- 注重版权,转载请注明原作者和原文链接
- 作者:向往同学
目录
最近无事练手的爬虫项目(老活新整),希望各位大佬给出意见,谢谢。
最近无事练手的爬虫项目(老活新整),希望各位大佬给出意见,谢谢。
一、视频分析
1、首先获取手机端的视频分享链接:7.99 [email protected] 03/27 TlC:/ 复制打开抖音,看看【生活随拍 可能有关】被你艾特的人 这个冬天要陪你一起去看雪. https://v.douyin.com/idbkmge8/
2、在浏览器打开后面的链接:https://v.douyin.com/idbkmge8/,然后F12打开控制台,左上角箭头图标选中视频区域,跳转到视频区域的代码找到video签,里面有三个src视频链接(都能跳转到无水印的原视频)
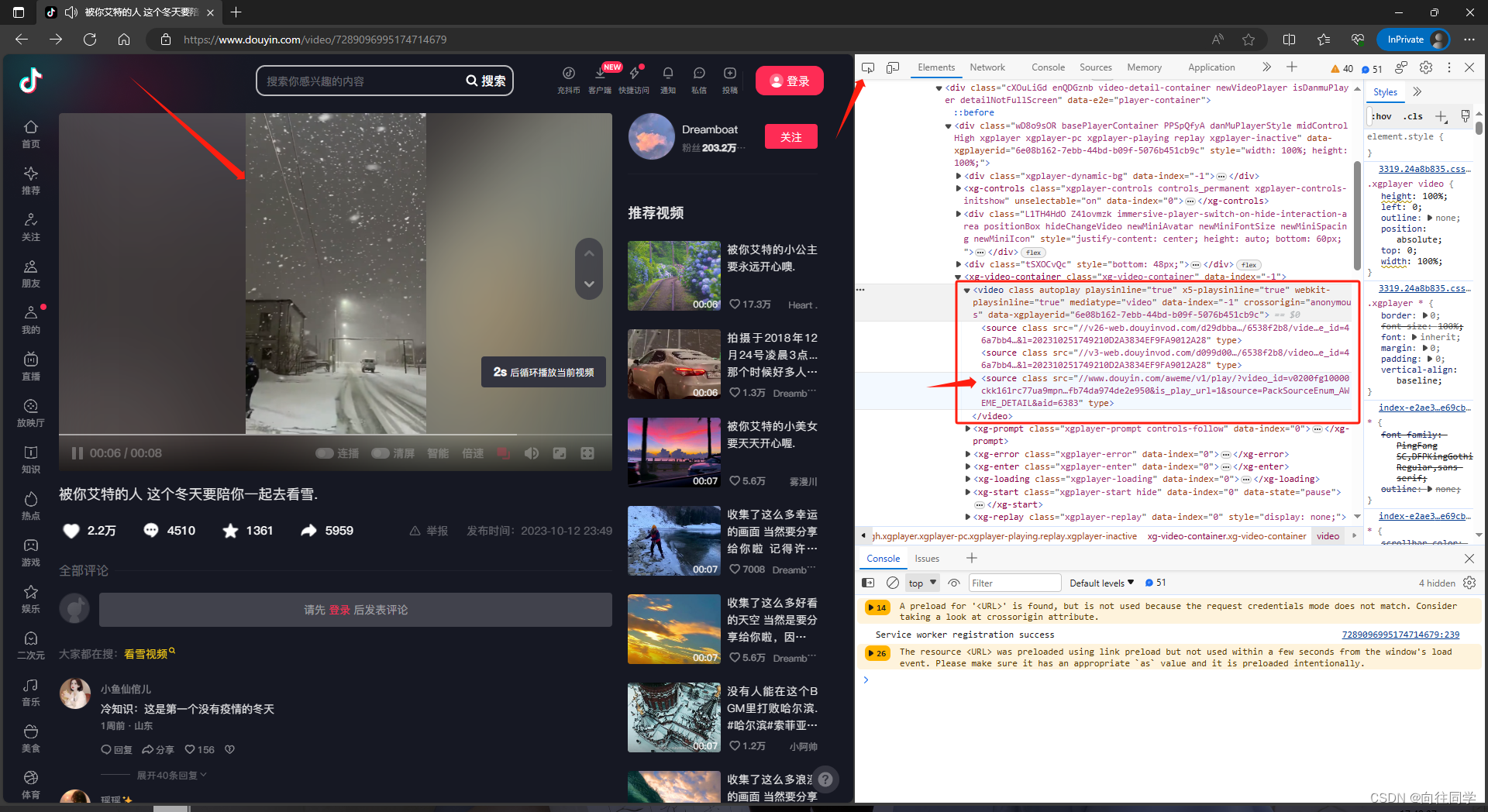
3、我们分析第三个src链接:www.douyin.com/aweme/v1/play/?video_id=v0200fg10000ckk161rc77ua9mpnl2i0&line=0&file_id=0ba9741f8a0f4c50a82d8cc39404c8b9&sign=3aed81ae44d4d276fb74da974de2e950&is_play_url=1&source=PackSourceEnum_AWEME_DETAIL&aid=6383
链接很长我们试着删除video_id=v0200fg10000ckk161rc77ua9mpnl2i0以后的所有参数得到新链接:www.douyin.com/aweme/v1/play/?video_id=v0200fg10000ckk161rc77ua9mpnl2i0然后访问发现可以得到原视频(video_id后面的参数属于视频的id不能删除)

4、到这我们就已经拿到无水印的视频了,但是那个video_id怎么获取呢?在控制台找到左边的包然后打开它获取到的json在aweme_detail里面的video里面的play_addr下的uri:"v0200fg10000ckk161rc77ua9mpnl2i0"这就是我们要找的video_id

5、接着我们看看这个包的请求头:很长并且里面涉及到了多个参数分析后试着删掉一些参数都会导致请求失败,所以这个包不适合我们使用,既然pc端的包这么复杂,那就试着抓取手机端的包
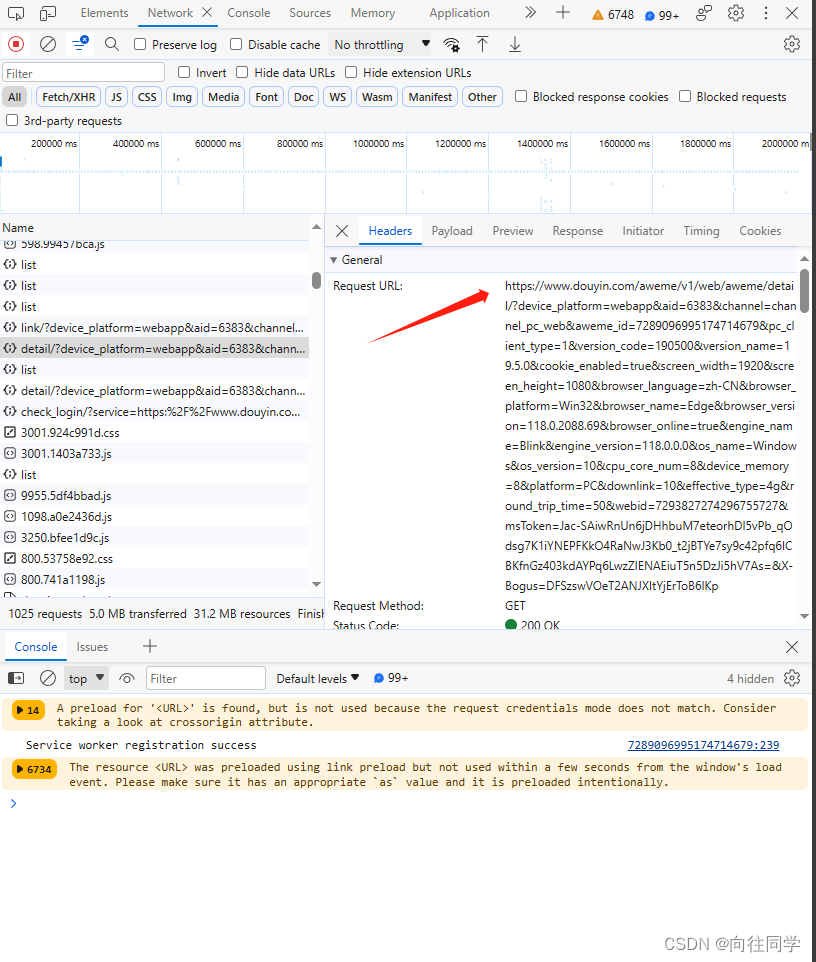
6、设置手机端:左上角箭头标记旁边,设置完成后刷新页面得到手机端
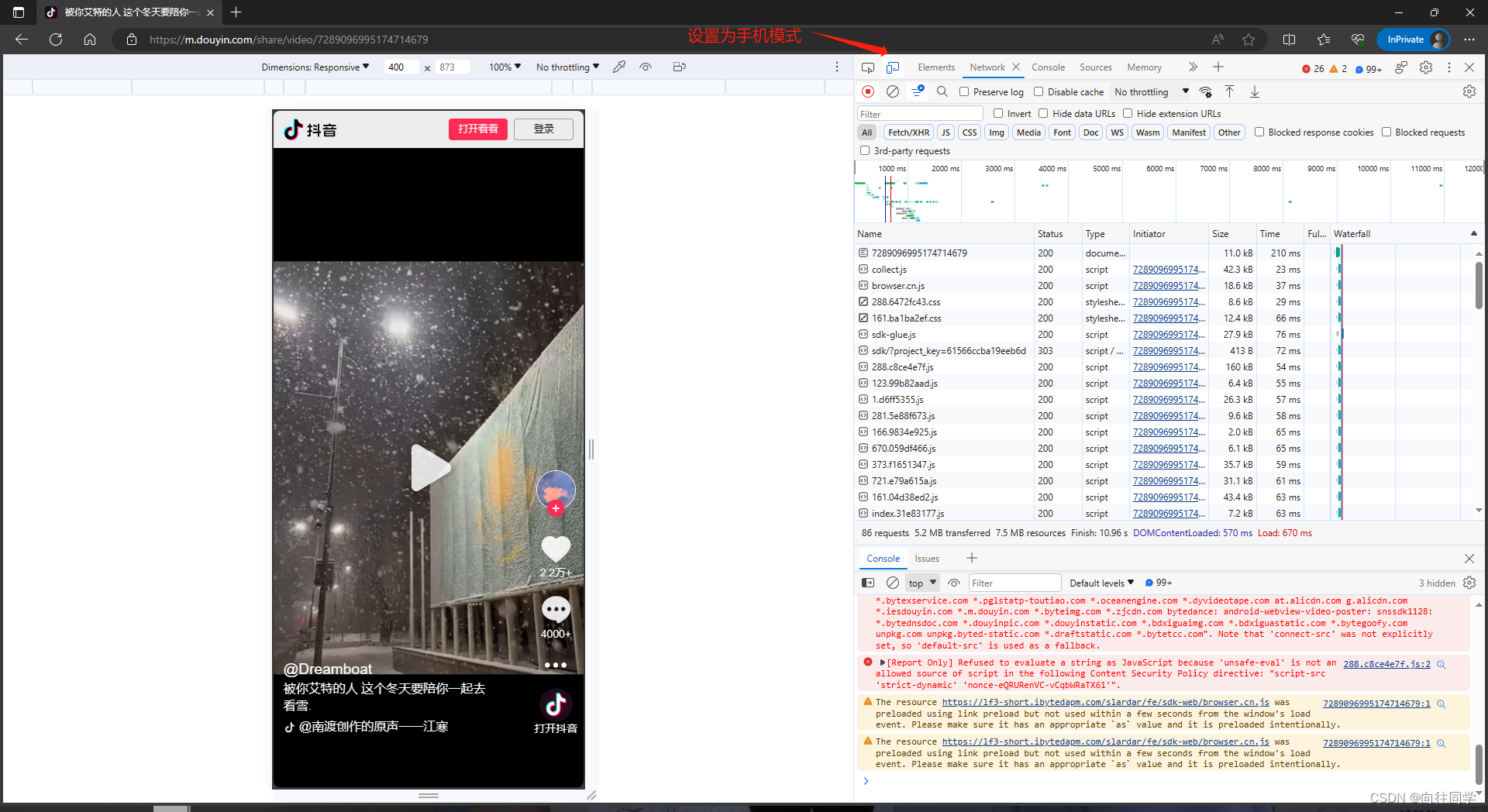
7、分析得到如下图的包名:我们可以看到这个包返回的json参数里也有我们刚刚pc端uri:"v0200fg10000ckk161rc77ua9mpnl2i0"这个参数

8、分析获取这个包的链接:https://m.douyin.com/web/api/v2/aweme/iteminfo/?reflow_source=reflow_page&item_ids=7289096995174714679&msToken=anBTIc1cLIN1y4SA9gFLfdlPmHPukK-0pgTfdWQcQI0YENGgCxPNI9h5kTCiOV__hFzHETwpa6lLL8t6p69LE64ZNp26-n-oK1gdxHeZ6zejX0gTQ3BWDbNSgUwNww%3D%3D&a_bogus=mvUYkcZCMsR10D3CMhkz9nTm5fD0YW4dgZEzPD6XQ0LR可以看到这个链接比pc端的链接短了很多,最后分析得出删掉&msToken后面的链接:https://m.douyin.com/web/api/v2/aweme/iteminfo/?reflow_source=reflow_page&item_ids=7289096995174714679也能获取相应的json,这个item_ids可以看出是分享链接重定向之后video/后面的字段https://m.douyin.com/share/video/7289096995174714679
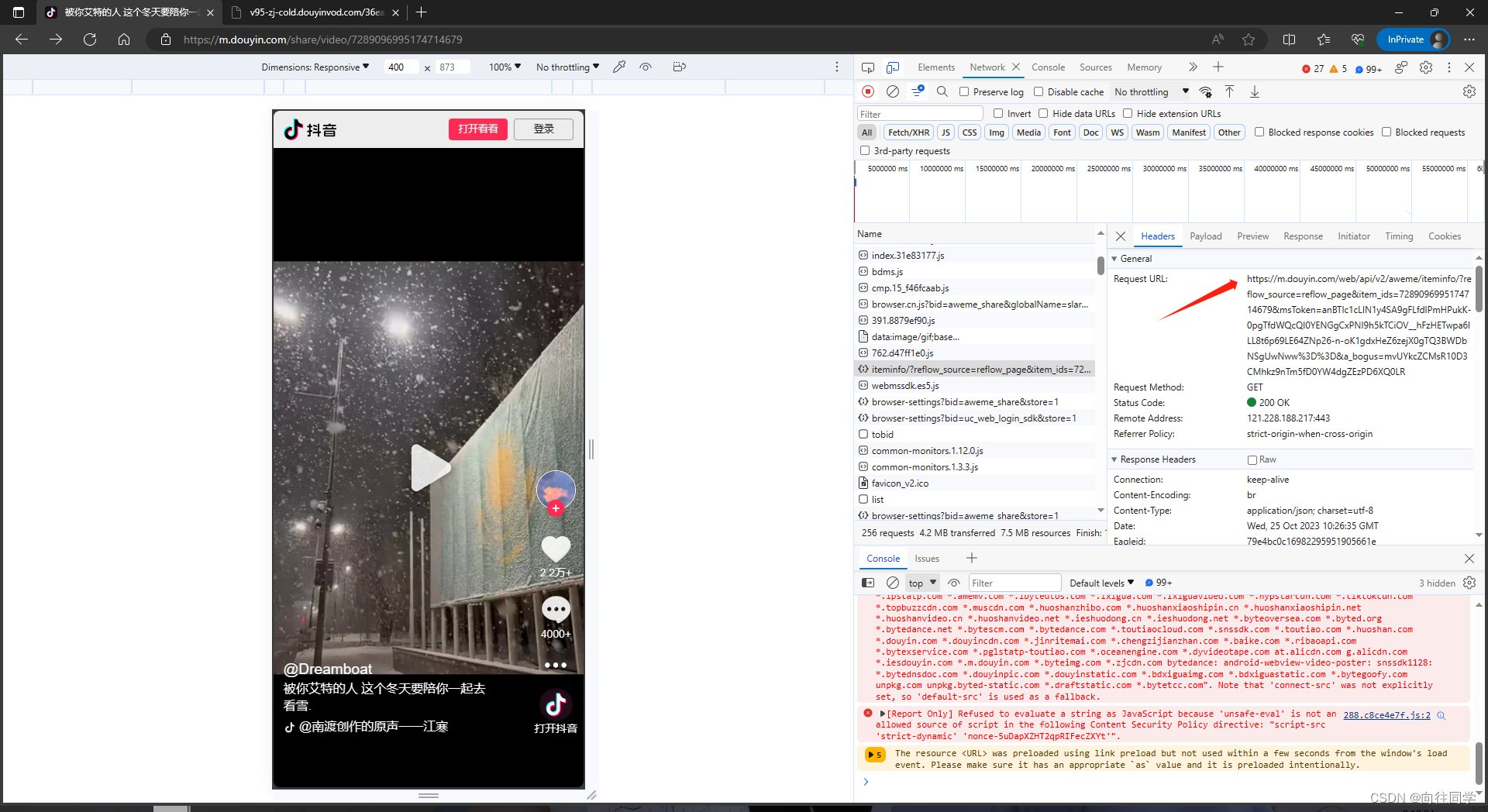
9、分析到这我们就可以完成上述的代码了
import re
import requests
import os
# 请求头
header = {
"User-Agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Mobile Safari/537.36"}
# 视频无水印
def videos(surl):
print('正在解析视频链接')
# 获取video_id (重定向后的链接会变化具体我也没弄清楚就做了两种判断)
if len(surl) > 60:
id = re.search(r'video/(\d.*)/', surl).group(1)
else:
id = re.search(r'video/(\d.*)', surl).group(1)
# print(id)
# 获取json数据
u_id = "https://m.douyin.com/web/api/v2/aweme/iteminfo/?item_ids={}&a_bogus=".format(id)
v_rs = requests.get(url=u_id, headers=header).json()
# titles = v_rs['item_list'][0]['desc']
# 截取文案
titles = re.search(r'^(.*?)[;;。.#]', v_rs['item_list'][0]['desc']).group(1)
# print(titles)
# 创建video文件夹
if not os.path.exists('video'):
os.makedirs('video')
# 获取uri参数
req = v_rs['item_list'][0]['video']['play_addr']['uri']
# print("vvvvvv", req)
print('正在下载无水印视频')
# 下载无水印视频
v_url = "https://www.douyin.com/aweme/v1/play/?video_id={}".format(req)
v_req = requests.get(url=v_url, headers=header).content
# 写入文件
with open(f'video/{titles}.mp4', 'wb') as f:
f.write(v_req)
if __name__ == '__main__':
# 抖音
shares = input("请输入分享链接并按下回车键:")
# 提取分享链接后面的链接
share = re.search(r'/v.douyin.com/(.*?)/', shares).group(1)
# 请求链接
share_url = "https://v.douyin.com/{}/".format(share)
# print(share_url)
s_html = requests.get(url=share_url, headers=header)
# 获取重定向后的视频id
surl = s_html.url
# print(surl)
# 判断链接类型为视频分享类型
if re.search(r'/video', surl) != None:
videos(surl)
quit = input('下载完成,按回车键退出程序。')
# 判断链接类型为图集分享类型
elif re.search(r'/note', surl) != None:
pics(surl)
quit = input('下载完成,按回车键退出程序。')
else:
quit = input('解析失败,按回车键退出程序。')二、图集分析
1、获取图集分享链接:0.07 yTy:/ 03/13 [email protected] 复制打开抖音,看看【生活随拍 可能有关】# 文案 # 朋友圈文案 # 图文掘金计划 发朋友圈会被秒赞的高级文案.# 文案 # 朋友圈文案# ... https://v.douyin.com/idpAF4rh/根据视频的经验我们直接打开手机版的控制台抓包,找到了一个和视频一样的包名打开获取后的json得到images下的五张原图片的链接
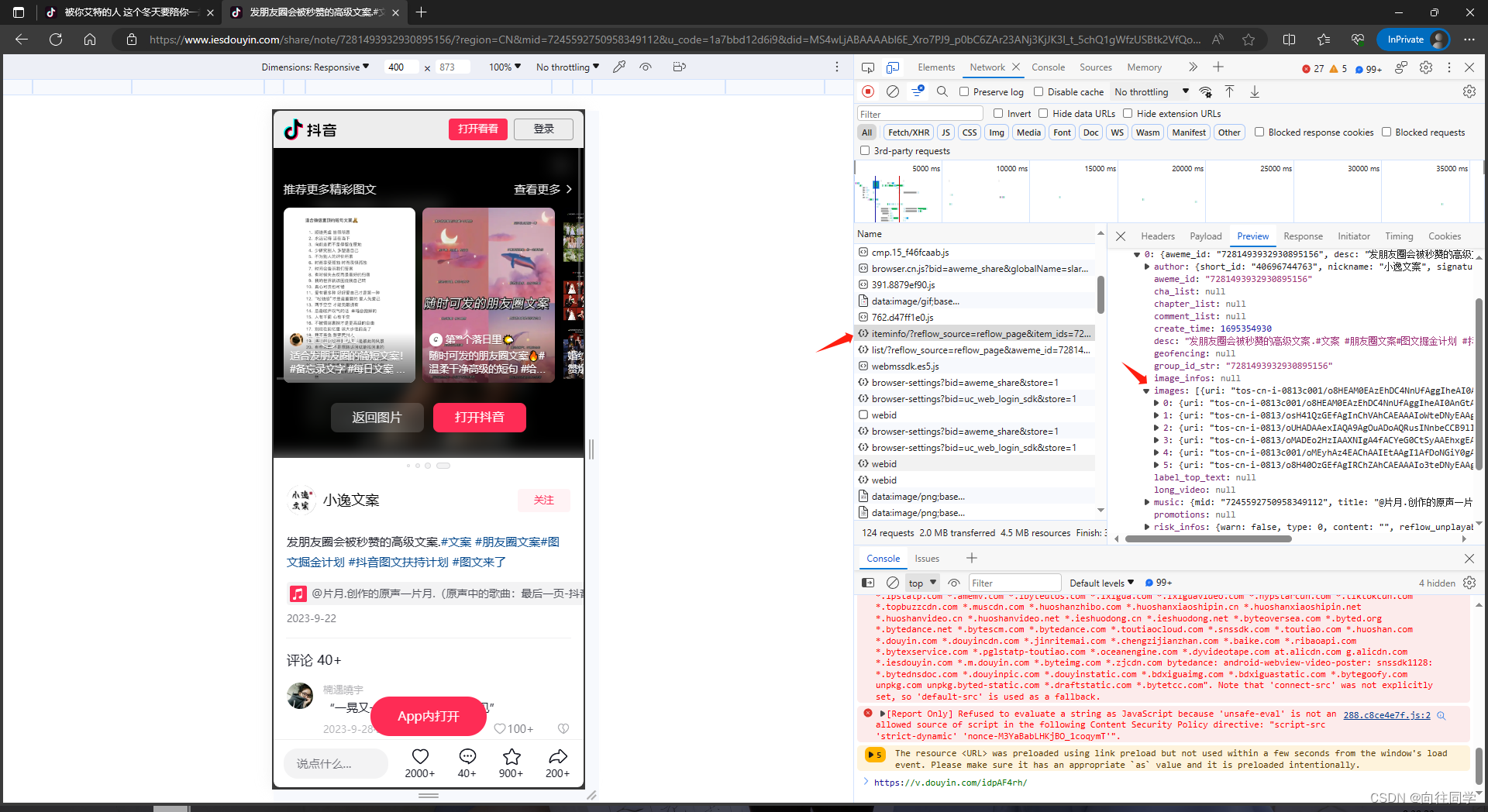
2、分析获取这个包的链接:https://www.iesdouyin.com/web/api/v2/aweme/iteminfo/?reflow_source=reflow_page&item_ids=7281493932930895156&a_bogus=DyMOgOZJMsR1Xj3Cdwkz9Htm54W0YW40gZEzYr%2FdMtL9删掉多余的参数得到:https://www.iesdouyin.com/web/api/v2/aweme/iteminfo/?reflow_source=reflow_page&item_ids=7281493932930895156&a_bogus=
这个链接其中item_ids和视频也是一样是分享链接重定向之后的id
3、完成上述代码
# 图片无水印
def pics(surl):
print('正在解析图片链接')
# 获取id
if len(surl) > 60:
pid = re.search(r'note/(\d.*)/', surl).group(1)
else:
pid = re.search(r'note/(\d.*)', surl).group(1)
# 获取json数据
p_id = "https://m.douyin.com/web/api/v2/aweme/iteminfo/?reflow_source=reflow_page&item_ids={}&a_bogus=".format(pid)
# print(p_id)
p_rs = requests.get(url=p_id, headers=header).json()
# print(p_rs)
# 拿到images下的原图片
images = p_rs['item_list'][0]['images']
# 获取文案
ptitle = re.search(r'^(.*?)[;;。.#]', p_rs['item_list'][0]['desc']).group(1)
# 创建pic文件夹
if not os.path.exists('pic'):
os.makedirs('pic')
if not os.path.exists(f'pic/{ptitle}'):
os.makedirs(f'pic/{ptitle}')
print('正在下载无水印图片')
# 下载无水印照片(遍历images下的数据)
for i, im in enumerate(images):
# 每一条数据下面都有四个原图链接这边用的是第一个
p_req = requests.get(url=im['url_list'][0]).content
# print(p_req)
# 保存图片
with open(f'pic/{ptitle}/{str(i + 1)}.jpg', 'wb') as f:
f.write(p_req)三、完整代码
import re
import requests
import os
# 请求头
header = {
"User-Agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Mobile Safari/537.36"}
# 视频无水印
def videos(surl):
print('正在解析视频链接')
# 获取video_id (重定向后的链接会变化具体我也没弄清楚就做了两种判断)
if len(surl) > 60:
id = re.search(r'video/(\d.*)/', surl).group(1)
else:
id = re.search(r'video/(\d.*)', surl).group(1)
# print(id)
# 获取json数据
u_id = "https://m.douyin.com/web/api/v2/aweme/iteminfo/?item_ids={}&a_bogus=".format(id)
v_rs = requests.get(url=u_id, headers=header).json()
# titles = v_rs['item_list'][0]['desc']
# 截取文案
titles = re.search(r'^(.*?)[;;。.#]', v_rs['item_list'][0]['desc']).group(1)
# print(titles)
# 创建video文件夹
if not os.path.exists('video'):
os.makedirs('video')
# 获取uri参数
req = v_rs['item_list'][0]['video']['play_addr']['uri']
# print("vvvvvv", req)
print('正在下载无水印视频')
# 下载无水印视频
v_url = "https://www.douyin.com/aweme/v1/play/?video_id={}".format(req)
v_req = requests.get(url=v_url, headers=header).content
# 写入文件
with open(f'video/{titles}.mp4', 'wb') as f:
f.write(v_req)
# 图片无水印
def pics(surl):
print('正在解析图片链接')
# 获取id
if len(surl) > 60:
pid = re.search(r'note/(\d.*)/', surl).group(1)
else:
pid = re.search(r'note/(\d.*)', surl).group(1)
# 获取json数据
p_id = "https://m.douyin.com/web/api/v2/aweme/iteminfo/?reflow_source=reflow_page&item_ids={}&a_bogus=".format(pid)
# print(p_id)
p_rs = requests.get(url=p_id, headers=header).json()
# print(p_rs)
# 拿到images下的原图片
images = p_rs['item_list'][0]['images']
# 获取文案
ptitle = re.search(r'^(.*?)[;;。.#]', p_rs['item_list'][0]['desc']).group(1)
# 创建pic文件夹
if not os.path.exists('pic'):
os.makedirs('pic')
if not os.path.exists(f'pic/{ptitle}'):
os.makedirs(f'pic/{ptitle}')
print('正在下载无水印图片')
# 下载无水印照片(遍历images下的数据)
for i, im in enumerate(images):
# 每一条数据下面都有四个原图链接这边用的是第一个
p_req = requests.get(url=im['url_list'][0]).content
# print(p_req)
# 保存图片
with open(f'pic/{ptitle}/{str(i + 1)}.jpg', 'wb') as f:
f.write(p_req)
if __name__ == '__main__':
# 抖音
shares = input("请输入分享链接并按下回车键:")
# 提取分享链接后面的链接
share = re.search(r'/v.douyin.com/(.*?)/', shares).group(1)
# 请求链接
share_url = "https://v.douyin.com/{}/".format(share)
# print(share_url)
s_html = requests.get(url=share_url, headers=header)
# 获取重定向后的视频id
surl = s_html.url
# print(surl)
# 判断链接类型为视频分享类型
if re.search(r'/video', surl) != None:
videos(surl)
quit = input('下载完成,按回车键退出程序。')
# 判断链接类型为图集分享类型
elif re.search(r'/note', surl) != None:
pics(surl)
quit = input('下载完成,按回车键退出程序。')
else:
quit = input('解析失败,按回车键退出程序。')
四、总结
这个是我的个人分析思路希望各位大佬能给出宝贵意见或者新思路,第一次发帖感谢各位支持