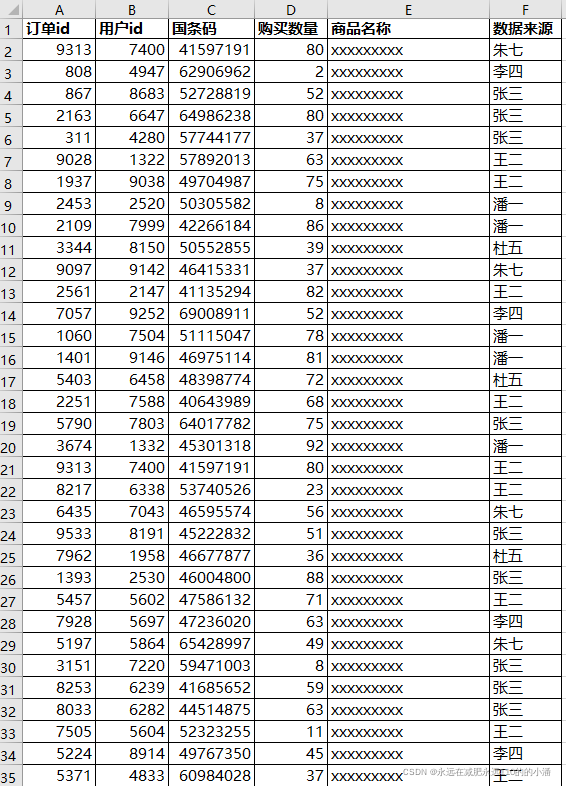
现在有一份订单源数据,是从各位业务人员处搜集整合而来。由于有的业务人员给的订单数据会出现重合的部分,需要将该部分的重复记录在源数据中标记出来,由业务人员确认后,删除该部分的重复记录,以得到最终准确的订单源数据用于后续的订单统计。
源数据样例如下,其中订单id、用户id、国条码、购买数量四个组合字段可作为一行记录的唯一标识。
第一步:读取数据
import pandas as pd
file_path=r"E:\临时\20220214\临时.xlsx"
data=pd.read_excel(file_path)
data.head()
第二步:查看重复记录行数
data.duplicated(subset=["订单id","用户id","国条码","购买数量"],keep="first").sum()#计算重复记录行数,其中第一次出现的重复记录不纳入计数
输出:96
data.duplicated(subset=["订单id","用户id","国条码","购买数量"],keep="last").sum()#计算重复记录行数,其中最后一次出现的重复记录不纳入计数
输出:96
data.duplicated(subset=["订单id","用户id","国条码","购买数量"],keep=False).sum()##计算重复记录行数,只要记录重复出现,就会被计入
输出:121
综上,我们可以得到的是一共(121-96=25条)记录重复出现了121次。这25条记录至少都重复出现了一次,部分记录重复出现了两次或以上。
第三步:标记重复记录
data.loc[data.duplicated(subset=["订单id","用户id","国条码","购买数量"],keep=False),"该行是否重复"]="是"#将重复出现的121条记录打上标记
第四步:标记需要剔除的重复记录
data.loc[data.duplicated(subset=["订单id","用户id","国条码","购买数量"],keep="first"),"该重复项是否应被剔除"]="是"#若某记录多次出现,第一次出现的记录保留,之后出现的记录剔除
第五步:与业务人员确认后删除重复记录
法一:
data_drop_dup=data.drop_duplicates(subset=["订单id","用户id","国条码","购买数量"],keep="first")
法二:
data_drop_dup=data[data["该重复项是否应被剔除"]!="是"]