线程池的原理与实现
线程池简介
1.线程池
1.线程池
一种管理维持固定线程数量的池式结构。
2.数量固定的原因
- 避免频繁的创建和销毁线程,造成资源浪费
- 随着线程的数量不断增多,并不能实现性能的提升,相反可能造成系统负担
3.线程数量如何确定
- CPU密集型:proc(CPU核心数)
- IO密集型(网络IO,磁盘IO):2 * proc(CPU核心数)
4.为什么需要线程池
某类任务执行特别耗时,造成阻塞,严重影响该线程执行其他任务
作用:
- 复用线程资源;
- 减少线程创建和销毁的开销;
- 可异步处理生产者线程的任务;
- 减少了多个任务(不是一个任务)的执行时间;
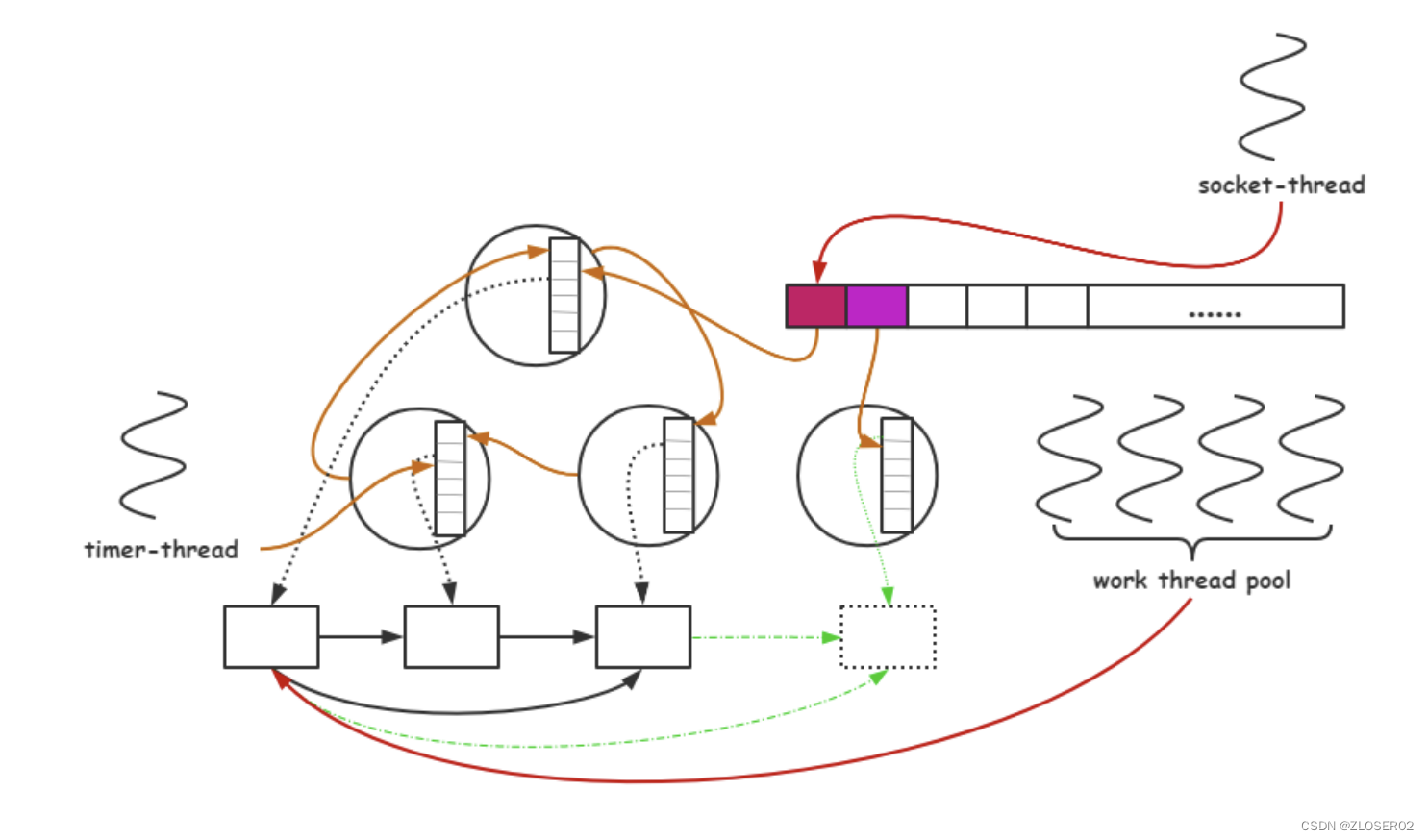
5.线程池结构
线程池属于一种生产消费模型。
线程池运行环境构成:
生产者线程:发布任务
队列:存储任务,调度线程池
消费者线程:取出任务,执行任务
线程池的实现
数据结构设计
1.任务结构
typedef struct task_s {
void *next;
handler_pt func;
void *arg;
} task_t;
2.任务队列结构
typedef struct task_queue_s {
void *head;
void **tail;
int block;
spinlock_t lock;
pthread_mutex_t mutex;
pthread_cond_t cond;
} task_queue_t;
3.线程池结构
struct thrdpool_s {
task_queue_t *task_queue;
atomic_int quit;
int thrd_count;
pthread_t *threads;
};
接口设计
// 创建对象的时候,回滚式的
static task_queue_t *
__taskqueue_create() {
task_queue_t *queue = (task_queue_t *)malloc(sizeof(*queue));
if (!queue) return NULL;
int ret;
ret = pthread_mutex_init(&queue->mutex, NULL);
if (ret == 0) {
ret = pthread_cond_init(&queue->cond, NULL);
if (ret == 0) {
spinlock_init(&queue->lock);
queue->head = NULL;
queue->tail = &queue->head;
queue->block = 1;
return queue;
}
pthread_cond_destroy(&queue->cond);
}
pthread_mutex_destroy(&queue->mutex);
return NULL;
}
static void
__nonblock(task_queue_t *queue) {
pthread_mutex_lock(&queue->mutex);
queue->block = 0;
pthread_mutex_unlock(&queue->mutex);
pthread_cond_broadcast(&queue->cond);
}
static inline void
__add_task(task_queue_t *queue, void *task) {
void **link = (void **)task; // malloc
*link = NULL; // task->next = NULL;
spinlock_lock(&queue->lock);
*queue->tail = link;
queue->tail = link;
spinlock_unlock(&queue->lock);
pthread_cond_signal(&queue->cond);
}
static inline void *
__pop_task(task_queue_t *queue) {
spinlock_lock(&queue->lock);
if (queue->head == NULL) {
spinlock_unlock(&queue->lock);
return NULL;
}
task_t *task;
task = queue->head;
queue->head = task->next;
if (queue->head == NULL) {
queue->tail = &queue->head;
}
spinlock_unlock(&queue->lock);
return task;
}
static inline void *
__get_task(task_queue_t *queue) {
task_t *task;
// 虚假唤醒
while ((task = __pop_task(queue)) == NULL) {
pthread_mutex_lock(&queue->mutex);
if (queue->block == 0) {
// break;
pthread_mutex_unlock(&queue->mutex);
return NULL;
}
// 1. 先 unlock(&mtx);
// 2. 在 cond 休眠
// ----- 生产者产生任务 signal
// 3. 在 cond 唤醒
// 4. 加上 lock(&mtx);
pthread_cond_wait(&queue->cond, &queue->mutex);
pthread_mutex_unlock(&queue->mutex);
}
return task;
}
static void
__taskqueue_destroy(task_queue_t *queue) {
task_t *task;
while ((task = __pop_task(queue))) { // 任务的生命周期由 thrdpool 管理
free(task);
}
spinlock_destroy(&queue->lock);
pthread_cond_destroy(&queue->cond);
pthread_mutex_destroy(&queue->mutex);
free(queue);
}
static void *
__thrdpool_worker(void *arg) {
thrdpool_t *pool = (thrdpool_t*) arg;
task_t *task;
void *ctx;
while (atomic_load(&pool->quit) == 0) {
task = (task_t*)__get_task(pool->task_queue);
if (!task) break;
handler_pt func = task->func;
ctx = task->arg;
free(task);
func(ctx);
}
return NULL;
}
static void
__threads_terminate(thrdpool_t * pool) {
atomic_store(&pool->quit, 1);
__nonblock(pool->task_queue);
int i;
for (i=0; i<pool->thrd_count; i++) {
pthread_join(pool->threads[i], NULL);
}
}
static int
__threads_create(thrdpool_t *pool, size_t thrd_count) {
pthread_attr_t attr;
int ret;
ret = pthread_attr_init(&attr);
if (ret == 0) {
pool->threads = (pthread_t *)malloc(sizeof(pthread_t) * thrd_count);
if (pool->threads) {
int i = 0;
for (; i < thrd_count; i++) {
if (pthread_create(&pool->threads[i], &attr, __thrdpool_worker, pool) != 0) {
break;
}
}
pool->thrd_count = i;
pthread_attr_destroy(&attr);
if (i == thrd_count)
return 0;
__threads_terminate(pool);
free(pool->threads);
}
ret = -1;
}
return ret;
}
void
thrdpool_terminate(thrdpool_t * pool) {
atomic_store(&pool->quit, 1);
__nonblock(pool->task_queue);
}
thrdpool_t *
thrdpool_create(int thrd_count) {
thrdpool_t *pool;
pool = (thrdpool_t*) malloc(sizeof(*pool));
if (!pool) return NULL;
task_queue_t *queue = __taskqueue_create();
if (queue) {
pool->task_queue = queue;
atomic_init(&pool->quit, 0);
if (__threads_create(pool, thrd_count) == 0) {
return pool;
}
__taskqueue_destroy(pool->task_queue);
}
free(pool);
return NULL;
}
int
thrdpool_post(thrdpool_t *pool, handler_pt func, void *arg) {
if (atomic_load(&pool->quit) == 1) {
return -1;
}
task_t *task = (task_t *)malloc(sizeof(task_t));
if (!task) return -1;
task->func = func;
task->arg = arg;
__add_task(pool->task_queue, task);
return 0;
}
void
thrdpool_waitdone(thrdpool_t *pool) {
int i;
for (i=0; i<pool->thrd_count; i++) {
pthread_join(pool->threads[i], NULL);
}
__taskqueue_destroy(pool->task_queue);
free(pool->threads);
free(pool);
}
线程池的应用
reactor
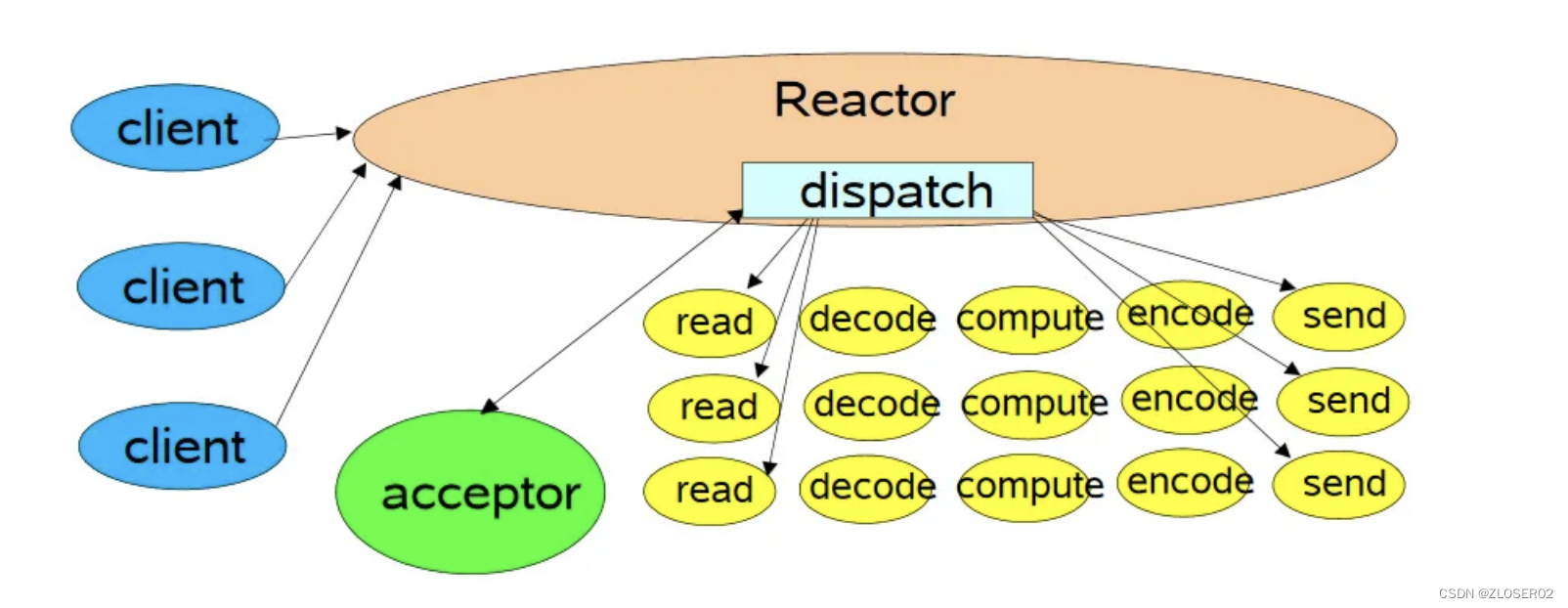
在一个事件循环中,可以处理多个就绪事件,这些就绪事件在reactor 模型中时串行执行的,一个事件处理若耗时较长,会延迟其他同时触发的事件的处理(对于客户端而言,响应会变得较慢)。
redis 中线程池
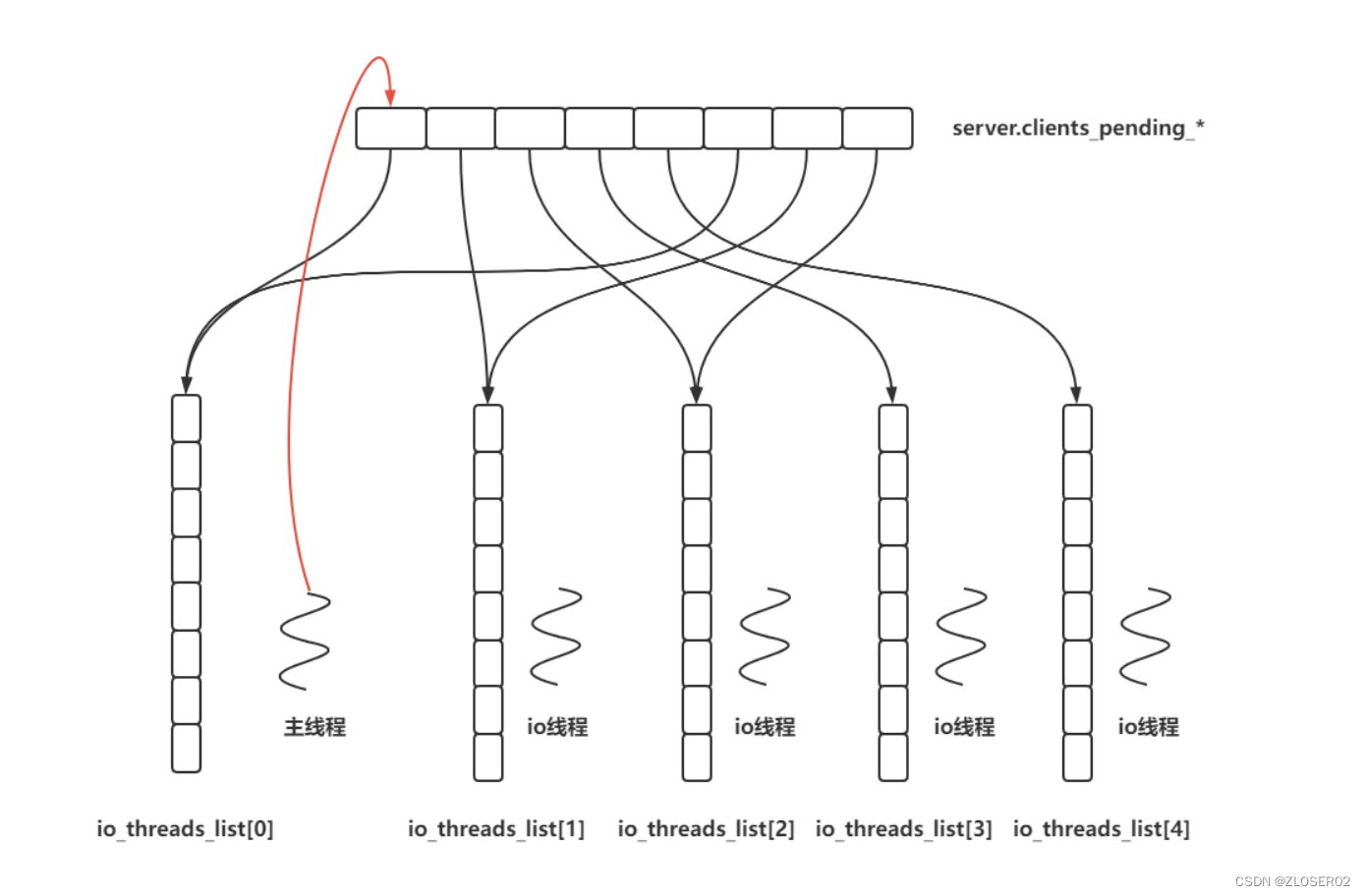
作用:读写 io 处理以及数据包解析、压缩;
skynet 中线程池