# -*- coding: UTF-8 -*-'''
@Project :拆分
@File :test.py
@IDE :PyCharm
@Author :一晌小贪欢([email protected])
@Date :2023/10/11 15:01
'''import jieba
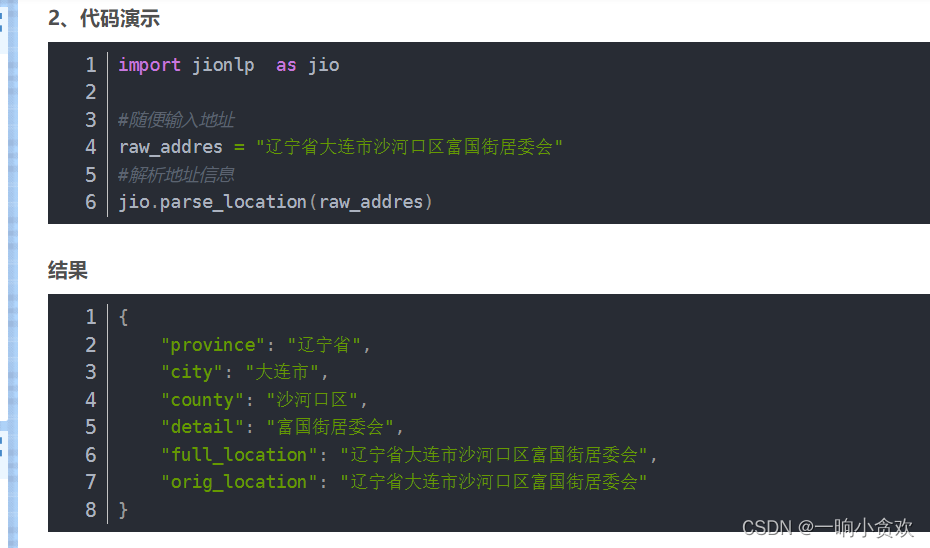
text ="安徽省、浙江省、江苏省、上海市,冷运标快首重1kg价格xx元,1.01kg(含)-5kg(不含)续重价格xx元/kg,5kg(含)以上续重价格xx元/kg。广西壮族自治区"
seg_list = jieba.lcut(text)
province =""
city =""
district =""
add_list =[]for word in seg_list:if"省"in word:
province = word
# 省# print(province)
add_list.append(province)elif"市"in word:
city = word
# 市# print(city)
add_list.append(city)elif"区"in word:
district = word
# 区# print(district)
add_list.append(district)print(add_list)