
文章链接:https://arxiv.org/abs/2309.04354
最近,专家混合模型MoE受到了学术界和工业界的广泛关注,其能够对任意输入来激活模型参数中的一小部分来将模型大小与推理效率分离,从而实现模型的轻量化设计。目前MoE已经在自然语言处理和计算机视觉进行了广泛的应用,本文介绍一篇来自Apple的最新工作,在这项工作中,苹果转而探索使用稀疏的MoE来缩小视觉Transformer模型(ViT)的参数规模,使其能够在移动端的推理芯片上更加流畅的运行。为此,本文提出了一种简化且适合移动设备的Mobile V-MoEs模型,将整个图像而不是单个patch路由输入给专家,并且提出了一种更加稳定的MoE训练范式,该范式可以使用超类信息来指导路由过程。作者团队通过大量的实验表明,与对应的密集ViT相比,本文提出的Mobile V-MoE可以在性能和效率之间实现更好的权衡,例如,对于 ViT-Tiny模型,Mobile V-MoE在ImageNet-1k上的性能比其密集模型提高了3.39%。对于推理成本仅为54M FLOPs的更小的ViT版本,本文方法实现了4.66%的改进。
01. 引言
稀疏专家混合模型是一种可以将模型大小与推理效率解耦的神经网络加速手段,直观上理解,MoEs[1]是一种可以被划分为多个“专家”模块的神经网络,“专家”模块与一个路由模块联合训练,在MoEs中,每个输入仅由一小部分模型参数处理(又称条件计算)。相比之下,普通的密集模型则会激活每个与输入有关的参数,如下图所示(b)(c)所示,MoE首先使用路由模块从输入图像中选取一些patch,然后再将这些patch送入到专家模块中进行计算。
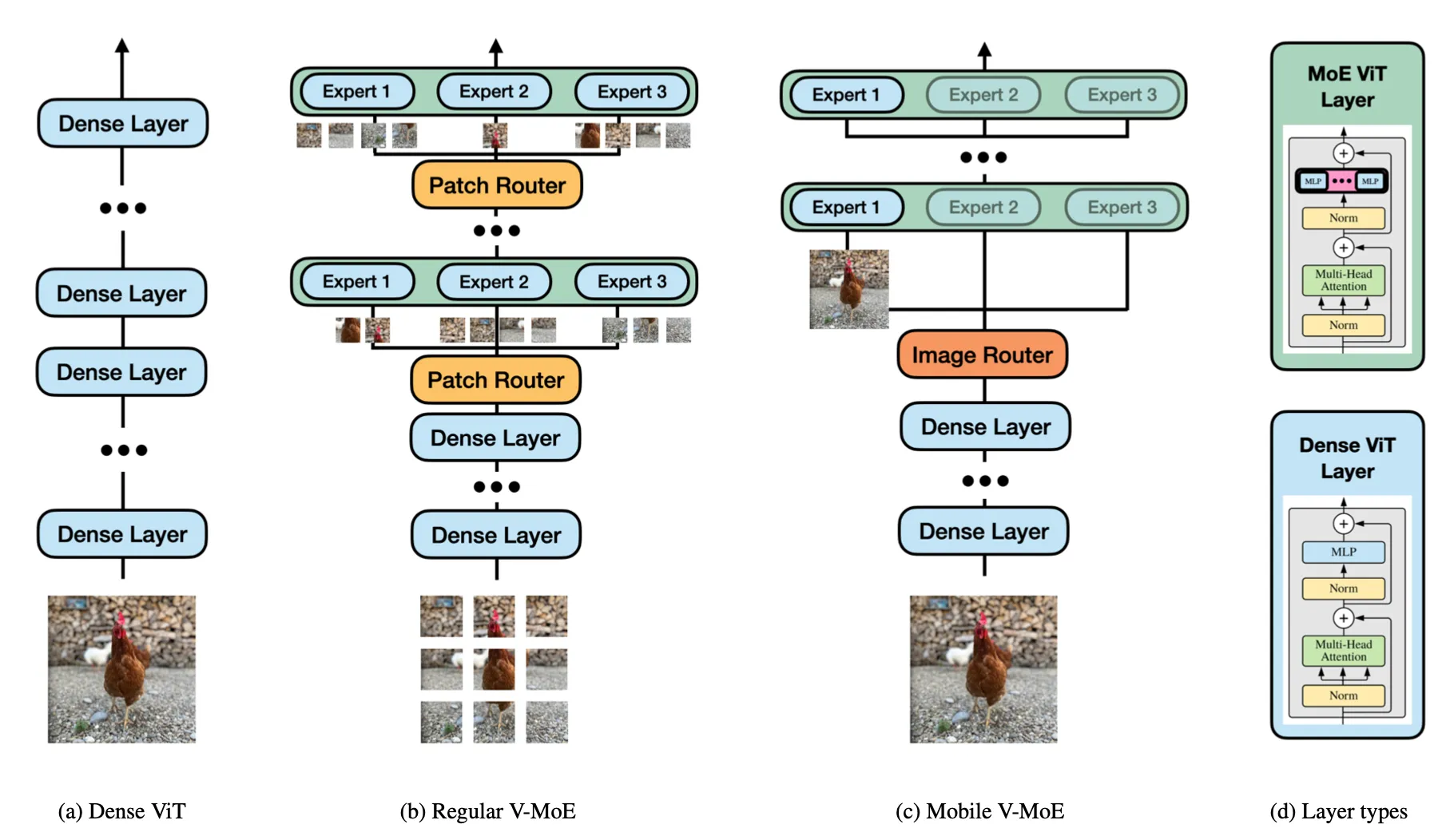
虽然目前在CV领域,Transformer架构代替CNN架构已经成为一种趋势,但是现有基于ViT架构的MoEs方法仍然无法像卷积结构一样很好的在移动端进行部署,因此,本文作者想使用条件计算来将注意力头的计算量进行缩减,此外提出了一种更加简化且更适合于移动设备的稀疏MoE设计,即首先使用路由模块将整个图像的表征(而不是图像块)直接分配给专家模块,作者还对这一结构设计了一套专门的训练范式,引入了语义超类的概念来指导路由器的训练来避免专家分配不平衡的问题。本文通过广泛的实验表明,所提出的稀疏MoE方法可以达到ViT模型性能与效率之间的全新平衡。
02. 本文方法
2.1 稀疏MoEs

2.2 适用于轻量级ViT的MoEs


03. 实验效果
本文的实验在ImageNet-1K数据集上进行,该数据集包含大约128万张训练图像,本文所有的对比方法和模型版本均在该训练集上从头端到端训练,然后在包含5万张图像的验证集上计算top-1识别准确率。
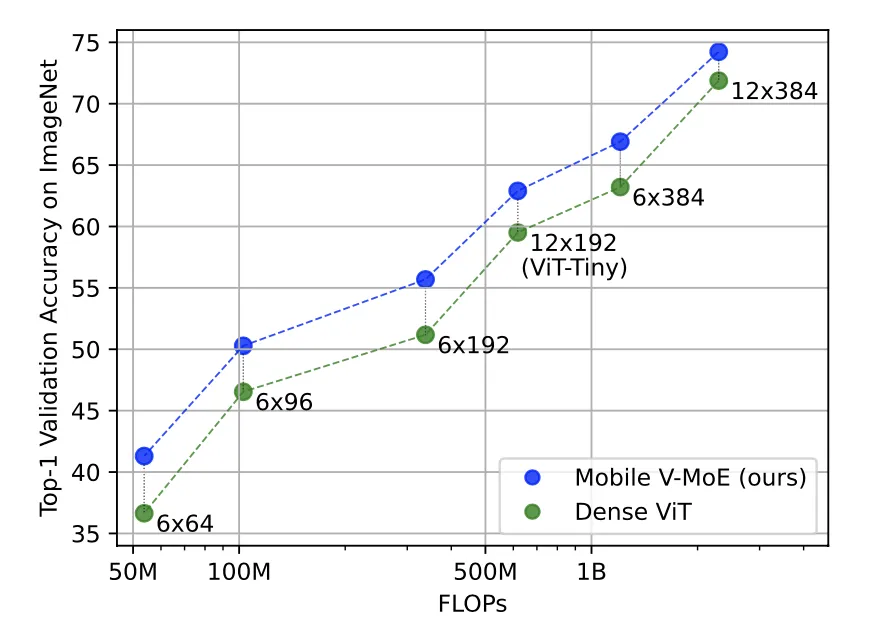
作者通过缩放Transformer总层数(12、9、6)和隐藏层特征维度(384、192、96和64)来控制Mobile V-MoEs与其对应的密集ViT的模型大小。上图展示了本文方法与其对应参数规模的ViT模型的识别准确率对比,可以看到本文提出的Mobile V-MoEs在所有的模型规模上都优于对应的ViT模型。从视觉ViT的基本范式出发,模型内部MLP的嵌入特征维度应是隐藏层特征维度的4倍。
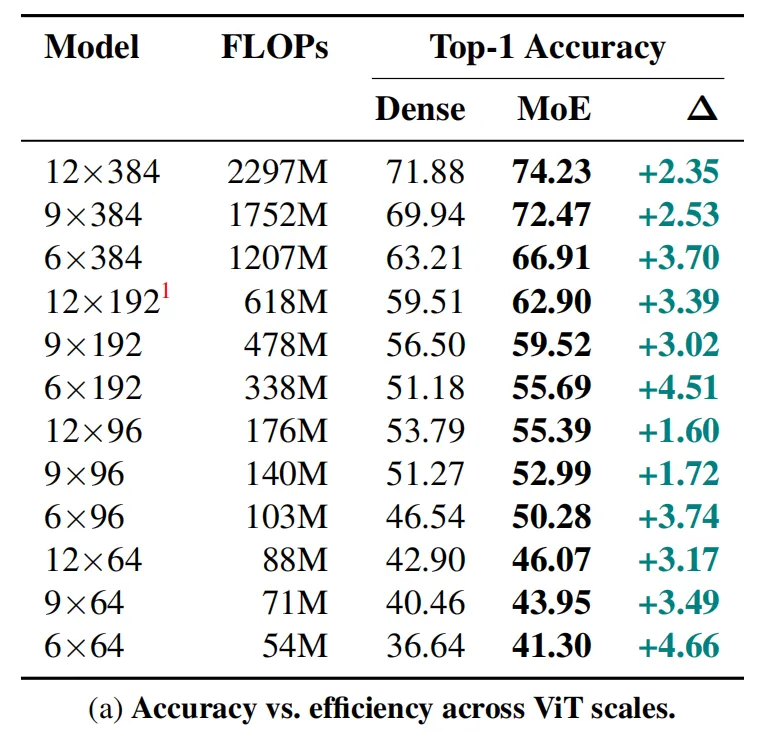
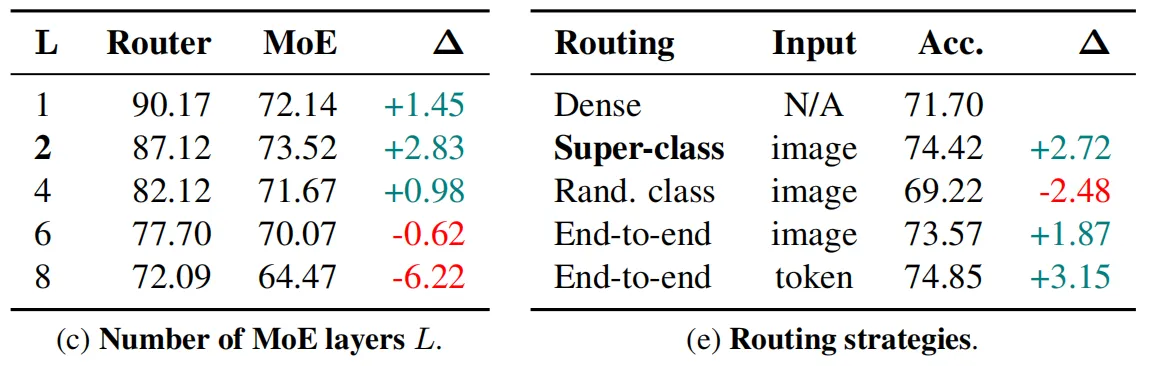
此外,本文涉及到的MoEs模型均由2个MoE-ViT层构成,在这些层的前面是不同数量级的密集ViT层,输入的patch大小为 32×32 。这样设置的目的是因为patch大小可以有效的控制FLOPs与模型参数数量之间的权衡,由于本文的目标是针对模型FLOPs进行优化,因此较大的patch大小使得我们可以更加专注于控制patch的计算效率,此外,作者还在 32×32的基础上尝试了更小的 16×16 尺寸,实验结果的趋势与大尺寸保持一致,上表展示了详细的实验效果。


04. 总结
目前,在深度学习模型落地部署领域,正在经历着从CNN向视觉ViT过度的大潮流,基于CNN的移动端轻量级网络(如MobileNet)也亟待升级。本文介绍了一种移动端ViT轻量化的最新技术,作者将稀疏MoEs迁移到视觉ViT模型架构中,与其对应的密集ViT相比,稀疏MoE可以实现高效的性能与效率权衡,这使得将更多类型的视觉ViT模型部署到移动端计算设备上成为可能。此外本文作者展望到,如果能将稀疏MoEs技术应用到CNN和视觉ViT结合的算法模型上,可能会得到更好的推理效果。
参考
[1] Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy
Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. arXiv preprint arXiv:1701.06538, 2017.
[2] Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, and Herv´e J´egou. Training data-efficient image transformers & distillation through attention. In International conference on machine learning, pages 10347–10357. PMLR, 2021.
关于TechBeat人工智能社区
▼
TechBeat(www.techbeat.net)隶属于将门创投,是一个荟聚全球华人AI精英的成长社区。
我们希望为AI人才打造更专业的服务和体验,加速并陪伴其学习成长。
期待这里可以成为你学习AI前沿知识的高地,分享自己最新工作的沃土,在AI进阶之路上的升级打怪的根据地!
更多详细介绍>>TechBeat,一个荟聚全球华人AI精英的学习成长社区