前言
Cookie 反爬虫指的是服务器端通过校验请求头中的 Cookie 值来区分正常用户和爬虫程序的手段,这种手段被广泛应用在 Web 应用中。
这次主要是对各类cookie值加密的网站情况进行分析
学习响应cookie和session的处理
学习基于首页返回的cookie值
声明
本文章中所有内容仅供学习交流使用,不用于其他任何目的,不提供完整代码,抓包内容、敏感网址、数据接口等均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关。
本文章未经许可禁止转载,禁止任何修改后二次传播,擅自使用本文讲解的技术而导致的任何意外,作者均不负责,若有侵权,请联系作者立即删除,请各位自觉遵守相关法律法规。
一. cookie反爬虫
1.1 特征提示
cookie加密一般有一个特征:会对服务器进行多次请求才能有数据
两种形式/情况
- 1.直接访问对方服务器,服务器通过响应头返回给你一个cookie值(一般有一个关键词会在头部,叫做set-cookie)
- 2.第一次请求对方服务器时,对方返回一些JS文件,在浏览器里面通过JS算法等情况获得一个cookie值,然后第二次请求时候携带该JS生成的cookie值 进行请求网站。对方显示正常数据(该方法相对来说比较频繁)
2.2 cookie加密原理

二. 实战分析
- 逆向目标:某某zf网站
- 逆向参数:X-Csrf-Token参数/cookie值
- 逆向接口:pubList(cookie)/published?via=pc(X-Csrf-Token)
对该网站进行分析
接口:pubList
对其进行分析,发现载荷部分没有加密,请求头部分cookie值可能有/X-Csrf-Token:参数部分也可能有
然后写了一个demo进行测试
cookie值中的szxx_session值以及请求头中的X-Csrf-Token值会导致是否能够进行请求成功
X-Csrf-Token:值位置是在头部文档请求的响应里面
所以我们需要的就是对这两个参数进行破解
因为X-Csrf-Token值进行刷新后未更改,所以直接复制,然后进行搜索这个只是从哪来的
确定该值位置是在HTML里面
所以想要获取该值,请求其接口,然后进行正则表达式进行搜索即可获取该值

分析cookie值,看一下应用里面,可以确认该两个cookie值都是后端返回的,也就是上文中说到的特征情况一,所以直接打开服务器返回的第一个响应头包,看看是不是有set_cookie值并判断是否为我们所需要的,发现确实是我们所需要的网站位置
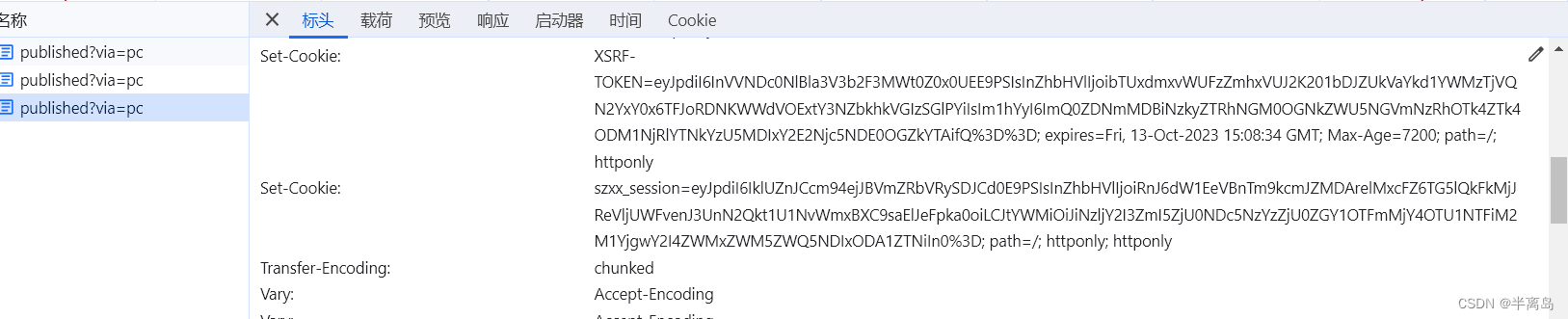
然后就很简单了,对二者部分进行请求和爬虫即可
代码如下
import requests
import re
headers = {
"Accept": "application/json, text/plain, */*",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8",
"Cache-Control": "no-cache",
"Connection": "keep-alive",
"Content-Type": "application/x-www-form-urlencoded",
"Origin": "http://www.zjmazhang.gov.cn",
"Pragma": "no-cache",
"Referer": "http://www.zjmazhang.gov.cn/",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36",
"X-CSRF-TOKEN": "LeeXVPsnXRIFt1SKxeuKyfptfSvcRaw1aCkfO5D1"
}
def get_index():
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8",
"Cache-Control": "no-cache",
"Connection": "keep-alive",
"Pragma": "no-cache",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36"
}
url = "http://www.zjmazhang.gov.cn/hdjlpt/published?via=pc"
response = requests.get(url, headers=headers)
# print(response.cookies)
XSRF_TOKEN = response.cookies.get('XSRF-TOKEN')
szxx_session = response.cookies.get('szxx_session')
X_Csrf_Token = re.findall("var _CSRF = '(.*?)';", response.text, re.S) # 使用re.S参数以后,正则表达式会将这个字符串作为一个整体,在整体中进行匹配。(允许进行换行匹配)
print(X_Csrf_Token)
return XSRF_TOKEN, szxx_session, X_Csrf_Token[0] if X_Csrf_Token else ''
def get_data():
XSRF_TOKEN, szxx_session, X_Csrf_Token = get_index()
headers['X-CSRF-TOKEN'] = X_Csrf_Token
url = 'http://www.zjmazhang.gov.cn/hdjlpt/letter/pubList'
cookies = {
"XSRF-TOKEN": XSRF_TOKEN,
"szxx_session": szxx_session
}
print(headers)
data = {
"offset": "0",
"limit": "20",
"site_id": "759010",
"time_from": "1665676800",
"time_to": "1697212799"
}
response = requests.post(url, headers=headers, cookies=cookies, data=data, verify=False)
print(response.text)
print(response)
if __name__ == '__main__':
get_data()
结果如下

写在最后:
本人写作水平有限,如有讲解不到位或者讲解错误的地方,还请各位大佬在评论区多多指教,共同进步.如有需要代码和讲解交流,可以加本人微信18847868809