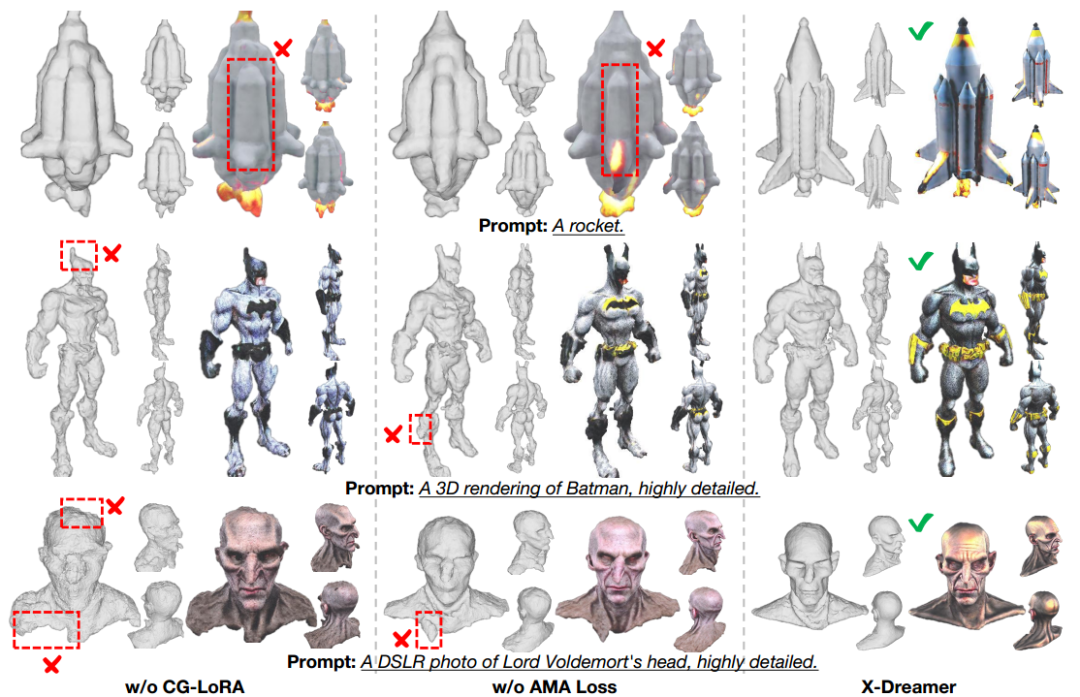
模块消融
为了深入了解CG-LoRA和AMA损失的能力,论文进行了消融研究,其中每个模块单独加入以评估其影响。如图7所示,消融结果表明,当CG-LoRA被排除在X-Dreamer之外时,生成的3D对象的几何形状和外观质量显著下降。此外,X-Dreamer缺失AMA损失也对生成的3D资产的几何形状和外观保真度产生有害影响。这些消融实验为CG-LoRA和AMA损失在增强生成的3D对象的几何形状、外观和整体质量方面的单独贡献提供了有价值的研究。
有无AMA损失的注意力图比较
引入AMA损失的目的是将去噪过程中的注意力引导到前景对象。这个是通过将SD的注意力图与3D对象的渲染掩码对齐来实现的。为了评估AMA损失在实现这一目标方面的有效性,论文在几何学习和外观学习阶段可视化了有和没有AMA损失的SD的注意力图。如图8所示,可以观察到,加入AMA损失不仅会改善生成的3D资产的几何形状和外观,而且会将SD的注意力特别集中在前景对象区域上。可视化证实了AMA损失在引导SD注意力方面的有效性,从而在几何和外观学习阶段提高了质量和前景对象的聚焦。

Conclusion
这项研究引入了一个名为X-Dreamer的开创性框架,该框架旨在通过解决text-to-2D和text-to-3D生成之间的领域差距来增强text-to-3D的生成。
为了实现这一点,论文首先提出了CG-LoRA,这是一个将3D相关信息(包括方向感知文本和相机参数)合并到预训练的Stable Diffusion(SD)模型中的模块。通过这样做,本文能够有效地捕获与3D领域相关的信息。此外,本文设计了AMA损失,以将SD生成的注意力图与3D对象的渲染掩码对齐。AMA损失的主要目标是引导text-to-3D模型的焦点朝着前景对象的生成方向发展。
通过广泛的实验,本文彻底评估了提出方法的有效性,实验始终证明了X-Dreamer能够根据给定的文本提示生成高质量和真实的3D内容。
References
[1] Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. Advances in neural information processing systems, 33:6840–6851, 2020.
[2] Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. In International conference on machine learning, pages 2256–2265. PMLR, 2015.
[3] Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. arXiv preprint arXiv:2011.13456, 2020.
[4] Ben Poole, Ajay Jain, Jonathan T Barron, and Ben Mildenhall. Dreamfusion: Text-to-3d using 2d diffusion. arXiv preprint arXiv:2209.14988, 2022.
[5] Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, et al. Photorealistic text-to-image diffusion models with deep language understanding. Advances in Neural Information Processing Systems, 35:36479–36494, 2022.
[6] Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis. Communications of the ACM, 65(1):99–106, 2021.
[7] Rui Chen, Yongwei Chen, Ningxin Jiao, and Kui Jia. Fantasia3d: Disentangling geometry and appearance for high-quality text-to-3d content creation. arXiv preprint arXiv:2303.13873, 2023.
[8] Chen-Hsuan Lin, Jun Gao, Luming Tang, Towaki Takikawa, Xiaohui Zeng, Xun Huang, Karsten Kreis, Sanja Fidler, Ming-Yu Liu, and Tsung-Yi Lin. Magic3d: High-resolution text-to-3d content creation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 300–309, 2023.
[9] Gal Metzer, Elad Richardson, Or Patashnik, Raja Giryes, and Daniel Cohen-Or. Latent-nerf for shape-guided generation of 3d shapes and textures. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12663–12673, 2023.
[10] Haochen Wang, Xiaodan Du, Jiahao Li, Raymond A Yeh, and Greg Shakhnarovich. Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12619–12629, 2023.
[11] Zhengyi Wang, Cheng Lu, Yikai Wang, Fan Bao, Chongxuan Li, Hang Su, and Jun Zhu. Prolificdreamer: High-fidelity and diverse text-to-3d generation with variational score distillation. arXiv preprint arXiv:2305.16213, 2023.
[12] Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bjorn Ommer. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022.
[^1]: 变量 分别表示x、y、z坐标、方位角、摄像机俯仰角和视场。滚动角度设置为0,以确保渲染图像中对象的稳定性。
[^2]: 表示一维向量。表示二维矩阵。
① 全网独家视频课程
BEV感知、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、协同感知、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)
 视频官网:www.zdjszx.com
视频官网:www.zdjszx.com
② 国内首个自动驾驶学习社区
近2000人的交流社区,涉及30+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(2D检测、分割、2D/3D车道线、BEV感知、3D目标检测、Occupancy、多传感器融合、多传感器标定、目标跟踪、光流估计)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多模态感知、Occupancy、多传感器融合、transformer、大模型、点云处理、端到端自动驾驶、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向。扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】平台矩阵,欢迎联系我们!
