网上冲浪时,我们会接触到网络流媒体和本地视频文件。常见的视频文件格式有MP4、MKV、AVI等。在流媒体网站上看见视频常用的协议有HTTP、RTSP、RTMP、HLS等。视频技术较为复杂,包括视频封装、视频编解码、视频播放和视频转码等内容。
1 视频基础概念
当下市场常见的视频APP很多,其中1080P视频清晰度已经普及开来,也逐渐有4K的影视了。
PS: 1080P是指视频分辨率为1920*1080逐行扫描。
1.1 图像与像素
图像是人类视觉的基础,其中“图”是物体反射或折射光的分布,“像”是人的视觉系统所接收的图在人脑中形成的印象或认识。于计算机领域,与图像相关的概念非常多,如像素、PPI、图像位深度等。
1.1.1 像素
图像本质上是由很多“带有颜色的点”组成的,而这些点,就是“像素”。像素的英文叫Pixel,缩写为PX。这个单词是由图像(picture)和元素(Element)两个单词组成的。
像素是图像显示的基本单位,分辨率是指一张图片的宽度和高度的乘积,单位是像素。通常说一张图片大小,如1920*1080像素,是指宽度为1920像素,高度为1080像素。它们的乘积是1920*1080=2 073 600,也就是说该图片是两百万像素的。同时1920*1080也被称为这幅图片的分辨率。
PS: 分辨率是显示器的重要指标。
1.1.2 PPI
每英寸的像素数(Pixels Per Inch,PPI)是手机屏幕(或计算机显示器)上每英寸面积到底能放多少“像素”。这个值越高,图像就越清晰细腻。
以前的功能机,屏幕PPI都很低,画质差,有很强的颗粒感。
数码相机常见的规格有72PPI、180PPI和300PPI。
DPI(Dots Per Inch)是指输出分辨率,是针对输出设备而言的,一般的激光打印机的输出分辨率为[300DPI,600DPI],印刷的照排机可达到[1200DPI,2400DPI],常见的冲印一般为[150DPI,300DPI]。
1.1.3 颜色
像素必须有颜色才能组成色彩斑斓的图像。像素只有黑白色时,图像就是黑白图像。
计算机中,R(Red红)、G(Green绿)、B(Blue蓝)也被称为“基色分量”。单项的取值范围都是0~255,一共256个等级。任何颜色都可以用RGB这3个值的组合表示,如保护眼睛的豆沙绿RGB=(199,237,204)。
RGB为3个分量,假定每个分量占8b,取值分别为0~255。那么3个分量的组合取值为256*256*256=16777216种色彩,也简称为1600万色。这种颜色范围已经超过人眼可见的全部色彩,所以又叫做真彩色。
RGB这3色,每色有8b,这种方式表达出来的颜色,也被称为24位真彩色。
1.1.4 像素位深度
像素位深度是指每像素所用的位数,它决定了彩色图像的每像素可能有的颜色数,或者确定灰度图像的每像素可能有的灰度级数。
通常把像素位深度说成图像深度,表示每像素的位数越多,它所能表达的颜色数目就越多,而它的深度也就越深。
不要一维追求特别深的像素深度,这样没有实际意义。因为像素深度越深,数据量越大,传输带宽及存储空间也就越大。相反,像素深度太浅,则会影响图像质量,图像看起来让人觉得很粗糙而不自然。
1.2 色彩空间
RGB为三原色,可以混合出所有的颜色。常见的色彩空间有RGB、YUV、HSV。
1.2.1 RGB
RGB色彩空间(又称为颜色模型、颜色空间),由红、绿、蓝三原色组成,广泛用于BMP、TIFF、PPM等。
1.2.2 YUV
YUV色彩空间是一种亮度与色度分离的色彩格式。YUV主要用于优化彩色视频信号的传输,使其向后兼容老式黑白电视。与RGB视频信号传输相比,它最大的优点在于只需占用极小的频宽(RGB要求3个独立的视频信号同时传输),其中Y表示亮度,也就是灰阶值,而U和V所表示的则是色度,其作用是描述影像色彩及饱和度,用于指定像素的颜色。
1.2.3 HSV
RGB和YUV颜色模型都是面向硬件的,而HSV颜色模型是面向用户的。HSV颜色模型的三维表示从RGB立方体演化而来的。其中H(色调)、S(饱和度)、V(明度)。
1.3 数字视频
数字视频就是以数字形式记录的视频,是和模拟视频相对的。数字视频有不同的产生方式、存储方式和播出方式。
1.3.1 图像和视频
图像是人对视觉感知的物质的再现。三维自然场景的对象包括深度、纹理和亮度信息。二维图像主要包括纹理和亮度信息。
视频本质上是连续的图像。视频由多幅图像构成,包含对象的运动信息,又称为运动图像。
1.3.2 数字视频
数字视频可以理解为自然场景空间和时间的数字采样表示。空间采样的主要技术指标为解析度(Resolution,与像素有些关联关系),时间采样的主要技术指标为帧率。
数字视频的系统流程包括采集、处理、显示等3个步骤。
1. 采集: 通常使用照相机、手机、摄像机。
2. 处理: 包括编解码器和传输设备。
3. 显示: 通常用显示器进行数字视频的渲染。
1.3.3 HVS
人类视觉系统(Human Visual System,HVS)有眼睛、神经和大脑构成。人眼对标光学信息处理系统。
PS: HVS与HSV虽然英文简写名字很类似,但是两个完全不同的概念。
人类通过HVS获取外界图像信息,光辐射刺激人眼时,引起的复杂生理和心理变化的这种感觉,就是视觉。HVS的研究包括光学、色度学、视觉心理学、解剖学、神经科学和认知科学等许多科学领域。
针对HVS的特点,数字视频系统的设计应当考虑以下因素:
1)丢弃高频信息,之编码低频信息。
2)提高边缘信息的主观质量。
3)降低色度的解析度。
4)对感兴趣区域(ROI)进行特殊处理。
PS: 在机器视觉、图像处理中,被处理的图像以方框、圆、椭圆、不规则多边形等方式勾勒出需要的区域,被称为感兴趣区域。
1.3.4 YUV采样格式
YUV图像可以根据HVS的特点,对色度进行分量采样,这样可以降低视频数据量。根据亮度和色度分量的采样比率,YUV图像的采样格式通常包括4:4:4、4:2:3、4:2:0。
1.3.5 YUV亮度分辨率
根据YUV图像亮度,定义常见几种分辨率。
格式名称 |
亮度分辨率 |
SQCIF |
128*96 |
QCIF |
176*144 |
CIF |
352*288 |
4CIF |
704*576 |
SD |
720*576 |
HD |
1280*720 |
1.4 视频的基础概念
人眼视觉有暂留现象,每秒超过24帧的图像变化看上去是平滑连续的,这种连续的画面叫做视频。
1.4.1 帧
帧(Frame)就是视频、动画、游戏中的每张画面,这些视频、动画和游戏就是由无数张画面组合而成的。每张画面就是一帧。视频帧又分为I帧、P帧和B帧。
I帧,帧内编码帧,大多数情况下I帧就是关键帧,也就是一个完整帧,无须任何辅助就能独立显示的画面。
P帧,向前预测编码帧,是一个非完整帧,通过参考前面的I帧或者P帧生成画面。
B帧,双向预测编码帧,参考前后图像帧编码生成,通过参考前面的I/P帧或后面的P帧来协助形成一个画面。
如只有I帧和P帧的视频序列,I1P1P2P3P4I2P5P6P7P8。包括I帧、P帧和B帧的序列,I1P1P2B1 P3P4B2 P5I2B3 P6P7。
PS:解码器是有缓存的,通常以GOP为单位,所以B帧可以参考其后续的P帧。
1.4.2 帧和场
电视大多采用的是每秒播放25帧,即每秒更换25张图片,由于视觉暂留效应,人眼不会感到闪烁。每帧图像又是分为两场进行扫描的,这里的扫描是指电子束在显像管内沿水平方向一行一行地从上到下扫描,第一场先扫奇数行,第二场扫偶数行,即常说的隔行扫描,扫完两场即完成一帧图像。
如果场频为50Hz,帧频为25Hz,奇数场和偶数场扫描的是同一帧图像,除非图像静止不动,否则相邻两帧图像不同。计算机显示器与电视机显像管的扫描方式一致,所以一帧图像包括两场,即顶场和底场。

1.4.3 逐行与隔行扫描
每帧图像由电子束顺序地一行行连续扫描而成,这种扫描方式叫做逐行扫描。
把每帧图像通过两场扫描完成则是隔行扫描,在两场扫描中,第一场(奇数场)只扫描奇数行,依次扫描1、3、5、7行等,而第二场(偶数场)只扫描偶数行,一次扫描2、4、6、8行等。隔行扫描技术在传输信号带宽不够的情况下起很大作用。
逐行扫描和隔行扫描的显示效果主要区别在稳定性上面,隔行扫描的行间闪烁比较明显,逐行扫描克服了隔行扫描的缺点,画面平滑自然无闪烁。于电视的标准显示模式中,i为隔行扫描,p为逐行扫描。
1.4.4 帧数
帧(Frames)即帧的数量,可以解释为静止画面的数量。
1.4.5 帧率
帧率(Frame Rate)是用于测量显示帧数的量度,单位为f/s(Frames Per Second)或者赫兹(Hz),即每秒显示的帧数。帧率越高,画面越流畅逼真,对显卡的处理能力要求也越高,数据量也越大。对于电影等视频24f/s满足观看需求,但对于游戏而言体验是不够的流畅的。比如玩英雄联盟,右上角的FPS如果只有20那么就会有卡顿感。
常见的帧率如下:
10~12f/s: 由于人眼的特殊生理结构,画面高于每秒10~12帧的时候,会认为视频连贯的。
24f/s: 一般的电影拍摄及播放帧数。
60f/s: 这个帧率对人眼识别来讲已经具备较高的平滑度。
85f/s: 人脑处理视频的极限,人眼无法分辨更高频率的差异。
1.4.6 刷新率
屏幕每秒画面被刷新的次数,分为垂直刷新率和水平刷新率。一般提到的刷新率是垂直刷新率,以赫兹(Hz)为单位,刷新率越高,图像就越稳定(显示越清晰自然)。
目前大多数显示器根据其设定按30Hz、60Hz、120Hz或者144Hz的频率进行刷新。最常见的刷新频率为60Hz,是为了继承之前的电视机刷新频率为60Hz的设定。
1.4.7 分辨率
分辨率即视频、图片的画面大小或尺寸。分辨率是以横向和纵向的像素数量来衡量的,表示平面图像的精细程度。视频精细程度并不只取决于视频分辨率,还取决于屏幕分辨率。
如1080P的P是指逐行扫描(Progressive Scan),即垂直方向像素,也就是“高”,所以1920*1080叫1080P,而不叫1920P。当720P(1280*720P)的视频在1080P屏幕上播放时,需要将图像放大,放大操作也叫上采样。
1.4.8 码率
码率即比特率,是指单位时间内播放连续媒体(如压缩后的音频或视频)的比特数量。在不同领域有不同的含义,于多媒体领域,指单位时间播放音频或视频的比特数,可以理解成吞吐量或带宽。码率的单位为b/s,即每秒传输的数据量,常用单位有b/s、kb/s等。比特率越高,带宽消耗得就越多。一般来说理解码率就是取样率,取样率越大,精度就越高,图像质量就越好,但数据量也越大,所以要找一个平衡点,用最低的比特率达到最小的失真。
视频有高速变化的场景和几乎静止的场景,这两种所需的数据量也是不同的,使用同样的比特率不太合理,故引入动态比特率。动态比特率(Variable Bit Rate,VBR),是指比特率可以随着图像复杂程度的不同而随之变化。
图像内容中简单的片段采用较小的码率,图像内容中复杂的片段采样较大的码率,这样既保证了播放质量,又兼顾了数据量的限制。
静态比特率(Constant Bit Rate,CBR)是指比特率恒定,此时图像内容复杂的片段质量不稳定,图像内容简单的片段质量较好。除VBR和CBR外,还有CVBR(Constrained Variable Bit Rate)、ABR(Average Bit Rate)等。
1.4.9 CPU&GPU
中央处理器(Central Proccessing Unit,CPU),包括算术逻辑部件(Arithmetic Logic Unit,ALU)和高速缓冲存储器(Cache)及实现它们之间联系的数据(Data)、控制及状态的总线(Bus)。
GPU即图形处理器(Graphics Proccessing Unit),专为执行复杂的数学和几何计算而设计的,拥有二维、三维图形加速功能。GPU相比于CPU具有更强大的二维、三维图形计算能力,可以让CPU从图形处理的任务重解放出来,执行其他更多的系统任务,这样可以大大提高计算机的整体性能。
硬件加速(Hardware Acceleration)就是利用硬件模块来代替软件算法以充分利用硬件所固有的快速特性,硬件加速通常比软件算法的效率要高。如将二维、三维图形计算相关工作交给GPU处理,从而释放CPU压力的操作,属于硬件加速。
1.5 视频格式
视频格式有很多,如视频文件格式、视频封装格式、视频编码格式等。常见的视频文件格式有MP4、RMVB、MKV、AVI等,常见的视频编码格式有MPEG-4、H.264、H.265等。
1.5.1 视频文件格式
Windows系统的文件名都有后缀,如1.txt、2.java等。Windows设置后缀名的目标是为了让系统中的应用程序来识别并关联这些文件,让相应的文件由相应的应用程序打开。
常见视频文件格式(MP4、RMVB、MKV、AV)与计算机上安装的视频播放器关联,通过后缀名来判断格式。
1.5.2 视频封装格式
视频封装格式(也叫容器)是将已经编码并压缩好的视频轨和音频轨按照一定的格式放到一个文件中,也就是说仅是一个外壳,或者把它当作一个放视频轨和音频轨的文件夹也可以。AVI、MPEG、VOB就是视频封装格式。
常见视频封装格式与对应的视频文件格式如下表:
视频封装格式名称 |
视频文件格式 |
AVI(Audio Video Interleave) |
.avi |
WMV(Windows Media Video) |
.wmv |
MPEG(Moving Picture Experts Group) |
.mpg/.vob/.dat/.mp4 |
Matroska |
.mkv |
Real Video |
.rm |
QuickTime |
.mov |
Flash Video |
.flv |
下面介绍几种常用的视频封装格式。
(1)音频视频交错(Audio Video Interlaved,AVI)格式,后缀.avi,是微软1992年推出的。该视频格式优点是图像质量好。由于无损AVI可以保存alpha通道,所以经常被使用。但缺点太多,例如体积过于庞大,压缩标准不统一。
(2)DV格式(Digital Video Format),是由索尼、松下、JVC等多家厂商联合提出的一种家用数字视频格式。数字摄像机就是使用这种格式记录视频数据的。它可通过计算机的IEEE 1394端口将视频数据传输到计算机,也可以将计算机中编辑好的视频数据回录到数码摄像机中。这种视频格式的文件扩展名也是.avi。电视台采用录像带记录模拟信号,通过EDIUS有IEEE 1394端口采集卡从录像带中采集出来的视频就是这种格式。
(3)MOV格式是苹果公司开发的一种视频格式,默认的播放器是苹果的QuickTime,具有较高的压缩比率和较完美的视频清晰度等特点,可以保存alpha通道。
(4)MPEG格式,文件后缀可以是.mpg、.dat、.vob、.mp4等。MPEG文件格式是运动图像压缩算法的国际标准。MPEG格式目前有3个压缩标准,分别是MPEG-1、MPEG-2和MPEG-4。
(5)WMV(Windows Media Video)格式,后缀为.wmv或.asf,也是微软公司退出的一种采用独立编码方式并且可以直接在网上实时观看视频节目的文件压缩格式。WMV格式主要优点包括本地或网络回放、丰富的流间关系及扩展性等。
(6)Flash Video格式,是由Adobe Flash延伸出来的一种流行网络视频封装格式,后缀.flv。随着H5视频标准的普及,Flash正在逐步淘汰中。
(7)Matroska格式,是一种新的多媒体封装格式,后缀为.mkv。这种封装格式可把多种不同编码的视频及16条或以上不同格式的音频和不同语言的字幕封装到一个Matroska Media文档中。它是一个开放源代码的多媒体封装格式,还可以提供非常好的交互功能,比MPEG更方便强大。
1.5.3 视频编码格式
视频编码格式是指能够对数字视频进行压缩或者解压缩的程序或者设备,也可以指通过特定的压缩技术,将某种视频格式转换成另一种视频格式。通常这种压缩属于有损压缩。
视频的编码格式才是一个视频文件的本质所在,不要简单地通过文件格式和封装形式来区分视频。常见的视频编码格式有H.26X系列、MPEG系列及其他系列。
(1)H.26X系列由ITU主导的,主要包括H.261、H.262、H.263、H.264、H.265等。H.261主要在较早的视频会议和视频电话产品中使用。H.263主要用在视频会议、视频电话和网络视频上。H.264即H.264/MPEG-4第十部分,或称AVC,是一种视频压缩标准,也是一种广泛使用的高精度视频的录制、压缩和发布格式。H.265及高效率视频编码是一种视频压缩标准,是H.264/MPEG-4 AVC的继任者,是它们两倍的压缩率。
(2)MPEG系列是由ISO下属的MPEG开发的,视频编码上主要包括几部分。MPEG-1第二部分主要使用在VCD上,有些在线视频也使用这种方式,该编解码器的质量大致上和原有的VHS录像带相当。MPEG-2第二部分(等同于H.262)使用在DVD\SVCD和大多数数字视频广播系统和有线分布系统中。MPEG-4第二部分可以使用在网络传输、广播和媒体存储上,相比于之前的系列其压缩性能有所提升。MPEG-4第十部分和ITU-T的H.264采用的是相同的标准。
(3)其他系列的视频编码格式包括AMV、AVS、Bink、CineForm、Cinepak、Dirac、DV、RealVideo、RTVideo、SheerVideo、Smacker、Sorenson、Video、VC-1、VP3、VP6、VP7、VP8、VP9、WMV等。但此类编码方式不常用。
2 音视频封装
常见AVI、RMVB、MKV、ASF、WMV、MP4、3GP、FLV等其实只能算是一种封装标准。完整的视频文件是由音频和视频两部分构成的,如H.264、Xvid等就是视频编码格式,MP3、AAC等就是音频编码格式。
将一个Xvid视频编码文件和一个MP3音频编码文件按MP4封装标准进行封装后,就可以得到一个MP4为后缀的视频文件,也就是常见的MP4视频文件。
2.1 数据封装和解封装
数据封装(Data Encapsulation)就是把业务数据映射到某个封装协议的净荷中,然后填充对应协议的包头,就可以形成封装协议的数据包,并完成速率适配。
数据接封装就是封装的逆过程,拆解协议包,处理包头中的信息,取出净荷中的业务信息数据封装,这与封装是一对逆过程。数据的封装和解封装如下:

2.2 音视频的封装
视频编码后加上音频编码,再一起进行封装,就可以得到我们观看的视频。
封装格式也称为多媒体容器,只为多媒体编码提供了一个“外壳”,也就是将所有的处理好的音频、视频或字幕都包装到一个文件容器中以便呈现给用户,这个包装过程叫做封装。

2.3 封装格式
封装格式即音视频容器,如经常看到的视频后缀名.mp4、.rmvb、.avi、.mkv、.mov等音视频容器。常见的封装格式包括AVI、VOB、WMV、RM、RMVB、MOV、MKV、FLV、MP4、MP3、WebM、DAT、3GP、ASF、MPEG、OGG等。视频文件的封装格式并不影响视频的画质,影响视频画面质量的是视频的编码格式。完成的视频文件=音频+视频+字幕(字幕是可选项)。
MPG是MPEG编码所采用的容器,具有流的特性,里面又分PS和TS,PS主要用于DVD存储,TS主要用于HDTV.
OGG是Ogg项目所采用的容器,具有流的特性,支持多音轨、章节、字幕等。OGM是OGG容器的变种,能够支持基于DirectShow的视频音频编码,支持章节等特性。
2.3.1 MP4
MP4(MPEG-4 Part14)是一种常见的多媒体容器格式,它是在ISO/IEC 14496-14标准文件中定义的,属于MPEG-4的一部分。MP4是一种较为全面的容器格式,被认为可以在其中嵌入任何形式的数据,不过常见的大部分的MP4文件存放的是AVC(H.264)或者MPEG-4 Part 2编码的视频和AAC编码的音频。MP4格式的官方文件后缀名是.MP4,还有其他的以MP4为基础进行的扩展格式,如M4v、3GP、F4V等。
box结构树
MP4文件中所有数据都装在box中,也就是说MP4由若干box组成,每个box有类型和长度,包含不同的信息,可以将box理解为一个数据对象块。box中可以嵌套另一个box,这种box称为container box。MP4文件box以树状结构的方式组织,一个简单的MP4文件由以下box组成,如下图(MP4info软件查看)。
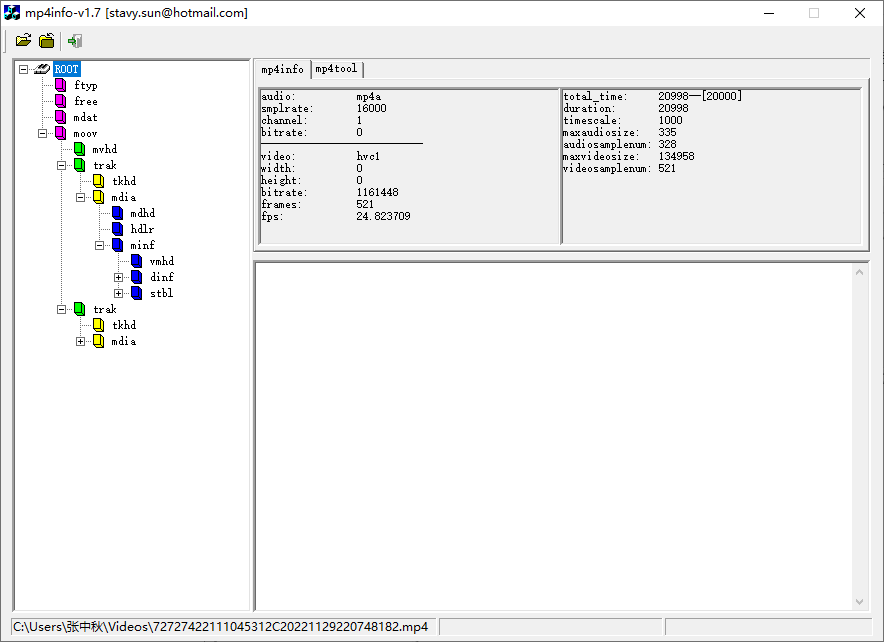
根节点(ROOT)下,主要包含以下3个box节点,即ftyp(File Type Box)文件类型、moov(Movie Box)文件媒体信息和mdat(Media Data Box)媒体数据。
2. ftyp
一个MP4文件有且仅有一个ftyp类型的box,作为MP4格式的标识并包含一些关于文件的信息。
ftyp是MP4文件的第1个box,包含了视频文件使用的编码格式、标准等。ftyp box通常放在文档的开始,通过对该box解析可以让软件(播放器、demux、解析器)之道应该使用哪种协议解析该文档,这是后续解读的基础。
C语言中定义MP4文件头结构体如下:
typedef struct{
unsigned int length; // box长度为28,包含注释对应的这4个字节
unsigned char name[4]; // 4个字符:ftyp
unsigned char majorBrand[4];
unsigned int minorVersion;
unsigned char compatibleBrands[12];
}FtypBox;以下是一段十六进制的MP4文件数据。
00 00 00 20 66 74 79 70 69 73 6F 6D 00 00 02 00 ....ftypisom....
69 73 6F 6D 69 73 6F 32 isomiso.
3. moov
ftyp box之后会有一个moov类型的box,是一种container box,子box中包含了媒体的metadata信息。该box包含了文档媒体的metadata信息,moov是一个container box,具体内容信息由子box诠释。
同File Type Box一样,该box有且只有一个,并只被包含在文档层。一般来说,moov会紧随ftyp出现,moov中包含一个mvhd和两个trak(1个音频和1个视频)。其中mvhd为header box,作为moov的第一个子box出现(对于其他container box来讲,header box 都应当作为首个子box出现)。trak包含了一个track的相关信息,是一个container box。
4. mdat
MP4文件的媒体数据包含在mdat类型的box(Media Data Box)中,该类型的box也是container box,可以有多个,也可以没有(当媒体数据全部引用其他文件时),媒体数据的结构由metadata进行描述。
2.3.2 AVI
音频视频交错(Audio Video Interleaved,AVI)格式是很成熟的老技术了。在国际学术界公认AVI已经属于被淘汰的技术,但因为简单易懂的开发API,还在被广泛使用中。AVI符合RIFF(Resource Interchange File Format)文件规范,使用四字符码(Four-Character Code,FOURCC)表征数据类型。
AVI的文件结构分为头部、主题和索引3部分。主题中图像数据和声音数据是交互存放的,从尾部的索引可以索引到想放的位置。AVI本身只提供这个框架,内部的图像数据和声音数据格式可以是任意的编码形式。因为索引放在了文件尾部,所以在播放网络流媒体时已经力不从心(如从网络上下载AVI文件,如果没有下载完成,很难正常播放)。
基本数据单元
AVI中有两种最基本的数据单元,一个是Chunks,另一个是Lists,结构体如下:
// Chunks
typedef struct{
DWORD dwFourcc;
DWORD dwSize; // data
BYTE data[dwSize]; // contains headers or audio/video data
}CHUNK;
// Lists
typedef struct{
DWORD dwList;
DWORD dwSize; // dwFourcc + data
DWORD dwFourcc;
BYTE data[dwSize-4]; // contains Lists and Chunks
}LIST;由如上代码可知,Chunks 数据块由四字符码、4B的data size(指下面的数据大小)及数据组成。Lists由4部分组成,包括4B的四字符码、4B的数据大小(指后面列的两部分大小)、4B的list类型及数据组成。与Chunks数据块不同的是,Lists数据内容可以包含字块(Chunks 或Lists)。
2.RIFF简介
RIFF是一种复杂的格式,其目的在于适用于多媒体应用的各种类型的数据。RIFF是微软公式为Windows GUI而创建的一种多媒体文件格式,它本身并没有定义任何存储数据的新方法,但是RIFF定义了一个结构化的框架,包含现有的数据格式。所以用户可以创建由两种或更多现有文件格式组成的新的复合格式。
多媒体应用需要存储和管理各种数据,包括位图、音频数据、视频数据和外围设备控制信息。RIFF提供了一种很好的方式来存储所有这些不同类型的数据。RIFF文件中包含的数据类型可以通过文件的后缀名来确认,例如常见的文件后缀名包括.avi、.wav、.rdi、.rmi和.bnd等。
PS: AVI是当前RIFF规范中使用最全面的一种类型。WAV也是经常被使用,但是它非常简单,WAV开发者通常使用旧的规范来构建它们。
只有编程人员才知道AVI文件和RIFF文件是同一种文件。
RIFF是一种包含多个嵌套数据结构的二进制文件格式,RIFF文件中的每个数据结构都称为块。块在RIFF文件中没有固定位置,因此标准偏移值不能用于定位它们的字段。因为块是由用户来定义的,所以每个块没有统一的位置。块包含数据,如数据结构、数据流或称为子块的其他块。每个RIFF块都具有以下基本结构:
typedef struct _Chunk{
DWORD ChunkId; // Chunk ID marker
DWORD ChunkSize; // Size of the chunk data in Bytes.
BYTE ChunkData[ChunkSize]; // The chunk data.
} CHUNK;PS: RIFF是以小端字节顺序写入的。字节顺序指占内存多于一个字节类型的数据在内存中的存放顺序,通常有小端、大端两种字节顺序。小端字节顺序指低字节数据存放在内存低地址处,高字节数据存放在内存高地址处;大端字节顺序指高字节数据存放在低地址处,低字节数据存放在高地址处。基于x86平台的PC是小端字节顺序地。
其中ChunkId包含4个ASCII字符,用于标识块包含的数据。例如字符RIFF用于识别包含RIFF数据的块。如果ID小于4个字符,则使用空格(ASCII 32)在右侧填充。ChunkSize表示存储在ChunkData字段中的数据的长度,不包括添加到数据中的任何填充数据(为了数据对齐会在结尾添加0,但是添加的0不算长度)。
PS: 结构体中ChunkId的4B和ChunkSize本身的4B的长度均不在ChunkSize的数据长度中。
3.AVI文件结构
AVI文件采用RIFF文件结构方式,使用四字符码(FOURCC)表征数据类型,如RIFF、AVI、LIST等,通常将四字符码称为数据块ID。RIFF文件的基本单元叫做数据块(Chunk),由数据块四字符码(数据块ID)、数据长度、数据组成。整个RIFF文件可以看成一个数据块,其数据块ID为RIFF,称为RIFF块。一个RIFF文件中只允许存在一个RIFF块。RIFF块中包含一系列其他子块,其中ID为LIST,称为LIST块,LIST块中可以包含一系列其他子块,但除了LIST块外的其他所有子块都不能再包含子块。
标准的RIFF文件结构如下。一个AVI通常包含几个子块。ID为hdrl的LIST块,包含了音视频信息,以及描述媒体流信息。ID为info的LIST块,包含编码该AVI的程序信息。ID为junk的chunk数据块,是无用数据,用于填充ID为movi的LIST块,包含了交错排列的音视频数据。ID为idxl的Chunk块,包含音视频排列的索引数据。

2.3.3 FLV
FLV(Flash Video)是现在非常流行的流媒体格式,由于其视频文件占用空间较小,封装及播放简单等特点,使其很适合在网络上进行应用,目前主流的视频网站无一例外地使用了FLV格式。但当前的浏览器已经不提倡使用Flash插件了,可以通过video.js和flv.js扩展Flash功能。FLV是常见的流媒体封装格式,可以将其数据看为二进制字节流。
FLV包括文件头(File Header)和文件体(File Body),其中文件体由一系列的Tag及Tag Size对组成。其Tag结构如下图所示:

PS: 可以使Ultra Edit、Submit、Binary Viewer的二进制查看工具查看FLV格式文件。
FLV的Header头部分由几部分组成,分别是Signature(3B)、Version(1B)、Flags(1B)、DataOffset(4B)。
Signature:占3B,固定为FLV这3个字符作为标识。一般发现前3个字符为FLV时就认为是FLV文件。
Version:占1B,标识FLV的版本号,此处为1。
Flags:占1B,其中第0位和第2位分别标识video与audio存在的情况(1表示存在,0表示不存在)。
DataOffset: 占4B,表示FLV的header长度,固定为9B。
FLV的body部分是由一系列的back-pointers+tag构成,back-pointers固定为4B,表示前一个tag的size。tag分为3种类型,包括video、audio和scripts。
FLV的tag部分是由tag type、tag data size、Timestamp、TimestampExtended、stream ID、tag data组成的。
2.3.4 TS
MPEG-2_TS是一种标准容器格式,用于传输与存储音视频、节目与系统信息协议数据,被广泛应用在数字广播系统。数字机顶盒接收的就是TS流。
在MPEG-2标准中,有两种不同的码流输出到信道:
1) PS流,适用于没有传输误差的场景。
2) TS流,适用于有信道噪声的传输场景。
节目流(PS)适用于合理可靠的媒体,如DVD;传输流(TS)适用于不太可靠的传输,如视频云存储监控。MPEG-2 System(编号 13818-1)是MPEG-2 标准的一部分,该部分描述了多个视频、音频和数据多种基本流(ES)合成传输流(TS)和节目流(PS)的方式。
基本概念
(1)ES是基本流(Elementary Stream),直接从编码器出来的数据流,可以是编码过的音频、视频或者其他连续码流。
(2)PES是打包的基础流(Packletized Elementary Streams),是ES流经过PES打包器处理后形成的数据流,在这个过程中完成将ES流分组,并加入包头信息(如PTS、DTS)等操作。PES流的基本单位是PES包,PES包由包头和负载(Payload)组成。
(3)节目流(Program Stream),由PS包组成,而一个PS包又由若干PES包组成。一个PS包由具有同一时间基准的一个或多个PES复合而成。
(4)传输流(Transport Stream),由固定长度(188Byte)的TS包组成,TS包是对PES包的另一种封装,是同一时间基准的一个或多个PES包复合而成。PS包是不固定长度的,而TS包为固定长度的。
(5)节目特定信息(Program Specific Information,PSI),用来描述传输流的组成结构。PSI信息由4中类型的表组成,包括节目关联表(PAT)、节目映射表(PMT)、条件接收表(CAT)、网络信息表(NIT)。
(6)节目关联表(Program Association Table,PAT),该表的PID是固定的0x0000,它的主要作用是指出该传输流的ID,以及该路传输流中所对应的几路节目流的MAP表和网络信息表的PID。
(7)节目映射表(Program Map Table,PMT),该表的PID是由PAT提供给出的。通过该表可以得到一路节目中包含的信息。
(8)NIT是网络信息表(Network Information Table),该表的PID是由PAT提供给出的。NIT的作用主要是对多路传输流的识别,NIT提供多路传输流、物理网络及网络传输相关的一些信息。
(9)条件访问表(Conditional Access Table,CAT),该表的PID是0x0001。
除上面几种表外,MPEG-2还提供了私有字段,用于实现对MPEG-2的扩充。为便于传输,实现时分复用,基本ES必须打包,也就是讲顺序连续、传输连续的数据流按一定的时间长度进行分割,分割的小段叫做包,因此打包也称为分组。
由于TS码流有较强的的抵抗传输误码能力,因此在传输媒体中进行传输的MPEG-2码流基本上采用TS。
TS流的形成过程
TS流的形成过程大体分为3个步骤:

如TS流的形成过程:
第一步:通过原始音视频数据经过压缩编码得到ES流,生成的ES基本流比较大,并且只是I、P、B这些视频帧或音频取样信息。
第二步:对ES基本流进行打包生成PES流,通过PES打包器,首先对ES基本流进行分组打包,在每个包前加上包头就构成了PES流的基本单位,即PES包,对视频PES来讲,一般是一帧一个包,音频PES一般一个包不超过64个kB。PES包头信息中加入了PTS、DTS信息,用于音视频的同步。
第三步:使用同一时间基准的PES包经过TS复用器生成TS传输包。
PES包的长度通常远大于TS包的长度,一个PES包必须由整数个TS包来传送,没装满的TS包由填充字节填充。PES包进行TS复用时,往往一个PES包会分存到多个TS包中。将PES包内容分配到一系列固定长度的TS传输包(TS Packect)中,TS流中TS传输包头加入了PCR(节目参考时钟)与PSI(节目专用信息),其中PCR用于解码器的系统时钟恢复。TS包的基本结构如下所示:

每个包固定长度为188Byte,其中包头为4B。PCR时钟的作用非常重要,编码器中有一个系统时钟用于产生指示音视频正确显示和解码的时间标签(如DTS、PTS)。解码器在解码时首先利用PCR时钟重建与编码器同步的系统时钟,再利用PES流中的DTS、PTS进行音视频的同步,这也是音视频同步的基本原理。
TS流形成过程如下:
(1)将原始音视频数据压缩后,由压缩结果组成一个基本码流ES。
(2)对ES进行打包形成PES。
(3)将PES包加入时间戳信息DTS、PTS。
(4)将PES包内容分配到一系列固定长度的TS包中。
(5)在传输包中加入定时信息PCR。
(6)在传输包中加入节目专用信息PSI。
(7)连续输出传输包形成具有恒定比特率的MPEG-TS流。
TS流的解析过程,可以说是生成的逆过程。
(1)从复用的MPEG-TS流中解析出TS包。
(2)从TS包中获取PAT及对应的PMT(PSI中的表格)。
(3)从而获取特定节目的音视频PID。
(4)通过PID筛选出特定音视频相关的TS包,并解析出PES。
(5)从PES中读取PTS/DTS,并从PES中解析出基本码流ES。
(6)将ES交给解码器,获得压缩前的原始音视频数据。
2.3.5 M3U8
M3U8是Unicode版本的M3U,采用UTF-8编码。M3U和M3U8文件都是苹果公司使用的HTTP Live Streaming(HLS)协议格式的基础,这种协议格式可以在iPhone 系列设备播放。M3U8文件其实是HLS协议的部分内容,而HLS是一个由苹果公司提出的基于HTTP的流媒体网络传输协议。
HLS简介
HTTP直播协议(HTTP Live Streaming,HLS),其工作原理是把整个流分成一个一个小的基于HTTP的文件来下载,每次只下载一部分。当媒体流正在播放时,客户端可以选择从许多不同的备用源中以不同的速率下载同样的资源,允许看流媒体会话适应不同的数据速率。
在开始一个流媒体会话时,客户端会下载一个包含元数据的Extended M3U(M3U8) Playlist文件,用于寻找可用的媒体流。HLS只请求基本的HTTP报文,与实时传输协议(RTP)不同,HLS可以穿过任何允许HTTP数据通过的防火墙或者代理服务器,也可以很容易地使用内容分发网络来传输媒体流。
总之,HLS是新一代流媒体传输协议,其基本实现原理为将一个大的媒体文件进行分片,将分片的文件资源路径记录在M3U8文件内容,其中附带一些额外的描述,例如该资源的多带宽信息,主要用于提供给客户端。客户端依据M3U8文件即可获取对应的媒体资源,进行播放,因此客户端获取HLS文件,主要就是对M3U8文件进行解析操作。
M3U8文件格式
M3U8文件实质上是一个播放列表(Playlist),其可能是一个媒体播放列表(Media Playlist),也可能是一个主播房列表(Master Playlist)。但无论是哪种播放列表,其内部文字都utf8编码。当M3U8文件作为媒体播放列表(Media Palylist)时其内部信息记录的是一系列媒体片段资源,顺序播放该片段资源即可完整展示多媒体资源。
M3U8播放列表内容片段如下:
#EXTM3U
#EXT-X-STREAM-INF: PROGRAM-ID=1, BANDWIDTH=1280000
http://example.com/low.m3u8
#EXT-X-STREAM-INF: PROGRAM-ID=1, BANDWIDTH=2560000
http://example.com/mid.m3u8
#EXT-X-STREAM-INF: PROGRAM-ID=1, BANDWIDTH=7680000
http://example.com/hi.m3u8
#EXT-X-STREAM-INF: PROGRAM-ID=1, BANDWIDTH=65000, CODECS="mp4a.40.5"
http://example.com/audio-only.m3u8
对于点播来说,客户端只需要按照顺序下载上述片段资源,顺序播放,而对于直播来讲,客户端需要定时重新请求该M3U8文件,看一看是否有新的片段数据需要进行下载并播放。
当M3U8作为主播放列表(Master Playlist)时,其内部提供的是同一份媒体资源的多份流列表资源。
#EXTM3U
#EXT-X-STREAM-INF:BANDWIDTH=150000,RESOLUTION=416x234,CODECS="avc1.42e00a,mp4a.40.2"
http://example.com/low/index.m3u8
#EXT-X-STREAM-INF:BANDWIDTH=240000,RESOLUTION=416x234,CODECS="avc1.42e00a,mp4a.40.2"
http://example.com/lo_mid/index.m3u8
#EXT-X-STREAM-INF:BANDWIDTH=440000,RESOLUTION=416x234,CODECS="avc1.42e00a,mp4a.40.2"
http://example.com/hi_mid/index.m3u8
#EXT-X-STREAM-INF:BANDWIDTH=640000,RESOLUTION=640x360,CODECS="avc1.42e00a,mp4a.40.2"
http://example.com/high/index.m3u8
#EXT-X-STREAM-INF:BANDWIDTH=64000,CODECS="mp4a.40.5"
http://example.com/audio/index.m3u8
该备用流资源指定了多种不同码率,以及不同格式的媒体播放列表,并且该备用流资源也可同时提供不同版本的资源内容,例如不同语言的音频文件、不同角度拍摄的视频文件等。客户可以根据不同的网络状态选取合适码流的资源,并且最好根据用户喜好选择合适的资源内容。
2.4 视频压缩编码
编码在通信和信息处理领域中被广泛使用,其基本原理是将信息按照一定规则使用某种形式的码流表示与传输。常用的需要编码的信息主要有文字、语音、视频和控制信息等。
2.4.1 视频编码基础知识
视频编码涉及的基础知识非常复杂,包括图像、视频、压缩原理等。
视频和图像的关系
视频本质上是由大量的连续图片组成的。
衡量视频很重要的一个指标是帧率,帧率越高,视频越逼真就越流畅。
每秒15帧==15FPS
每秒30帧==30FPS
每秒60帧==60FPS
视频编码的重要性
原始视频如果不编码那么体积会非常庞大。
如分辨率为1920*1080,帧率为30的视频。
单画面像素值1920*1080=2073600像素,每个像素占用24b(采用RGB24),也就是单画面图片占用2073600*24=49766400b。
8bit=1Byte,单画面大小48766400bit/8=6220800Byte,约等于6.44MB。
1S的视频大小,单画面大小*帧率=6.22mb*30=186.6mb。
1min大小视频约为11GB,90min大小视频约为1TB。 不压缩不行。
视频产生之后涉及存储和传输问题。如果按照100mb/s网速下载完刚才的电影需要22小时,那么拉流的时间太长了。
视频编码
视频编码是指按指定的方法将信息从一种格式转换成另一种格式。视频编码就是将一种视频格式转换成另一种视频格式。视频编码和解码是互逆的过程,如下。

编码的最终目的就是为了压缩,市面上各种各样的视频编码方式都是为了让视频变得更小,有利于存储和传输。视频从录制到播放的整个过程,如下。

首先是视频采集,通常会使用摄像机、摄像头进行视频采集。
采集可视频数据后进行模数转换,将模拟信号转变成数字信号。
信号输出之后,要进行预处理,将RGB信号编程YUV信号,然后进行压缩编码,包含音频和视频,然后进行音视频封装,形成有利于存储或传输的格式,以便可以通过网络传输出去。
YUV成像原理
RGB信号和YUV信号,YUV本质上是一种颜色数字化表示方式。视频通信系统之所以要采用YUV,而不是RGB,主要是因为RGB信号不利于压缩。在YUV这种格式中,加入亮度这一概念。
视频工程师发现,眼睛对于明暗的分别率要比对颜色的分辨率更精细一些。所以视频存储中,没必要存储全部颜色信号,可以把更多带宽留给黑白信号(亮度),将稍少的带宽留给彩色信号(色度),这就是YUV的基本原理,Y是亮度,U和V则是色度。
YUV格式可以很方便的实行视频压缩,YUV的存储格式与其采样方式密切相关。
采样的原理非常复杂,常采用YUV 4:2:0的采样方式,获得1/2的压缩率,这些预处理做完后,就可以正式进行编码了。
IPB帧
I帧,帧内编码帧(Intra Picture),采用帧内压缩去掉空间冗余信息。
P帧,前向预测编码帧(Predictive-Frame),通过将图像序列中前面已经编码的帧的时间冗余信息来压缩传输数据量的编码图像。
B帧,双向预测内插编码帧(Bi-Directional Interpolated Predication Frame),既考虑图像序列前面的编码图像,又顾及源图像序列后面的已编码帧之间的冗余信息,以此来压缩传输数据量的编码图像,又称为双向编码帧。参考前面的一个I帧或者P帧及其后面的一个P帧。
注意:B帧有可能参考它后面的P帧,解码器一般有视频帧缓存队列(以GOP为单位)。
PTS和DTS
解码时间戳(Decoding Time Stamp,DTS)用于标识读入内存中比特流在什么时候开始送入解码器中进行解码,也就是解码顺序的时间戳。
展示时间戳(Presentation Time Stamp,PTS)用于度量解码后的视频帧什么时候被显示出来。
在没有B帧的情况下,DTS和PTS的输出顺序是一样的,一旦存在B帧,PTS和DTS则会不同,也就是显示顺序地时间戳。
GOP简介
图像组(Group OF Picture,GOP),指两个I帧之间的距离。Reference即参考周期,指两个P帧之间的距离。一个I帧所占用的字节数大于一个P帧,一个P帧所占用的字节数大于一个B帧,所以在码率不变的前提下,GOP越大,P、B帧的数量就会越多,平均每个I、P、B帧所占用的字节数就越多,也就更容易获得较好的图像质量。
2.4.2 视频压缩
对原始视频进行压缩的目的是为了去除冗余信息,这些冗余信息包括以下内容:
空间冗余,即图像相邻像素之间有较强的相关性。
时间冗余,即视频序列的相邻图像之间内容相似。
编码冗余,即不同像素值出现的概率不同。
视觉冗余,即人的视觉系统对某些细节不敏感。
知识冗余,即规律性的结构可由先验知识和背景知识得到。
数据压缩主要分为有损压缩和无损压缩。
无损压缩(Lossless)即压缩前、解压缩后图像完全一致X=X’,压缩比一般比较低(2:1 ~ 3:1),典型的压缩格式有Winzip、JPEG-LS等。
有损压缩(Lossy)即压缩前与解压缩后图像不一致X!=X’,压缩比一般比较高(10:1 ~ 20:1),典型格式有MPEG-2、H.264/AVC、AVS等。
数据压缩与解压缩的流程如下:

无损压缩
无损压缩也称为可逆编码,重构后的数据与原数据完全相同,适用于磁盘文件的压缩等。主要采用熵编码方式,包括香农编码、哈夫曼编码和算术编码等。香农编码采用信源符号的累计概率分布函数来分配码字,效率不高,实用性不大,但对其他编码方法有很好的的理论指导意义。霍夫曼(哈夫曼)编码完全依据出现概率来构造异字头的平均长度最短的码字,先对图像数据扫描一遍,计算出各种像素出现的概率,按照概率的大小指定不同长度的唯一码字,由此得到一张该图像的哈夫曼码表。编码后的图像数据记录的是每像素的码字,而码字与实际像素值的对应关系记录在码表中。算术编码是用符号的概率和编码间隔两个基本参数来描述的,在给定符号集和符号概率的情况下,算术编码可以给出接近最优的编码结果。使用算术编码的压缩算法通常先要对输入符号的概率进行估计,然后编码,估计越准,编码就越接近最优的结果。
有损压缩
有损压缩也称为不可逆编码,重构后的数据与原数据有差异,适用于任何允许失真的场景,例如视频会议等。常用的有损编码方式包括预测编码、变换编码、量化编码、混合编码等。
2.4.3 视频编码原理
视频编码是指通过特定的压缩技术,将某个视频格式的文件转换成另一种视频格式。视频数据在时域和空域层面都有极强的相关性,这也表示有大量的时域冗余信息和空域冗余信息,压缩编码技术就是去掉数据中的冗余信息。
去除时域冗余信息的主要方法包括运动补偿、运动表示、运动估计等。运动补偿是通过先前的局部图像来预测、补偿当前的局部图像,可有效减少帧序列冗余信息。运动表示是指不同区域的图像使用不同的运动矢量来描述运动信息,运动矢量通过熵编码进行压缩(熵编码在编码过程中不会丢失信息)。运动估计是指从视频序列中抽取运动信息,通用的压缩标准使用基于块的运动估计和运动补偿。
去除空域冗余信息的主要方法包括变换编码、量化编码和熵编码。变换编码是指将空域信号变换到另一正交矢量空间,使相关性下降,数据冗余度减小。量化编码是指对变换编码产生的变换系数进行量化,控制编码器的输出位率。熵编码是指对变换、量化后得到的系数和运动信息进行进一步的无损压缩。
原始视频所需存储空间巨大,且传输成本也大,需要去除冗余信息。
视频一般有5中冗余信息,包括空间冗余、时间冗余、编码冗余、视觉冗余和知识冗余。
2.4.4 视频编码的关键技术
编解码器包括编码器和解码器。编码器(Encoder)是指压缩信号的设备和程序;解码器(Decoder)是指解压缩信号的设备或程序;编解码器(Codec)是指编解码器对。
编码的主要流程保罗预测、变换、量化、熵编码,解码的流程与之互逆。如下图所示。
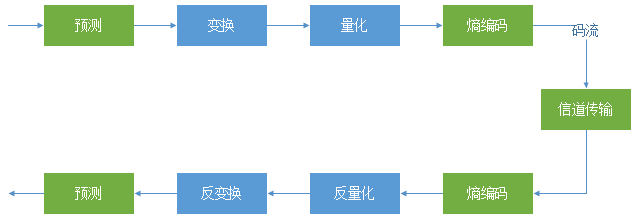
2.4.5 视频编解码流程
视频的编解码流程分为编码和解码,是互逆的过程。编码过程包括运动估计、运动补偿、DCT、量化与熵编码等,如下图所示。

(1)运动估计(Motion Estimate)是指从前几帧中寻找匹配的宏块,有多种不同的搜索算法,编码获得的质量和速度也不相同。其中快速算法的编码质量比全搜索算法低不了太多,但是速度却提高了很多倍。得到的运动矢量的过程被称为运动估计。
(2)运动补偿(Motion Compensate)是通过先前的局部图像来预测、补偿当前的局部图像,它是减少帧序列冗余信息的有效方法,包括全局运动补偿和分块运动补偿两类。运动补偿的结果分为两份,一份被当前帧做参考求出差值Dn,另一份用于生成Fn的对应参考帧。
(3)离散余弦变换(Discrete Cosine Transform,DCT),主要用于对数据或图像进行压缩,能够将空域的信号转换到频域上,具有良好的去相关性的性能。图像经过DCT变换后,其频率系数的主要成分集中于比较小的范围,且主要位于低频部分。
(4)量化(Quant)是指除指定的数值(有损压缩)。量化结果分为两份,一份做进一步处理,另一份经过反量化(Rescale)/反DCT(IDCT)变化,结合第2步的运动补偿生成Fn对应的参考帧,供后续参考。
(5)重排(Reorder)是指对量化后的数据进行重排序,常用算法为游程编码等。
(6)熵编码(Entropy Encode)进行最后编码,使用上一步结果及Vectors和Headers的内容。
2.5 视频播放原理
绝大部分视频播放器,如MPlayer、VLC、Xine、DirectShow等在播放视频的原理和架构上是非常相似的。视频播放器播放一个互联网上的视频文件需要经过几个步骤,包括解协议、解封装、音视频解码、音视频同步、音视频输出。
2.5.1 视频播放器简介
视频播放器播放本地视频文件或互联网上的流媒体文件大概需要解协议、解封装、解码、同步、渲染等几个步骤,如下图所示:

解协议
解协议是指将流媒体协议的数据,解析为标准的封装格式数据。音视频在网络上传输的时候,采用各种流媒体协议如HTTP、RTMP、RTSP、MMS等。此类协议在传输音视频数据的同事,也会传输一些信令数据。这些信令数据包括对播放的控制(播放、暂停、停止),或者对网络状态的描述等。在解协议的过程中会去除信令数据而只保留音视频数据。如采用RTMP协议传输的数据,经过解协议操作后,输出FLV格式的数据。
解封装
解封装是指将输入的封装格式的数据,分离成为音频流压缩编码数据和视频流压缩编码数据。封装格式种类有很多,如MP4、MKV、RMVB、TS、FLV、AVI等,其作用就是将已经压缩编码的视频数据和音频数据按照一定的格式放到一起。FLV格式的数据经解封装操作后,输出H.264 编码的视频码流和AAC编码的音频码流。
解码
解码是指将视频/音频压缩编码数据,解码称为非压缩的视频/音频原始数据。音频的压缩标准包括AAC、MP3、AC-3等,视频的压缩编码标准则包含H.264、MPEG-2、VC-1等。解码是整个系统中最重要也是最复杂的一个环节。通过解码,压缩编码的视频数据输出称为非压缩的颜色数据,如YUV420P、RGB等。压缩编码的音频数据输出称为非压缩的音频抽样数据,例如PCM数据。
音视频同步
根据解封装模块在处理过程中获取的参数信息,同步解码出来的视频和音频数据,被送至系统的显卡和声卡播放出来。
为什么要音视频同步?
因为媒体数据经过解复用流程后,音频/视频解码是独立的,也是独立播放的,而在音频流和视频流中,其播放速度由霞凝管信息指定的,如视频是根据帧率,音频是根据采样率。从帧率及采样率即可知道视频、音频播放速度。声卡和显卡均是以一帧数据来作为播放单位。如果单纯依赖帧率及采样率进行播放,在理想条件下是同步,不会有误差。
下面以一个44.1kHz的AAC音频流和24f/s的视频流为例来说明。如果一个AAC音频frame每个声道包含1024个采样点,则一个frame的播放时长为(1024/44100)*1000ms=23.27ms,而一个视频frame播放时长为1000ms/24=41.67ms。
理想情况下音视频完全同步,但实际情况下使用以上简单的方式,慢慢会出现音视频不同步。可能的原因有:
一帧的播放时间难以精准控制;
音视频解码及渲染的耗时不同,可能造成每一帧输出有一点细微差别,长久累计,不同步便越来越明显;
音频输出是线性的,而视频输出可能是非线性的,从而导致有偏差;
媒体流本身视频有差距(特别是TS实时流,音视频能播放的第1个帧起点不同),所以解决解决音视频同步问题引入了时间戳。
时间戳包含几个特点,首先选择一个参考时钟(要求参考时钟上的时间是线性递增的),编码时依据参考时钟给每个音视频数据块都打上时间戳。播放时根据音视频时间戳参考时钟来调整播放,所以音视频同步实际上是一个动态的过程。即同步是暂时的,不同步是常态。
2.5.2 FFmpeg播放架构与原理
ffplay是使用FFmpeg API开发的功能完善的开源播放器。在ffplay中个线程如下所示。

read_thread线程负责读取文件内容,将video和audio内容分离出来后生成packet,将packet输出到packet队列中,包括Video Packet Queue和Audio Packet Queue,不考虑subtitle。
video_thread线程负责读取Video Packets Queue队列,将video packet解码得到Video Frame,将Video Frame输出到Video Frame Queue队列中。
audio_thread线程负责读取Audio Packets Queue队列,将audio packet解码得到Audio Frame,将Audio Frame输出到Audio Frame Queue队列中。
主线程——>event_loop——>refresh_loop_wait_event 负责读取Video Frame Queue中的video frame,调用SDL进行显示,其中包括了音视频同步控制的相关操作。
SDL的回调函数sdl_audio_callback负责读取Audio Frame Queue中的audio frame,对其进行处理后,将数据返回给SDL,然后SDL进行音频播放。
FFmpeg解码流程涉及几个重要的数据结构和API,如图所示:
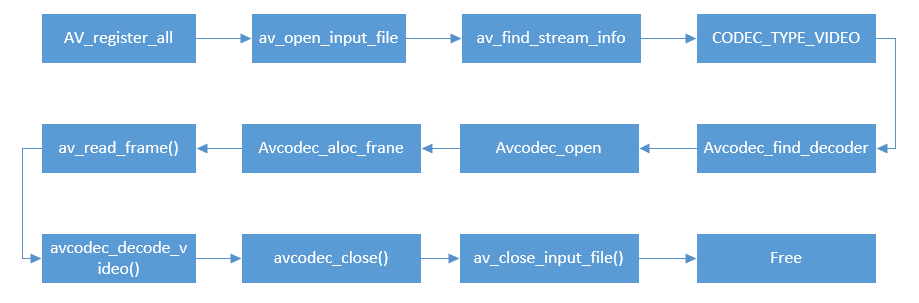
(1)注册所有容器格式和CODEC,使用av_register_all,最新版本中无须调用该函数。
(2)打开文件av_open_input_file,最新版本为avformat_open_input。
(3)从文件中提取流信息av_find_stream_info。
(4)枚举所有流,查找的种类为CODEC_TYPE_VIDEO。
(5)查找对应的编解码器 avcode_find_decoder。
(6)打开编解码器 avcodec_open。
(7)为解码帧分配内存 avcodec_alloc_frame。
(8)不停地从码流中提取帧数据 av_read_frame。
(9)判断帧的类型,对于视频帧则调用 avcodec_decode_video。
(10)解码完后,释放解码器 avcodec_close。
(11)关闭输入文件 av_close_input_file。
注意:该流程图为FFmpeg 2.*版本,最新的FFmpeg略有改动。
2.5.3 VLC播放原理
VLC播放视频分为4个步骤:
(1)access访问,或者理解为接收、获取、得到;
(2)demux解复用,就是把通常合在一起的音频和视频分离(可能还有字幕);
(3)decodc解码,包括音频和视频的解码;
(4)output输出,也分为音频和视频的输出(aout和vout)。
2.5.4 现代播放器架构
典型的播放器可分为应用层、视图层和内核层,如下图所示:
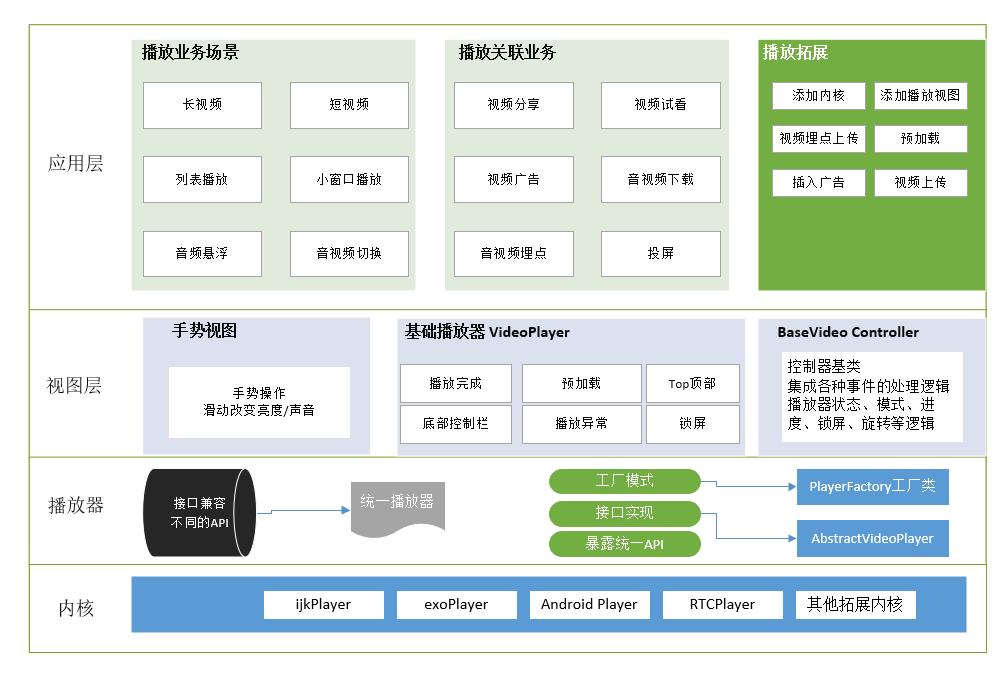
架构简介
用户界面(UI)定义了用户端的观看体验,包括“皮肤”(播放器的外观设计)、所有可自定义的特性(如播放列表和社交分享等)及业务逻辑部分(如广告、设备兼容性逻辑及认证管理等)。
播放器内核是最核心的部件,播放器最底层的部分是内核,如解码器等,这层的功能直接调用操作系统暴露出来的API。解码器的主要功能在于解码并渲染视频内容,DRM管理器则通过解密过程来控制是否有权播放。DRM即数字版权管理,是指数字内容,如音视频节目内容、文档、电子书籍等在生产、传播、销售、使用过程中进行的权利保护、使用控制与管理的技术。
用户界面
UI层处于播放器架构的上层,控制用户所能看到和交互的东西,为用户提供独特的用户体验。在UI内部,也包含业务逻辑组件,这些组件构成了播放体验的独特性,虽然用户端无法直接和这部分功能进行交互。UI部分主要包含3大组件。
(1)“皮肤”是对与播放器视觉相关部分的统称,包括进度控制条、按钮和动画图标等。和大部分设计类的组件一样,这部分组件也可以使用CSS实现,设计师或者开发者可以很方便地用来集成。
(2)UI逻辑部分。此部分定义了播放过程中和用户交互方面所有可见的交互,包括播放列表、缩略图、播放频道的选择和社交媒体分享等。
(3)业务逻辑部分,除了上面所介绍的两部分功能特性外,还有一个不可见的部分,这部分构成了业务的独特性,包括认证和支付、频道和播放列表的获取,以及广告等。
多媒体引擎
多媒体引擎以一种全新独立的组件形式出现在播放器架构中。在MP4时代,平台处理了所有与播放相关的逻辑,而只讲一部分与多媒体处理相关的特性(仅仅是播放、暂停、拖曳和全屏模式等功能)开放给开发者。然而新的基于HTTP的流媒体格式需要一种全新的组件来处理和控制新的复杂性,包括解析声明文件、下载视频片段、自适应码率监控及决策指定等甚至更多。
解码器和DRM管理器
出于解码性能和安全考虑,解码器和DRM管理器与操作系统平台密切绑定,其工作流程如下:

解码器用于处理与最底层播放相关的逻辑,它将不同封装格式的视频进行解包,并将其内容解码,然后将解码后的视频帧交给操作系统进行渲染,最终让用户端看到。由于视频压缩算法越来越复杂,解码过程需要密集计算过程,并且为了保证解码性能和流畅的播放体验,解码过程需要强依赖与操作系统和硬件。
DRM管理器管理付费内容,防止视频被盗版。因此DRM的代码和工作过程都向终端用户可开发者屏蔽了。解密过的内容不会离开解码层,因此也不会被拦截。
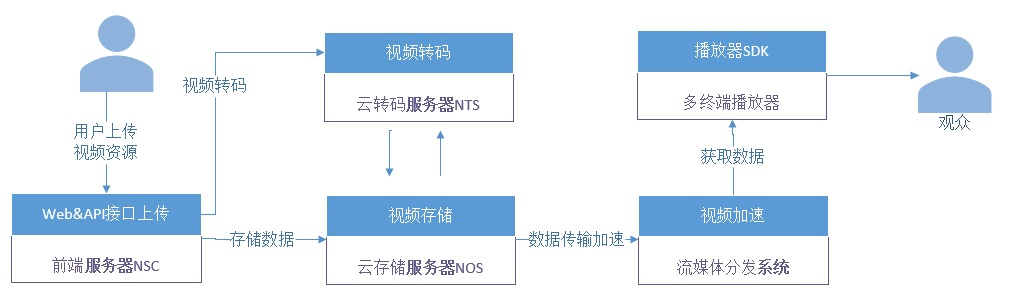
2.5.5 短视频技术
短视频技术主要涉及短视频拍摄端、播放端及合成、上传、转码、分发、加速、播放等操作,其架构如下: