科学研究中有时候咱们收集到的数据很乱,不能马上进行分析,如SEER数据,用过都知道,咱们需要对数据进行清洗,从数据中提取咱们需要的东西,才能进行分析,这时候有个有用的东西叫正则式,对于我们在字符串中提取数据非常实用,上一章《R语言提取文字(字符串)中的内容–正则式(1)》咱们已经初步介绍了一些正则式的常见函数,今天咱们进一步介绍正则式使用。
别害怕看不懂,你正在一点点向前迈进!这个东西需要慢慢积累!
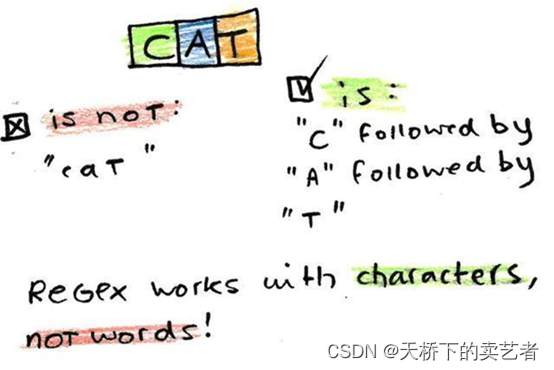
我们先导入数据,假设咱们有一串很乱的数据,
readLines("E:/r/test/messages.txt")

而我们想需要对它进行整理,咱们需要找到其中关于水果的数据,方便利于统计,但是计算机可不认识什么是水果
正则表达式提供了一系列用于表示模式的符号。
上述模式可以被描述成^\w+:\s\d+$,
其中的元符号(meta-symbols)用来表示一类字符。下面是一些简单的介绍,具体看参考文献。
• ^:这个符号表示一行的开始。
• \w:这个符号表示一个字母或数字。
• \s:这个符号表示一个空格字符。
• \d:这个符号表示一个数字字符。
• $:这个符号表示一行的结束。
"\w+“意味着一个或更多个字母,”:"是我们希望在单词后面看到的符号,
"\d+"表示一个或更多个数字字符。这个模式表达了所有我们需要的情况,并且排除了所有不需要的情况。
我们先进行我们需要的匹配,继续使用上次咱们使用的grep函数来匹配字符串。我们可以看到水果中例如苹果(apple: 20)都是这种字母加冒号(:)再加数字来表示,但是字母的个数不确定,数字的个数不确定,因此我们可以告诉计算机,字母加冒号(:)再加数字就是水果。
我们先写一个规则匹配符。
matches <- grep("^\\w+:\\s\\d+$",bc)

上面这段代码我来解释一下,^表示这行开始,$表示这行结束,\w 中 \w表示开头的是字母,但是\需要再加一个\来转义,所以写成2个\,\w+表示它可以是一个或者多个字符。接着的冒号(:)表示我们在字母后面需要看到一个冒号。\s表示冒号后面接着一个空格,还要再加一个\进行转义,我们这里注意一下,空格也是要占位的,不处理空格很多时候会导致匹配失败 ,\d+和w+的意思差不多,表示1个或者多个数字,也是要再加一个\进行转义的,所以写成\d+。这段内容体会一下。
根据规则,计算机帮我们选出1,3,5,6是水果,咱们提取就可以了。
bc[matches]

这样就轻易把其中的水果的内容提取出来了。如果咱们使用stringr包,功能更加强大,它是以矩阵的形式提取数据,
library(stringr)
matches <- str_match(bc,"^(\\w+):\\s(\\d+)$")
matches

Stringr包的str_match函数规则与grep稍微不同,多个字符匹配的内容需要括号()包起来,而且它的功能更加强大,把每个组件都提取出来,我更加喜欢。
咱们再来看个例子,先导入数据
be<-readLines("E:/r/test/messages.txt")
be

数据连在一起,我们需要的是下面这样的数据,分类分条好的
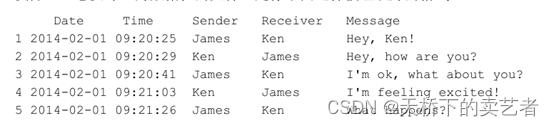
这相当于数据清理了,当数据量大的时候是没办法手工做的。咱们先对数据其中一行进行分析,可以看到第一个是日期,带二个是时间,后面两个是字母,不过一个是逗号连接,一个是空格连接,还是很有规律的
2014-02-01,09:20:29,Ken,James,Hey, how are you?
继续使用刚才我们使用的str_ _match函数,
日期的提取可以使用
(\\d+-\\d+-\\d+)
时间的的提取可以用
(\\d+:\\d+:\\d+)
提取逗号连接的字符
(\\w+),(\\w+)
提取空格链接的字符,这里要说一下\s表示空格,但是要注意一下大写S和小写s是不同的。\s*表空格出现零次、一次或者更多次,(.+)中,点符号(.)可代替任意符号,(.+)在这里表示可以是任意内容,最后以$结尾
\\s*(.+)$
咱们把上面的内容串联起来
pattern <- "^(\\d+-\\d+-\\d+),(\\d+:\\d+:\\d+),(\\w+),(\\w+),\\s*(.+)$"
matches <- str_match(be,pattern)

可以看到内容都被单独提取出来了稍微整理一下就是咱们所需要的数据了
df <- data.frame(matches[, -1])
colnames(df) <- c("Date", "Time", "Sender", "Receiver", "Message")

正则式初看有些复杂,当你理解掌握后用处很大,这个需要慢慢的积累。
推荐几个好的教程,共同学习,见参考文献
参考文献
- https://github.com/ziishaned/learn-regex/blob/master/translations/README-cn.md#4-零宽度断言前后预查
- http://www.regexlab.com/zh/regref.htm
- R语言编程指南
- R语言编程艺术
- R数据科学