前言:
观看视频有感,随手记录一下。并且对于自己身为一个前端工程师,连一个浏览器的页面渲染的大致过程都无法正确表达出来,深深感到羞愧。
tips: 本文是纯新手向,只会以自己初学的理解讲解大致过程,给和我有同样疑问的新手提供一个大致的思路,并且会同步讲解其它额外相关知识。本文并不会牵扯源码级别的实现,请各位深知其中细节大佬键⌨️下留情。
<hr/>
一.当你刚打开浏览器时
- 双击浏览器图标
- 紧接着系统分配给浏览器一块内存
- 随后浏览器创建一个进程准备工作(progress)
以Mac为例子,在聚焦内搜索活动监视器,就会出现类似于 Windows 任务管理器很相似的窗口,可以看到这台机器上运行着已经开启的 Chrome 应用进程。
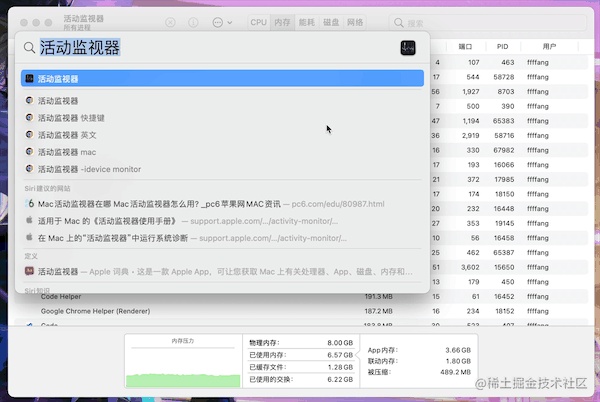
二.浏览器启动后
恭喜你获得了一个空白的 Chrome 首页,但是没想到吧~它此时已经同步开启了多个进程来协助它完成后续工作。
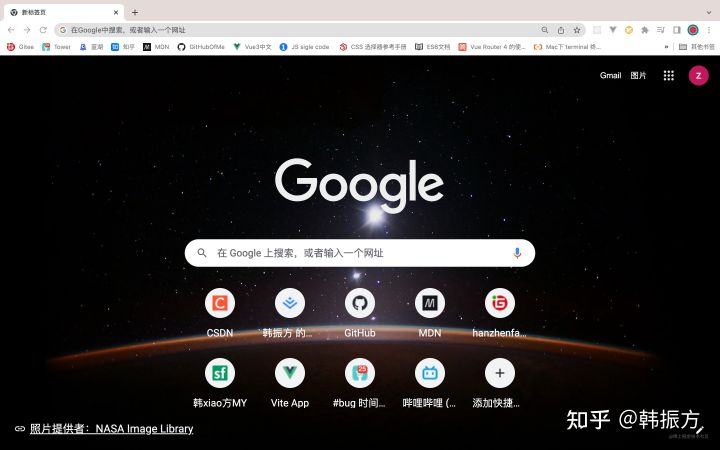
- 找到 Chrome 右上角头像旁边的三个点点,找到更多工具,点击任务管理器,就可以看到此时 Chrome 浏览器运行时,同步开启了哪些进程。

- 你自定义的拓展工具也会各自开启一个进程。

- 回过头看一下这些进程分别代表着什么

浏览器进程(主进程,但不负责Tab)主要控制-> 地址栏、书签、后退、前进,并负责进行浏览器和其它进程之间的调度协调。
主进程又细分为:
1. GPU进程 (负责整个浏览器页面的渲染,包含顶部的搜索栏,和Tab标签页的内容)
2. Network:网络进程 (看名字就显而易见,负责网络请求的处理)
3. Storage:缓存进程 (顾名思义,管理缓存之类)
4. Audio: 音频进程 (顾名思义)
5. Data Decoder :数字解码进程
6. Plugin :在这里没有明确写出 Plugin 这几个字,其实它就是我们浏览器
- 可以很清晰的看到,每个 Tab 页都有属于自己的一个进程,这也就保证了某一个页面卡死,但是并会不影响其它页面的正常工作。
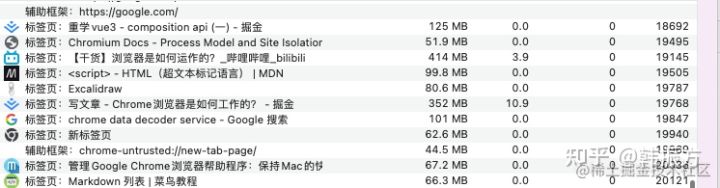
但是这样一种一个 Tab 一个进程分配原则是一定的吗?并不一定,这取决于你浏览器设置的进程模型是什么。这里贴一下 "https://link.segmentfault.com/?enc=mKu%2B32caRJN8QJbfXDww7Q%3D%3D.SXDFRuOf%2B5gkCyqsrUg3%2BANaReI0J3qMdOKfq2bZbzdAox23obhsMgj3piiiRjrgOmyVX48rXTsWQkoH790wEjqExfjQz7%2F%2Br5IJedrcsHusqPYgChOWJq5ken2TsBUuIUEesLYycfnB%2Bfi2eaZbrgsllPvmVJ5VNxCrbNLTtX8%3D">Chromium文档。

其中 Chrome 默认使用的的就是第一个 Process-per-site-instance 模型,可以简单的理解为每个 Tab 都会分配一个进程去处理。另外三个模型可以自行了解,这里我暂时还未搞懂,就不误导大家了。
三.当你在url地址栏输入网站敲下回车后
- 此时浏览器线程会开启一个 UI 线程去捕捉你输入的到底是关键字还是域名。 这里假设你输入的是 http://www.baidu.com (输入的是域名,并不是关键字。)
- UI 线程判断你输入的是域名,然后它会把用户输入的信息通知给Network 进程。(这里就需要了解一下进程之间的通讯是通过 IPC inter process communication)
- Network 进程收到通知后,会去请求 DNS(domain name system)域名解析系统,解析域名相对应的 IP 地址。
- 如果你输入的是关键词,那么 Network 进程会使用默认的搜索引擎去查找相对应的输入内容。
- 当网络进程拿到站点服务器返回的数据后,(注意,此时你已经拿到相对应的页面信息,但是还没渲染到页面上)首先 Chrome 自带的 SafeBrowsing 会检查站点是否⚠️风险站点。(通常是检查站点 ip 是否在谷歌的黑名单里)
- ok,假设你访问的并不是风险网站。那么 Network 进程会通知 UI 进程我这边处理好了,该你上场了。

- UI 线程拿到网站数据后,会创建一个渲染进程(Renderer Process)来渲染页面。(通过 IPC 传递)
四.页面渲染流程
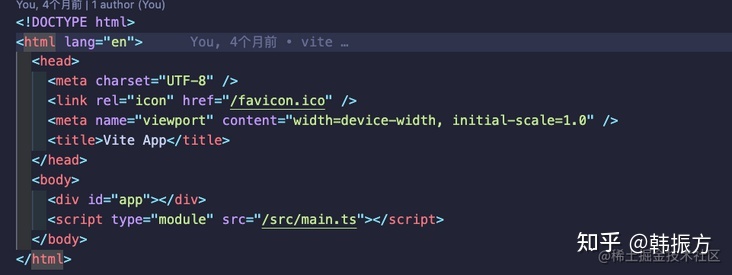
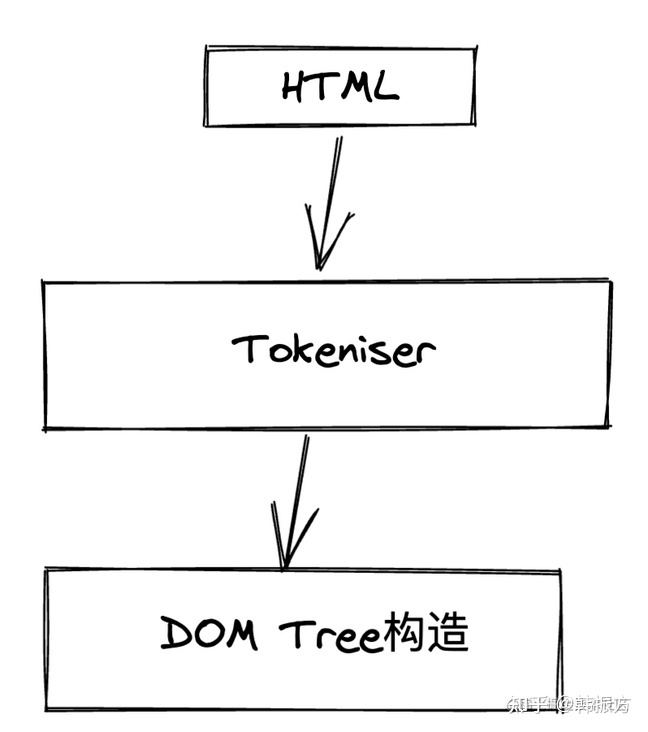
- 渲染进程拿到数据后,也就是
.html文件后,将会解析该文件。构建对应的 Dom 节点。(拿到的其实就是这个样子)
- 紧接着进行 Render 进程进行
Tokeniser词法解析。这个过程有些抽象,这里我简单举个栗子 。(比如:我今天吃了一个冰激凌 ,其中【我】是主语,【吃】是动词,【冰激凌】是名词,这些都是我们人类主观定义好的词性,如何让机器去理解这写词语的词性,就是词法解析。)映射到这里,就好比我们写的<div>、<img> 等标签,都是我们人主观定义好的,告诉机器如何去理解对应的数据,这个过程就是词法解析。 - 当解析好以后,紧接着会进行
DOM Tree构造。
- ⚠️注意此时真实 DOM 还未构造出来。
- 这时候会创建
Document对象,body对象,节点对象等等。(这里不要觉得很高深。没错,这里创建的 Document 对象并不是什么稀罕玩意,就是我们常用的 document.getElementById 方法中的那个 document 。Body 同理。) - 文档解析是从上向下解析的,当遇到像
<img>等行内替换元素是不会阻塞 Dom Tree的构造的。但是当遇到<script>标签的时候,就会停止解析.html文件,知道.js文件解析完毕。为什么呢?这也就是为什么 JS 为什么要设计成单线程的原因,如果解析dom和JS并行,那么就会造成某一时刻dom要将一个div渲染成一个蓝色背景,但是JS同时修改了这个div的背景颜色为红色,那我到底该听谁的呢?通常就会造成页面无法正常工作。

- 也对应了最开始学习
html标签时的知识,<script>标签要放到合适的位置。 - 假设现在最后一行代码已经解析完毕,那么我们就会得到一个完整的 DOM Tree
五.样式渲染
这个过程就是解析.css 文件的过程,查找每个节点是否有设置类名,然后添加相对应的样式即可。
六.元素渲染位置
- 只拿到了每个元素该渲染成什么样子是不够的,这时候还需要知道各个元素所需要呈现在页面哪个位置。也就是元素所占页面的大小和节点的坐标。这个过程称为 Layout布局。
- Render 主线程通过遍历 DOM Tree 和先前计算好的样式生成与之对应的 Layout Tree 。Layout Tree 记录了每个节点在页面上对应的(x,y)坐标和尺寸。
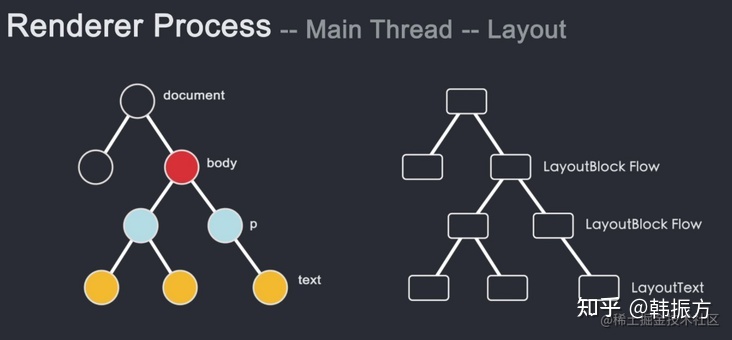
- 这里需要注意的是,DOM Tree 和 Layout Tree 并不是一一对应的关系。DOM Tree 某个元素如果设置了
display:none,则该元素不会出现在 Layout Tree 上。 - 而如果在样式中设置了 伪类 (如:
div::before)并且设置了content属性,那么该元素就会出现在 Layout Tree 上,但是并不会出现在 Dom Tree 上。造成这个的根本原因就是 DOM Tree 完全就是根据html生成的,它并不关心样式。而 Layout Tree 是根据计算 DOM Tree 和样式计算生成的。
<hr/>
篇幅有些长,有点晚了,我要睡觉啦~未完待续...