文章目录
1. 基础知识
1.1 前言
1.1.0 样本
要理解性能指标的含义,首先需要了解两种样本:
- 正样本:属于某一类(一般是所求的那一类)的样本。在本例中是及格的学生。
- 负样本:不属于这一类的样本。在本例中是不及格的学生。
- 困难样本: 预测时与真值标签误差较大的样本。
- 简单样本: 预测时与真值标签误差较小的样本。
eg. 图片分类:需要识别马、羊、牛三个类别。
给一张马的图片。对于预测马来说这个样本为正样本,对于预测羊和牛来说该样本为负样本。
eg. 语音识别:需要识别“我 爱 中 国”四个字。
语音片段对应“我”。则对于预测“我”来说这个样本为正样本,对于预测其他字来说该样本为负样本。
eg. 真值one-hot标签:[1, 0, 0]
在预测出概率分布为[0.3, 0.3, 0.4]时,与真值one-hot标签相差较大,该样本是困难样本。而预测出[0.98, 0.01, 0.01]时,与真值one-hot标签相差较小,该样本为简单样本。
1.1.1 混淆矩阵
基本所有的性能指标都需要通过混淆矩阵(表0.1)计算:
| Actual positive (P=TP+FN) | Actual nefative(N=FP+TN) | |
|---|---|---|
| Predicted positive | True positive(TP) | False positive(FP) |
| Predicted nefative | False negative(FN) | True negative(TN) |
eg. 一个班有50人,在某场考试中有40人及格,10人不及格。
现在需要根据一些特征预测出所有及格的学生。
某一模型执行下来,给出了39人,其中37人确实及格了,剩下2人实际上不及格。
-
TP:被检索到正样本,实际也是正样本(正确识别)
在本例表现为:预测及格,实际也及格。 -
FP:被检索到正样本,实际是负样本(一类错误识别)
在本例表现为:预测及格,实际不及格。 -
FN:未被检索到正样本,实际是正样本。(二类错误识别)
在本例表现为:预测不及格,实际及格了 -
TN:未被检索到正样本,实际也是负样本。(正确识别)
在本例表现为:预测不及格,实际也不及格 -
混淆矩阵的作用:
1)用于观察模型在各个类别上的表现,可以计算模型对应各个类别的准确率,召回率;
2)直接观察到哪些类别不容易区分,比如A类别中有多少被分到了B类别,这样可以有针对性的设计特征等,使得类别更有区分性;
eg. 对一百张图片进行学习分类,其中包含 火星(40张),地球(40张),冰激凌(20张) 三个种类;
在算法学习过程中需要对每次的迭代分类结果进行精度评估,用到混淆矩阵这一工具。
如下图,列出每次迭代后各类别分类状态的混淆矩阵。
其中,每一行的数目之和是该类别的真实数量,比如第一行的总和为50,代表火星真实存在50个。
对角线代表模型预测正确了,而其他的位置代表预测错误。
因此,混淆矩阵能够帮助分析每个类别的误分类情况,从而分析调整。

图1. 第一次迭代、第二次迭代、第n次迭代(分类结果全部正确)
1.2 阈值相关
许多二分类器的原理,都是给每个样本打一个分,然后设置一个阈值,分数高于阈值的样例就被分为正类,低于阈值则被分为负类。
依赖阈值的性能指标如下:
1.2.1 准确率 A c c u r a c y Accuracy Accuracy
分类正确的样本数 与 样本总数之比。即: ( T P + T N ) / ( A L L ) (TP + TN) / ( ALL ) (TP+TN)/(ALL).
准确率是最常用的指标,可以总体上衡量一个预测的性能。
在本例中,正确分类了45人(及格37 + 不及格8),所以 A c c u r a c y = 45 / 50 = 90 Accuracy = 45 / 50 = 90% Accuracy=45/50=90.
1.2.2 精确率/查准率 P r e c i s i o n Precision Precision
被正确检索的正样本数 与 被检索到正样本总数之比。即: T P / ( T P + F P ) TP / (TP + FP) TP/(TP+FP).
在本例中,正确检索到了37人,总共检索到39人,所以 P r e c i s i o n = 37 / 39 = 94.9 Precision = 37 / 39 = 94.9% Precision=37/39=94.9.
1.2.3 召回率/查全率 R e c a l l Recall Recall
被正确检索的正样本数 与 应当被检索到的正样本数之比。即: T P / ( T P + F N ) = T P / P TP / (TP + FN)=TP/P TP/(TP+FN)=TP/P.
在本例中,正确检索到了37人,应当检索到40人,所以 R e c a l l = 37 / 40 = 92.5 Recall = 37 / 40 = 92.5% Recall=37/40=92.5.
1.2.4 平衡F分数 F 1 − s c o r e F_1-score F1−score
精确率和召回率的调和平均数(值越大越好) F 1 = 2 P r e c i s i o n ∗ R e c a l l P r e c i s i o n + R e c a l l F_1=2\frac{Precision*Recall}{Precision+Recall} F1=2Precision+RecallPrecision∗Recall
推广为: F β = ( 1 + β 2 ) P r e c i s i o n ∗ R e c a l l ( β 2 P r e c i s i o n ) + R e c a l l F_\beta=(1+\beta^2)\frac{Precision*Recall}{(\beta^2Precision)+Recall} Fβ=(1+β2)(β2Precision)+RecallPrecision∗Recall
其中 β β β 用于调整权重,当 β = 1 β=1 β=1 时两者权重相同,简称为 F 1 − S c o r e F_1-Score F1−Score.
P r e c i s i o n Precision Precision 更重要,则减小 β β β, R e c a l l Recall Recall 更重要,则增大 β β β.
除了 F 1 − s c o r e F_1-score F1−score 之外, F 2 − s c o r e F_2-score F2−score 和 F 0.5 − s c o r e F_{0.5}-score F0.5−score 在统计学中也得到大量的应用。其中, F 2 − s c o r e F_2-score F2−score召回率的权重高于精确率,而 F 0.5 − s c o r e F_{0.5}-score F0.5−score精确率的权重高于召回率
1.2.5 TOP error
TOP-5 error:前五个概率中 全都未正确标记的样本本数 / 总的样本数
TOP-1 error:最佳概率 未正确标记的样本数 / 总的样本数
- 依赖阈值 ≠ \neq =固定阈值,我们不固定阈值,而是根据需求来调整。如0.1所示(假设P=4)。
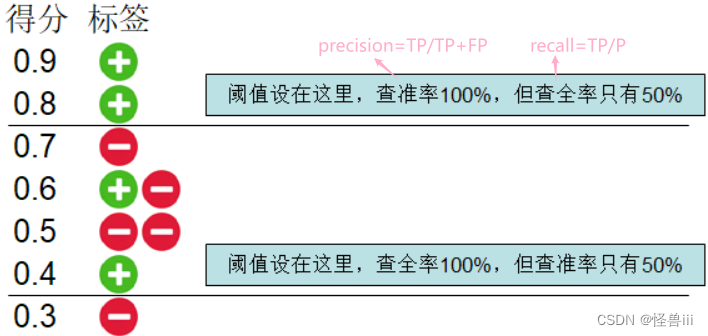
图0.1:不同阈值下的查全率和查准率
1.3 阈值不相关
不依赖阈值的性能指标:
- Receiver operating characteristic Curve(ROC 曲线);
评估性能的具体数值:area under the curve(AUC);mean area under the curve(mAUC) - Precision-recall Curve( P-R 曲线);
评估性能的 具体数值:average precision(AP);mean average precision(mAP) - Detection error tradeoff Curve(DET 曲线)。
2. ROC曲线+P-R曲线
关于ROC,P-R曲线等
2.1 ROC(Receiver Operating Characteristic Curve)
- ROC曲线:横坐标为负类查误率 = 1 -负类的查全率( F P R = 1 − T N P = 1 − R − = F P N = 1 − T N N FPR=1-TNP=1-R_-=\frac{FP}{N}=1-\frac{TN}{N} FPR=1−TNP=1−R−=NFP=1−NTN);纵坐标为正类的查全率( R e c a l l = T P R = R + = T P P Recall=TPR=R_+=\frac{TP}{P} Recall=TPR=R+=PTP)。
- ROC 曲线最早是在二战中用来分析雷达检测信号的能力的。
假设有10个导弹信号,其中8个是导弹(P=8),2个是飞过的鸟(N=2)。经过导弹信号分析,判断出9个是导弹,1个是鸟。则TP=8,FP=1,TN=1,FN=0。计算出FPR=1/2=0.5,TPR=8/8=1。则(0.5,1)对应ROC曲线上一点。 - 根据不同阈值,计算正类查全率TPR和负类查误率FPR,如图1.1所示。
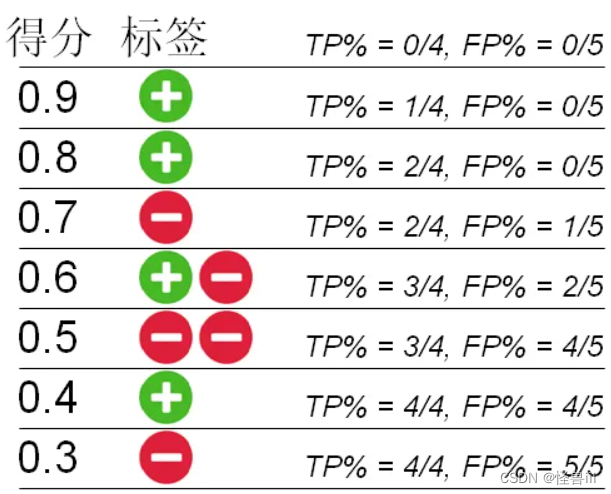
图1.1:不同阈值下的正类查全率TPR和负类查误率FPR
- 根据图1.1绘制ROC曲线,如图1.2所示。
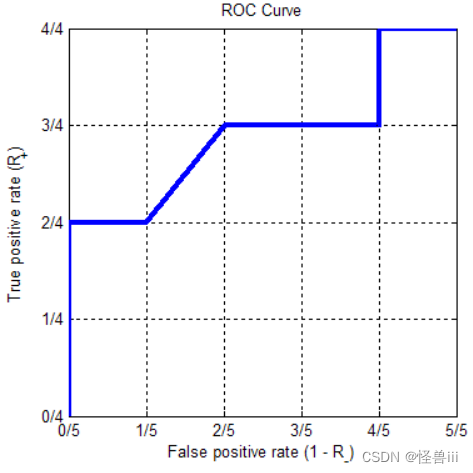
图1.2:根据不同阈值下的TPR和FPR绘制的ROC曲线
-
FPR和TPR相互制约
以导弹预测为例:对于导弹的判断,希望能把所有导弹(P)都预测(TP)出来,即TPR(正类的查全率)越高越好;但不希望把小鸟(N)也当成导弹(FP),即 FRP(1 减去负类的查全率)越低越好。我们发现,FPR和TPR这两个坐标值是相互制约的。
以图1.1和1.2为例:- 从微观上看,ROC 曲线是锯齿状的,但它的每一段都是横平竖直的(有正、负例得分相同时除外)。
- 从宏观上看,ROC 曲线呈单调上升趋势;
- 总体来看,二分类器越好,ROC 曲线越接近图像的左上角,在这个区域,正类的查全率高,负类的查误率低。
- 极端情况:
它的左、右两端一定会位于 ( 0 , 0 ) (0,0) (0,0)和 ( 1 , 1 ) (1,1) (1,1),分别对应阈值设为最高和最低的情况。
-
优点
当正负样本分布变化时,ROC曲线形状基本保持不变。(P-R曲线形状一般会发生剧烈的变化)因此ROC能降低不同测试集带来的干扰,更加客观的衡量模型本身的性能。- 分析:
如混淆矩阵(表0.1)所示,若负样本(N)数量扩大10倍,FP,TN都会增加,必然会影响到Precision,Recall。
对于ROC曲线: F P R = F P N FPR=\frac{FP}{N} FPR=NFP只考虑混淆矩阵第二列,N增大10倍,则FP,TN也会成比例增加,不影响其值, T P R = T P P TPR=\frac{TP}{P} TPR=PTP只考虑混淆矩阵第一列,不影响其值。
通过图1.3可视化分析:图a:ROC曲线,图b:P-R曲线; 在负样本增大10倍后:图c:ROC曲线基本没有变化,图d:P-R曲线却剧烈震荡。
- 分析:
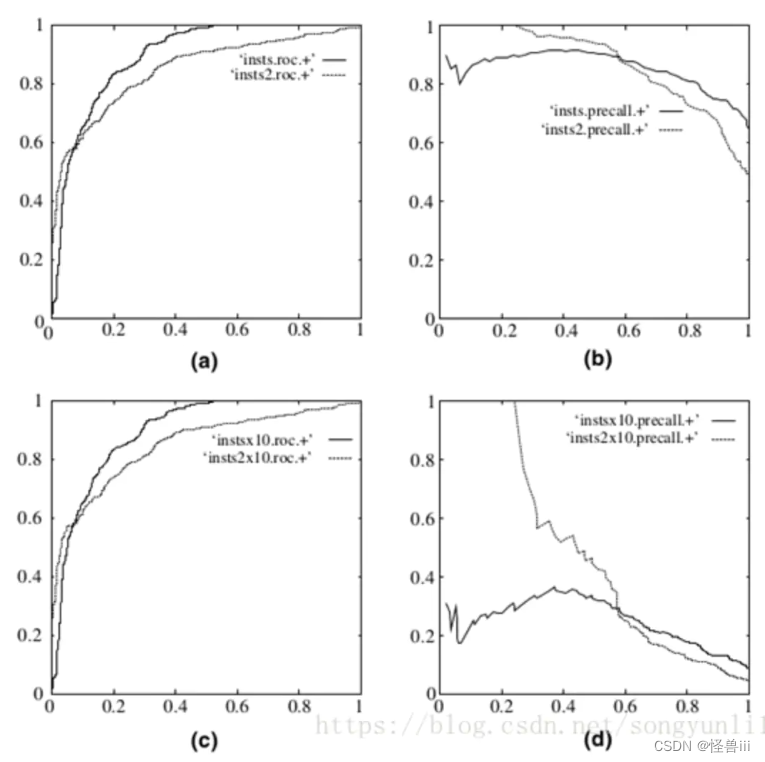
图1.3:ROC曲线(左)和P-R曲线(右)
2.2 P-R曲线(Precision-Recall)
- P-R曲线:横坐标为召回率/查全率( R e c a l l = T P R = T P T P + F N = T P P Recall=TPR=\frac{TP}{TP+FN}=\frac{TP}P Recall=TPR=TP+FNTP=PTP);纵坐标为精确率/查准率( P r e c i s i o n = T P T P + F P Precision=\frac{TP}{TP+FP} Precision=TP+FPTP)。
- 计算不同阈值下的查准率 P + P_+ P+和查全率 R + R_+ R+,如图1.4所示。
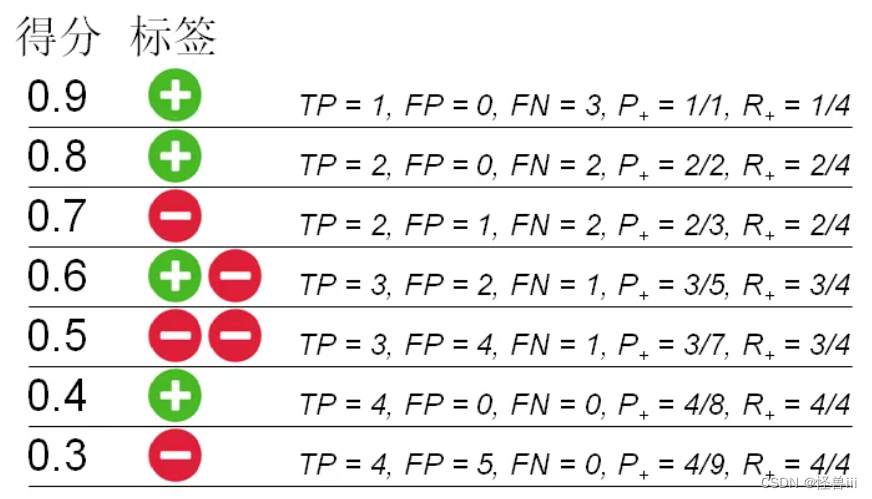
图1.4:不同阈值下的正类查准率P+ 和 查全率R+
- 根据图1.4绘制P-R曲线,如图1.5所示。
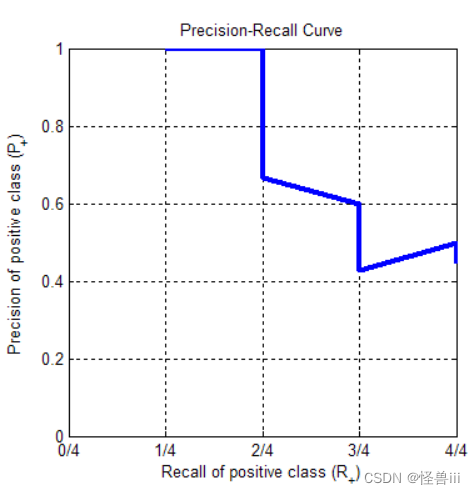
图1.5根据不同阈值的P+ 和R+绘制的 P-R曲线
- Recall和Precision相互制衡,以图1.4和图1.5为例:
- 从微观上看,P-R 曲线是锯齿状的。
当阈值下调,并且跨越一个正例时(0.9->0.8和0.5->0.4), P + P_+ P+和 R + R_+ R+都会升高,产生一条向右上方的线段;
当阈值下调,并且跨越一个负例时(0.8->0.7和0.6->0.5和0.4->0.3), R + R_+ R+不变,而 P + P_+ P+会减小,产生一条竖直向下的线段。
图 1.5中有一条向右下方的线段(0.7->0.6),这是由于正样例得分=负样例得分=0.6产生的,这种得分相同的情况在实际中是罕见的。 - 从宏观上看, P + P_+ P+和 R + R_+ R+ 是相互制衡的关系,所以 P-R 曲线呈现单调下降的趋势。
- 总体来看,越好的二分类器,其 P-R 曲线会越接近图像的右上角,在这个区域,正类的查准率和查全率都高。
- 极端情况:
右端不在 ( 1 , 0 ) (1,0) (1,0),而是会位于 ( 1 , P P + N ) (1,\frac{P}{P+N}) (1,P+NP),纵坐标为正例在所有数据中的比例,这对应于阈值设为最低的情形。
左端不在 ( 0 , 1 ) (0,1) (0,1) ,这对应于阈值设为最高的情形,对于正常的二分类器,得分最高的样例应当是个正例,所以左端的坐标会是 ( 1 P , 1 ) (\frac1P,1) (P1,1),实际上很接近 ( 0 , 1 ) (0,1) (0,1) ;如果得分最高的样例是个负例,那么左端的坐标就是 ( 0 , 0 ) (0,0) (0,0) 了。
- 从微观上看,P-R 曲线是锯齿状的。
2.3 ROC 曲线跟 P-R 曲线的关系
- 我们发现,ROC 曲线的纵轴,恰好就是 P-R 曲线的横轴,它们都是正类的查全率(Recall,TPR, R + R_+ R+)。如果把 ROC 曲线以 ( 1 2 , 1 2 ) (\frac12,\frac12) (21,21)为中心顺时针旋转 90 度,就能让 ROC 曲线变得「像」P-R 曲线,如图1.6所示.
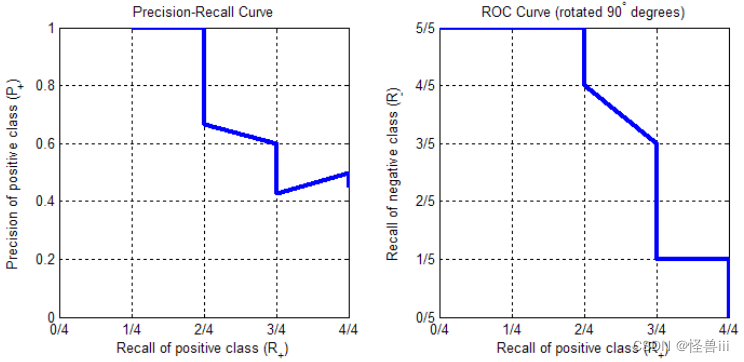
图1.6 P-R曲线(左),旋转后的ROC曲线(右)
- 如图1.6所示,两条曲线都集中在图像的右上角,宏观上呈单调下降趋势。横轴都是正类的查全率。旋转后的 ROC 曲线,其纵轴的含义是 R − ( 即 1 − F P R = 1 − ( 1 − T N R ) = T N R ) R_-(即1-FPR=1-(1-TNR)=TNR) R−(即1−FPR=1−(1−TNR)=TNR),即负样本中被正确地分类为负例的比例,称为负类的查全率。而 P-R 曲线的纵轴是正类的查准率 ,两条曲线只是纵轴的含义不同。
- 在真实场景中,正例往往远少于负例。只要阈值不是设得极端低,一般都有 T P < T N TP<TN TP<TN,所以 P + < R − P_+<R_- P+<R−(正类查准率<负类查全率)。也就是说,除了在曲线的最右端,旋转后的 ROC 曲线一般会高于 P-R 曲线。
- 在曲线的最右端,阈值设为最低,所有样例均被分类为正例,正类查全率 R + R_+ R+ 为1;P-R 曲线的纵坐标正类查准率 P + P_+ P+为 P P + N \frac{P}{P+N} P+NP等于正例所占比例,而旋转后的 ROC 曲线的纵坐标负类查全率 R − R_- R−则会下降到 0。
3. AUC+AP
3.1 AUC(Area under roc Curve)
- AUC面积:ROC曲线下的面积大小,沿ROC横轴做积分计算。
绘制完ROC,通过计算AUC面积,对模型进行量化的分析。 - 真实场景中ROC曲线一般会在直线的上方,所以AUC的值一般在0.5~1之间。
- AUC值是一个概率值,分类算法按此概率(AUC值)将正样本排在负样本前面。
AUC的值越大,越可能将正样本排在负样本前面,该模型的性能越好。
3.2 AP(average precision)
- P-R曲线下的面积为: m A P = ∫ 0 1 P ( R ) d R = ∑ k = 1 N P ( k ) ∆ r ( K ) mAP=\int_0^1P(R)dR=\sum_{k=1}^{N}P(k)∆r(K) mAP=∫01P(R)dR=∑k=1NP(k)∆r(K)
- AP 指标的定义:是对物体检测模型性能的一种评估指标,它主要用于衡量模型在不同类别目标上的精度。具体来说,AP是计算Precision-Recall曲线下的面积得到的,即使用一组阈值生成P-R曲线并计算该曲线下的面积。
- AP的值越大,该模型的性能越好
- mAP指标:由于一个数据集中通常会包含多个目标类别,因此平均准确率(mAP)是评估模型在整个数据集上性能的更综合的指标。通常,对于每个目标类别,我们都可以计算出一个AP值,然后对这些AP值取平均数来得到mAP。计算mAP时,通常采用两种方式:1)对所有类别的AP值求平均数;2)对所有类别进行加权平均数,其中每个类别的权重为它在数据集中出现的频率。
- mAP是评估物体检测模型性能的一种广泛使用的指标,特别是在目标检测竞赛中。它可以综合考虑模型在多个目标类别上的性能表现,并提供了一种直观的方法来比较不同模型之间的性能差异。是取所有类别AP的平均值,衡量的是在所有类别上的平均好坏程度。

图2.1:不同阈值下的正类查准率P+
- 以图2.1为例
把阈值设置在紧靠第 1、2、3、4 个正例之后,正类的查准率分别是 1、1、0.6、0.5,所以 AP 指标等于 ( 1 + 1 + 0.6 + 0.5 ) / 4 = 0.775 (1+1+0.6+0.5)/4=0.775 (1+1+0.6+0.5)/4=0.775。
如果有多个正例的得分相同,那么阈值设置在紧靠它们之下时的查准率,在取平均时也会被计算多次。比如,如果图 5.1 中得分为 0.6 的两个样例都是正例,那么 AP 就会变成 ( 1 + 1 + 4 / 5 + 4 / 5 + 5 / 8 ) / 5 = 0.845 (1+1+4/5+4/5+5/8)/5=0.845 (1+1+4/5+4/5+5/8)/5=0.845。
4. 真实的ROC和P-R曲线
上述例子中展示了小数据集上的ROC和P-R曲线,下面展示了在大数据集上的结果。
4.1 正负样本得分-随机分布
-
把所有的样例得分随机分布,作为二分类问题的一个 baseline。当样例随机排序时,不管把阈值设在哪里,正类的查准率都会接近正类在所有数据中的比例(下记为 % + \%_+ %+);而正类的查全率 R + R_+ R+会跟负类的查误率 1 − R − 1-R_- 1−R−一样高,都等于阈值上方的样例占所有数据的比例,即 T P + F P P + N = 1 − T N + F N P + N \frac{TP+FP}{P+N}=1-\frac{TN+FN}{P+N} P+NTP+FP=1−P+NTN+FN。于是,P-R 曲线将是纵坐标为 % + \%_+ %+的一条横线,而 ROC 曲线将是从 ( 0 , 0 ) (0,0) (0,0)到 ( 1 , 1 ) (1,1) (1,1)的一条斜线。
-
图 3.1是把 2000 个正例和 8000 个负例随机排序后,绘制出的 P-R 曲线和 ROC 曲线,以及把 ROC 曲线顺时针旋转 90 度后的结果。除了 P-R 曲线的左端有较大波动以外,一切符合预期。
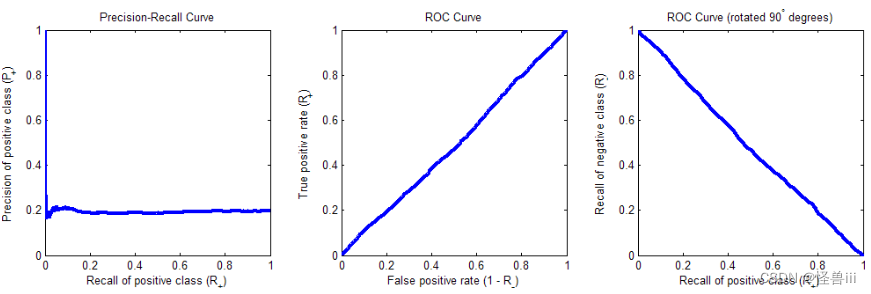
图3.1:样本随机分布的 P-R 曲线(左)、 ROC 曲线(中)、旋转后的ROC曲线(右)
4.2 正负样本得分-等方差高斯分布
- 假设正类与负类各有 5000 个样例,且两类的得分都服从方差为 1 的高斯分布,均值之差为 2,如图 3.2:
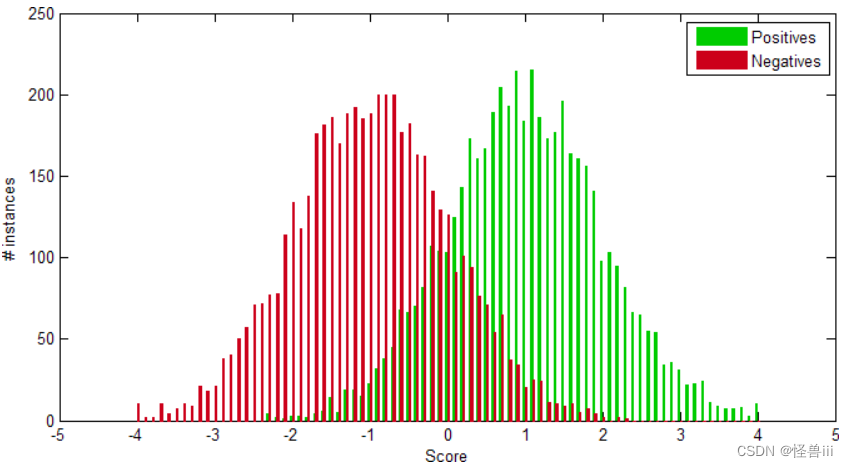
图3.2正负样本得分为等方差高斯分布
- 这是一种比较真实的场景,在此场景下的 P-R 曲线与 ROC 曲线如图 3.3。P-R 曲线集中于右上角;ROC 曲线集中于左上角,顺时针旋转 90 度后则集中于右上角。
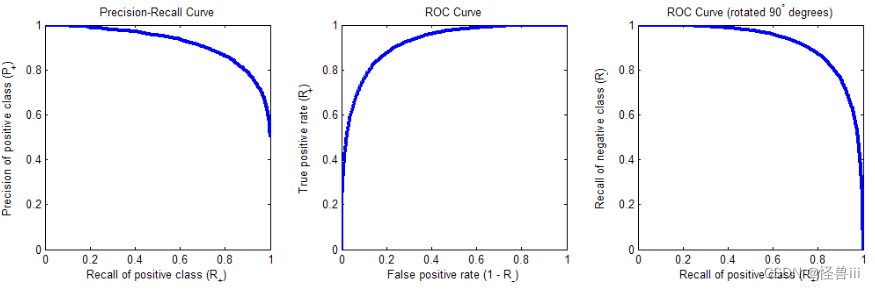
图3.3 样本高斯分布的 P-R 曲线(左)、 ROC 曲线(中)、旋转后的ROC曲线(右)
- 曲线越靠近相应的角落,正负样本得分的分布则相距越远。在上面的例子里,两类得分的均值之差 d d d 等于各自标准差 σ \sigma σ的 2 倍。如果把正负样本得分的分布距离拉远,那么 P-R 和 ROC 曲线都会更加靠近角落。图 3.4 展示了 d = 2 σ , 3 σ , 4 σ d=2\sigma,3\sigma,4\sigma d=2σ,3σ,4σ时曲线的样子:
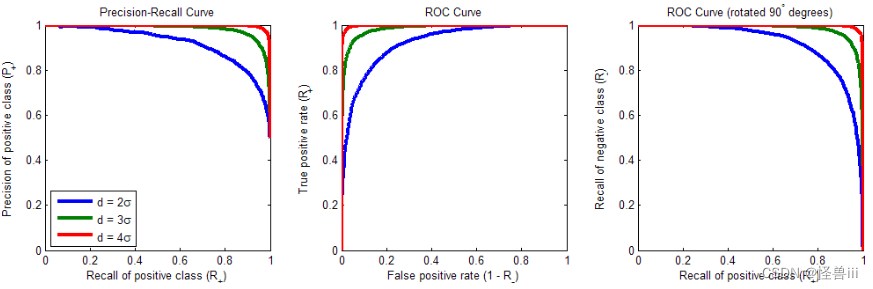
图3.4 d=2σ,3σ,4σ时的P-R 曲线(左)、 ROC 曲线(中)、旋转后的ROC曲线(右)
- 上面的例子中,正例的比例均为 50%。事实上,正例的比例对 P-R 曲线有较大的影响。正例越少,曲线越低,并且曲线右端的纵坐标恰好就是正例的比例。然而,ROC 曲线并不受正例所占比例的影响(如图1.2,ROC曲线比较稳定)。图 3.5 展示了 d = 2 σ d=2\sigma d=2σ时,把正例的比例减少至 20% 和 5% 时的 P-R 曲线。同时证明了1.1-6.中的理论,当正例远少于负例时,旋转后的 ROC 曲线会高于 P-R 曲线,最右端除外。
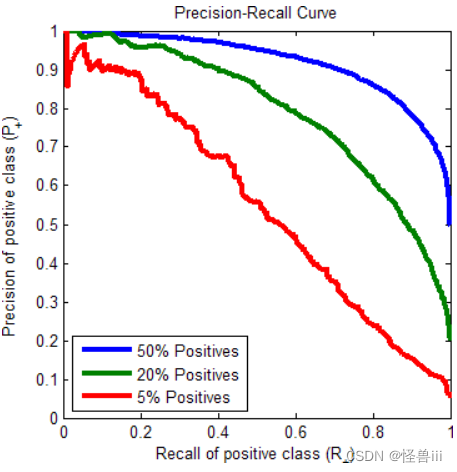
图3.5 不同正例占比的P-R曲线
4.3 正负样本得分-不等方差高斯分布
- 当两类得分呈不等方差的高斯分布时,观察P-R 曲线和 ROC 曲线。设正、负类各有 5000 个样例,正类得分的均值为 1、方差为 1,负类得分的均值为 -2、方差为 4,如图 3.6所示。
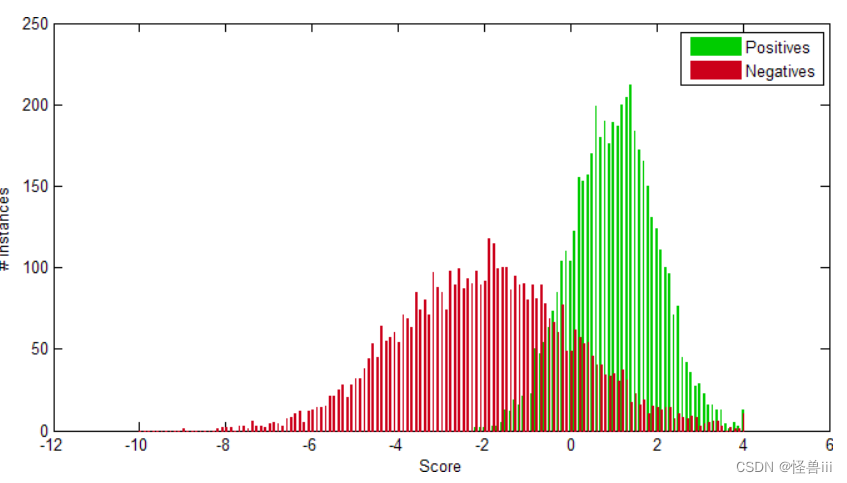
图3.6正负样本得分为不等方差高斯分布
- 此时的 P-R 曲线和 ROC 曲线如图 3.7。注意到 P-R 曲线不再呈单调下降的趋势,而是先升后降,这是因为负类的最高得分跟正类的最高得分差不多了,哪怕把阈值设得很高,也无法完全排除负类。这并不是「两类得分方差不等」的必然结果,而是依赖于分布的具体参数。另外可以注意到,与等方差的情形不同,ROC 曲线不再是关于对角线对称的了。
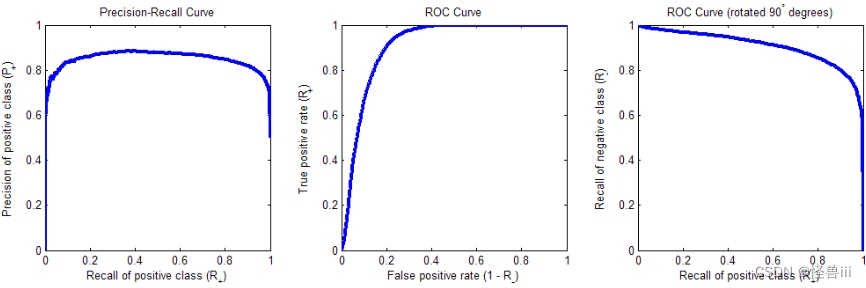
图3.7 样本不等方差高斯分布的 P-R 曲线(左)、 ROC 曲线(中)、旋转后的ROC曲线(右)
- 和等方差高斯分布一样,两类得分的分布分得越开,曲线就越靠近角落(图略);
- 和等方差高斯分布一样,正例所占比例会影响 P-R 曲线,如图 3.8所示。但不会影响 ROC 曲线(图略,理由同上,请看1.1-6.中的理论)。
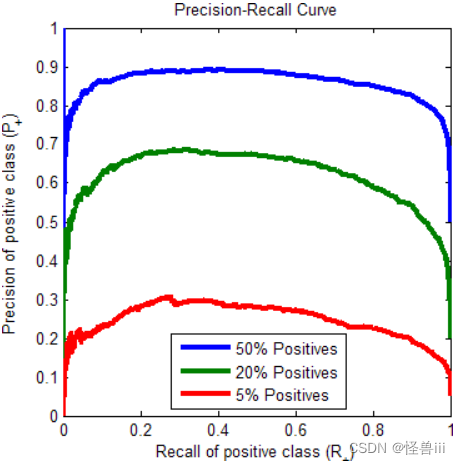
图3.8 不同正例占比的P-R曲线
5. MCC(Matthews correlation coefficient)
参考
马修斯相关系数 (MCC)是 p h i phi phi系数的一个特例。即将True Class和Predicted Class视为两个(二进制)变量,并计算它们的相关系数(与计算任何两个变量之间的相关系数类似)。真实值和预测值之间的相关性越高,预测效果越好。只有当预测在所有四个混淆矩阵类别(TP、TN、FN和FP)中都获得了良好的结果时,它才会产生高分。
计算公式如下:
M C C = T P × T N − F P × F N ( T P + F P ) ( T P + F N ) ( T N + F P ) ( T N + F N ) MCC=\frac{TP\times TN-FP\times FN}{\sqrt{(TP+FP)(TP+FN)(TN+FP)(TN+FN)}} MCC=(TP+FP)(TP+FN)(TN+FP)(TN+FN)TP×TN−FP×FN
根据计算公式,可知当分类器是完美的(FP = FN = 0),MCC的值是1,表示完全正相关。相反,当分类器总是分类错误时(TP = TN = 0),得到的数值是-1,代表完美的负相关。所以,MCC的值总是在-1和1之间,0意味着分类器不比随机二分类选择好。此外,MCC是完全对称的,所以没有哪个类别比其他类别更重要,如果把正反两个类别换一下,仍然会得到相同的值。
然后我们再计算一下,上面例举的数据中MCC的值:
M C C = 18 × 1 − 3 × 2 ( 18 + 3 ) ( 18 + 2 ) ( 1 + 3 ) ( 1 + 2 ) = 0.17 MCC=\frac{18\times 1-3\times 2}{\sqrt{(18+3)(18+2)(1+3)(1+2)}}=0.17 MCC=(18+3)(18+2)(1+3)(1+2)18×1−3×2=0.17
MCC的值是0.17 ,表明预测类和真实类是弱相关的。从以上的计算和分析,我们知道这种弱相关是因为分类器不擅长对猫进行分类。
6. IOU
6.1 重叠度 IoU Intersect over Union
IoU:在特定数据集中检测物体准确度的一个标准,评价候选框 bounding box的定位精度。
IOU用于测量真实和预测范围之间的相关度(重叠度),相关度越高,该值越高。对于任意大小形状的物体检测,其中:
- ground-truth bounding boxes:人为在训练集图像中标出要检测物体的大概范围
- predicted bounding boxes:根据算法得出的预测范围
如下图6所示。绿色标线是人为标记的正确结果(ground-truth),红色标线是算法预测的结果(predicted)。

真实和预测候选框
6.2 IoU的计算
IoU为区域重叠的部分 除以 区域的集合部分得出的结果。
I o U = A r e a o f O v e r l a p A r e a o f U n i o n IoU=\frac{Area\, of\, Overlap}{Area\, of\, Union} IoU=AreaofUnionAreaofOverlap
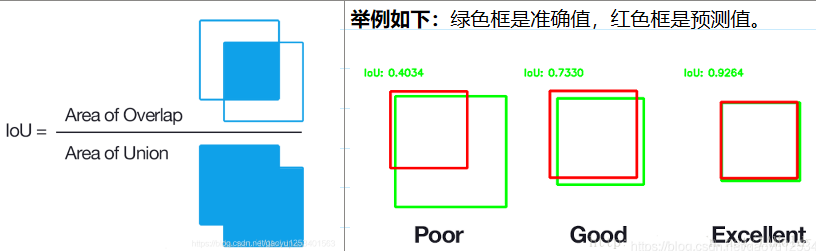
真实和预测候选框
比较设定的阈值与IoU计算结果,通常我们认为:
- Correct: 类别正确 且 IoU > .5
- Localization: 类别正确, .1 < IoU < .5
- Similar: 类别近似, IoU > .1
- Other: 类别错误, IoU > .1
- Background: IoU < .1 的任意目标