一、查询流程
在讲述 Mybatis 为我们提供的三种 Executor 执行器策略之前,先说说默认情况下 Mybatis 的执行流程。
以下是准备调试的代码:
<sql id="person_test">
id,name,age,sex
</sql>
<select id="hhh" resultType="com.ncpowernode.mybatis.bean.Person">
select <include refid="person_test"/>
from t_person
</select>
@Test
public void testExecutor() throws SQLException {
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(Thread.currentThread().getContextClassLoader().getResourceAsStream("mybatis-config.xml"));
Configuration configuration = sqlSessionFactory.getConfiguration();
Environment environment = configuration.getEnvironment();
TransactionFactory transactionFactory = environment.getTransactionFactory();
Transaction transaction = transactionFactory.newTransaction(environment.getDataSource(), null, false);
// Executor executor = new SimpleExecutor(configuration, transaction);
Executor executor = configuration.newExecutor(transaction);
List<Object> list = executor.query(configuration.getMappedStatement("com.ncpowernode.mybatis.mapper.PersonMapper.hhh"),
null, new RowBounds(), null);
System.out.println(list);
}
看查询方法时,先知道 sqlsessionFactory 在创建 sqlsession 时,会搞个执行器出来,即下面这个方法(如果你配置了二级缓存,默认是配置的,这用了装饰者模式,这个Executor 是 CachingExecutor 执行器,内部封装了真实执行的委托Executor):
final Executor executor = configuration.newExecutor(tx, execType);
mybatis 默认是会去执行 CachingExecutor 中的 query 方法的,但没有在 mapper 文件中配置 该select语句所在的Mapper,配置了< cache> 或< cached-ref>节点,并且有效
该select语句的参数 useCache=true,所以会走 CachingExecutor 中的委托者中的 query 方法。
执行的查询方法是执行的执行器的父抽象类 BaseExecutor.query 方法,核心代码和相关解释如下:
@Override
public <E> List<E> query(MappedStatement ms, Object parameter,
RowBounds rowBounds, ResultHandler resultHandler,
CacheKey key, BoundSql boundSql) throws SQLException {
// 看看是否清除一级缓存
// 清除一级的缓存的条件是:
// 1.配置了 flushCacheRequired 参数为true
// 2. 不存在嵌套查询,就是存在递归
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();
}
List<E> list;
try {
// queryStack 是表示的查询栈个数,递归帧的个数
queryStack++;
// 从一级缓存中取,没取到执行 queryFromDatabase 方法,准备从数据库中取
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
if (queryStack == 0) {
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
// issue #601
deferredLoads.clear();
// 配置是否使用一级缓存,默认是使用的:SqlSession
// 如果配置成了 Statement 就表示不适用一级缓存
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
// issue #482
clearLocalCache();
}
}
return list;
}
- 判断这条sql是否是嵌套sql且被标注了清除一级缓存;
- 从一级缓存中取这条sql的结果集,没找到的话调用
queryFromDatabase方法获取结果集; - 当然一级缓存是和配置的 LocalCacheScope 有关的,即本地缓存设置如果是
SESSION则表示开启,STATEMENT则表示不开启。
(有关一级、二级缓存,我再写篇博客详细讲解,现在先分析查询过程)
queryFromDataBase 源码分析
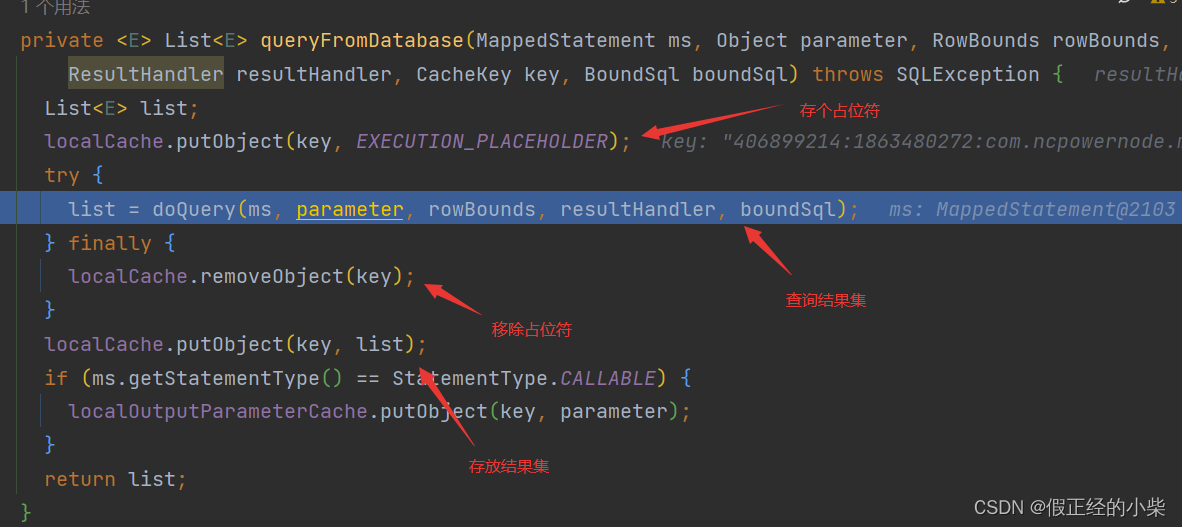
至于为什么填充个占位符,且这会导致多线程执行同一个查询sql的时候出现ClassCastException异常,为什么的话我在这里阐述了:mybatis查询时一级缓存会引发的问题 。
SimpleExecutor.doQuery 方法源码如下,核心语句查询交给了 RoutingStatementHandler.query 方法。
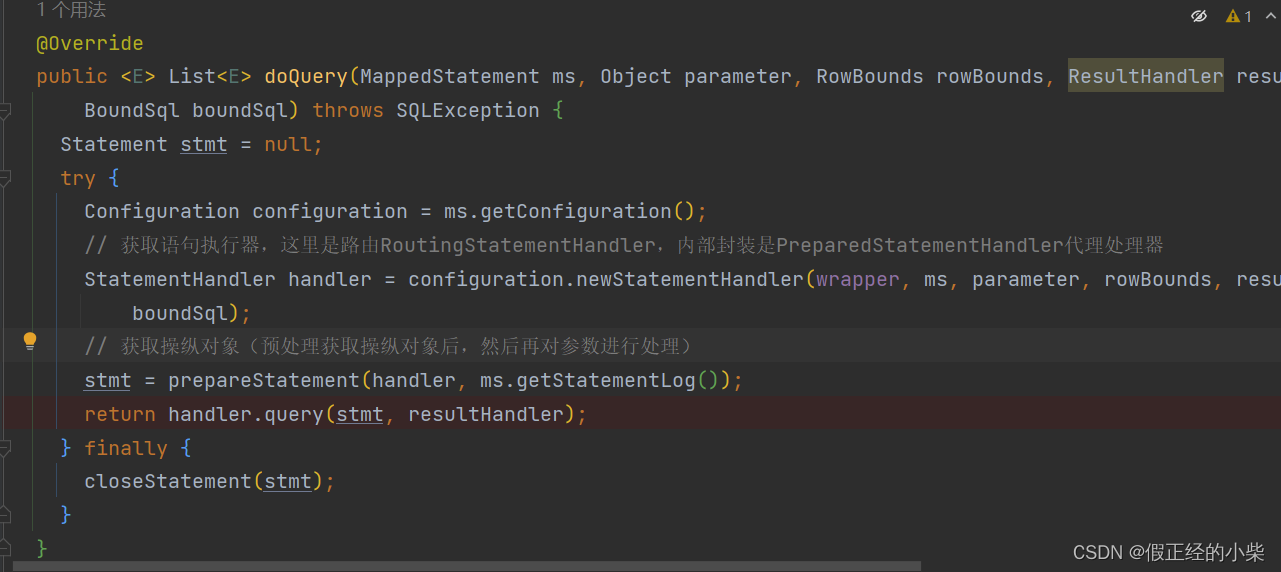 PreparedStatementHandler.query 方法源码(这里的话也可以知道是先执行sql,然后再处理结果集映,即ORM映射):
PreparedStatementHandler.query 方法源码(这里的话也可以知道是先执行sql,然后再处理结果集映,即ORM映射):
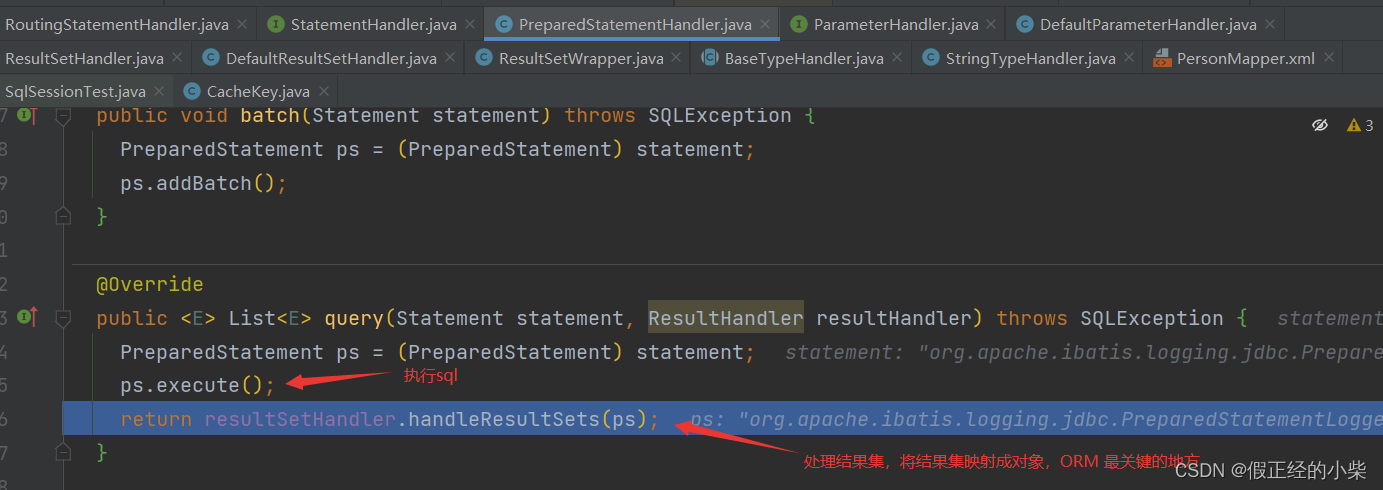 处理结果集映射可以看一下,由于代码比较复杂这里截取一些核心的,首先这个resultSetHandler 是 DefaultResultSetHandler 的对象,是通过它去处理结果集映射的。
处理结果集映射可以看一下,由于代码比较复杂这里截取一些核心的,首先这个resultSetHandler 是 DefaultResultSetHandler 的对象,是通过它去处理结果集映射的。
步骤呢这里梳理一下:
- 首先是去获取到对应的结果集 ResultSet,然后将其封装成 ResultSetWrapper 对象;
- 然后去获取对应 MappedStatement 的 ResultMap,不管是配置的 resultType 还是 resultMap 都会封装成 ResultMap 让 MappedStatement 封装起来;
- 然后通过上面俩调用 handleResultSet 方法去处理结果集;
- 然后在其方法内部又调用 handleRowValues-handleRowValuesForSimpleResultMap 方法 去处理结果集封装成集合对象,然后放入 multipleResults 中返回。
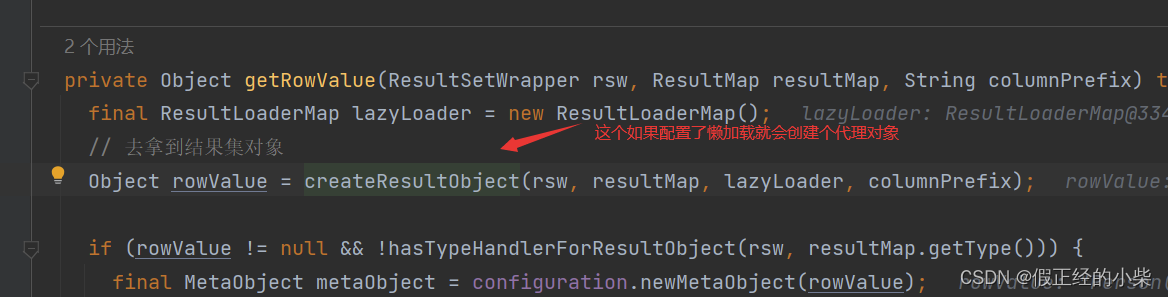
那我们就去分析 handleRowValuesForSimpleResultMap 方法,它方法内部核心就是去遍历 ResultSet 中的每行数据,将其映射成对象,然后搞成结果集,其核心代码是通过 getRowValue 方法去获取一行结果的结果集对象。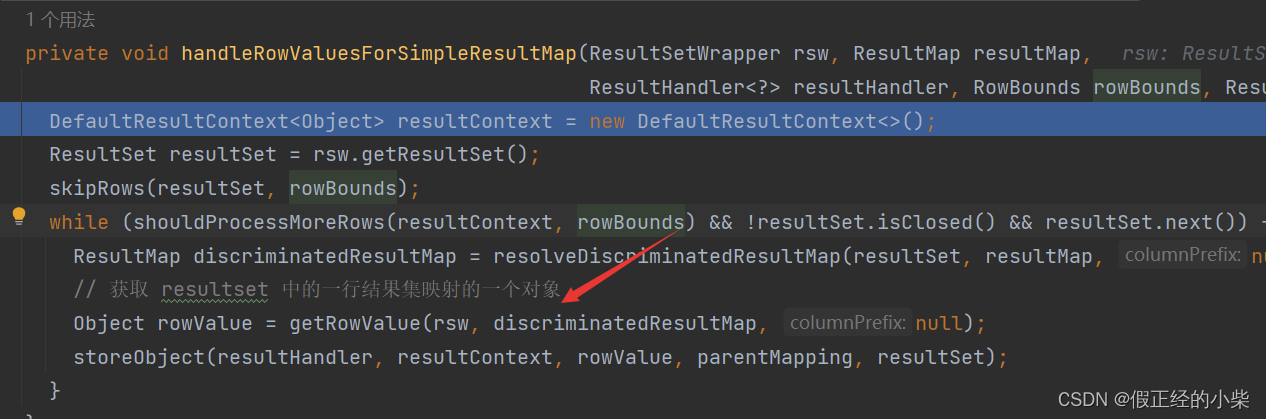 getRowValue 就是重中之重啊,即 ORM 的关键,看下面源代码:
getRowValue 就是重中之重啊,即 ORM 的关键,看下面源代码:
private Object getRowValue(ResultSetWrapper rsw, ResultMap resultMap, String columnPrefix) throws SQLException {
final ResultLoaderMap lazyLoader = new ResultLoaderMap();
// 去拿到结果集对象
Object rowValue = createResultObject(rsw, resultMap, lazyLoader, columnPrefix);
if (rowValue != null && !hasTypeHandlerForResultObject(rsw, resultMap.getType())) {
final MetaObject metaObject = configuration.newMetaObject(rowValue);
boolean foundValues = this.useConstructorMappings;
if (shouldApplyAutomaticMappings(resultMap, false)) {
// 默认是会去执行自动映射的
foundValues = applyAutomaticMappings(rsw, resultMap, metaObject, columnPrefix) || foundValues;
}
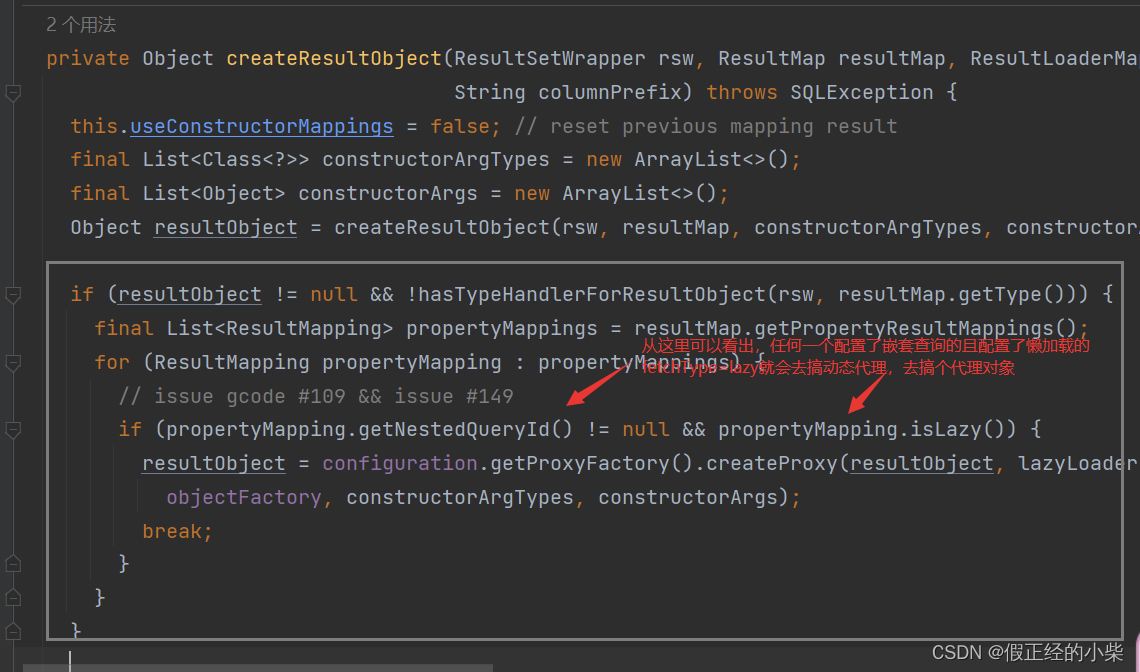
// 根据一堆 ResultMapping 去进行属性映射,这是自己配的,上面是自动的
foundValues = applyPropertyMappings(rsw, resultMap, metaObject, lazyLoader, columnPrefix)
|| foundValues;
foundValues = lazyLoader.size() > 0 || foundValues;
rowValue = foundValues || configuration.isReturnInstanceForEmptyRow() ? rowValue : null;
}
return rowValue;
}
自动映射处理也非常简单,就是拿到那个类型处理器去从 ResultSet 中获取查找的字段值,然后通过 metaObject 工具实体对象去进行映射。
private boolean applyAutomaticMappings(ResultSetWrapper rsw, ResultMap resultMap, MetaObject metaObject,
String columnPrefix) throws SQLException {
List<UnMappedColumnAutoMapping> autoMapping = createAutomaticMappings(rsw, resultMap, metaObject, columnPrefix);
boolean foundValues = false;
if (!autoMapping.isEmpty()) {
for (UnMappedColumnAutoMapping mapping : autoMapping) {
// 拿到 ResultMapping 中的类型处理器去从 ResultSet 中获取字段值
final Object value = mapping.typeHandler.getResult(rsw.getResultSet(), mapping.column);
if (value != null) {
foundValues = true;
}
if (value != null || configuration.isCallSettersOnNulls() && !mapping.primitive) {
// gcode issue #377, call setter on nulls (value is not 'found')
// 将字段的值给映射到 实体对象中
metaObject.setValue(mapping.property, value);
}
}
}
return foundValues;
}
而根据我们配置的属性进行映射呢,它的关键在与获取字段值,因为在这个 ResultMap 中,除了需要处理简单类型映射外,还要处理嵌套查询,这里的话我们看获取字段值方法,它是核心:getPropertyMappingValue
private Object getPropertyMappingValue(ResultSet rs, MetaObject metaResultObject, ResultMapping propertyMapping,
ResultLoaderMap lazyLoader, String columnPrefix) throws SQLException {
// 判断嵌套查询的id是否是空,即select对应的值,是的话表示这个映射不存在嵌套查询
if (propertyMapping.getNestedQueryId() != null) {
// 判断是否是嵌套查询映射,是嵌套查询就执行嵌套查询
return getNestedQueryMappingValue(rs, metaResultObject, propertyMapping, lazyLoader, columnPrefix);
}
if (propertyMapping.getResultSet() != null) {
addPendingChildRelation(rs, metaResultObject, propertyMapping); // TODO is that OK?
return DEFERRED;
} else {
// 这就是简单映射咯
final TypeHandler<?> typeHandler = propertyMapping.getTypeHandler();
final String column = prependPrefix(propertyMapping.getColumn(), columnPrefix);
return typeHandler.getResult(rs, column);
}
}
嵌套查询映射呢我们再好好看看源码:
private Object getNestedQueryMappingValue(ResultSet rs, MetaObject metaResultObject, ResultMapping propertyMapping,
ResultLoaderMap lazyLoader, String columnPrefix) throws SQLException {
final String nestedQueryId = propertyMapping.getNestedQueryId();
final String property = propertyMapping.getProperty();
// 拿到嵌套查询对应的 MappedStatement 实例
final MappedStatement nestedQuery = configuration.getMappedStatement(nestedQueryId);
final Class<?> nestedQueryParameterType = nestedQuery.getParameterMap().getType();
final Object nestedQueryParameterObject = prepareParameterForNestedQuery(rs, propertyMapping,
nestedQueryParameterType, columnPrefix);
Object value = null;
if (nestedQueryParameterObject != null) {
final BoundSql nestedBoundSql = nestedQuery.getBoundSql(nestedQueryParameterObject);
final CacheKey key = executor.createCacheKey(nestedQuery, nestedQueryParameterObject, RowBounds.DEFAULT,
nestedBoundSql);
final Class<?> targetType = propertyMapping.getJavaType();
// 判断在一级缓存中是否存在这个嵌套查询
if (executor.isCached(nestedQuery, key)) {
// 是一级缓存的话它就直接从一级缓存中获取然后映射了
executor.deferLoad(nestedQuery, metaResultObject, property, key, targetType);
value = DEFERRED;
} else {
final ResultLoader resultLoader = new ResultLoader(configuration, executor, nestedQuery,
nestedQueryParameterObject, targetType, key, nestedBoundSql);
if (propertyMapping.isLazy()) {
// 如果配置了 lazy 的话还会进行懒加载
// 如果配置了 fetchType 为 lazy 的话
// 默认是 eager,是不支持懒加载的
lazyLoader.addLoader(property, metaResultObject, resultLoader);
value = DEFERRED;
} else {
// 可以理解为递归了
value = resultLoader.loadResult();
}
}
}
return value;
}
- 首先是从一级缓存中拿,一级缓存中存在的话就直接映射了,返回值对象不重要了;
- 然后在判断是否配置了
fetchType=lazy即懒加载,配置了就放入懒加载行列中; - 没配置懒加载的话就相当于进行了递归操作,去拿到其 executor,然后执行 query 方法。
二、查询流程总结
- 首先是会创建一个执行器:CachingExecutor;
- 如果没有配置二级缓存就会自动让代理 Executor 去执行 query 方法。
- 从一级缓存中获取,没有的话调用
queryFromDatabase方法去获取结果集,queryDataBase 方法内部会去调用 doQuery 方法; - 默认是去预编译获取 PreparedStatement 操纵对象,对参数进行填充后,调用 execute 方法执行 sql。
- 然后调用 handleResultSet 方法去处理结果集映射,它会遍历 ResultSet 中的每行查询结果集,然后将其映射成对象。
- 映射主要有俩处,一处是自动映射,通过
applyAutomaticMappings方法进行自动映射,一处是根据自己属性配置进行映射,通过getPropertyMappingValue方法; - 在处理属性配置映射的时候会去处理配置的嵌套查询。
- 在处理嵌套查询时,是先尝试从一级缓存中获取结果集,如果那个该查询结果集是占位符,说明正在查询,封装到
deferLoad中。 - 看看有没有配置懒加载,
fetchType=lazy,配置了的话就会去封装到lazyLoader懒加载对象中。 - 如果上面俩种情况都不存在的话,就直接加载结果,直接进行查询了。
- 在处理嵌套查询时,是先尝试从一级缓存中获取结果集,如果那个该查询结果集是占位符,说明正在查询,封装到
下面是含 Mapper 代理的一个查询过程的简图。
三、一级、二级缓存
个人觉得一级缓存就是去针对嵌套查询的,因为在实际开发中 SqlSession 的生命周期很短,那么一级缓存可以说就是针对 SqlSession 这个会话域中的在内存中的一个缓存,虽然在查询的过程也会去从一级缓存中取,但是最实用的地方还是在属性映射的时候遇到嵌套查询,然后去一级缓存看看有没有存在结果集。
二级缓存的话我觉得是一个全局的缓存,需自己在Mapper中配置cache标签表示使用二级缓存,且要在对应的语句标签上写上 useCache 属性为 true,表示这个语句使用二级缓存,然后会在对应的 MappedStatement 对象中封装这个 Cache 对象。在查询的过程中就会首先走这个二级缓存,不存在的话才会去走代理查询。
下面的图是很好的诠释
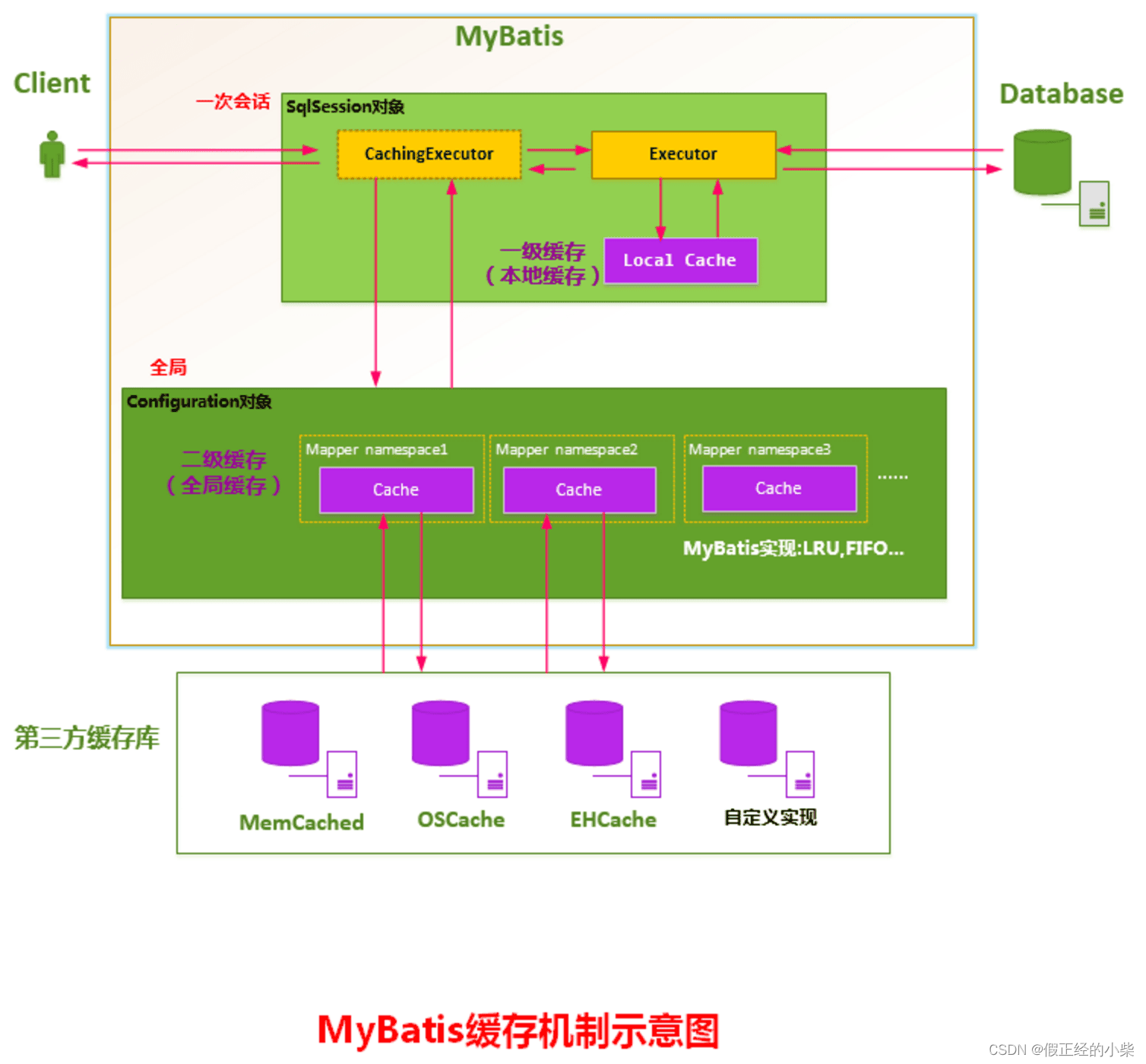
注意:二级缓存需在 sqlSession 提交或者关闭的时候才会把一级缓存刷新到二级缓存才能使用。但在实际开发中由于 sqlSession 的会话很短,所以这个也是不用担心的。(准确点说是执行器内封装了个事务Cache,事务Cache内又封装了咱的二级Cache对象还有个本地缓存,那个本地缓存就本应该是二级内的缓存的,然后提交或者关闭sqlSession之后呢,会调用flushPendingEntries方法将事务Cache里缓存的弄到二级Cache中)
当然使用二级缓存可能会存在一些问题,比如分布式下的缓存一致性如何解决;如果有俩个表的查询缓存,会引发缓存不准备的情况等等。
可以看看下面俩篇我觉得优秀文章,图不错~
总的来说一级缓存会默认帮你用,嵌套查询显示的明显,二级缓存的话谨慎使用,特别是分布式的情况下。
四、懒加载源码分析
lazyLoader 对象是一个 ResultLoaderMap 对象,其本质是内部封装了一个 hashMap,先用来缓存一下懒加载的对象。

那它何时被加载呢?肯定是被结果集对象有关,本质是使用了动态代理,只有执行了get方法才会去加载对应的结果集。具体源码我们往下看:
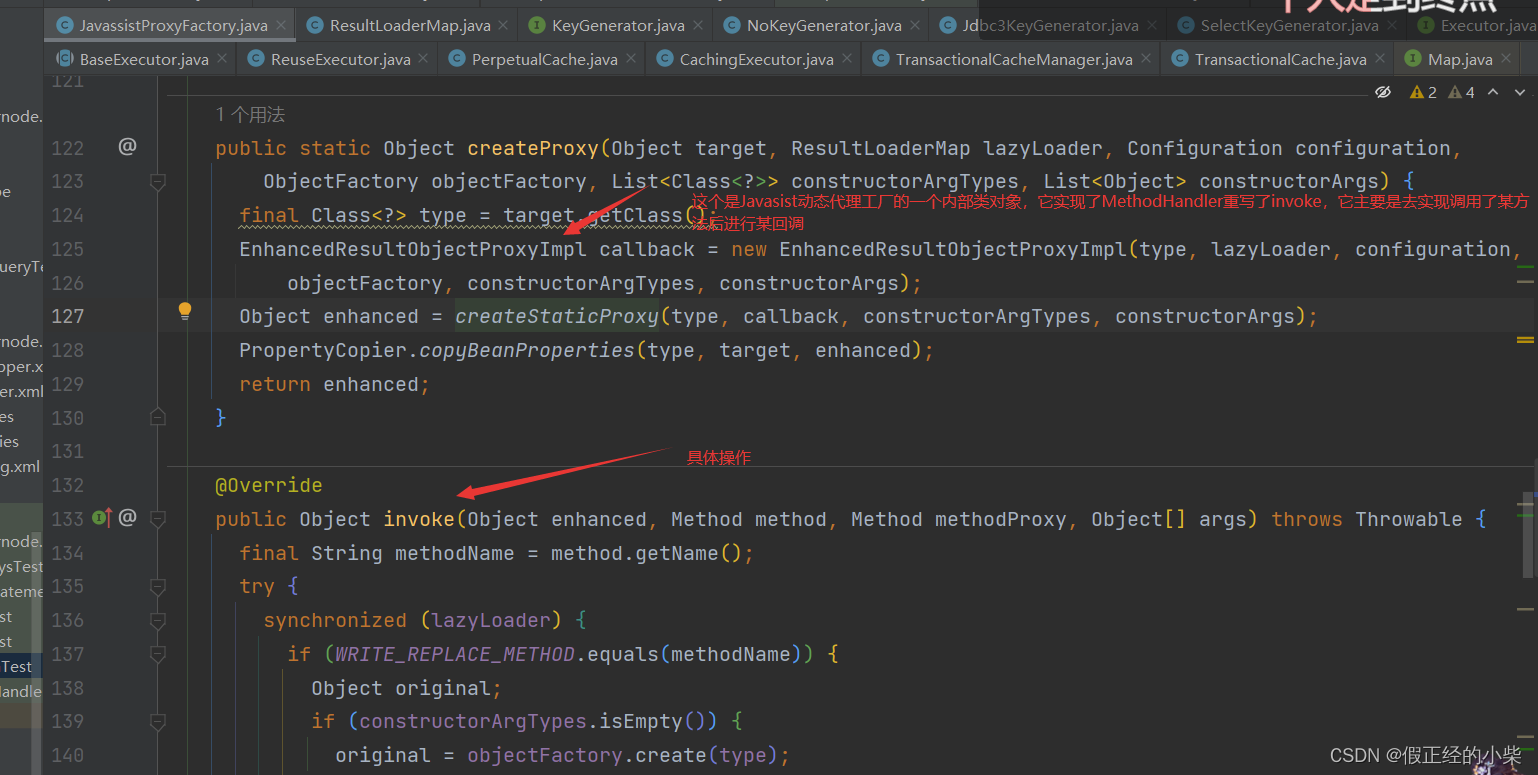 下面对代理的核心代码进行核心源码解析(每次执行映射对象的方法都会回调这个方法,首先是判断懒加载中是否存在加载对象,然后判断方法不为finalize,它是一个垃圾回收方法):
下面对代理的核心代码进行核心源码解析(每次执行映射对象的方法都会回调这个方法,首先是判断懒加载中是否存在加载对象,然后判断方法不为finalize,它是一个垃圾回收方法):
@Override
public Object invoke(Object enhanced,
Method method, Method methodProxy,
Object[] args) throws Throwable {
final String methodName = method.getName();
try {
synchronized (lazyLoader) {
if (lazyLoader.size() > 0 && !FINALIZE_METHOD.equals(methodName)) {
// 这个和配置的 aggressiveLazyLoading 有关,如果配置为true
// 那么就是说如果遇到 lazyLoadTriggerMethods 配置的相关方法
// 那么就全部加载lazyLoader中的内容
if (aggressive || lazyLoadTriggerMethods.contains(methodName)) {
lazyLoader.loadAll();
}
// 如果执行了内部的setter方法就移除对应的懒加载实例
// 它只判断是不是set方法,是不是修改了属性它不管哦
else if (PropertyNamer.isSetter(methodName)) {
final String property = PropertyNamer.methodToProperty(methodName);
lazyLoader.remove(property);
}
// 如果执行了内部的getter方法就加载结果集
// 然后通过那个MetaObject对象去映射到真正的结果对象中
else if (PropertyNamer.isGetter(methodName)) {
final String property = PropertyNamer.methodToProperty(methodName);
if (lazyLoader.hasLoader(property)) {
lazyLoader.load(property);
}
}
}
}
return methodProxy.invoke(enhanced, args);
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
}
注意:
aggressiveLazyLoading在在 3.4.1 及之前的版本中默认为
true,现在新的版本默认是false了。lazyLoadTriggerMethods的话在配置方法表时候用,分割开。
最后对懒加载的一个总结:
- 如果你在你写的嵌套查询中配置了懒加载(fetchType=true),那么它在根据 resultType 或者 resultMap 中的 type 属性值去得到映射对象时,就会去搞个动态代理对象,至于这个代理对象是通过 javassist 动态代理工厂实现的。
- 代理方法实现呢就是在执行方法前进行一个回调,如果是 set 方法就移除 lazyLoader 中的加载嵌套查询,如果是 get 就加载对应的嵌套查询,如果配置了
aggressiveLazyLoader,且方法在配置lazyLoadTriggerMethods中,那么就会对 lazyLoader 的所有缓存的进行加载。加载后的结果集会通过 MetaObject 赋值给原始对象。