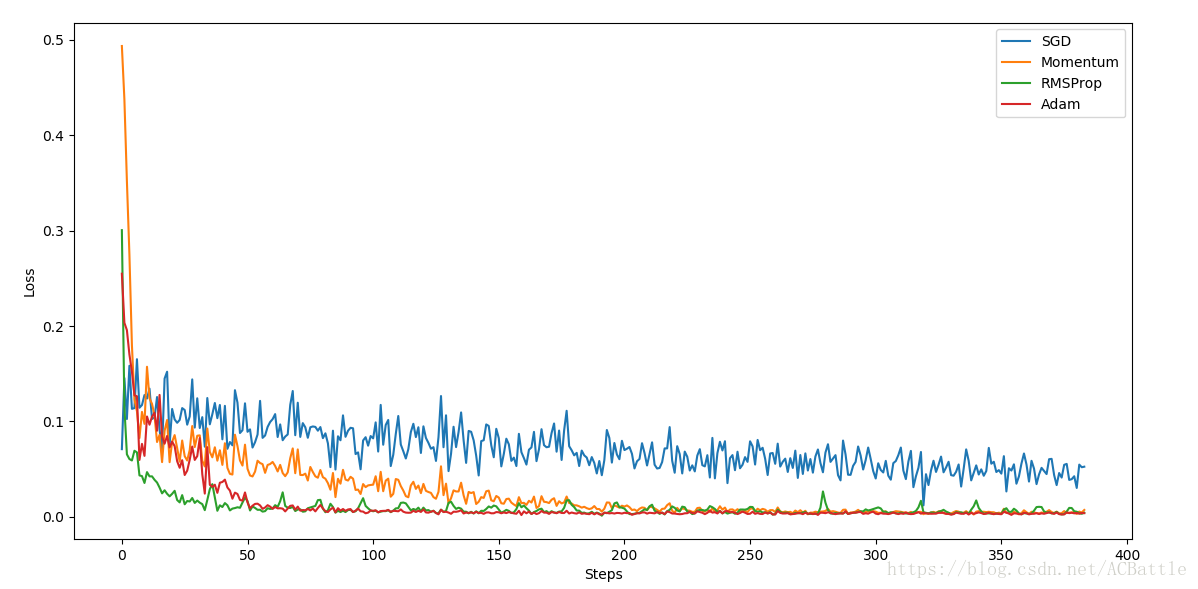
摘自here
优化器的参数有待进一步了解
import torch
from torch.autograd import Variable
import torch.nn.functional as F
import matplotlib.pyplot as plt
import torch.utils.data as Data
# super param
LR = 0.01
BATCH_SIZE=32
EPOCH=12
x = torch.unsqueeze(torch.linspace(-1,1,1000),dim = 1) #压缩为2维,因为torch 中 只会处理二维的数据
y = x.pow(2) + 0.2 * torch.rand(x.size())
print(x.numpy(),y.numpy())
torch_dataset = Data.TensorDataset(x, y)
loader = Data.DataLoader(
dataset = torch_dataset,
batch_size = BATCH_SIZE,
shuffle = True,# true表示数据每次epoch是是打乱顺序抽样的
num_workers = 2, # 每次训练有两个线程进行的????? 改成 1 和 2 暂时没看出区别
)
class Net(torch.nn.Module): # 继承 torch 的 Module
def __init__(self):
super(Net, self).__init__() # 继承 __init__ 功能
# 定义每层用什么样的形式
self.hidden = torch.nn.Linear(1,20) # 隐藏层线性输出
self.predict = torch.nn.Linear(20,1) # 输出层线性输出
def forward(self, x): # 这同时也是 Module 中的 forward 功能
# 正向传播输入值, 神经网络分析出输出值
x = F.relu(self.hidden(x)) # 激励函数(隐藏层的线性值)
x = self.predict(x) # 输出值
return x
net_SGD = Net()
net_Momentum = Net()
net_RMSProp = Net()
net_Adam= Net()
nets = [net_SGD,net_Momentum,net_RMSProp,net_Adam] # 一个比一个高级
opt_SGD = torch.optim.SGD(net_SGD.parameters(),lr=LR)
opt_Momentum = torch.optim.SGD(net_Momentum.parameters(),lr = LR,momentum=0.8) # 是SGD的改进,加了动量效果
opt_RMSProp = torch.optim.RMSprop(net_RMSProp.parameters(),lr=LR,alpha=0.9)
opt_Adam= torch.optim.Adam(net_Adam.parameters(),lr=LR,betas=(0.9,0.99))
optimizers = [opt_SGD, opt_Momentum, opt_RMSProp, opt_Adam]
# 比较这4个优化器会发现,并不一定越高级的效率越高,需要自己找适合自己数据的优化器
loss_func = torch.nn.MSELoss()
losses_his = [[],[],[],[]]
if __name__ == '__main__': # EPOCH + win10 需要if main函数才能正确运行,
for epoch in range(EPOCH):
print(epoch)
for step,(batch_x,batch_y) in enumerate(loader):
b_x = Variable(batch_x)
b_y = Variable(batch_y)
for net,opt,l_his in zip(nets, optimizers, losses_his):
output = net(b_x) # get_out for every net
loss = loss_func(output,b_y) # compute loss for every net
opt.zero_grad()
loss.backward()
opt.step() # apply gradient
l_his.append(loss.data[0]) # loss recoder
labels = ['SGD','Momentum','RMSProp','Adam']
for i,l_his in enumerate(losses_his):
plt.plot(l_his,label=labels[i])
plt.legend(loc='best')
plt.xlabel('Steps')
plt.ylabel('Loss')
plt.ylim = ((0,0.2))
plt.show()