三HDFS分布式文件系统
HDFS系统结构 、HDFS存储原理,与数据读写过程
3.1 HDFS简介
HDFS: Hadoop distributed file system
两大核心(分布存储与分布处理)技术之一
分布式文件系统
单机无法存储,借助集群来存储
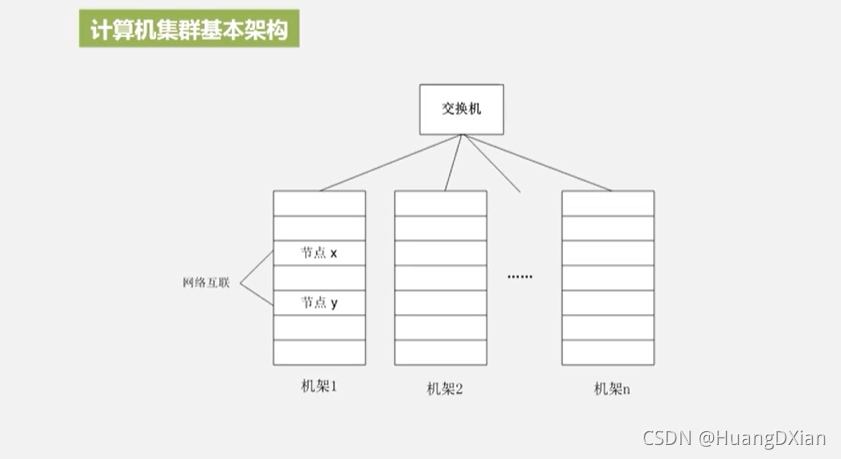
计算机集群基本架构
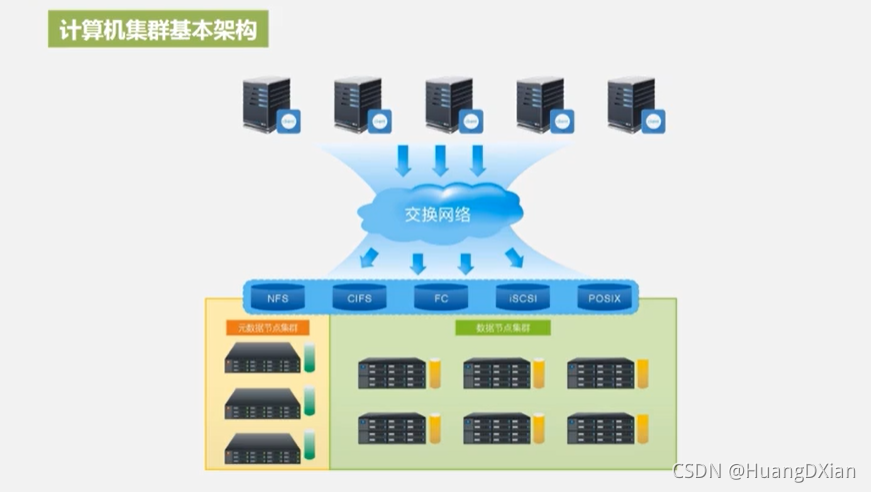
文件系统结构
设计目标

hdfs自身局限性

3.2HDFS相关概念
块:64-128M

缺点:

设计优点:
1.切块存储大文件
2.简化系统设计
3.对数据备份

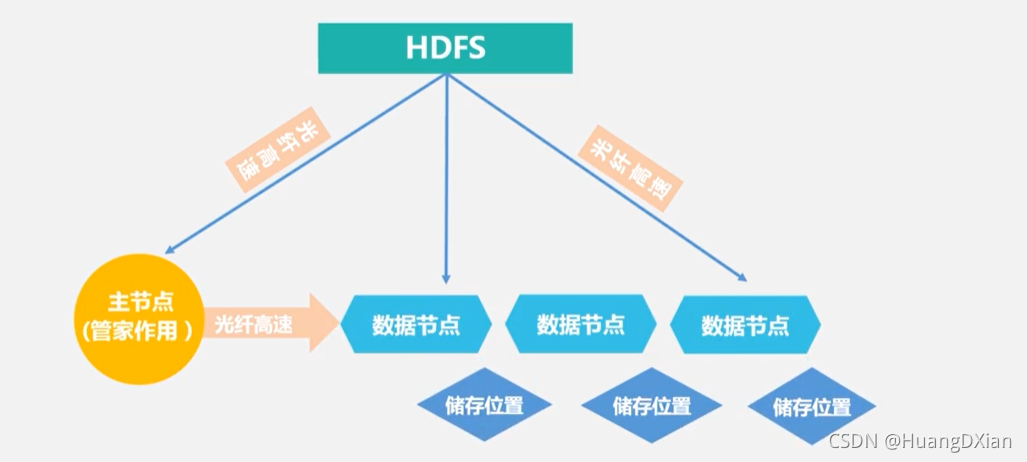
HDFS 两大组件
NameNode 与 DataNode
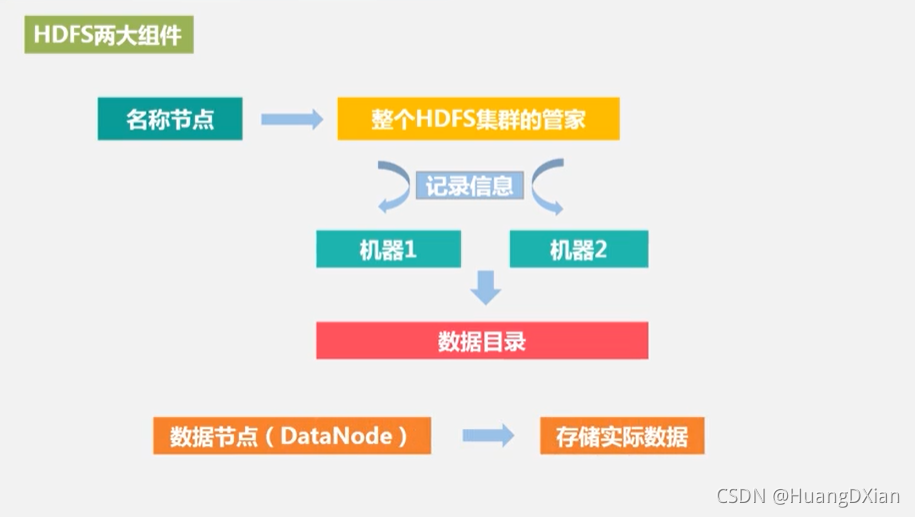
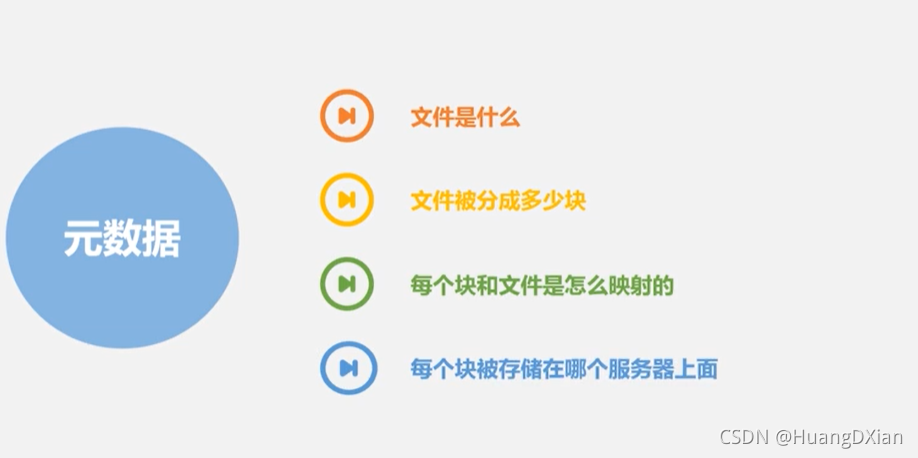
元数据
一个hdfs节点称为元数据
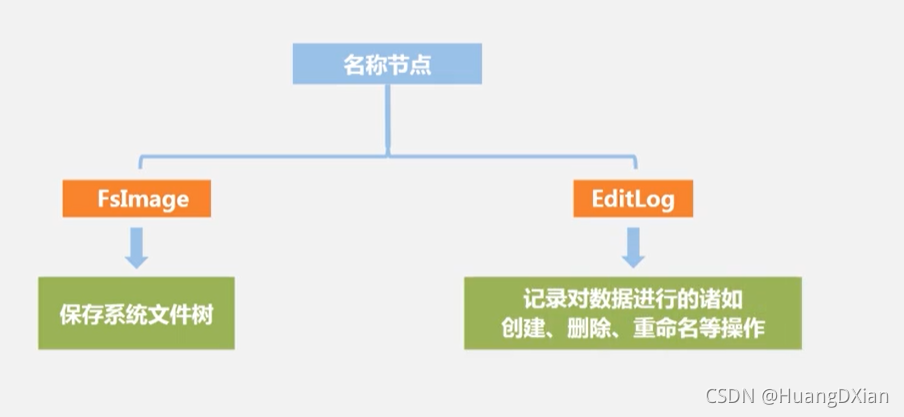
名称节点:
FsImage :系统文件数
EditLog:对数据创建、删除、重命名
fsImage不维护信息在哪里储存,单独保存,铜鼓名称节点与数据节点实时沟通来维护这个信息。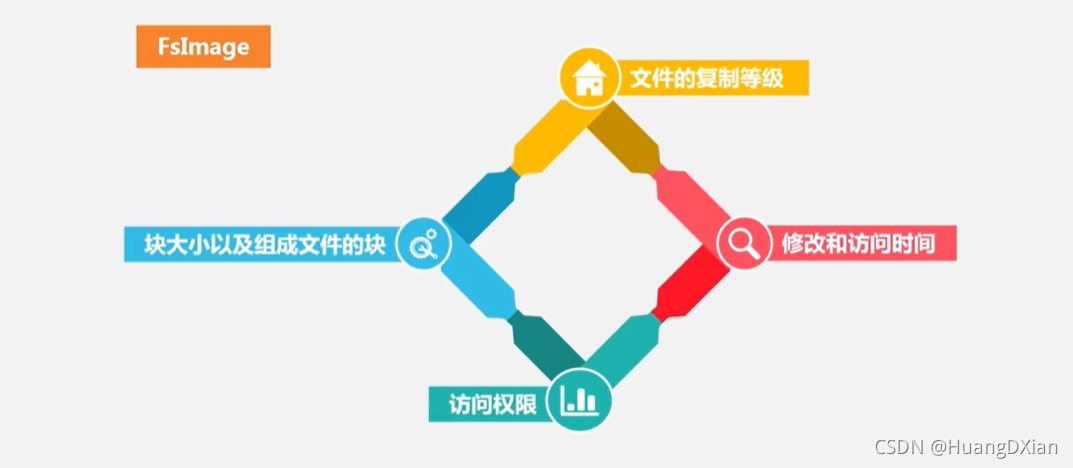
运行流程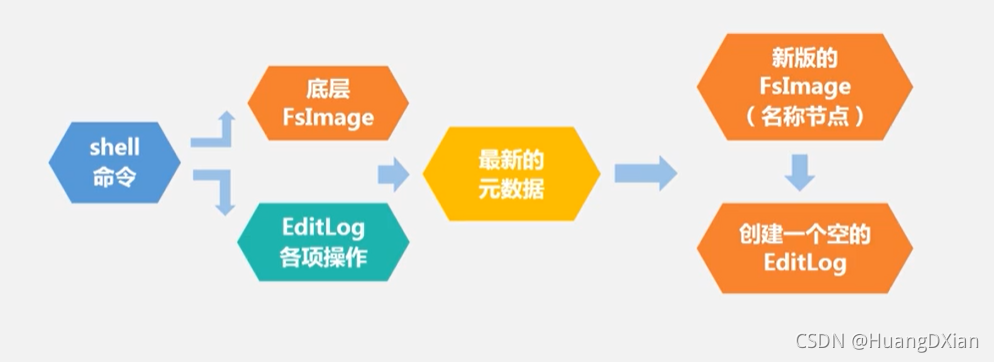
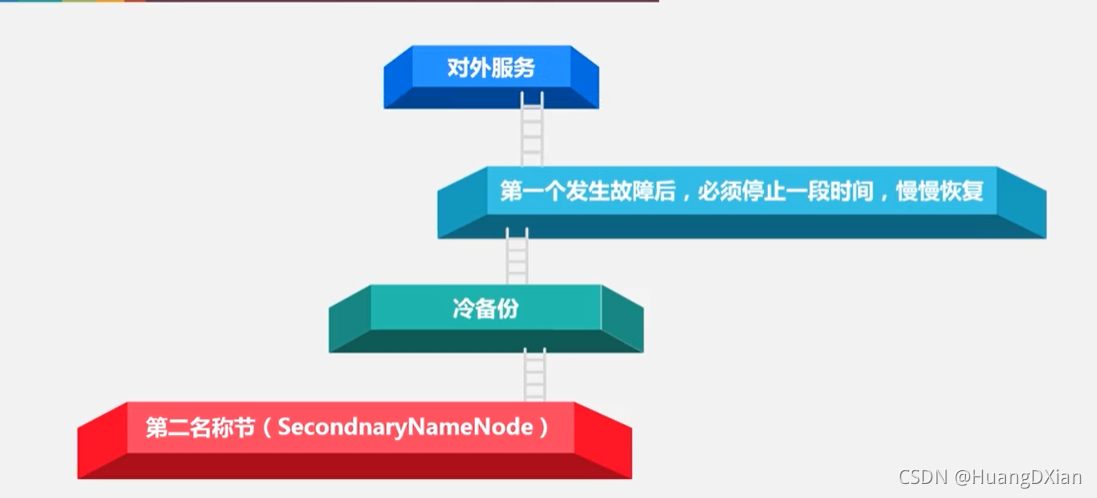
导致EditLog不断增大,引入secondaryNode

对editlog处理
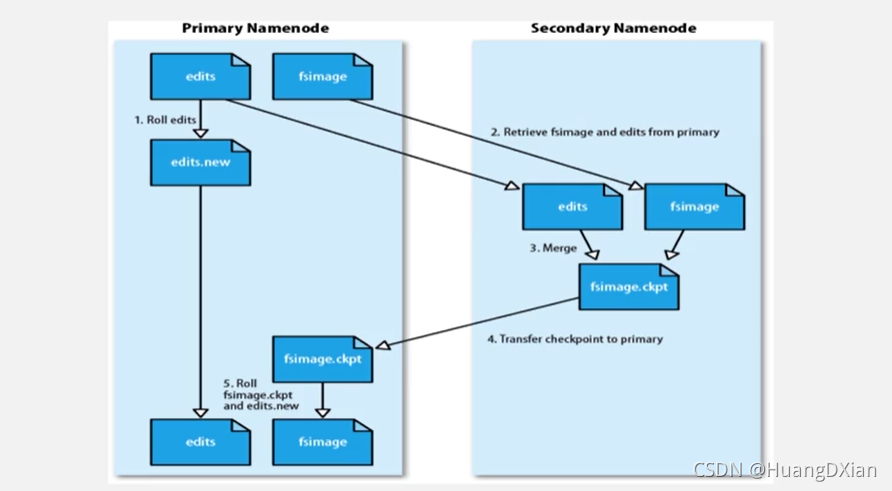
第二节点定期与名称节点进行通信

停止写旧的editlog后,名称节点创建新的edit.new,第二节点获取http get方式获取FsIamge与EditLog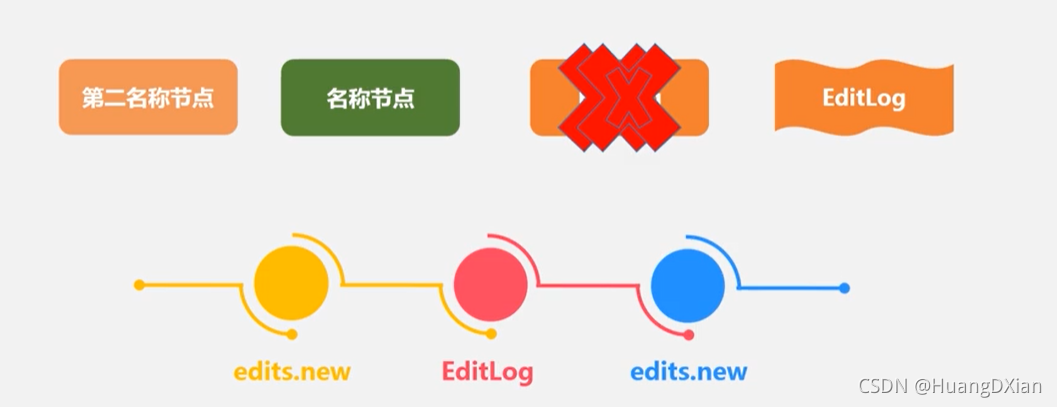
第二节点会和平成新的FSImage传给名称节点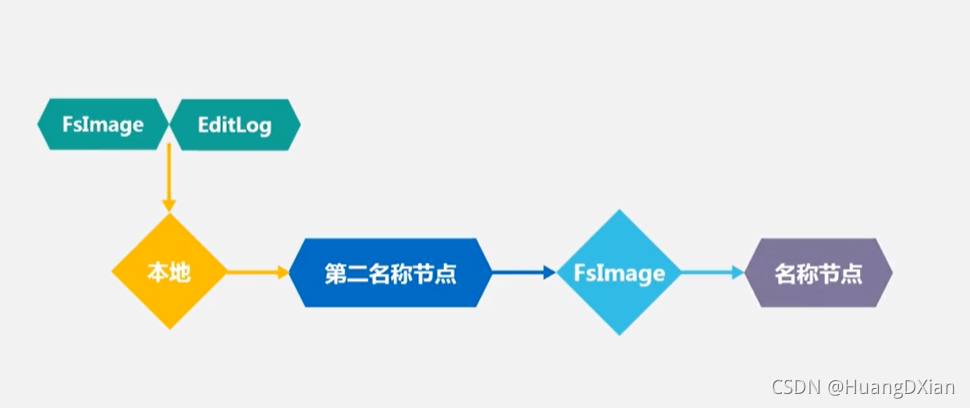
名称节点最后将Edit.new 更改为新的EditLog

数据节点
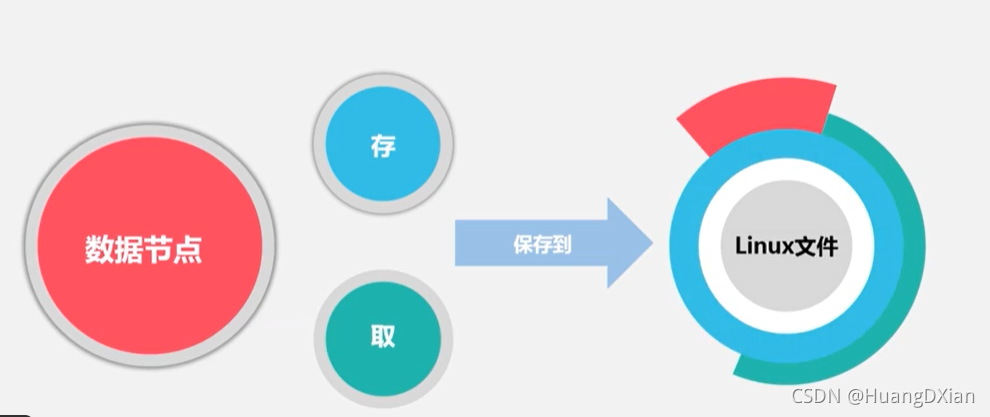
3.3 HDFS体系结构
命名空间与文件类似,层次目录

HDFS通信协议

局限性
1.所有数据保存在内存中,内存有上限
2. 吞吐受到单节点限制
3. 隔离空间问题,只有一个命名空间
4. 集群单点故障
5.

为了改进HDFS2.0,做出了热备与名称节点

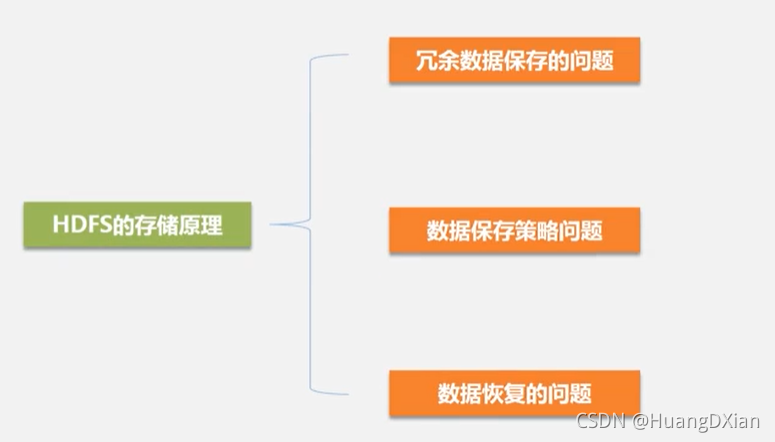
3.4HDFS存储原理
- 冗余数据保存
- 数据保存策略
- 数据恢复
廉价机器容易出问题,一块保存三块(默认)可以设置为1,2,3,4
伪分布式:名称节点和数据节点放同一机器上,冗余因子为1
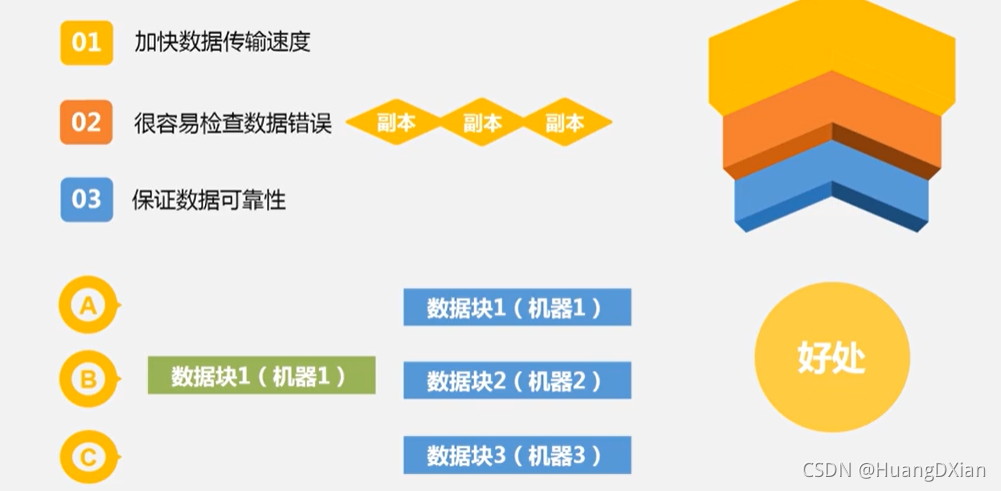
好处:
1.加快传输速度
2.容易检查数据错误
3.数据可靠性
块: 节点为机器,
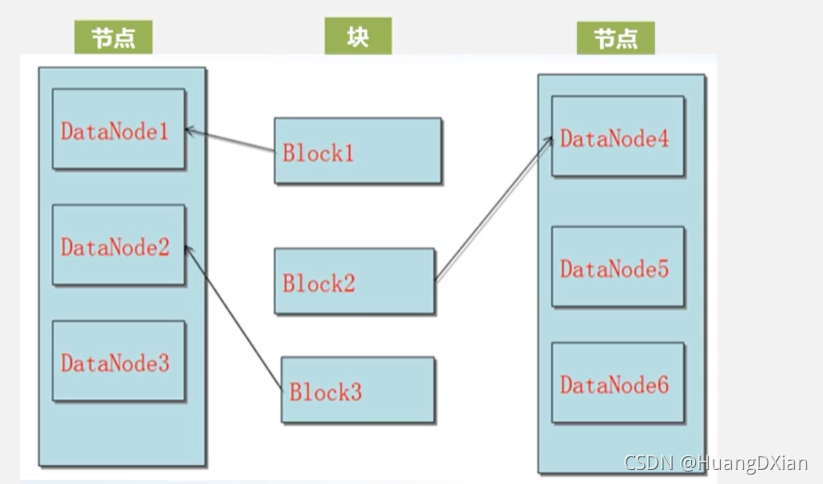
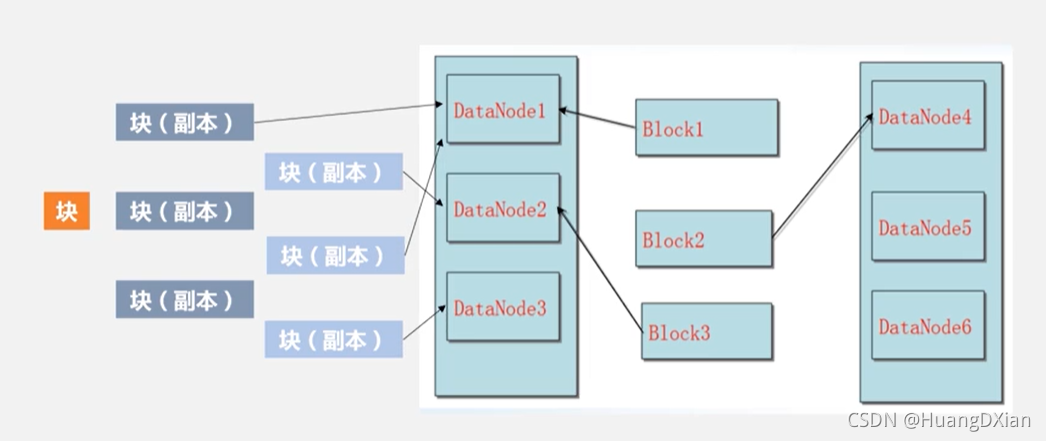
数据存储:
第一块来了后,复制为3份
第一副本:哪个要就放到哪个节点,外部请求则选不满数据,处理不忙的节点上
第二副本:放在不同一副本节点上面去,
第三节点:放在一副本相同节点不同datanode上
数据读取:就近原则
HDFS提供API确定数据节点所属机架的ID,客户端可调用API获取自己所属机架ID

数据错误和恢复
名称节点出错

数据节点出错:
定期向NameNode发送消息,不发送消息则出故障
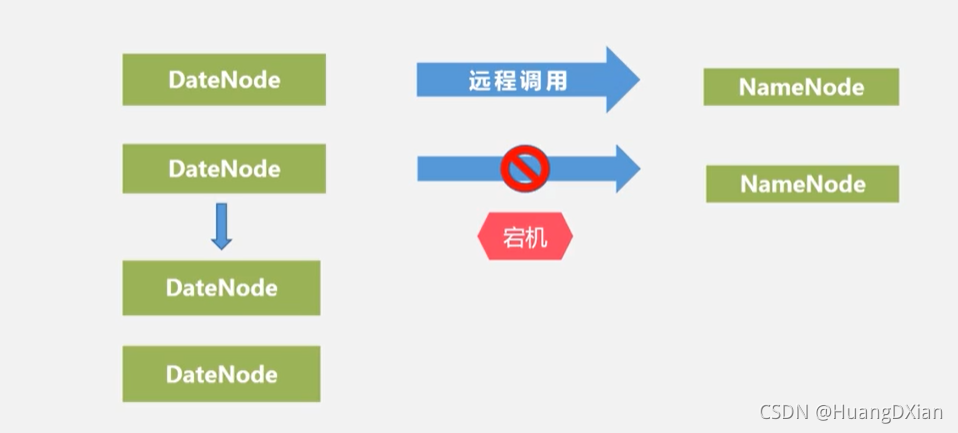
负载均衡
数据本身出错:校验码校验

3.5 HDFS数据的读写
代码示意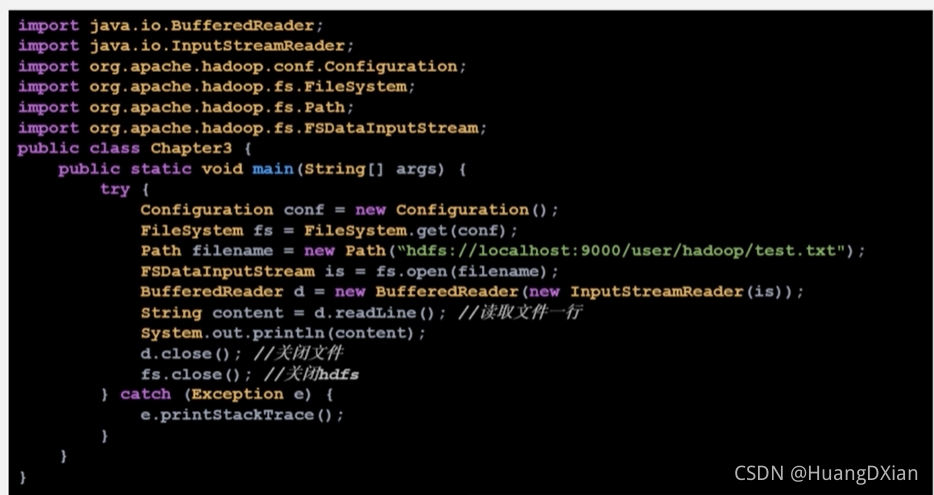
背后原理:
Hadoop 中有FileSyetem 父类 派生子类
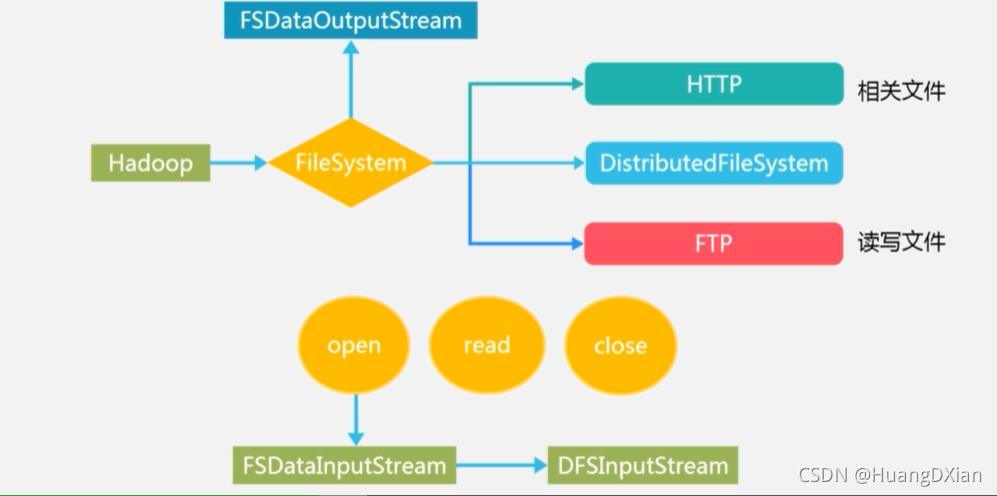
定义类加载配置文件
1,2,3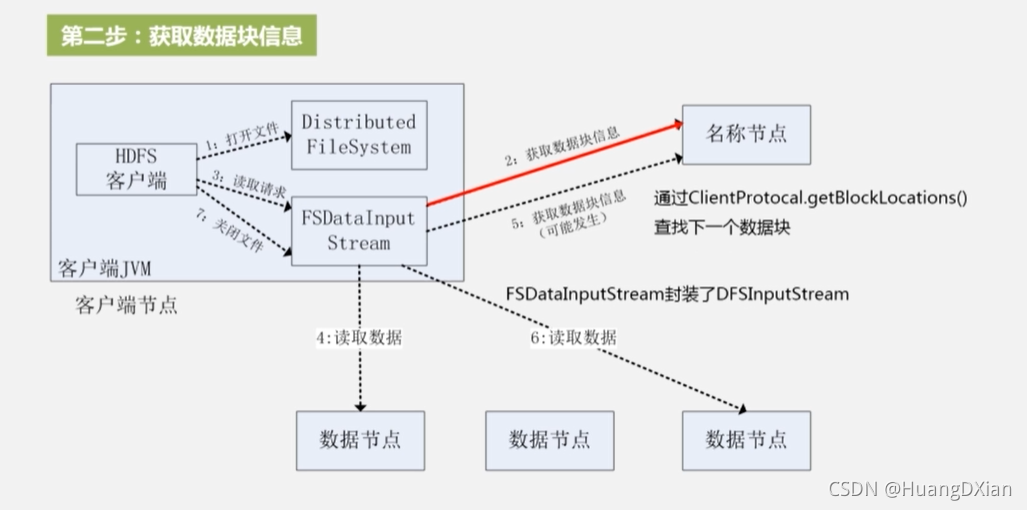
4,5,6
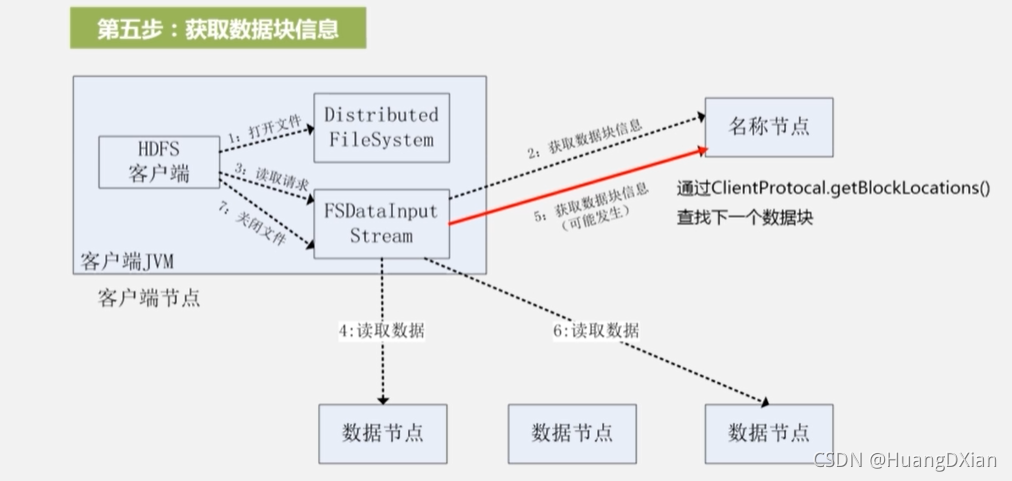
7,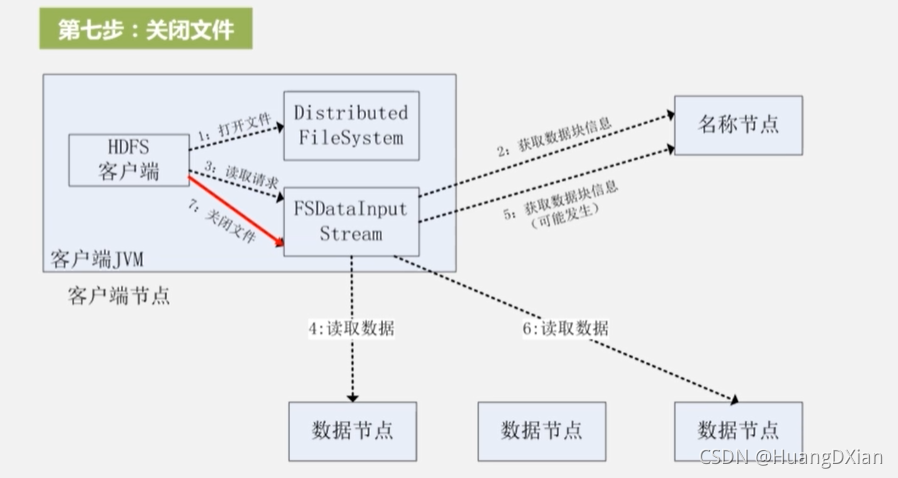
3.6hdfs编程实践
利用设立了命令与HDFS进行交互
1. hadoop fs:
适用于任何不同文件系统,比如本地文件系统和HDFS文件系统
2. hadoop dfs
只适用于HDFS文件系统
3. hdfs dfs
只适用于hdfs文件系统
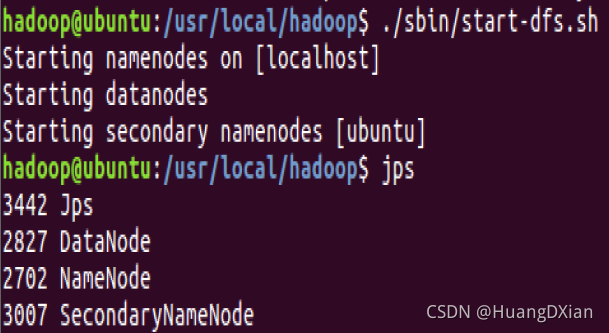
正常开启Hadoop 进入安装文件/usr/local/hadoop
./sbin/start-dfs.sh 进行启动
使用jps 查看启动情况
第一步为Hadoop创建家目录,在上一步的操作目录下使用以下命令
./bin/hdfs dfs -mkdir -p /user/hadoop
# -p 为创建多层目录
#然后查看创建情况
./bin/hdfs dfs -ls /
# 在hadoop家目录 (/user/hadoop/ 可以使用 “." 来代替)
直接使用 ./bin/hdfs dfs mkdir ** 相当于在家目录下创建子目录**)
删除命令
#删除命令 和上面 -mkdir相似 替换成 -rm
./bin/hdfs dfs -rm -r /user/hadoop
加-r 表示删除文件夹
hdfs与本地文件系统传递文件
将ubantu 本地桌面文件传入到Hadoop中去
# 进入Hadoop工作目录(设置环境变量可省略此步)
./bin/hdfs dfs -put ~/Desktop/mylocalfile
# 查看结果
./bin/hdfs dfs -ls .
在这里插入代码片

** 从 hdfs 中文件下载到本地**
./bin/hdfs dfs -get /user/hadoop/mylocalfile ~/Desktop
#第一目录为hdfs目录,第二为本地文件目录
** 在hdfs中进行文件移动复制**
# 在hadoop 操作目录下
./bin/hdfs dfs -cp + 源文件地址 目的地址
3.7 hdfs web UI界面管理
默认端口为 9870
在浏览器 输入 127.0.0.1:9870 即可打开
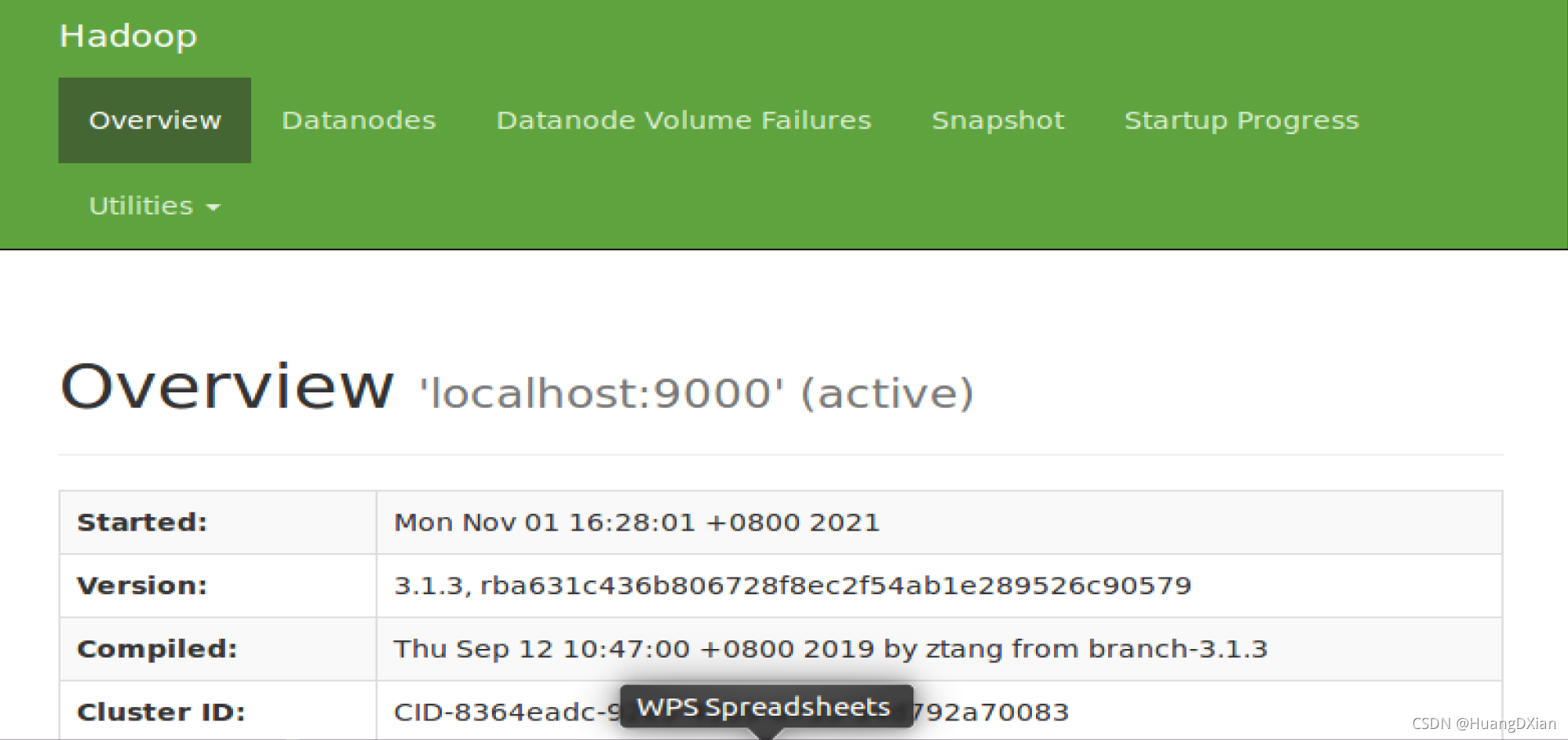
在此界面可以查看相应的信息。