2021年 中国图象图形学报
摘 要
背景: 视频异常行为检测是智能监控技术的研究重点,广泛应用于社会安防领域。当前的挑战之一是如何提高异常检测的准确性,这需要有效地建模视频数据的空间维度和时间维度信息。生成对抗网络(GANs)因其结构优势而被广泛应用于视频异常行为检测。
方法: 本文提出了一种改进的生成对抗网络方法,用于视频异常行为检测。该方法在生成对抗网络的生成网络 U-net 部分引入了门控自注意力机制,用于逐层分配特征图的权重,以更好地融合了 U-net 网络和门控自注意力机制的性能优势。这有助于抑制与异常检测任务无关的背景区域特征,突出不同目标对象的相关特征表达,更有效地建模了视频数据的时空维度信息。方法还包括使用 LiteFlownet 网络提取视频流中的运动信息,以保持视频序列之间的连续性。此外,引入了强度损失函数、梯度损失函数和运动损失函数,以增强模型的检测稳定性,从而实现对视频异常行为的检测。
实验结果: 作者在多个视频异常事件数据集上进行了实验验证,包括 CUHK Avenue、UCSD Ped1 和 UCSD Ped2 数据集。实验结果显示,本文方法在 CUHK Avenue 数据集上的 AUC 达到了 87.2%,比同类方法提高了2.3%。在 UCSD Ped1 和 UCSD Ped2 数据集上,本文方法的 AUC 值也高于其他方法。作者还进行了消融实验,并比较了实验结果,验证了本文方法的有效性和性能优势。
结论: 实验结果表明,本文提出的方法更适合视频异常行为检测任务,它有效地提高了异常行为检测模型的稳定性和准确性。同时,使用视频序列帧间的运动信息可以显著提升异常行为检测性能。
0 引言
视频中的异常检测是指在监控视频中识别不符合预期的行为事件。这一领域的应用广泛,包括智能安防、智能家居和医学康复等,具有重要的研究意义和实际价值。视频异常检测面临多个挑战:
- 异常行为的多样性:异常行为在视频中可以有各种各样的形式,难以将其全部列举或描述。
- 低概率事件:异常事件在视频中的发生概率通常较低,这使得异常行为的学习变得更加困难。
- 特征学习难度:由于异常行为的多样性和低概率,对所有可能的异常行为进行特征学习几乎是不可行的。
传统的视频异常行为检测方法需人工提取视频中目标对象的表观轮廓、运动信息和轨迹等特征,如梯度直方图( histogram of oriented gradient,HOG) 可 表示目标对象表观轮廓的特征信息( Li 等,2015) , 通过光流特征图可捕捉目标对象的运动信息特征 ( Li 等,2015) ; 通过轨迹可提取运动目标的轨迹特 征( Ahmed 等,2019) 。但此类方法在表示形式上较 为单一且无法学习预期之外事件的特征,同时处理海量视频数据能力较弱,已较难得到新的突破。
基于深度学习的方法越来越多地应用于视频异常行为检测,可通过自动从海量数据集中学习数据 本身的分布规律来提取出更加鲁棒的高级特征,已 取代基于人工构建行为特征的传统方法。目前,基 于深度学习的监控视频异常行为检测方法主要分为 重构判别和未来帧预测两类。
基于重构判别的方法认为,通过模型训练学习 正常样本在样本空间服从的分布,符合该分布的正 常样本都能较好地重构,重构误差大的样本属于异 常样本( 胡海洋 等,2020) 。Hasan 等人( 2016) 利用 卷积自编码器( convolution auto-encoder,CAE) 对目 标帧进行误差重构来检测视频中的异常行为; Luo等人( 2017 ) 通 过 利 用 卷 积 长 短 期 记 忆 自 编 码 器 ( convolution long-short term memory auto-encoder,Conv LSTM-AE) 重构目标对象的外观信息和运动信 息进行异常行为检测,提出将稀疏编码映射到堆叠 的循环神经网络 ( stacked recurrent neural network,sRNN) 框架中重构异常行为。但由于深度学习方法 具有强大的学习能力,对正常事件和异常事件的重 构结果是相似的,此类方法并不能保证对异常事件 的重构误差一定很大。因此,几乎所有基于重构误 差的方法都不能保证准确检测出异常事件。
基于未来帧预测的方法假设正常行为是有规律 的且是可预测的,而视频中异常行为事件由于其不 确定性不可预测。该类方法可通过生成未来目标帧 的预测帧,将其与对应的视频真实帧进行对比来判 断该视频中是否包含异常行为。目前,生成对抗网 络( generative adversarial network,GAN) 在视频异常 检测领域已取得突破性进展,其网络架构可很好地 用于预测。Liu 等人( 2018) 提出基于 U-net 的条件 生成对抗网络进行异常行为检测,同时加入 Flownet光流网络对运动特征约束; Dong 等人( 2020) 在此基 础上提出基于对偶生成对抗网络模型,利用双生成 器和双鉴别器的对偶结构分别对外观和运动信息进 行异常判别; Nguyen 等人( 2019) 提出采用卷积自编 码器学习空间结构,将空间特征输入 U-net 中与运 动信息相关联从而进行异常检测。
基于生成对抗网络的视频异常行为检测方法通 过生成器 U-net 的良好性能捕获了训练样本空间特 征,但仍存在一定的局限性( 马钰锡 等,2019) ,主要 表现为: 1) 虽然已能够检测出视频中的异常行为,但如何有效建模空间维度信息和时间维度信息提高 异常检测的精度仍是目前研究领域的重难点; 2) 针 对目标对象的空间特征的提取,基础的 U-net 无法 建立长距离依赖性,不能将特征信息进行有效连接;3) 除数据样本的空间特征外,时间信息也是视频的 一个重要特征。现有大多数工作对视频的时间信息 特征利用不够充分。
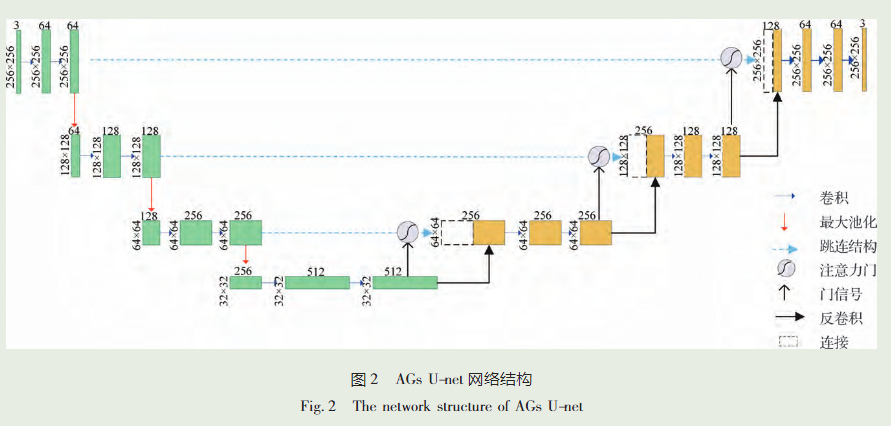
为了更好地解决此问题,本文提出一种融合门 控自注意力机制的生成对抗网络方法,在 U-net 生 成器部分中逐层引入门控自注意力机制来更好地学 习视频样本的空间维度信息,同时采用 LiteFlownet网络来对视频样本的时间维度信息进行更好地提 取。但该模型易受噪声影响,需同时加入强度损失 函数、梯度损失函数和运动损失函数加强模型检测 的稳定性以实现对异常行为的检测。
本文的贡献主要有以下 3 个方面: 1) 考虑视频序列帧之间的时间和空间 2 维关系,提出一种改进 的异常行为检测模型。利用生成对抗网络中的生成 模块对视频中的空间特征进行提取,利用 LiteFlownet 光流网络对运动信息的时间特征进行提取,引入门控自注意力机制对特征图进行加权处理,实现了 视频序列之间时空特征更有效的表达。2 ) 引入门控自注意力机制,逐层对 U-net 采样过程中的特征 进行加权计算。该自注意力机制在视频帧的单层特 征中对远距离且具有空间相关性的特征进行建模, 可自动寻找图像特征中的相关部分,提高对视频帧 中时间和空间两个维度的特征响应。3) 选用 LiteFlownet 光流网络对运动信息进行提取,得到视频帧 之间的时间关联,进一步提高了该模型的检测性能。
2 方法
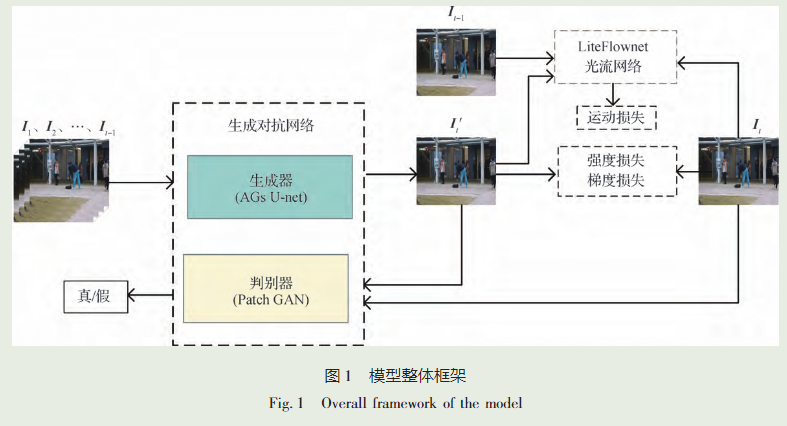
模型组成部分: 融合门控自注意力机制的生成对抗网络模型包括以下 4 部分:
- 生成模块:使用引入了门控注意力机制的 U-net 模型(AGs U-net)来生成预测帧。
- 损失约束模块:用于施加损失约束,包括强度损失和梯度损失函数,以进行空间约束。
- 对抗训练模块:利用马尔可夫判别器(Patch GAN)进行训练,通过对抗学习来优化模型。
- 异常判别模块:用于识别异常行为。
训练数据: 模型的训练数据包括正常视频帧序列,其中连续 t - 1 帧的正常视频帧按时间顺序堆叠起来,作为训练视频 I1 ,I2 ,...,It -1 ,用于输入生成器网络 AGs U-net,以预测下一帧(I't)。同时,真实帧(It)也用于训练和比较。
损失函数: 为了更好地预测正常行为下一帧,采用强度损失和梯度损失函数进行空间约束。这些损失函数有助于提高模型的性能。
运动信息处理: 为了增强相邻帧之间的运动特征相关性,采用了 LiteFlownet 光流网络,以更快速和平滑的方式提取运动信息,从而可以更准确地预测正常行为的下一帧。
异常检测: 当有异常行为样本输入时,模型将正常模式下的预测帧与实际真实值进行比较,如果误差较大,则异常分数下降,从而识别该事件样本为异常事件。

本文模型的整体框架如图 1 所示。