例题1
注释的形式是 *comment 1*,请编写函数找出字符串中的注释,并以*comment 1*\ code *comment 2*\为例,找出其中的comment 1和comment 2
import re
#注释的形式是 \*comment 1*\,请编写函数找出字符串中的注释,并以\*comment 1*\ code \*comment 2*\为例,找出其中的comment 1和comment 2
def find_comments(input_string):
# 使用正则表达式查找注释
comments = re.findall(r'\*(.*?)\*', input_string)
return comments
# 示例字符串
example_string = " \*comment 1*\ code \*comment 2*\ "
# 调用函数查找注释
found_comments = find_comments(example_string)
# 打印结果
for i, comment in enumerate(found_comments):
print(f"comment {
i + 1}: {
comment}")
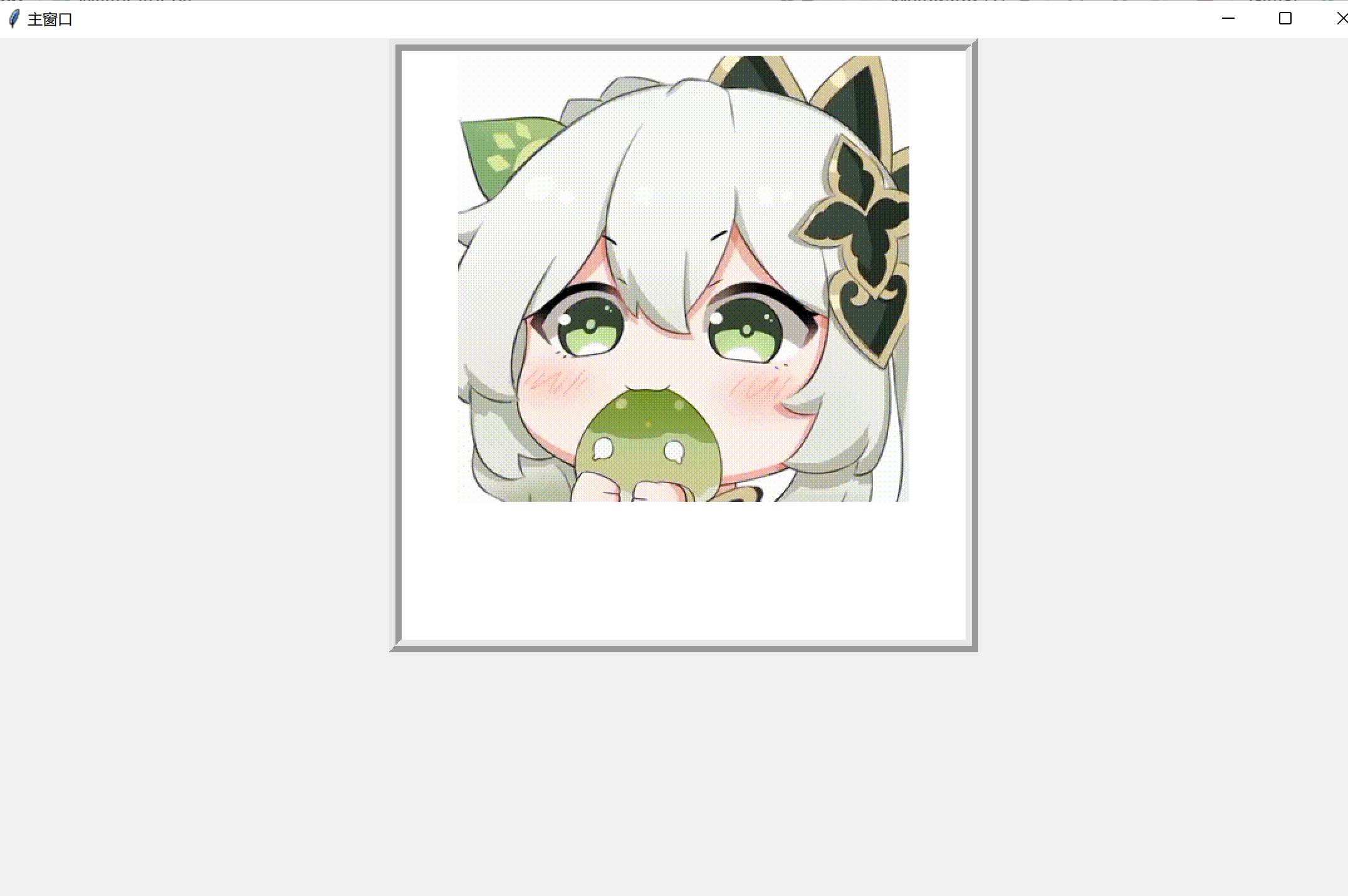
GUI编程
import tkinter as tk
from tkinter import Tk
def createWin(title,width,height,x,y):
window=Tk()
window.title(title)
window.geometry(f"{
width}x{
height}+{
x}+{
y}")
return window
root = createWin('主窗口', 1100, 700, 100, 50)
str = tk.StringVar()
str.set("这是TKinter所支持的字符串类型")
image = tk.PhotoImage(file="C:\\Users\\83854\\Pictures\\表情包\\i2Q2r-8ph2Z2bT3cSa0-9w.gif")
#image = Image.open("C:\\Users\\83854\\Pictures\\壁纸\\n7Qjrt-8llaK1yT3cSk3-sg.gif")
#photo = ImageTk.PhotoImage(image)
label = tk.Label(root,
#背景选项
height = 250, #标签的高度,单位为像素
width = 250,
padx=100, #字符离边框(标签右边界)的距离
pady=110, #字符离边框(标签上边界)的距离
background="white",
relief="ridge", #Label 系统样式
borderwidth=10,
# 文本
text = "卡通图画",
textvariable = str, #textvariable与text同时存在时,显示textvariable
justify = "center",
foreground = "black",
underline = 10, #第10个字符画下划线
anchor = "s", #注意该属性与padx和pady相互影响
#图形
image=image,
compound = "bottom")
label.pack()
root.mainloop()
输出:
正则表达式
正则表达式(regular expression)描述了一种字符串匹配的模式(pattern),
是字符串处理的有力工具和技术,可以快速、准确地完成复杂的查找、替换等处理要求。
正则表达式是由普通字符以及特殊字符(称为"元字符")组成的文字模式。 普通字符包括没有显式指定为元字符的所有可打印和不可打印字符,包括所有大写和小写字母、所有数字、所有标点符号和一些其他符号。
Python中,re模块提供了正则表达式操作所需要的功能。
匹配
^ 行首匹配,和在[]里的^不是一个意思
$ 行尾匹配
\A 匹配字符串的开始,和^的区别是:
\A只匹配整个字符串的开头,即使在re.M的模式下也不会匹配其他行的行首
\Z 匹配字符串结束,它和$的区别是:
\Z只匹配整个字符串的结束,即使在 re.M的模式下也不会匹配其他行的行尾
\b 匹配一个单词的边界,也就是值单词和空格间的位置
\B 匹配非单词的边界
#re.M多行匹配
print(re.findall("^tom","tom is a boy \ntom is a boy",re.M))#结果['tom', 'tom']
print(re.findall("\Atom","tom is a boy \ntom is a boy",re.M))#结果['tom']
print(re.search(r"er\b","never "))#匹配到
print(re.search(r"er\b"," nerve"))#没有
print(re.search(r"er\B","never "))#没有
print(re.search(r"er\B","nerve"))#匹配到
D:\coder\randomnumbers\venv\Scripts\python.exe D:/coder/randomnumbers/MyIterator.py
['tom', 'tom']
['tom']
<re.Match object; span=(3, 5), match='er'>
None
None
<re.Match object; span=(1, 3), match='er'>
进程已结束,退出代码0
在data..dat中,“\”、””和”.”都是特殊字符,
在正则表达式中具有特殊的意思:
. 匹配或代表 除换行符以外的任意单个字符
- 匹配或代表位于*之前的字符或子模式的0次或多次
\ 表示位于\之后的为转义字符
import re
s='data.dat\ndata1.dat\ndata2.dat\ndata12.dat\ndatax.dat\ndataXYZ.dat'
print(re.findall( r'data.*?\.dat' , s ))
D:\coder\randomnumbers\venv\Scripts\python.exe D:/coder/randomnumbers/MyIterator.py
['data.dat', 'data1.dat', 'data2.dat', 'data12.dat', 'datax.dat', 'dataXYZ.dat']
进程已结束,退出代码0
^ 为匹配输入字符串的开始位置。
[0-9] 匹配单个数字,+ 匹配一个或者多个,[0-9]+匹配多个数字。
abc 匹配字母 a b c 并以 a b c 结尾, 匹配字母 abc 并以 abc 结尾, 匹配字母abc并以abc结尾, 为匹配输入字符串的结束位置
import re
s='23454fghdfghabc'
result=re.findall( '^[0-9]+.*?abc$' , s )
print(result)
D:\coder\randomnumbers\venv\Scripts\python.exe D:/coder/randomnumbers/MyIterator.py
['23454fghdfghabc']
进程已结束,退出代码0
普通字符
普通字符包括没有显式指定为元字符的所有可打印和不可打印字符。这包括所有大写和小写字母、所有数字、所有标点符号和一些其他符号。
import re
pattern = re.compile('[abc]', re.S)
titles = re.findall(pattern, 'adfgjk\n23vvcdbdsfa')
print(titles)
.的作用是匹配除“\n”以外的任何字符
re.S表示模式的作用扩展到整个字符串,包括“\n”
在这里插入代码片
D:\coder\randomnumbers\venv\Scripts\python.exe D:/coder/randomnumbers/MyIterator.py
['a', 'c', 'a']
进程已结束,退出代码0
[^ABC] 匹配除了 […] 中字符的所有字符
import re
pattern = re.compile('[^abc]', re.S)
titles = re.findall(pattern, 'adfgjk\n23vvcdbdsfa')
print(titles)
D:\coder\randomnumbers\venv\Scripts\python.exe D:/coder/randomnumbers/MyIterator.py
['d', 'f', 'g', 'j', 'k', '\n', '2', '3', 'v', 'v', 'd', 'd', 's', 'f']
进程已结束,退出代码0
[A-Z] 表示一个区间,匹配所有大写字母,
[a-z] 表示所有小写字母
[0-9]表示数字0,1直到9
import re
pattern = re.compile('[a-d]', re.S)
titles = re.findall(pattern, 'adfgjk23vvcdbdsfa')
print(titles)
D:\coder\randomnumbers\venv\Scripts\python.exe D:/coder/randomnumbers/MyIterator.py
['a', 'd', 'c', 'd', 'b', 'd', 'a']
进程已结束,退出代码0
import re
pattern = re.compile('[^\n\r]', re.S)
titles = re.findall(pattern, 'a\ns\rf')
print(titles)
D:\coder\randomnumbers\venv\Scripts\python.exe D:/coder/randomnumbers/MyIterator.py
['a', 's', 'f']
进程已结束,退出代码0
\s 是匹配所有空白符,包括换行,
\S 非空白符,不包括换行
import re
pattern = re.compile('[\s]', re.S)
titles = re.findall(pattern, 'a\ns\rf')
print(titles)
D:\coder\randomnumbers\venv\Scripts\python.exe D:/coder/randomnumbers/MyIterator.py
['\n', '\r']
进程已结束,退出代码0
import re
pattern = re.compile('\S', re.S)
titles = re.findall(pattern, 'a\ns\rf')
print(titles)
D:\coder\randomnumbers\venv\Scripts\python.exe D:/coder/randomnumbers/MyIterator.py
['a', 's', 'f']
进程已结束,退出代码0
\w匹配字母、数字、下划线。等价于 [A-Za-z0-9_]
\W与\w含义相反,与“[^A-Za-z0-9_]”等效
非打印字符
非打印字符也可以是正则表达式的组成部分。
字符 描述
\cx 匹配由x指明的控制字符。例如, \cM 匹配一个 Control-M
或 回车符。x 的值必须为 A-Z 或 a-z 之一。否则,将 c 视为
一个原义的 ‘c’ 字符。
\f 匹配一个换页符。等价于 \x0c 和 \cL。
\n 匹配一个换行符。等价于 \x0a 和 \cJ。
\r 匹配一个回车符。等价于 \x0d 和 \cM。
\s 匹配任何空白字符,包括空格、制表符、换页符等等。
等价于 [ \f\n\r\t\v]。注意 Unicode 正则表达式会匹配全角空格符。
\S 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。
\t 匹配一个制表符。等价于 \x09 和 \cI。
\v 匹配一个垂直制表符。等价于 \x0b 和 \cK。
特殊字符
所谓特殊字符,就是一些有特殊含义的字符.
若要匹配这些特殊字符,必须首先使字符"转义",即,将反斜杠字符\ 放在它们前面。
特别字符 描述
$ 匹配输入字符串的结尾位置。如果设置了 RegExp 对象的 Multiline
属性,则 $ 也匹配 ‘\n’ 或 ‘\r’。要匹配 $ 字符本身,请使用 $。
( ) 标记一个子表达式的开始和结束位置。子表达式可以获取供以后使用。
- 匹配前面的子表达式零次或多次。要匹配 * 字符,请使用 *。
- 匹配前面的子表达式一次或多次。要匹配 + 字符,请使用 +。
. 匹配任何单字符。要匹配 . ,请使用 . 。
[ 标记一个中括号表达式的开始。要匹配 [,请使用 [。
? 匹配前面的子表达式零次或一次,或指明一个非贪婪限定符。
\ 将下一个字符标记为或特殊字符、或原义字符、或向后引用、 或八进
制转义符。例如, ‘n’ 匹配字符 ‘n’。‘\n’ 匹配换行符。序列 ‘\’ 匹配 “”。
^ 匹配输入字符串的开始位置,除非在方括号表达式中使用,当该符号在
方括号表达式中使用时,表示不接受该方括号表达式中的字符集合。
{ 标记限定符表达式的开始。要匹配 {,请使用 {。
| 指明两项之间的一个选择。要匹配 |,请使用 |。
限定符
限定符用来指定正则表达式的一个给定组件必须要出现多少次才能满足匹配。有 * 或 + 或 ? 或 {n} 或 {n,} 或 {n,m} 共6种。
字符 描述
- 匹配前面的子表达式零次或多次。
例如,zo* 能匹配 “z” 以及 “zoo”。* 等价于{0,}。
- 匹配前面的子表达式一次或多次。例如,
‘zo+’ 能匹配 “zo” 以及 “zoo”,但不能匹配 “z”。+ 等价于 {1,}。
? 匹配前面的子表达式零次或一次。例如,“do(es)?” 可以匹配 “do” 、
“does” 中的 “does” 、 “doxy” 中的 “do” 。? 等价于 {0,1}。
{n} n 是一个非负整数。匹配确定的 n 次。例如,‘o{2}’ 不能匹配 “Bob”
中的 ‘o’,但是能匹配 “food” 中的两个 o。
{n,} n 是一个非负整数。至少匹配n 次。例如,‘o{2,}’ 不能匹配 “Bob” 中
的 ‘o’,但能匹配 “foooood” 中的所有 o。
‘o{1,}’ 等价于 ‘o+’。‘o{0,}’ 则等价于 ‘o*’。
{n,m} m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。
例如,“o{1,3}” 将匹配 “fooooood” 中的前三个 o。‘o{0,1}’ 等价于
‘o?’。请注意在逗号和两个数之间不能有空格。
定位符
定位符使您能够将正则表达式固定到行首或行尾。它们还使您能够创建这样的正则表达式,这些正则表达式出现在一个单词内、在一个单词的开头或者一个单词的结尾。
字符 描述
^ 匹配输入字符串开始的位置。
$ 匹配输入字符串结尾的位置。
\b 匹配一个单词边界,即字与空格间的位置。
\B 非单词边界匹配。