目录
一、全连接网络实现
1、实现说明
(1) 输入和输出
输入:28*28手写数字图片
输出:判定该图像对应的数字
(2) 网络结构
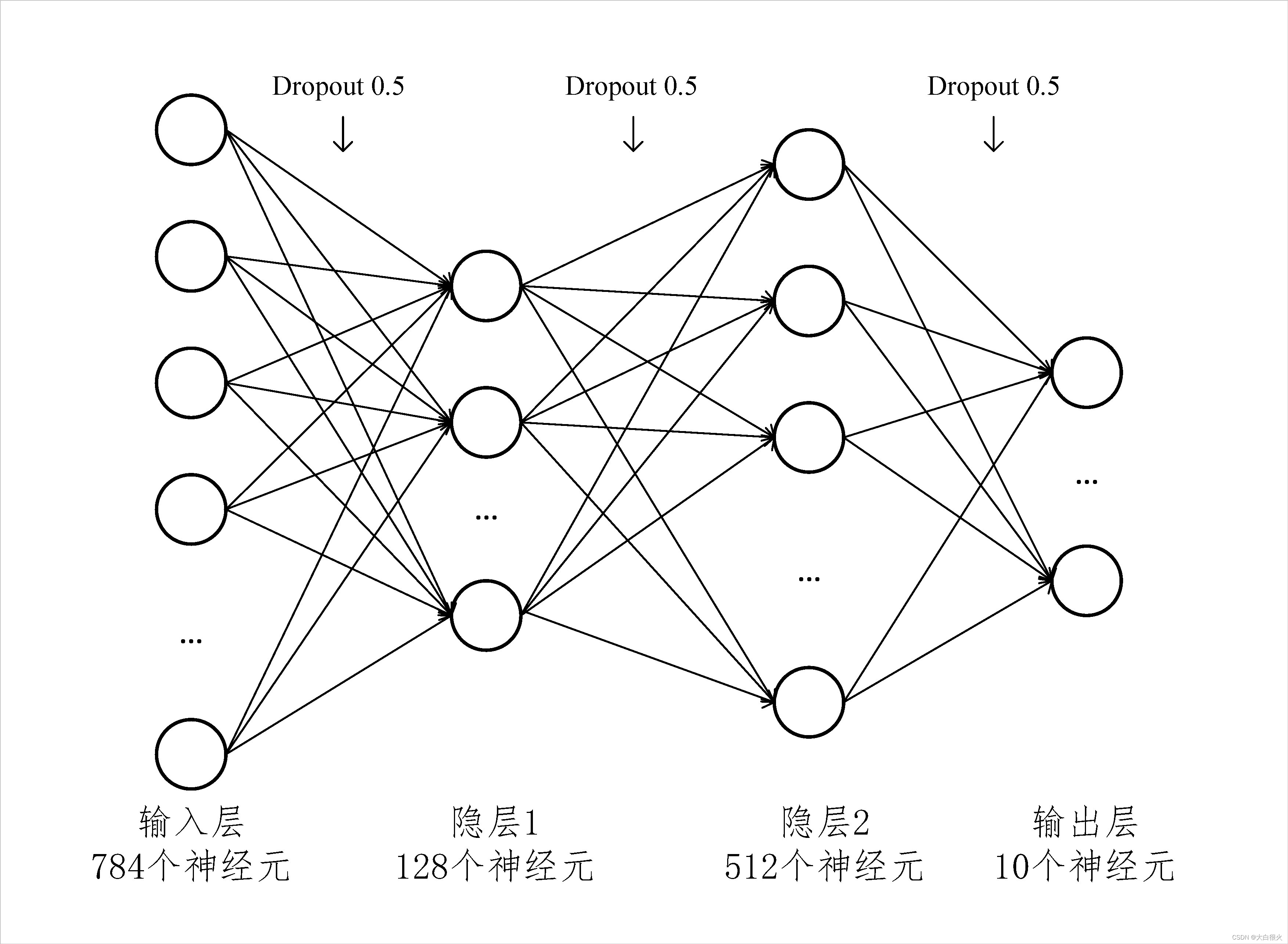
2、代码实现
import torch
import numpy as np
from torch import nn
from torch.nn import functional as F
from pathlib import Path
import requests
import pickle
import gzip
from torch.utils.data import TensorDataset
from torch.utils.data import DataLoader
from torch import optim
from time import time
class MNIST_NN(nn.Module):
def __init__(self):
super().__init__()
self.hidden1 = nn.Linear(784, 128)
self.hidden2 = nn.Linear(128, 512)
# self.hidden3 = nn.Linear(256, 512)
self.out = nn.Linear(512, 10)
self.dropout = nn.Dropout(0.5)
# 97.64% 3个隐层
# 97.79% 2个隐层 第2隐层256神经元
# 97.82% 2个隐层 第2隐层512神经元
def forward(self, x):
x = F.relu(self.hidden1(x))
x = self.dropout(x)
x = F.relu(self.hidden2(x))
# x = self.dropout(x)
# x = F.relu(self.hidden3(x))
x = self.dropout(x)
return self.out(x)
# ############################### 查看网络的参数
# print(net)
# # 打印权重参数
# for name, parameter in net.named_parameters():
# print(name, parameter)
def get_model():
model = MNIST_NN()
return model, optim.Adam(model.parameters(), lr=0.001) # Adam
def get_data(bs):
DATA_PATH = Path("data")
PATH = DATA_PATH / "mnist"
PATH.mkdir(parents=True, exist_ok=True)
URL = "https://storage.googleapis.com/cvdf-datasets/mnist/"
FILENAME = "mnist.pkl.gz"
if not (PATH / FILENAME).exists():
content = requests.get(URL + FILENAME).content
(PATH / FILENAME).open("wb").write(content)
with gzip.open((PATH / FILENAME).as_posix(), "rb") as f:
((x_train, y_train), (x_valid, y_valid), _) = pickle.load(f, encoding="latin-1")
x_train, y_train, x_valid, y_valid = map(torch.tensor, (x_train, y_train, x_valid, y_valid))
train_ds = TensorDataset(x_train, y_train)
valid_ds = TensorDataset(x_valid, y_valid)
return (
DataLoader(train_ds, batch_size=bs, shuffle=True),
DataLoader(valid_ds, batch_size=bs * 2)
)
def loss_batch(model, loss_func, xb, yb, opt=None):
loss = loss_func(model(xb), yb)
if opt is not None:
loss.backward()
opt.step()
opt.zero_grad()
return loss.item(), len(xb)
# 定义训练函数
def fit(steps, model, loss_func, opt, train_dl, valid_dl):
for step in range(steps):
start_time = time()
model.train() # 指定model的模式,一般训练模型时加上model.train()就会正常使用Batch Normalization和Dropout
# 更新权重和偏置
for xb, yb in train_dl:
loss_batch(model, loss_func, xb, yb, opt)
model.eval() # 指定model的模式,一般训练模型时加上model.eval()就不会正常使用Batch Normalization和Dropout
with torch.no_grad():
losses, nums = zip(*[loss_batch(model, loss_func, xb, yb) for xb, yb in valid_dl])
val_loss = np.sum(np.multiply(losses, nums)) / np.sum(nums)
end_time = time()
print("当前step: " + str(step) + ",验证集平均损失:" + str(val_loss), ", 消耗时间:", end_time - start_time)
correct = 0
total = 0
for xb, yb in valid_dl:
outputs = model(xb)
_, predicted = torch.max(outputs.data, 1)
total += yb.size(0)
correct += (yb == predicted).sum().item()
print("Acc: ", 100 * correct / total, "%")
if __name__ == '__main__':
bs = 64 # batch_size = 64
epoch = 30
train_dl, valid_dl = get_data(bs)
loss_func = F.cross_entropy
model, opt = get_model()
fit(epoch, model, loss_func, opt, train_dl, valid_dl)
3、运行结果
C:\Users\Administrator\.conda\envs\torzml\python.exe D:/Project/PythonProject/LSTM_text/others/MNISTReco.py
当前step: 0,验证集平均损失:0.1683511969923973 , 消耗时间: 3.590179204940796
当前step: 1,验证集平均损失:0.1312192772962153 , 消耗时间: 3.058769941329956
当前step: 2,验证集平均损失:0.11431313703283667 , 消耗时间: 2.9534740447998047
当前step: 3,验证集平均损失:0.10498983032917604 , 消耗时间: 3.0124051570892334
当前step: 4,验证集平均损失:0.09412320185815916 , 消耗时间: 3.009488344192505
当前step: 5,验证集平均损失:0.093143627073057 , 消耗时间: 2.890739917755127
当前step: 6,验证集平均损失:0.09063829299034551 , 消耗时间: 3.1035313606262207
当前step: 7,验证集平均损失:0.08887825601268559 , 消耗时间: 3.6453356742858887
当前step: 8,验证集平均损失:0.08634029937214219 , 消耗时间: 3.641497850418091
当前step: 9,验证集平均损失:0.08860128401129042 , 消耗时间: 4.121753215789795
当前step: 10,验证集平均损失:0.08582983395410701 , 消耗时间: 3.940110445022583
当前step: 11,验证集平均损失:0.08012033958600369 , 消耗时间: 3.7954063415527344
当前step: 12,验证集平均损失:0.08083907972197048 , 消耗时间: 3.8298981189727783
当前step: 13,验证集平均损失:0.07870770492306911 , 消耗时间: 3.784552812576294
当前step: 14,验证集平均损失:0.0787701717220014 , 消耗时间: 3.679483652114868
当前step: 15,验证集平均损失:0.07930033117127605 , 消耗时间: 3.6713767051696777
当前step: 16,验证集平均损失:0.07984851049119607 , 消耗时间: 3.6588127613067627
当前step: 17,验证集平均损失:0.07337796090731863 , 消耗时间: 3.672180414199829
当前step: 18,验证集平均损失:0.07625965428813361 , 消耗时间: 3.6567420959472656
当前step: 19,验证集平均损失:0.07491345010597725 , 消耗时间: 3.6410393714904785
当前step: 20,验证集平均损失:0.07532293595063966 , 消耗时间: 3.6485989093780518
当前step: 21,验证集平均损失:0.07646674913240131 , 消耗时间: 3.6318893432617188
当前step: 22,验证集平均损失:0.07439087963479106 , 消耗时间: 3.6764001846313477
当前step: 23,验证集平均损失:0.07468655214742757 , 消耗时间: 3.6644670963287354
当前step: 24,验证集平均损失:0.07627506786901504 , 消耗时间: 3.6473772525787354
当前step: 25,验证集平均损失:0.07737481498552952 , 消耗时间: 3.6624276638031006
当前step: 26,验证集平均损失:0.07628958516074927 , 消耗时间: 3.6760411262512207
当前step: 27,验证集平均损失:0.07489939673700718 , 消耗时间: 3.670935869216919
当前step: 28,验证集平均损失:0.07496044216285809 , 消耗时间: 3.631747007369995
当前step: 29,验证集平均损失:0.07229171380188491 , 消耗时间: 3.705427646636963
Acc: 97.94 %
进程已结束,退出代码 0
二、卷积神经网络实现
1、实现说明
(1)输入和输出
输入:28*28手写数字图片
输出:判定该图像对应的数字
(2)网络结构
2、代码实现
import gzip
import pickle
from pathlib import Path
import requests
from torch import nn
from torch import optim
import torch
import time
# 网络结构
from torch.utils.data import TensorDataset, DataLoader
class MnistNet(nn.Module):
def __init__(self):
super(MnistNet, self).__init__()
self.conv1 = nn.Sequential( # (b, 1, 28, 28)
nn.Conv2d(in_channels=1, out_channels=16, kernel_size=5, stride=1, padding=2), # (b, 16, 28, 28)
nn.ReLU(),
nn.MaxPool2d(2) # (b, 16, 14, 14)
)
self.conv2 = nn.Sequential(
nn.Conv2d(in_channels=16, out_channels=32, kernel_size=5, stride=1, padding=2), # (b, 32, 14, 14)
nn.ReLU(),
nn.Conv2d(in_channels=32, out_channels=32, kernel_size=5, stride=1, padding=2), # (b, 32, 14, 14)
nn.ReLU(),
nn.MaxPool2d(2) # (b, 32, 7, 7)
)
self.conv3 = nn.Sequential(
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5, stride=1, padding=2), # (b, 64, 7, 7)
nn.ReLU()
)
self.out = nn.Linear(64*7*7, 10)
def forward(self, x):
x = x.view(-1, 1, 28, 28)
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = x.view(x.size(0), -1)
output = self.out(x)
return output
def get_data(bs):
DATA_PATH = Path("data")
PATH = DATA_PATH / "mnist"
PATH.mkdir(parents=True, exist_ok=True)
URL = "https://storage.googleapis.com/cvdf-datasets/mnist/"
FILENAME = "mnist.pkl.gz"
if not (PATH / FILENAME).exists():
content = requests.get(URL + FILENAME).content
(PATH / FILENAME).open("wb").write(content)
with gzip.open((PATH / FILENAME).as_posix(), "rb") as f:
((x_train, y_train), (x_valid, y_valid), _) = pickle.load(f, encoding="latin-1")
x_train, y_train, x_valid, y_valid = map(torch.tensor, (x_train, y_train, x_valid, y_valid))
device = "cuda" if torch.cuda.is_available() else "cpu"
x_train, y_train, x_valid, y_valid = x_train.to(device), y_train.to(device), x_valid.to(device), y_valid.to(device)
train_ds = TensorDataset(x_train, y_train)
valid_ds = TensorDataset(x_valid, y_valid)
return (
DataLoader(train_ds, batch_size=bs, shuffle=True),
DataLoader(valid_ds, batch_size=bs * 2)
)
def get_model():
model = MnistNet()
return model, optim.Adam(model.parameters(), lr=0.001)
def accuracy(predictions, labels):
pred = torch.max(predictions, 1)[1]
rights = pred.eq(labels.data.view_as(pred)).sum()
return rights, len(labels)
def fit(model, optimizer, bs, epochs, loss_func):
train_dl, valid_dl = get_data(bs)
for epoch in range(epochs):
train_rights = []
for batch_index, (xb, yb) in enumerate(train_dl):
model.train()
output = model(xb)
loss = loss_func(output, yb)
optimizer.zero_grad()
loss.backward()
optimizer.step()
rights = accuracy(output, yb)
train_rights.append(rights)
# print(batch_index)
if batch_index % 100 == 0:
model.eval()
valid_rights = []
for xb, yb in valid_dl:
rights = accuracy(model(xb), yb)
valid_rights.append(rights)
# 准确率计算
train_rate = (sum([tup[0] for tup in train_rights]), sum([tup[1] for tup in train_rights]))
valid_rate = (sum([tup[0] for tup in valid_rights]), sum([tup[1] for tup in valid_rights]))
print('当前epoch: {} [{} / {} ({:.2f}%)]\t损失: {:.6f} \t 训练集准确率: {:.2f}%\t 测试集准确率: {:.2f}%'.format(
epoch,
batch_index * bs,
len(train_dl.dataset),
100. * batch_index / len(train_dl),
loss.data,
100. * train_rate[0].cpu().numpy() / train_rate[1],
100. * valid_rate[0].cpu().numpy() / valid_rate[1]
))
train_rights = []
if __name__ == '__main__':
bs = 64
epochs = 10
loss_func = nn.CrossEntropyLoss()
model, optimizer = get_model()
device = "cuda" if torch.cuda.is_available() else "cpu"
model.to(device)
fit(model, optimizer, bs, epochs, loss_func)
3、运行结果
C:\Users\Administrator\.conda\envs\torzml\python.exe D:/Project/PythonProject/LSTM_text/others/Mnist_Conv.py
当前epoch: 0 [0 / 50000 (0.00%)] 损失: 2.301290 训练集准确率: 7.81% 测试集准确率: 11.80%
当前epoch: 0 [6400 / 50000 (12.79%)] 损失: 0.341838 训练集准确率: 76.25% 测试集准确率: 94.57%
当前epoch: 0 [12800 / 50000 (25.58%)] 损失: 0.088409 训练集准确率: 94.03% 测试集准确率: 96.25%
当前epoch: 0 [19200 / 50000 (38.36%)] 损失: 0.208718 训练集准确率: 96.33% 测试集准确率: 97.55%
当前epoch: 0 [25600 / 50000 (51.15%)] 损失: 0.123537 训练集准确率: 97.09% 测试集准确率: 97.80%
当前epoch: 0 [32000 / 50000 (63.94%)] 损失: 0.018433 训练集准确率: 97.47% 测试集准确率: 97.76%
当前epoch: 0 [38400 / 50000 (76.73%)] 损失: 0.097949 训练集准确率: 97.95% 测试集准确率: 98.00%
当前epoch: 0 [44800 / 50000 (89.51%)] 损失: 0.070966 训练集准确率: 97.72% 测试集准确率: 98.37%
当前epoch: 1 [0 / 50000 (0.00%)] 损失: 0.123680 训练集准确率: 98.44% 测试集准确率: 98.05%
当前epoch: 1 [6400 / 50000 (12.79%)] 损失: 0.100362 训练集准确率: 98.19% 测试集准确率: 98.56%
当前epoch: 1 [12800 / 50000 (25.58%)] 损失: 0.035721 训练集准确率: 98.30% 测试集准确率: 98.46%
当前epoch: 1 [19200 / 50000 (38.36%)] 损失: 0.007506 训练集准确率: 98.56% 测试集准确率: 98.70%
当前epoch: 1 [25600 / 50000 (51.15%)] 损失: 0.016346 训练集准确率: 98.41% 测试集准确率: 98.50%
当前epoch: 1 [32000 / 50000 (63.94%)] 损失: 0.035862 训练集准确率: 98.47% 测试集准确率: 98.66%
当前epoch: 1 [38400 / 50000 (76.73%)] 损失: 0.050021 训练集准确率: 98.56% 测试集准确率: 98.45%
当前epoch: 1 [44800 / 50000 (89.51%)] 损失: 0.013187 训练集准确率: 98.52% 测试集准确率: 98.41%
当前epoch: 2 [0 / 50000 (0.00%)] 损失: 0.020915 训练集准确率: 100.00% 测试集准确率: 98.88%
当前epoch: 2 [6400 / 50000 (12.79%)] 损失: 0.091681 训练集准确率: 99.33% 测试集准确率: 98.56%
当前epoch: 2 [12800 / 50000 (25.58%)] 损失: 0.034122 训练集准确率: 98.95% 测试集准确率: 98.88%
当前epoch: 2 [19200 / 50000 (38.36%)] 损失: 0.074170 训练集准确率: 98.78% 测试集准确率: 98.63%
当前epoch: 2 [25600 / 50000 (51.15%)] 损失: 0.018684 训练集准确率: 98.92% 测试集准确率: 98.45%
当前epoch: 2 [32000 / 50000 (63.94%)] 损失: 0.007384 训练集准确率: 98.80% 测试集准确率: 98.89%
当前epoch: 2 [38400 / 50000 (76.73%)] 损失: 0.015758 训练集准确率: 99.12% 测试集准确率: 98.95%
当前epoch: 2 [44800 / 50000 (89.51%)] 损失: 0.014709 训练集准确率: 99.12% 测试集准确率: 98.70%
当前epoch: 3 [0 / 50000 (0.00%)] 损失: 0.001915 训练集准确率: 100.00% 测试集准确率: 98.89%
当前epoch: 3 [6400 / 50000 (12.79%)] 损失: 0.005979 训练集准确率: 99.30% 测试集准确率: 98.58%
当前epoch: 3 [12800 / 50000 (25.58%)] 损失: 0.007681 训练集准确率: 98.98% 测试集准确率: 98.94%
当前epoch: 3 [19200 / 50000 (38.36%)] 损失: 0.007919 训练集准确率: 99.19% 测试集准确率: 99.07%
当前epoch: 3 [25600 / 50000 (51.15%)] 损失: 0.060704 训练集准确率: 99.16% 测试集准确率: 98.71%
当前epoch: 3 [32000 / 50000 (63.94%)] 损失: 0.055418 训练集准确率: 99.14% 测试集准确率: 98.90%
当前epoch: 3 [38400 / 50000 (76.73%)] 损失: 0.033441 训练集准确率: 99.12% 测试集准确率: 98.90%
当前epoch: 3 [44800 / 50000 (89.51%)] 损失: 0.028578 训练集准确率: 99.03% 测试集准确率: 98.94%
当前epoch: 4 [0 / 50000 (0.00%)] 损失: 0.016460 训练集准确率: 98.44% 测试集准确率: 98.89%
当前epoch: 4 [6400 / 50000 (12.79%)] 损失: 0.031492 训练集准确率: 99.39% 测试集准确率: 99.08%
当前epoch: 4 [12800 / 50000 (25.58%)] 损失: 0.023526 训练集准确率: 99.44% 测试集准确率: 98.76%
当前epoch: 4 [19200 / 50000 (38.36%)] 损失: 0.004695 训练集准确率: 99.34% 测试集准确率: 98.94%
当前epoch: 4 [25600 / 50000 (51.15%)] 损失: 0.000252 训练集准确率: 99.34% 测试集准确率: 99.01%
当前epoch: 4 [32000 / 50000 (63.94%)] 损失: 0.020111 训练集准确率: 99.27% 测试集准确率: 99.08%
当前epoch: 4 [38400 / 50000 (76.73%)] 损失: 0.024171 训练集准确率: 99.52% 测试集准确率: 98.94%
当前epoch: 4 [44800 / 50000 (89.51%)] 损失: 0.014028 训练集准确率: 99.16% 测试集准确率: 99.04%
当前epoch: 5 [0 / 50000 (0.00%)] 损失: 0.000271 训练集准确率: 100.00% 测试集准确率: 99.24%
当前epoch: 5 [6400 / 50000 (12.79%)] 损失: 0.017214 训练集准确率: 99.64% 测试集准确率: 99.15%
当前epoch: 5 [12800 / 50000 (25.58%)] 损失: 0.000260 训练集准确率: 99.53% 测试集准确率: 99.02%
进程已结束,退出代码 -1