我们先了解一下有哪些内存
1.storage内存 存储数据,缓存 可预估
2.shuffle内存 计算join groupby 不可预估
spark1.6之前 静态管理的,spark1.6之后变成动态管理 默认0.5
温馨提示
在公司尽量不要写rdd(性能不好)
RDD示范(spark版本2.1.1)
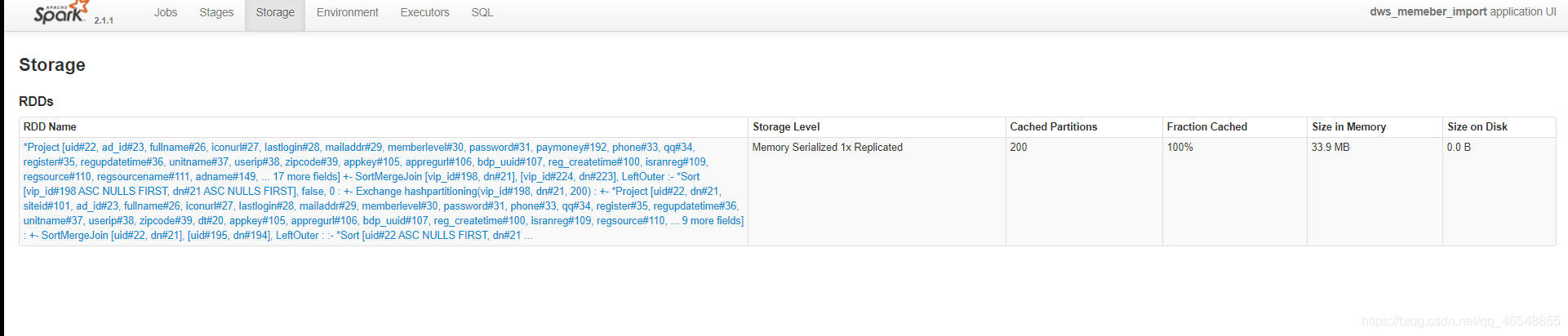
我们转成rdd去跑任务,看看内存占有多大
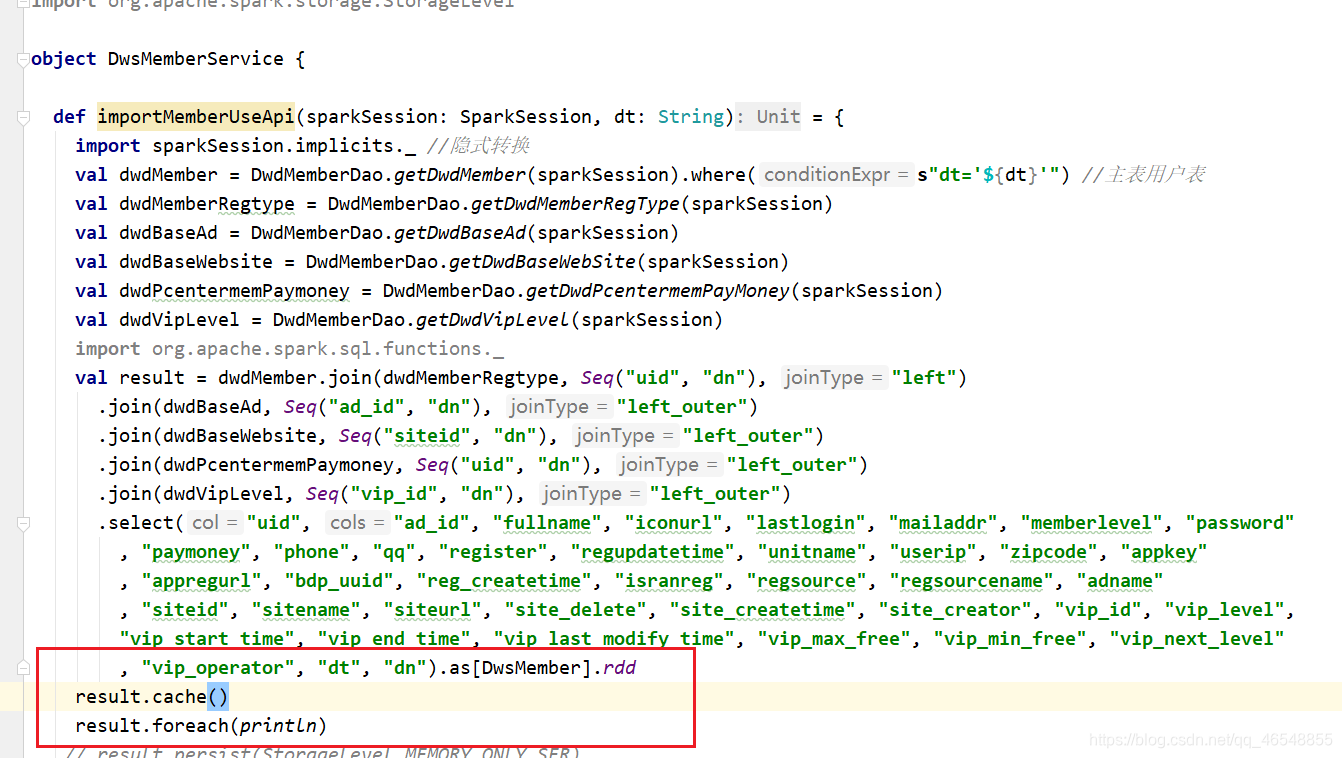

我们也可以去excutor看内存大小
显示红色,是因为我写了while循环

RDD进行优化
看官网
https://spark.apache.org/docs/2.4.5/configuration.html#compression-and-serialization
我们采用kryo(只支持rdd)

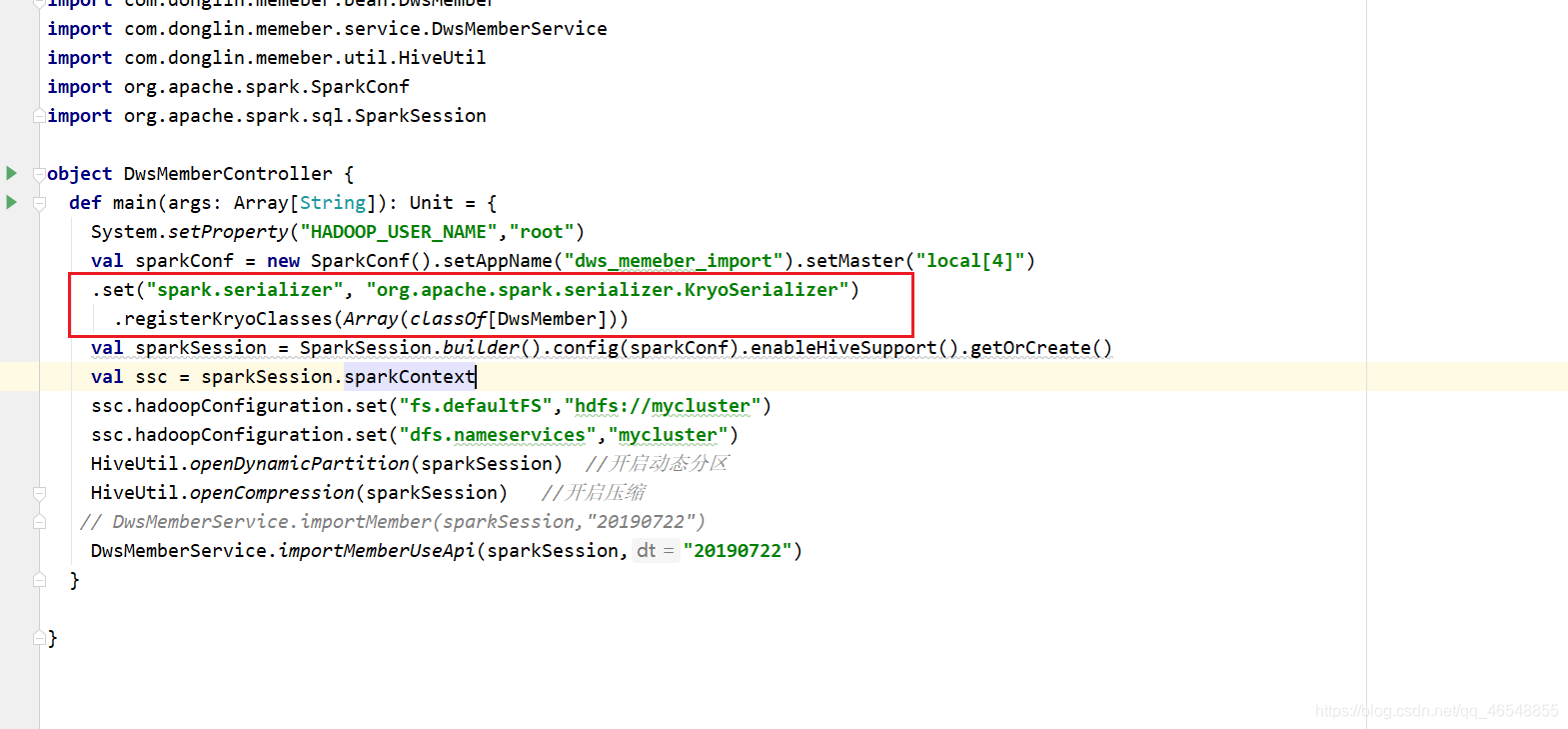
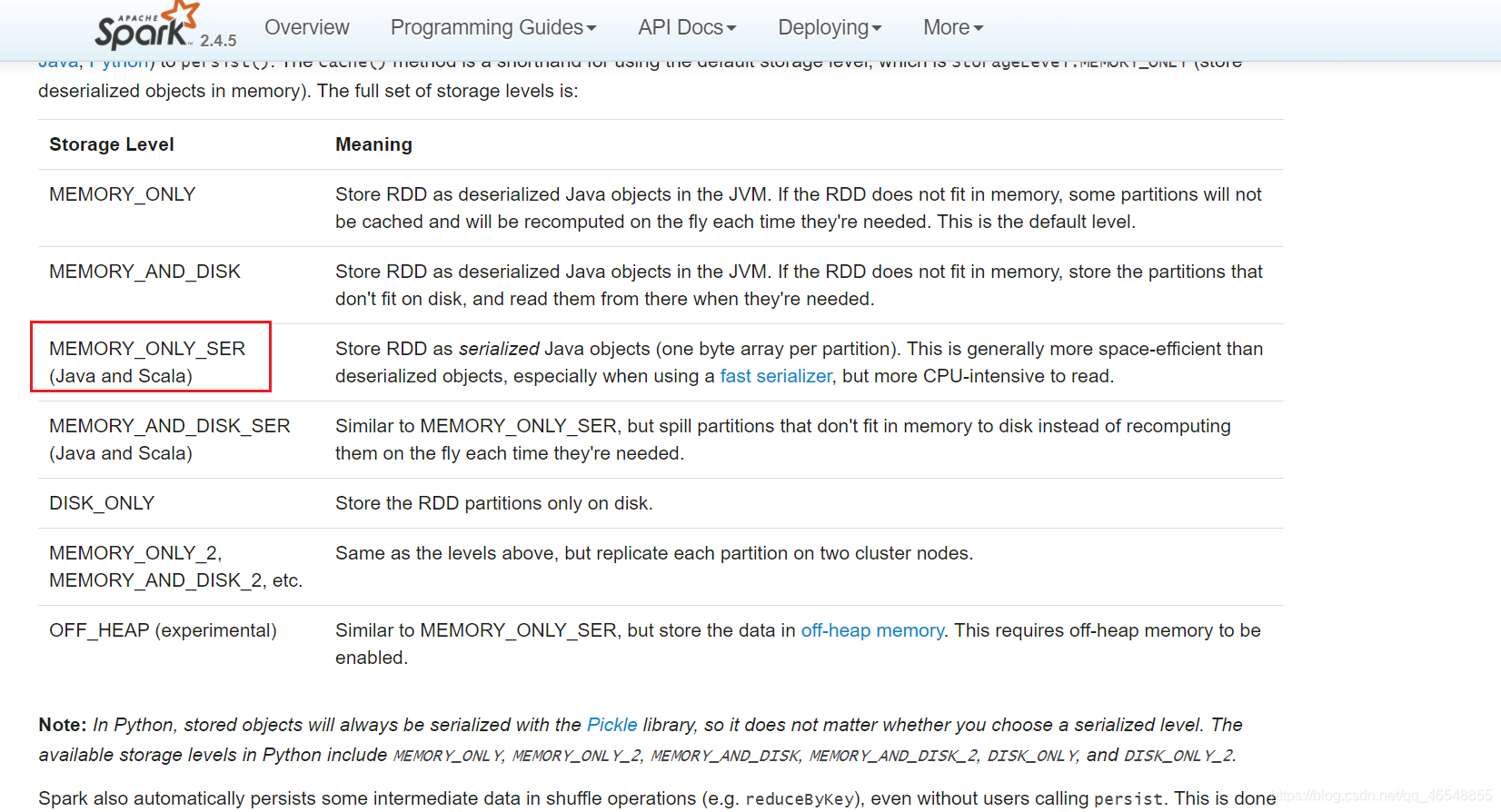
我们需要看看rdd的缓存级别
https://spark.apache.org/docs/2.4.5/rdd-programming-guide.html#which-storage-level-to-choose
使用序列化的缓存级别

发现1.7g直接变成了270m,优化还是挺大的!
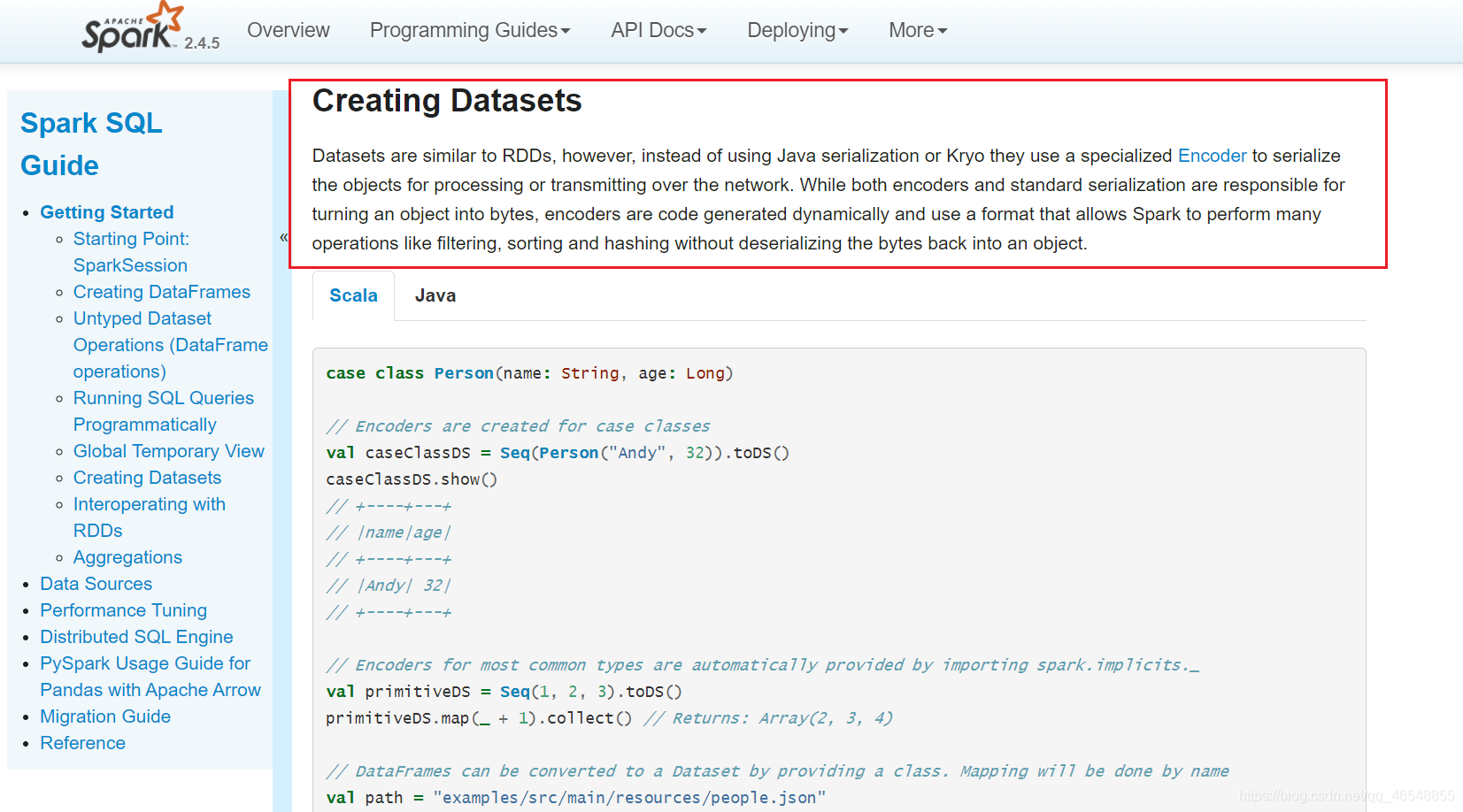
Df和Ds进行示范
看官网
https://spark.apache.org/docs/2.4.5/sql-getting-started.html#creating-datasets
Ds会专门使用自己的偏码进行序列化
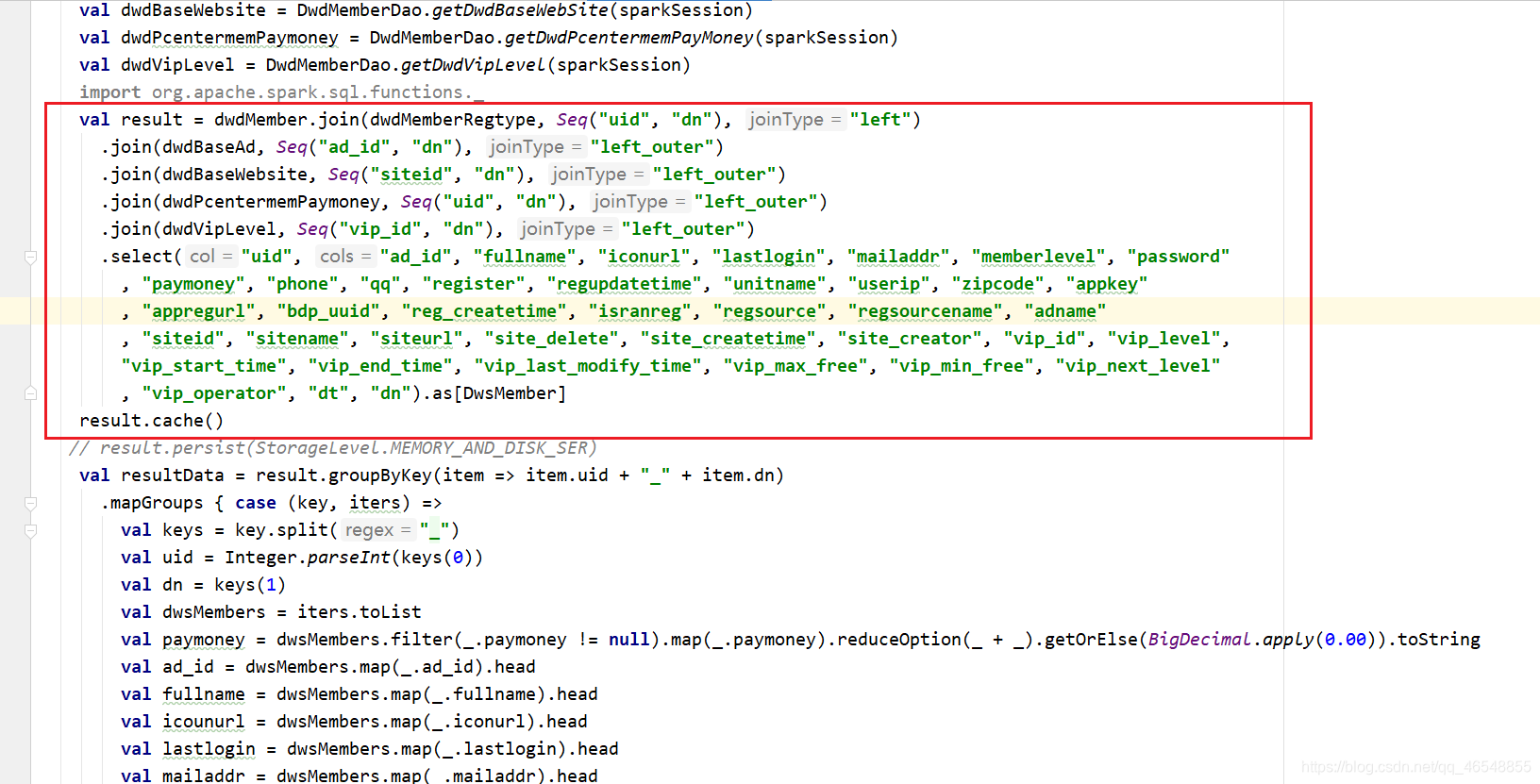
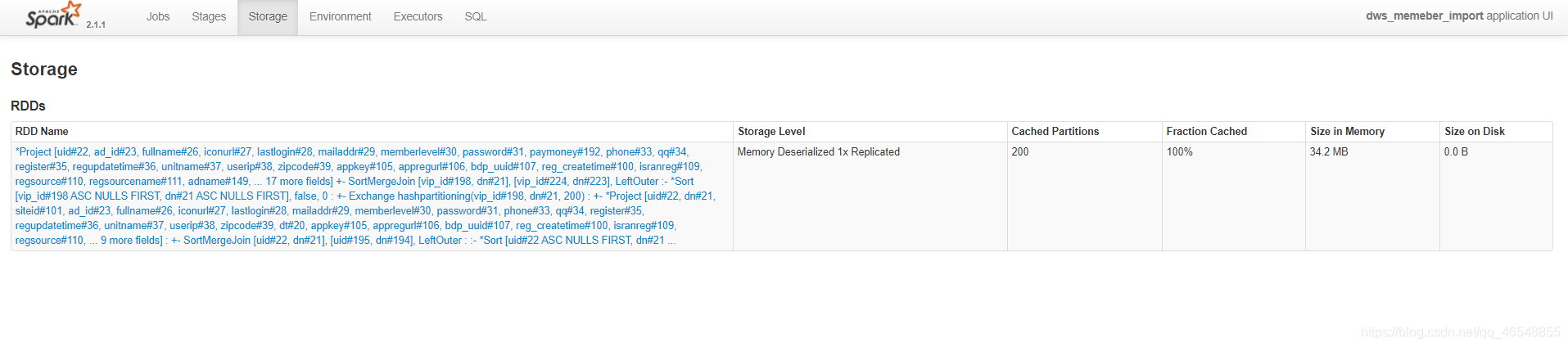
内存大小34.2M
我们还可以进行序列化(变化不大)
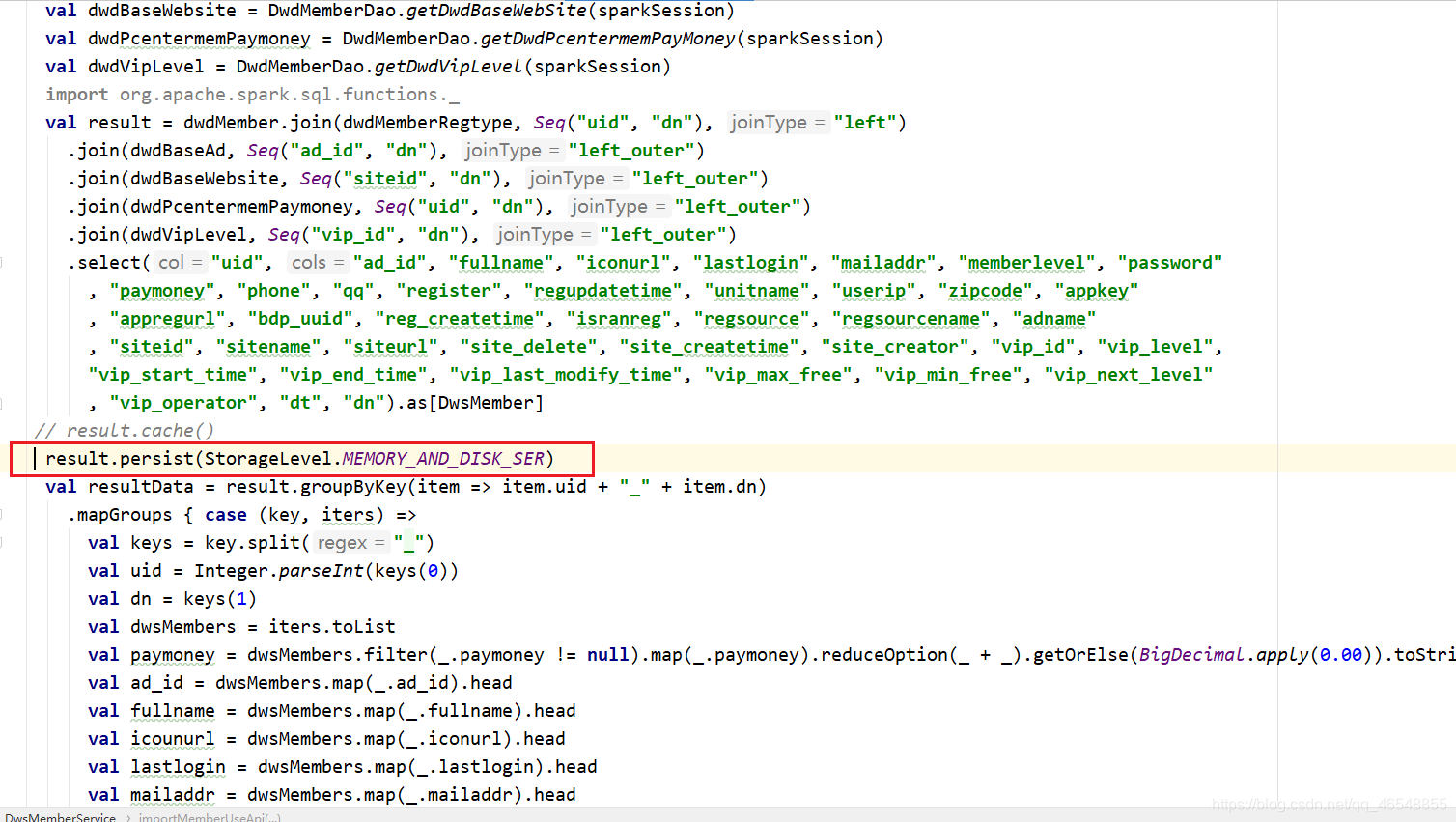
进行优化之后33.9M