1.字符串
字符串可以使用下标 (索引); 就像 C 一样, 字符串的第一个字符的下标 (索引) 为 0. 索引可以是负数, 那样就会从右边开始算起.(但是要注意, -0 与 0 是完全一样的, 因此它不会从右边开始数!)
如果字符串里面有很多字符都需要转义,就需要加很多\,为了简化,Python还允许用r’ ‘表示’ ‘内部的字符串默认不转义,
如果字符串内部有很多换行,用\n写在一行里不好阅读,为了简化,Python允许用”’…”’的格式表示多行内容
空值是Python里一个特殊的值,用None表示。None不能理解为0,因为0是有意义的,而None是一个特殊的空值。
对于单个字符的编码,Python提供了ord()函数获取字符的整数表示,chr()函数把编码转换为对应的字符:
>>> ord('A')
65
>>> chr(66)
'B'由于Python的字符串类型是str,在内存中以Unicode表示,一个字符对应若干个字节。如果要在网络上传输,或者保存到磁盘上,就需要把str变为以字节为单位的bytes。
Python对bytes类型的数据用带b前缀的单引号或双引号表示:
x = b'ABC'要注意区分’ABC’和b’ABC’,前者是str,后者虽然内容显示得和前者一样,但bytes的每个字符都只占用一个字节。
- 以Unicode表示的str通过encode()方法可以编码为指定的bytes,例如:
>>> 'ABC'.encode('ascii')
b'ABC'
>>> '中文'.encode('utf-8')
b'\xe4\xb8\xad\xe6\x96\x87'
>>> '中文'.encode('ascii')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128)- 纯英文的str可以用ASCII编码为bytes,内容是一样的
- 含有中文的str可以用UTF-8编码为bytes。
- 含有中文的str无法用ASCII编码,因为中文编码的范围超过了ASCII编码的范围,Python会报错。
在bytes中,无法显示为ASCII字符的字节,用\x##显示。
反过来,如果我们从网络或磁盘上读取了字节流,那么读到的数据就是bytes。要把bytes变为str,就需要用decode()方法:
>>> b'ABC'.decode('ascii')
'ABC'
>>> b'\xe4\xb8\xad\xe6\x96\x87'.decode('utf-8')
'中文'如果bytes中包含无法解码的字节,decode()方法会报错:
>>> b'\xe4\xb8\xad\xff'.decode('utf-8')
Traceback (most recent call last):
...
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xff in position 3: invalid start byte- 如果bytes中只有一小部分无效的字节,可以传入errors=’ignore’忽略错误的字节:
>>> b'\xe4\xb8\xad\xff'.decode('utf-8', errors='ignore')
'中'在操作字符串时,我们经常遇到str和bytes的互相转换。为了避免乱码问题,应当始终坚持使用UTF-8编码对str和bytes进行转换。
- 格式化
在Python中,采用的格式化方式和C语言是一致的,用%实现,举例如下:
>>> 'Hi, %s, you have $%d.' % ('Michael', 1000000)
'Hi, Michael, you have $1000000.'%运算符就是用来格式化字符串的。在字符串内部,%s表示用字符串替换,%d表示用整数替换,有几个%?占位符,后面就跟几个变量或者值,顺序要对应好。如果只有一个%?,括号可以省略。
- format()
另一种格式化字符串的方法是使用字符串的format()方法,它会用传入的参数依次替换字符串内的占位符{0}、{1}……,不过这种方式写起来比%要麻烦得多:
>>> 'Hello, {0}, 成绩提升了 {1:.1f}%'.format('小明', 17.125)
'Hello, 小明, 成绩提升了 17.1%'
- 字符串常用功能:
移除空白 分割 长度 索引 切片
2.列表
创建列表:
name_list = [‘alex’, ‘seven’, ‘eric’]
或
name_list = list([‘alex’, ‘seven’, ‘eric’])
list.append(obj) 在列表末尾添加新的对象
list.count(obj) 统计某个元素在列表中出现的次数
list.extend(seq) 在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表)
list.index(obj) 从列表中找出某个值第一个匹配项的索引位置,索引从0开始
list.insert(index, obj) 将对象插入列表
list.pop(obj=list[-1]) 移除列表中的一个元素(默认最后一个元素),并且返回该元素的值
list.remove(obj) 移除列表中某个值的第一个匹配项
list.reverse() 反向列表中元素,倒转
list.sort([func]) 对原列表进行排序
- 基本操作:
索引 切片 追加 删除 长度 切片 循环 包含 list
3.元祖
创建元祖:
ages = (11, 22, 33, 44, 55)
或
ages = tuple((11, 22, 33, 44, 55))
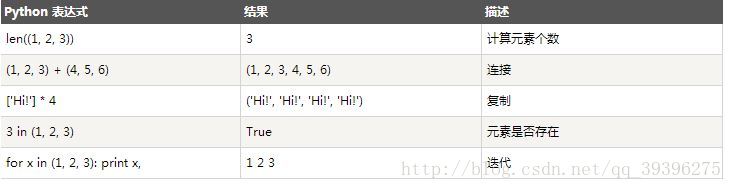
cmp(tuple1, tuple2) 比较两个元组元素。
len(tuple) 计算元组元素个数。
max(tuple) 返回元组中元素最大值。
min(tuple) 返回元组中元素最小值。
tuple(seq) 将列表转换为元组。- 如果要定义一个空的tuple,可以写成():
>>> t = ()
>>> t
()- 但是,要定义一个只有1个元素的tuple,如果你这么定义:
>>> t = (1)
>>> t
1定义的不是tuple,是1这个数!这是因为括号()既可以表示tuple,又可以表示数学公式中的小括号,这就产生了歧义,因此,Python规定,这种情况下,按小括号进行计算,计算结果自然是1。
- 所以,只有1个元素的tuple定义时必须加一个逗号,,来消除歧义:
>>> t = (1,)
>>> t
(1,)
- 基本操作:
索引 切片 循环 长度 包含
4.字典(无序)
字典(dictionary)是除列表之外python中最灵活的内置数据结构类型。列表是有序的对象结合,字典是无序的对象集合。两者之间的区别在于:字典当中的元素是通过键来存取的,而不是通过偏移存取。
每个键与值必须用冒号隔开(:),每对用逗号分割,整体放在花括号中({})。键必须独一无二,但值则不必;值可以取任何数据类型,但必须是不可变的,如字符串,数或元组。字典由键和对应的值组成。字典也被称作关联数组或哈希表。
创建字典:
person = {“name”: “mr.wu”, ‘age’: 18}
或
person = dict({“name”: “mr.wu”, ‘age’: 18})
访问字典里的值
常用操作:
索引 新增 删除 键、值、键值对 循环 长度
cmp(dict1, dict2) 比较两个字典元素。
len(dict) 计算字典元素个数,即键的总数。
str(dict) 输出字典可打印的字符串表示。
type(variable) 返回输入的变量类型,如果变量是字典就返回字典类型。
radiansdict.clear() 删除字典内所有元素
radiansdict.copy() 返回一个字典的浅复制
radiansdict.fromkeys() 创建一个新字典,以序列seq中元素做字典的键,val为字典所有键对应的初始值
radiansdict.get(key, default=None) 返回指定键的值,如果值不在字典中返回default值
radiansdict.has_key(key) 如果键在字典dict里返回true,否则返回false
radiansdict.items() 以列表返回可遍历的(键, 值) 元组数组
radiansdict.keys() 以列表返回一个字典所有的键
radiansdict.setdefault(key, default=None) 和get()类似, 但如果键不已经存在于字典中,将会添加键并将值设为default
radiansdict.update(dict2) 把字典dict2的键/值对更新到dict里
radiansdict.values() 以列表返回字典中的所有值