1. 问题一:pytroch-ssd : RuntimeError: Expected a 'cuda' device type for generator but found 'cpu'
解决:File "C:\ProgramData\Anaconda3\lib\site-packages\torch\utils\data\sampler.py", line 133, in __iter__ yield from torch.randperm(n, generator=generator).tolist()。点击该报错的链接,定位到sampler.py文件中,找到如图1所示位置,121行和122行进行修改,将generator = troch.Generator() 修改为generator = torch.Generator(device='cuda')即可。
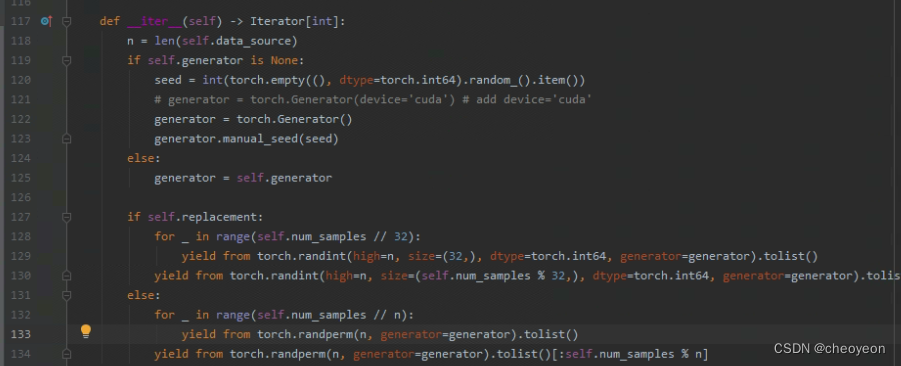
图1
2. 问题二:IndexError: Caught IndexError in DataLoader worker process 0.
解决:将num_works设置为0 ,parser.add_argument('--num_workers', default=0, type=int,help='Number of workers used in dataloading')
3. 问题三:当只有一个类别时,注意点
当只有一个类别时,需要修改为NUM_CLASSES= [('people')],给类别中小括号外再添加一个中括号。
4. 问题四:IndexError: too many indices for array: array is 1-dimensional, but 2 were indexed
解决:说明某些xml文件中没有标签,也就是没有object,所以需要将此类xml文件进行删除。
5. 问题五:IndexError: invalid index of a 0-dim tensor. Use tensor.item() in Python or tensor.item<T>()
解决:由于pytorch版本不一致导致的问题,将所有类似报错中的.data[0]改为.item()
# 把data[0]全部改为.item()
self.losses[loss name] = losses [loss name] .data[0]
self.losses[loss name] = losses [loss name] .item()6. 问题六:StopIteration
解决:将train.py165行代码
images, targets = next(batch_iterator)改为:
try:
images, targets = next(batch_iterator)
except StopIteration:
batch_iterator = iter(data_loader)
images, targets = next(batch_iterator)
7. 问题七:训练时,LOSS为nan
解决:可以尝试将train.py中的学习率从0.001改为1e-4
8. 问题八:运行eval.py时,args = parser.parse_args()处报错,运行过程中可能出现pytest错误
解决:将eval.py文件中,最后三行的test_net改为set_net,并且将该方法的具体实现,也同样改成set_net。右键运行eval.py时,会从原来的run pytest in eval.py 变为 run eval
9. 问题九:运行eval.py时,报错:TypeError:can only concatenate str(not "int") to str
解决:将eval.py中代码进行修改
# 原代码
# dataset = MaizeDetection(args.voc_root, [('2007', set_type)],
# BaseTransform(300, dataset_mean),
# MaizeAnnotationTransform())
# 修改后
dataset = MaizeDetection(args.voc_root, set_type,
BaseTransform(300, dataset_mean),
MaizeAnnotationTransform())10. 问题十:RuntimeError: Legacy autograd function with non-static forward method is deprecated. Please use new-style autograd function with static forward method. (Example:
解决:首先根据http://t.csdnimg.cn/nQ4NQ修改detection.py中的内容,然后在ssd.py中进行如下修改
# if self.phase == "test":
# output = self.detect(
# loc.view(loc.size(0), -1, 4), # loc preds
# self.softmax(conf.view(conf.size(0), -1,
# self.num_classes)), # conf preds
# self.priors.type(type(x.data)) # default boxes
# )
#修改为
if self.phase == "test":
output = self.detect.apply(self.num_classes, 0, 200, 0.01, 0.45,
loc.view(loc.size(0), -1, 4), # loc preds
self.softmax(conf.view(-1,
self.num_classes)), # conf preds
self.priors.type(type(x.data)) # default boxes
)
11. 问题十一:UserWarning: An output with one or more elements was resized since it had shape [80], which does not match the required output shape [84].
12. 问题十二:DeprecationWarning: elementwise comparison failed; this will raise an error in the future. if dets == []:
解决:将 if dets == []: 替换为 if len(dets) == 0:即可。
13. 问题十三:DeprecationWarning: `np.bool` is a deprecated alias for the builtin `bool`.
解决:将出现的np.bool替换成bool即可。
总结:在使用pytorch-ssd进行实验过程中,数据集格式转换在本人的http://t.csdnimg.cn/Xahl7这篇文章第三部分;本篇只是为记录一些实验过程中遇到的错误以及解决......
参考资料: