1. LLM还无法自我纠正推理
引言
LLM具有强大的文本生成能力,但生成内容的准确性和适当性的担忧仍然存在。目前 self-correction方法用来补救这类问题。自我纠正:llm基于对他们之前的输出的反馈来完善响应。
我们期望:在一个数学推理中,LLM解决了一个复杂的问题,但在某个计算步骤出现错误,自我纠正场景期待模型认识到潜在的错误,重新审视问题,纠正错误,从而产生准确方案。
然而,如果一个LLM拥有自我纠正能力,为什么不从最初的尝试中简单的提供正确的答案?本文对目前的自我纠正概念进行怀疑与反驳。内在自我纠正,是在没有外部反馈的情况下,利用内在能力而纠正,内部反馈依赖于模型的固有知识和参数重新评估是输出,而外部反馈包含了人类和其他模型的输入,或外部工具和知识来源等。研究表明,大多数情况,自我修正后的结果甚至会恶化。之前的改进都是基于使用真实标签来指导自我纠正过程,当这类标签不可用时,改进也因此消失。另外,研究了多智能体辩论来提升推理能力,结果显示当考虑相同响应时,其有效性并不优于self-consistency。
另一方面,虽然自我纠正在增强推理方面有局限性,但他在其他任务仍展示了有希望的结果,如改变风格或提高反应的适当性。因此需要理解其中的细微差别,我们认为自我纠正是一种事后提示的形式,其中涉及了LLM的反应。真正有益的情况是——缺乏标准提示的指示和反馈时,或初始指令过于拙劣。
实验与分析
1. 带有真实反馈的自我纠正
使用现有的自我纠正方法(设置为使用标签指导自我修正过程),来检验在推理任务上的性能有效性。
数据集: 选择之前有过自我纠正增长的数据集,包括GSM8K(1319个不同语言的小学数学单词测试集)、CommenSenseQA(多选题,测试常识推理)、HotpotQA(开放多跳问答数据集,100个问题)
提示: 三步提示策略
- 促进模型初始化生成(即标准提示的结果)
- 提示模型回顾上一代并生成反馈
- 通过反馈提示模型重新回答原来的问题。

模型: gpt-3.5-turbo-0613(0301版本总认为初始版本正确)、GPT-4(随机抽样200、200、100问题)
温度设置1.0,最多两轮自我纠正,使用正确标签来决定何时停止纠正循环。
结果:
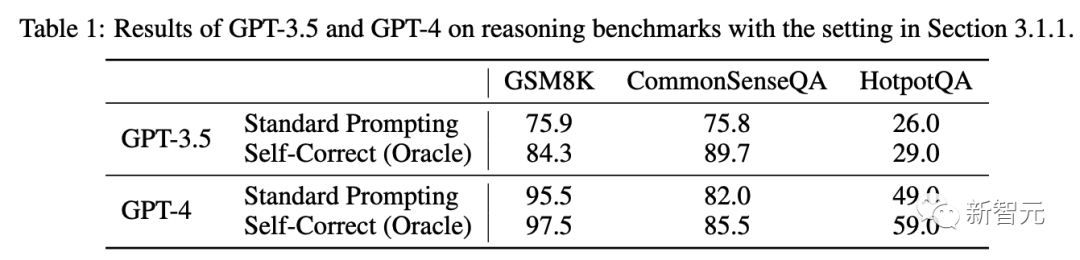
与之前工作一致,自我纠正确实带来了显著的性能改进。
**思考:**虽然没有利用任何外部资源或工具,但我们遵循了之前的工作,使用正确的标签来决定何时停止自我校正循环。实际上,当LLM回答数学问题时,可能是不知道正确答案的,因此需要重新考虑。
因此,设计了一个基于随机猜测的baseline,纠正行为不是由LLM进行,而是从剩余选项随机猜测。对于CommonSenseQA,每个题目有5个选项。如果第k轮(从0开始)的精度为x,则下一代的进度为x+(1-x)/(5-k)

2轮后,其性能与自校正相当甚至更好,4轮后,其准确率达到100%。很明显,这样的随机基线不能被视为有效的校正方法。
不过,使用标签获得的结果仍然可能起到预言机的作用,表明存在可以判断答案正确性的完美验证者。这在代码生成任务中是可行的(可以利用执行器来验证是否成功)。但对于数学问题,若知道答案则没必要再使用LLM。
2.内在自我纠正
我们删除了决定何时停止并评估性能的标签。

此时,经过自我修正后,模型的性能在所有基准中都下降了
为什么性能反而下降?
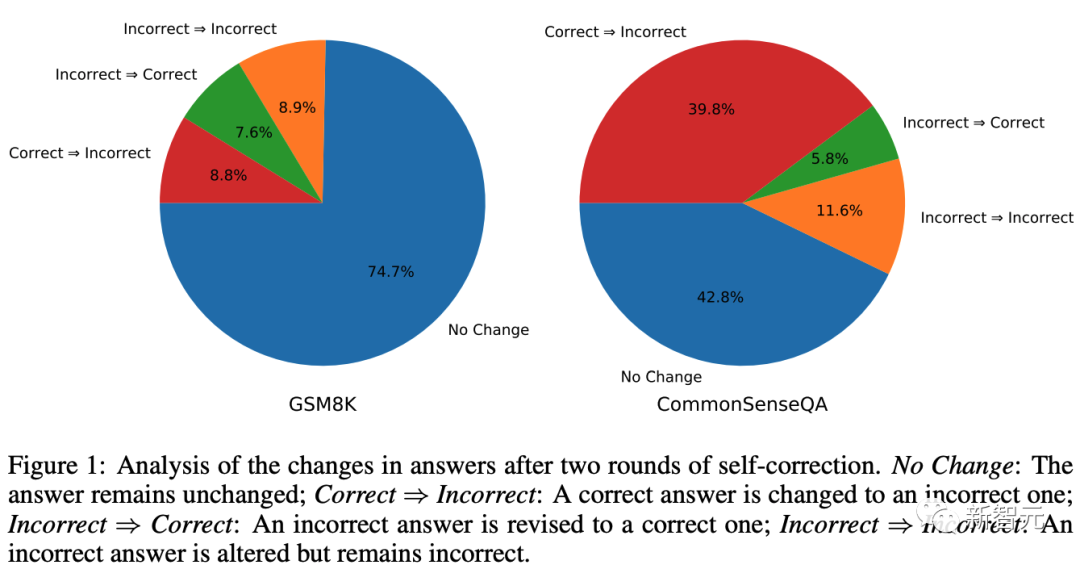

实证分析: 对于GSM8K,74.7%的概率下模型保留其初始答案。在其余实例中,模型更有可能将正确答案修改为错误答案,而不是将错误答案修改为正确答案。
对于CommonSenseQA,GPT-3.5改变其答案的可能性更高。造成这种情况的主要原因是CommonSenseQA中的错误答案选项通常看起来与问题有些相关,并且使用自我纠正提示可能会使模型偏向于选择另一个选项,从而导致较高的「正确⇒错误」比率。
而最初的表1 利用真实标签,防止了模型将正确答案改为错误答案。如何防止这种「修改错误」的发生,实际上是确保自我纠错成功的关键。
**直观解释:**如果该模型与精心设计的初始提示相匹配,那么在给定提示和具体的解码算法的情况下,初始响应应该已经是最佳的。引入反馈可以被视为添加额外的提示,可能使模型偏向于生成适合该组合输入的响应。在内在自我纠正设置中,在推理任务中,这种补充提示可能不会为回答问题提供任何额外的优势。事实上,它甚至可能使模型偏离对初始提示产生最佳回复,从而导致性能下降。
其他提示的结果
为防止研究人员测试的自我修正提示不理想? 找到一个在特定基准上增强模型的提示是完全可能的,但是与本文的内在自我纠正则不一致,这更类似少样本设置。同时我们也测试其他的提示符,性能仍然没有提高。
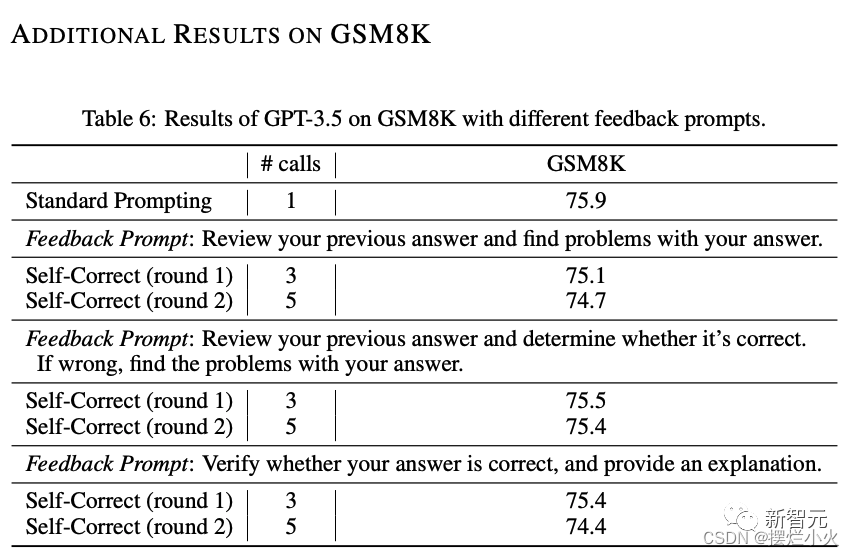
我们的重点并不是解决提示来影响模型,“是否存在自我纠正的提示来提高模型”,而是“大语言模型真的可以基于固有能力自我纠正其推理吗?”
多智能体辩论和自一致性
自我纠正的另一潜在方法是允许模型通过多个模型调用进行批判和辩论

这类方法获得了显著的改善,且相同数量的回答下,多智能体辩驳低于多数投票的性能。
实际上,这类改善归因于自我一致性,如果是要证明自我修正特性,需要排除多代选择的影响。
作为事后提示的自我纠正
要把握自我纠正的本质,从形式上,自我纠正类似于一种事后提示方法,是基于LLM的回答之上的,此过程为事后提示工程。当自我纠正可以提供事前提示无法提供的有价值的指导或反馈时,就会出现自我纠正增强模型响应的情况。 例如,当目标是使响应更安全时,指导模型仅使用事前提示在第一次尝试中生成完全无风险的响应可能具有挑战性。在这种情况下,自我纠正可以作为通过细粒度事后检查来增强响应安全性的一种手段。
使用精致的事后提示打败错误的事前提示的回答,当做为自我纠正是没有用的。需要公平设置事前事后的提示。

研究人员精心设计的提示「标准提示(研究人员的)」优于之前研究的自我校正后结果。
此外,当研究人员利用他们的提示来改进研究人员的输出时,性能甚至会下降。
讨论
- 自我纠正仍然是有益的对于对齐有特定偏好的回答。(改变风格、增加安全性)
- 利用外部反馈进行纠正(搜索引擎、外部工具)。在日常,往往会提供回答引导GPT产生想要的话题,偶尔是可以纠正的,特别是我们的提示是高质量时。
- 使用自我一致性作为自我纠正的方法。这表明在LLM搜索空间中可能存在正确答案,可以强大的验证或引导脱离歧途。
- 事后提示的代价和延迟高于事前提示,将重点放在事前提示工程是有效的。
- 在比较自我纠正方法时需要注意:推理成本、响应次数相同、事前事后设置需精心公平、判断是否作弊(使用正确答案)
2. GPT-4不知其错误:对推理问题迭代提示的分析
引文
面对观点:基于正确性的验证应当比生成更容易,因此LLM可以自我批评并迭代的改进自己的解决方案。实际这与LLM无关,因为它们做的是近似检索。
图着色问题: NP-完全推理问题,包含AI命题可满足性、约束满足性、调度和分配实际问题
本文研究LLM在图着色背景下迭代意识的有效性。我们的任务是1. 解决大量随机图着色问题 2. 分别验证候选着色的正确性。该实证研究对目前最先进的LLM自我批评能力提出质疑:
- LLM不擅长图着色问题
- LLM不擅长验证解决方案,因此在迭代时批评生成的解决方案是无效的
- 批评的正确性和内容,无论由LMM还是外部求解器生成,似乎都和迭代提示性能无关
- 观察到的有效性很大程度是因为正确的解决方案碰巧出现在提示的top-k补全中
方法
图着色问题
「着色问题」是非常经典的推理问题,即使难度不大,答案也足够多样性,而且答案的正确性很容易进行验证。
多样性的结果使得LLM的训练数据很难覆盖全,尽量避免了LLM的训练数据被污染的可能。
现有的图着色基准集包含问题过于复杂,由于没有那么大上下文窗口。我们构建自己的数据集,使用GrinPy处理常见的图形操作,每个图都用Erd˝os–Rényi method (p = 0.4)方法构造,一旦找到成功的候补对象,它就被编译为DIMACS格式,并附上色数的注释。我们生成100个示例,平均每个图24条边,节点数为10-17

首先将平面图传递给GPT-4作为生成器(1),这将返回一个建议的着色(2)。GPT4将作为验证器判断颜色是否正确,如果错误,则通过反提示(3)提供反馈和以前的历史记录,这将在下一代使用(4)。每个新的着色都将被GPT4评估,若回答正确或超过15次,则结束并通过验证器。
迭代返回提示的架构
提示生成器(Prompt Generator):
这个提示词生成器会选取一个DIMACS实例,并将每条边翻译成一个句子,然后将整体包裹在一组通用指令中,从而构造出一个自然语言提示。
研究人员有意缩小不同实例提示之间的差异,以减少研究人员向LLM泄露的问题特定信息。各种类型提示的示例可以在附录中找到。

LLM: 温度=0,系统提示:"You are a constraint satisfaction solver that solves various CSP problems
可扩展性: 容易扩展到其他CSP问题的领域,提供了一种添加新领域描述的方法,即插即用
返回提示的生成

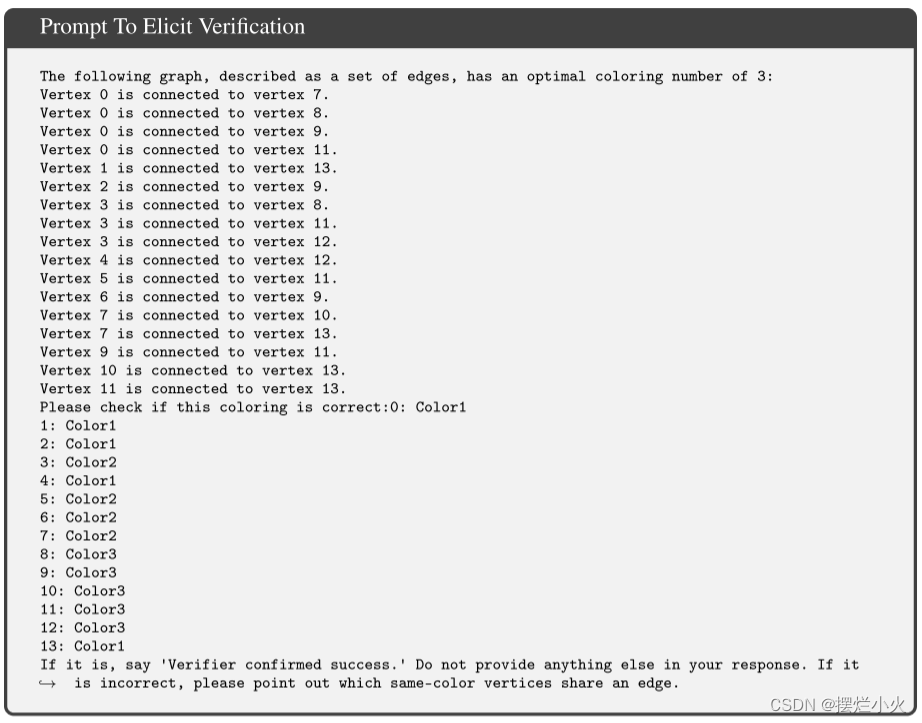
验证模式下,LLM接受不同类型的结果,它的任务是验证正确性和最优性,以及是否每个点都已分配,若存在矛盾的边则任务错误。
为了比较每个点,研究人员还构建了一个能够列出每一条矛盾边的验证器。
由于LLM的响应也是自然语言形式的,研究人员首先将它们翻译成便于分析的格式。为了使这个过程更加一致,研究人员设计了最初的提示,以描述一个模型需要遵循的精确输出格式。然后,该响应会被评估其正确性。如果验证者说答案正确则停止,若超出15次则放弃,否则就返回提示,附加到以前的消息历史中作为新提示。构造反向提示的案例:
- None: A single iteration baseline. No backprompting.
- Pass/Fail: The only feedback given is that the answer was incorrect.
- First: Only the first error encountered is returned.
- Full: A comprehensive list of errors.
- LLM: Feedback is provided by the language model through a separate prompt, given in the
appendix. We pass any and all response back to the generator, regardless of its validity or
correctness.
6-8. Top 5: With temperatures 0.5, 1, and 1.5, query the LLM for n = 5 responses.
- Top 15: With a temperature of 1, query the LLM for n = 15 responses.


验证
为了更深入了解LLM的验证能力,研究人员研究了它们在找出提出的着色方案中的错误方面的表现。
直观来说,这些错误应该很容易识别:如果组成一个边的两个顶点共享一个颜色,则立即返回该边。从算法角度来看,所有需要做的就是遍历所有边,并将每个顶点的颜色与其对应顶点的颜色进行比较。
研究人员使用相同的分析流程,但构建了一个研究人员称为color_verification的新域。LLM被引导去检查着色的正确性、最优性以及是否每个顶点都已经被赋予了一个颜色。如果着色是不正确的,它被指示列出着色中的错误,即如果两个连接的节点共享一种颜色,就返回该边以表示该错误。没有给出返回提示(backprompts)。
正确(Correct):通过迭代的、随机的贪婪算法生成的没有错误的最优着色方案(使用预先计算的色数以确保最优性)。
缺失(Ablated):将先前一组着色方案中的一个随机节点改变为其邻居的颜色。
非最优(Non-optimal):在正确的集合中,随机选择一个颜色部分重新着色为一个新的色调。
随机(Random):完全随机分配的颜色,不同颜色的数量等于图的色数。
LLM:从先前实验中LLM生成的输出中随机选取的着色方案。
结果
作为自我批评的反提示
当不给予任何反馈时为16%,若LLM验证反馈时只有1%。这可能是由于我们缺少停止条件,即使反向提示输出了正确颜色也不会被注意到,而产生虚假反馈。
外部的验证器初看起来很有效,但如果GPT4在听取并改进的话,越精确的提示应该效果更好,然而后三者一致
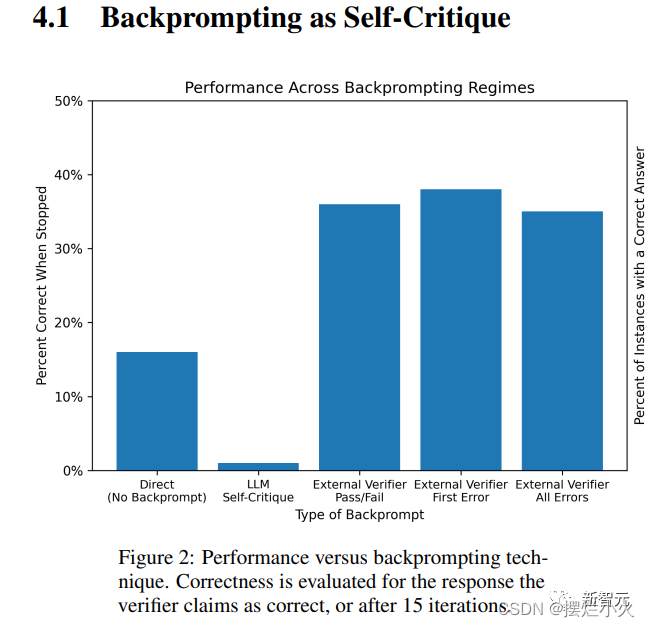
如果在反向提示出现过正确案例就视为正确的话,可以获得40%的结果。这样来看反馈的重要性不如迭代次数重要。此时使用更高的温度接受多个独立的反馈,n=5时性能接近,而当n=15(t=1)达到40%,即猜测和精心设计反馈一样有效

LLM的验证
测试GPT4在相同实例上验证着色的能力,每个实例5个不同类型方案。结果与之前类似:
模型几乎没有将任何答案标记正确,100个最优方案只有2个被标记。在500个着色方案里有118个是正确的,但他只认为30个正确,且其中只有5是真正正确的。总体而言,这一模式保持不变。在不到10%的案例中,LLM给出了「正确」、「非最优」或「缺少赋值」的反应。在这些情况中,行为看似有些随机。在大约四分之一的实例中,它用「这是不正确的」验证作出回应,而解释与现实相符,而且它只通过指明不超过一个边来实现这一点,从而最小化了错误陈述某事的机会。

当域的错误率增加时,幻觉比例下降。也就是说,当有更多的不正确的边时,模型更有可能指出其中出错的情况。
- 边幻觉比顶点幻觉更常见,通常会选择颜色相同但没有连接的边,认为其是连接的
- 顶点幻觉:
结论:即使这个领域有常识性,但LLM的验证能力很弱
反提示链之中
为探索LLM使用或不使用什么信息,检查了GPT4在反提示链中回答的变化。我们比较三种类型的提示:
提供一个边的错误、提供所有边的错误、随机选择一个正确边当做错误(检查是否盲目遵循修改建议)

性能变化不大,且GPT纠正了大多数被指出的错误,但这并不是他发现了真正的错误,而是盲目的修复,而忽略正确性
结论
LLM在验证图着色问题的解决方案上表现非常差,这是自我批评的关键。
带有自我批评的LLM比直接生成单个答案的LLM表现更差。然而当外部有可表明正误的验证器时,迭代意识才有帮助,同时迭代提示的内容并不重要,和多次迭代随机的能力一般。
因此对迭代提示的有效性和LLM推理能力有质疑
3. LLM能通过自我批评改进自己的计划吗?
前言
我们想研究LLMs在规划环境下的验证与自我批评能力。
之前的研究认为LLM可以批评它们的候选一代并迭代,不断精炼。然而值得怀疑的是推理任务的复杂性和LLM是无关的,它只进行了近似检索
我们研究最简单的规划问题,采用一个规划系统,该系统在生成和验证中使用相同的LLM,称为LLM+LLM系统。生成器LLM不断产生候选计划,验证者LLM给出反馈,直到验证者LLM批准此计划或超出阈值。我们提出实证评估:1. 自我批评对整个系统计划生成性能的影响 2. 验证者LLM与真实标签的性能比较 3. 批评LLM生成时 不同反馈水平对整体系统性能的影响。LLM使用GPT-4
我们发现自我批评会降低计划生成性能,这归因于验证者LLM的大量误报,而反馈的类型并不会显著影响计划生成性能,因质疑LLM作为迭代的能力和作为验证器的能力
PDDL问题:

方法
LLM+LLM规划系统
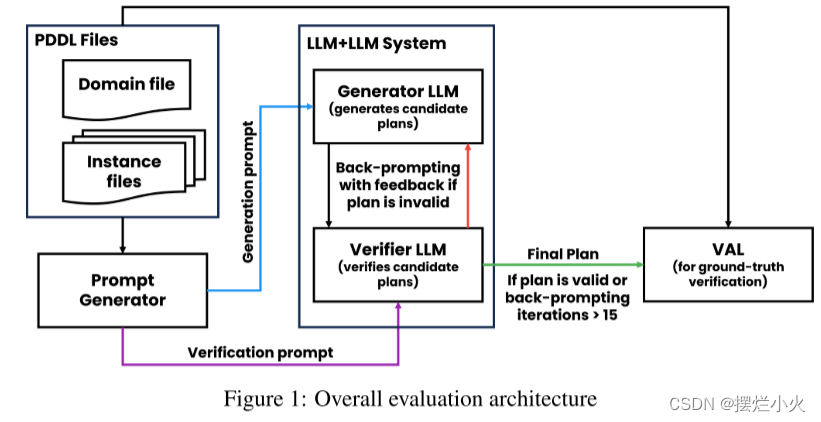
给定一个实例,生成器LLM生成后续按计划,验证器LLM确定其正确性。若不正确,则验证器提供反馈,详细说明失败原因,再转发给生成器促进新的候选计划;若正确或提示迭代次数超过15次,则停止生成
提示生成器
提示生成器利用PDDL域和实例文件以自然语言生成所需提示(对生成器、验证器不同)
生成器:one-shot提示,提出域描述和一个示例+计划,新的实例(从实例集随机选择)
验证器:zero-shot,给出与描述,查询实例和对应计划
评估与分析
在Blocksworld(常识性规划域)上评估我们的规划系统,生成100个随机实例。为了提供LLM最终计划的正确性真实标签,使用外部完美验证器 VAL(人机共同决策的自动计划验证工具)。 LLM选择GPT4 温度=0
自我批评对计划生成的影响
baseline: LLM+VAL(若计划不足,则反馈给生成器)、纯生成器LLM(无反向提示)
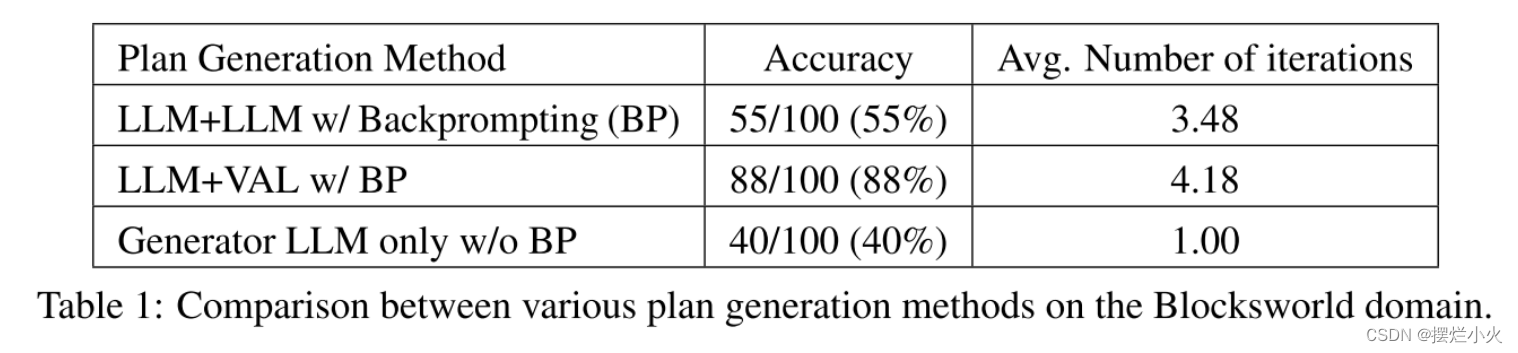
显然LLM+LLM<LLM+VAL<only。优于仅存在生成器的原因可能并不归功于验证器,反向提示本身也为生成器提供了多个机会,这是一个因素。LLM+LLM的低性能可能是因为验证器产生大量的类型-1错误(误报,将错认为正),而加入外部合理验证器可以显著提高性能。
自我批评验证者的分析
使用LLM 验证者做二元评估(计划是否有效)来评估性能。

对于100个例子,准确识别61个,但其中有38个是因为FP假阳性出错(即 对无效的验证有效)
反馈级别对计划生成的影响
在四个反馈提示上评估影响:
- 无反馈
- 二元反馈: 即告知计划是否有效
- 不可执行行动反馈: 若计划无效,显示第一个不可执行的动作和未满足的目标条件(类似VAL)
- 开放条件反馈: 会展示多个未满足先决条件和目标条件
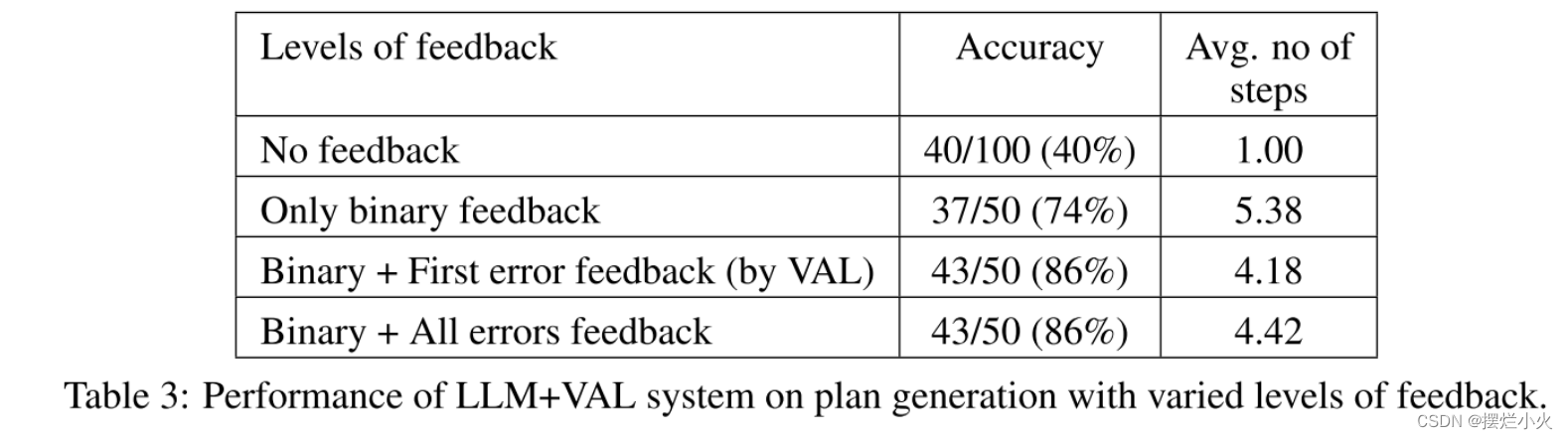
有反馈比无反馈明显提升,但反馈数量似乎对LLM提升很小,只要二元反馈是准确的,LLM有足够的机会生成计划
结论与未来展望
通过使用规划问题来研究LLM的自我批评能力,发现会存在大量的误报,对整个系统有害。且反馈无论二进制还是相信并无明显影响,说明核心问题在于LLM的二分类验证功能,而不是反馈粒度
未来,我们计划在实例数、域数和提示方法(如chain-of-thought)方面进行更广泛的实验。