点击下方“JavaEdge”,选择“设为星标”
第一时间关注技术干货!
免责声明~
任何文章不要过度深思!
万事万物都经不起审视,因为世上没有同样的成长环境,也没有同样的认知水平,更「没有适用于所有人的解决方案」;
不要急着评判文章列出的观点,只需代入其中,适度审视一番自己即可,能「跳脱出来从外人的角度看看现在的自己处在什么样的阶段」才不为俗人。
怎么想、怎么做,全在乎自己「不断实践中寻找适合自己的大道」
1 简介
类型提前建议,也称为自动完成功能,使用户可以搜索已知的和频繁搜索的查询。当用户在搜索框中输入查询时,该功能就会启用。类型提前系统根据用户的搜索历史、当前搜索的上下文以及不同用户和地区的热门内容,提供一系列建议来完成查询。频繁搜索的查询总是出现在建议列表的顶部。类型提前系统并不会使搜索更快,但是它可以帮助用户更快地组成一个句子。它是所有搜索引擎的一个重要部分,可以增强用户体验。
2 需求
2.1 功能性
系统应该根据用户在搜索框中输入的文本,向用户提供建议出前 N 个(比如前十个)频繁相关的词条。
2.2 非功能性
低延迟
系统应该在用户输入后实时显示所有建议的查询。延迟不应超过 20ms。一项研究表明,两次击键之间的平均时间为 160 毫秒。因此,我们对建议的时间预算应该大于 160 毫秒,以提供实时响应。这是因为如果用户正在快速输入,他们已经知道要搜索什么,并且可能不需要建议。同时,我们的系统响应应大于 160 毫秒。然而,它不应该太高,因为在这种情况下,建议可能已经过时,并且效用较低。
容错性
系统应该足够可靠,即使其一个或多个组件失败,也能够提供建议。
可扩展性
随着时间的推移,系统应该支持不断增加的用户数量。
3 高级设计
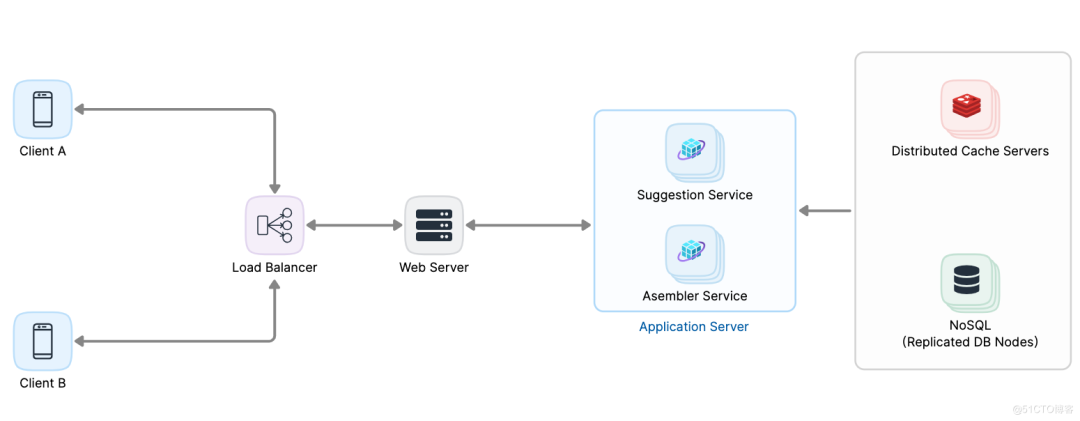
系统不仅应以最小延迟实时提供查询建议,还应将新的搜索查询存储在数据库。用户就能根据流行的和最近的搜索获得建议。
当用户开始在搜索框中输入查询时,每个键入的字符都会打到其中一个应用服务器。假设有个建议服务,它从缓存、Redis 中获取前十个建议,并作为响应发送回客户端。
假设还有个服务称为装配器。装配器收集用户搜索,对搜索进行一些分析以对其排名,并将其存储在分布在几个节点上的 NoSQL:
Fig 1.0,High level design of typeahead suggestion system:
4 数据结构
4.1 Trie 树数据结构
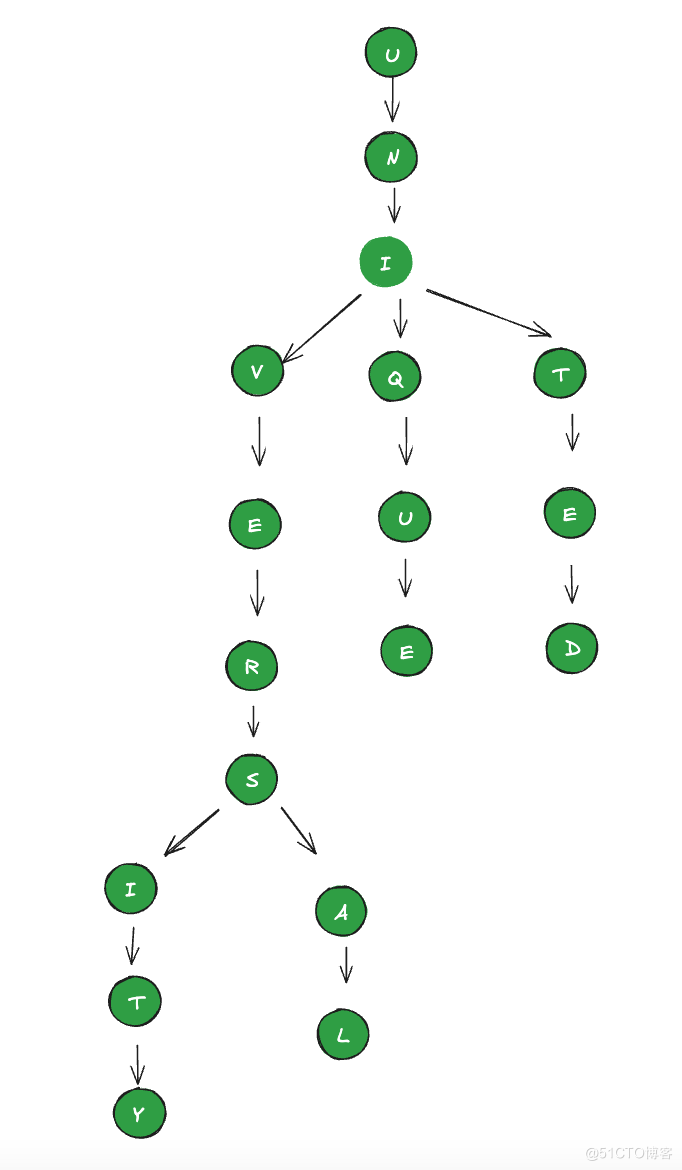
我们必须选择一个高效的数据结构来存储前缀。前缀是用户键入的一组字符。我们需要以一种允许用户使用任何前缀进行搜索的方式来存储它们。假设我们的数据库包含短语 UNITED、UNIQUE、UNIVERSAL 和 UNIVERSITY。当用户键入 "UNIV" 时,我们的系统应该建议 "UNIVERSAL" 和 "UNIVERSITY"。
我们需要一种方法,可以高效地存储我们的数据并帮助我们进行快速搜索,因为我们必须以最小延迟处理大量请求。我们不能依赖数据库,因为从数据库中提供建议比从 RAM 中读取建议花费的时间更长。因此,我们需要在内存中以高效的数据结构存储我们的索引。但是,为了持久性和可用性,这个数据被存储在数据库中。
Trie(发音为 "try")是最适合我们需求的数据结构之一。Trie 是一个树形数据结构,用于按顺序存储词组中的每个字符。如果我们需要在 trie 中存储 UNITED、UNIQUE、UNIVERSAL 和 UNIVERSITY,它看起来像这样:
图 2.0:UNITED、UNIQUE、UNIVERSAL 和 UNIVERSITY 的 trie
如果用户输入 "UNIV",我们的服务可以遍历 trie 中的节点 V 来找到所有以这个前缀开头的词条——例如,"UNIVERSAL"、"UNIVERSITY" 等等。
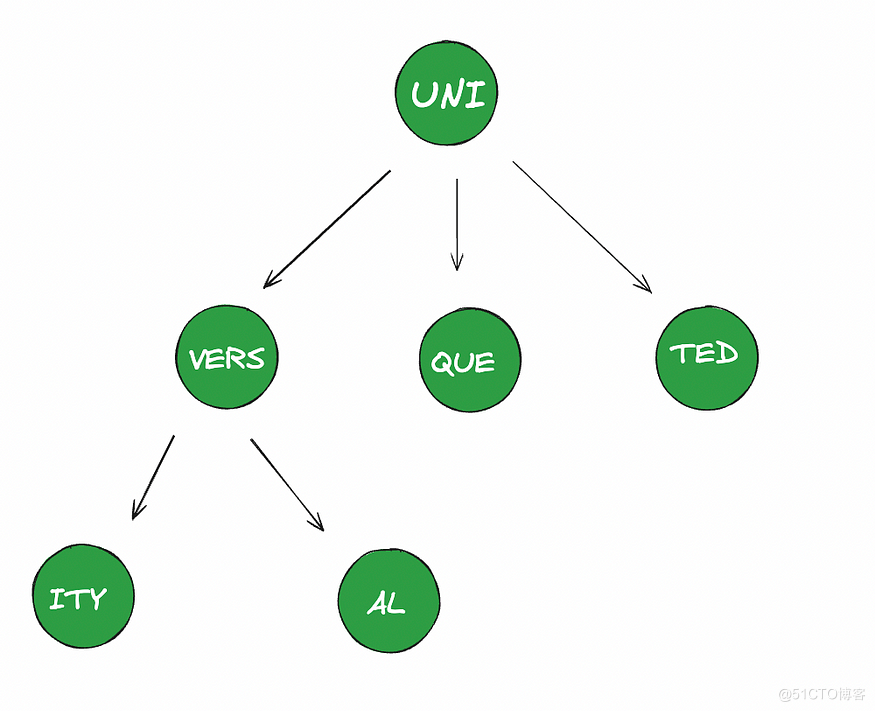
Trie 可以将只有单个分支的节点组合成一个节点,这减少了树的深度。这也减少了遍历时间,从而提高了效率。例如,上述 trie 的一个空间和时间高效模型:
图 3.0:UNITED、UNIQUE、UNIVERSAL 和 UNIVERSITY 的缩减版 Trie
跟踪热门搜索
由于我们的系统会跟踪热门搜索并返回热门建议,所以我们在 trie 节点中存储每个词条被搜索的次数。比如说,用户搜索 UNITED 15 次,UNIQUE 20 次,UNIVERSAL 21 次,UNIVERSITY 25 次。为了向用户提供热门建议,这些计数被存储在每个词条终止的节点中。结果 trie 如下:
图 4.0: 显示 UNITED、UNIQUE、UNIVERSAL 和 UNIVERSITY 搜索频率的 trie
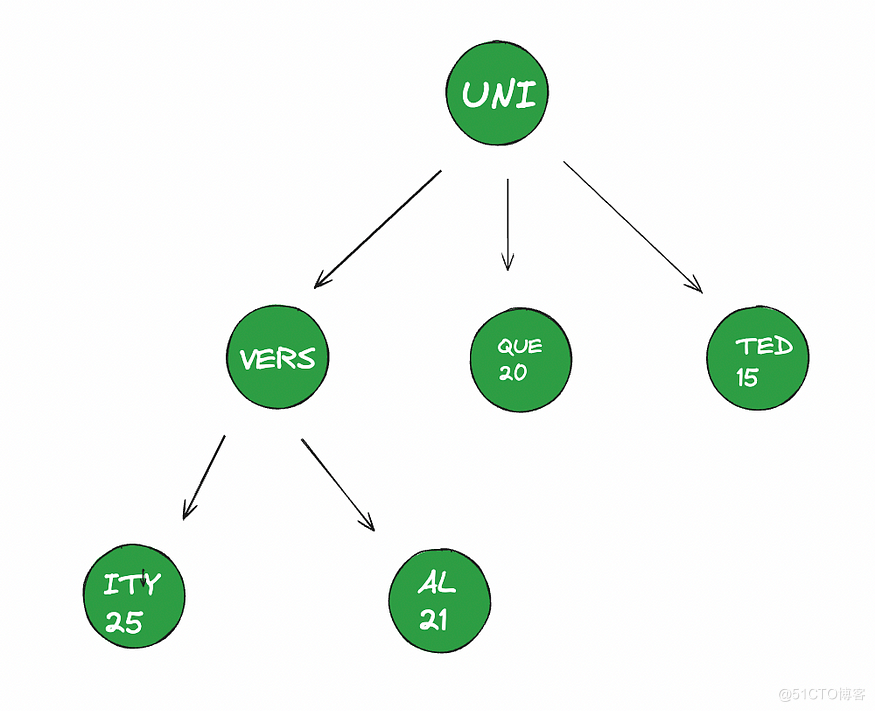
如果用户输入 "UNI",系统会在根节点下面的 UNI 下开始遍历树。 在比较根节点下面所有词条的原点后,系统会提供所有可能单词的建议。 由于 UNIVERSITY 一词的频率很高,它会显示在最前面。 类似地,UNITED 一词的频率相对较低,所以它显示在最后。 如果用户从建议列表中选择 UNIQUE,UNIQUE 对应的数值会增加到 21。
Trie 分区
我们的目标是设计一个像谷歌那样的系统,可以每秒处理数十亿个查询。一台服务器是不够的来处理这么大量的请求。此外,在一个 trie 中存储所有的前缀也不是这个系统的可用性、可扩展性和持久性的可行选择。一个好的解决方案是将 trie 拆分成多个 trie 以获得更好的用户体验。
假设 trie 被拆分成两部分,每部分都有一个副本用于持久性目的。所有从 "A" 到 "M" 开头的前缀都存储在 Server/01 上,副本存储在 Server/02上。类似地,所有从 "N" 到 "Z" 开头的前缀都存储在 Server/03上,副本存储在 Server/04上。应该注意,这种简单的技术并不总是能够平衡负载,因为某些前缀包含的词更多,而其他前缀则更少。
分区后查询
当用户输入一个查询时,它会命中负载均衡器并转发到其中一个应用服务器。应用服务器会根据用户输入的前缀搜索适当的 trie。
更新 trie
每天数十亿次搜索给了我们每秒数百万个查询量。因此,为每个查询更新一个 trie 的过程非常资源密集和耗时,可能会影响我们的读请求。我们可以通过在特定间隔离线更新 trie 来解决这个问题。为了脱机更新 trie,我们记录查询及其频率的哈希表,并定期聚合数据。在一定的时间后,使用聚合的信息更新 trie。在更新 trie 后,所有以前的条目都会从哈希表中删除。
我们可以定期设置一个 MapReduce(MR)作业来处理所有日志数据,比如每 15 分钟一次。这些 MR 服务会计算过去 15 分钟内搜索的所有词组的频率,并将结果转储到 Cassandra 等数据库中的哈希表中。之后,我们可以使用新数据进一步更新 trie。我们可以使用 Cassandra 数据库中的所有新单词及其频率更新当前拷贝的 trie。我们应该离线执行此操作,因为我们的优先事项是为用户提供建议,而不是让他们等待。
另一种方法是有一个主副本和几个辅助副本的 trie。当主副本用于回答查询时,我们可以更新辅助副本。我们也可以在升级完成后使辅助副本成为我们的主副本。然后我们可以升级我们以前的主副本,然后它也可以为流量提供服务。
5 详细设计
图 5.0:类型提前建议系统的详细设计

装配器
Trie 的创建和更新不应该出现在用户查询的关键路径上。我们有一个独立的服务称为装配器,它负责在一定的可配置时间后创建和更新 tries。装配器由以下不同的服务组成:
收集服务
每当用户输入时,此服务会收集包含词组、时间和其他元数据的日志,并将其转储到数据库中以供以后处理。由于这些数据的大小很大,Hadoop 分布式文件系统(HDFS)被认为是存储这些原始数据的合适存储系统。
聚合器
收集服务收集的原始数据通常不在汇总状态。我们需要汇总原始数据以进一步处理它并创建或更新 tries。聚合器从 HDFS 检索数据并将其分配给不同的工作者。通常,MapReducer 在给定的时间间隔内负责聚合前缀的频率,并定期在相关的 Cassandra 数据库中更新频率。Cassandra 非常适合这种用途,因为它可以以表格格式存储大量数据。
Trie 构建器
该服务负责创建或更新 tries。它通过 ZooKeeper 在各自的分片上将这些新更新的 tries 存储在 trie 数据库中。为了便于重建我们的 trie(如果有必要的话),tries 以文件形式存储在持久存储中。MongoDB 等 NoSQL 文档数据库非常适合存储这些 tries。如果机器重启,就需要这种对 trie 的存储。
trie 是从 Cassandra 数据库中的聚合数据更新的。使用所有新词及其相应频率更新现有的 trie 快照。否则,使用 Cassandra 数据库中的数据创建一个新的 trie。
一旦创建或更新了一个 trie,系统会将其提供给建议服务。
6 评估
低延迟
我们可以在多个级别最小化系统延迟。我们可以通过以下选项最小化延迟:
减少树的深度,从而减少总体遍历时间。
脱机更新 trie,这意味着更新操作花费的时间不在客户的关键路径上。
使用地理分布式的应用和数据库服务器。这样,服务就可以近用户端提供,这也减少了任何通信延迟并有助于减少延迟。
在 NoSQL 数据库集群之上使用 Redis 和 Cassandra 缓存集群。
适当分区 trie,这会导致负载的适当分布并带来更好的性能。
容错性
由于提供了树的复制和分区,系统的操作具有很高的弹性。如果一台服务器失败,其他服务器就在待命状态以提供服务。
可扩展性
由于我们提出的系统是灵活的,可以根据负载的增加添加或删除更多的服务器。例如,如果查询量增加,树的分区或分片数量会相应增加。
总结
学会如何将资源密集型处理推送到离线基建,并使用合适数据结构以提供低延迟服务。
trie 数据结构上的多项优化,用于精简数据存储和高速服务。
参考:
编程严选网
写在最后
编程严选网(www.javaedge.cn),程序员的终身学习网站已上线!
点击阅读原文,即可访问网站!
欢迎长按图片加好友,我会第一时间和你分享软件行业趋势,面试资源,学习途径等等。
 添加好友备注【技术群交流】拉你进群,更多教程资源应有尽有
添加好友备注【技术群交流】拉你进群,更多教程资源应有尽有
关注公众号后,在后台私信:
回复【架构师】,获取架构师学习资源教程
回复【面试】,获取最新最全的互联网大厂面试资料
回复【简历】,获取各种样式精美、内容丰富的简历模板
回复 【路线图】,获取直升Java P7技术管理的全网最全学习路线图
回复 【大数据】,获取Java转型大数据研发的全网最全思维导图
微信【ssshflz】私信 【副业】,进副业交流群
点击【阅读原文】,即可访问程序员一站式学习网站