2023 年 MathorCup 高校数学建模挑战赛——大数据竞赛
赛道 B复赛:电商零售商家需求预测及库存优化问题
问题一
目标:制定补货计划,基于预测销量。
背景:固定库存盘点周期NRT=1, 提前期LT=3天。
初始条件:所有商品期初库存为5,持有成本及缺货成本与商品价格正相关。
策略:周期性盘点库存策略(s,S)。
数据处理:需结合历史及预测需求量。
任务:提供2023-05-16至2023-05-30期间的补货计划(每天的s和S值)。
目标指标:降低成本,提升服务水平,降低库存周转天数。
问题二
目标:撰写关于电商零售商家需求预测及库存优化问题的总结报告。
内容要求:报告中需要明确团队方案的优缺点。
附件说明
结果表4:库存补货结果表,包含商家编码、商品编码、仓库编码、日期、库存决策变量(s和S)、当天期初库存、当天期末库存、预测需求量和补货量等字段。
总结问题一团队认为可以采用的方法为:基于模拟退火求解规划问题;基于遗传算法求解规划问题;使用库存管理理论,如经济订货量(EOQ)模型;基于机器学习的预测模型;基于修正机器学习的预测模型
团队将选取至少3种方法分别进行求解。
mbd.pub/o/bread/mbd-ZZeckpxs
商品价格数据的Excel文件:
这个数据表包含了商品编号(product_no)和相应的价格(price)。
预测结果表,包含以下信息:
商家编号(seller_no)
商品编号(product_no)
仓库编号(warehouse_no)
日期范围(date),这里显示的是从2023-05-16至2023-05-30的日期范围
预测需求量(forecast_qty)
对原始数据做可视化:
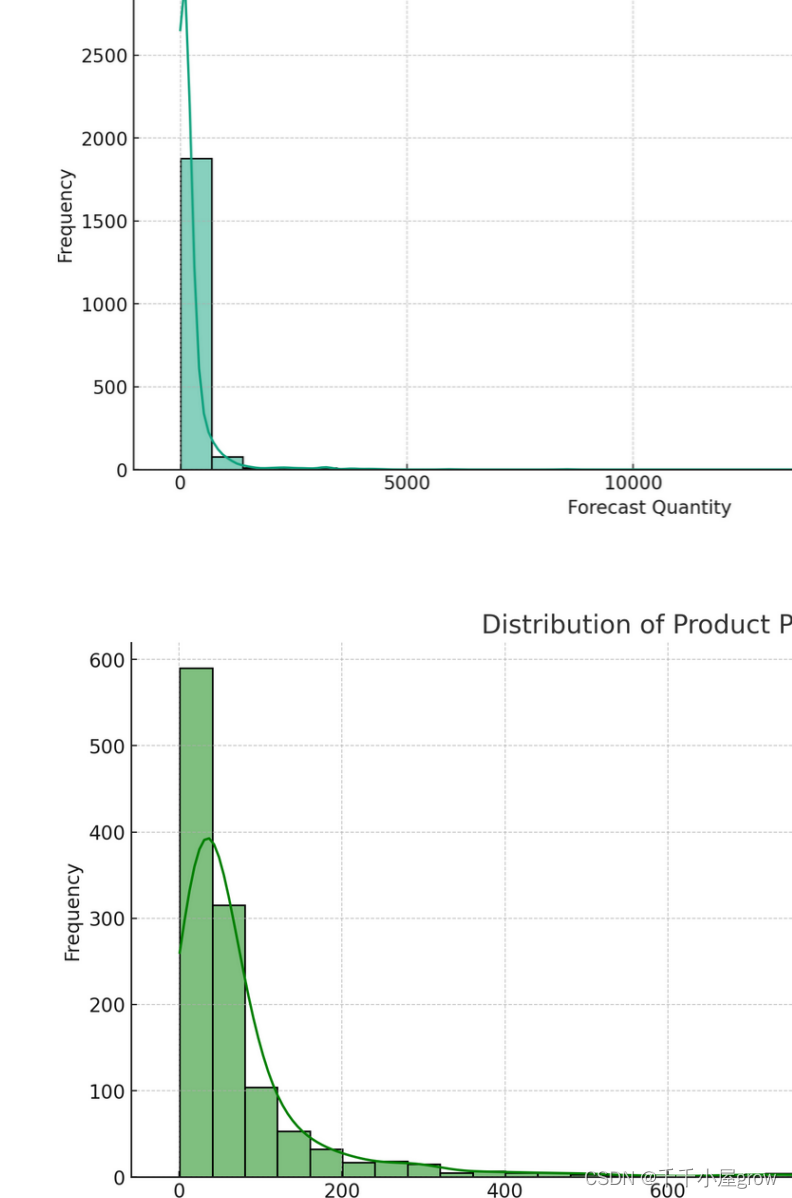
预测需求量的分布:这个图表显示了预测需求量的分布情况。可以看到需求量的分布范围和集中趋势。
商品价格的分布:这个图表显示了商品价格的分布情况。通过这个图表,我们可以了解商品价格的波动和集中趋势。
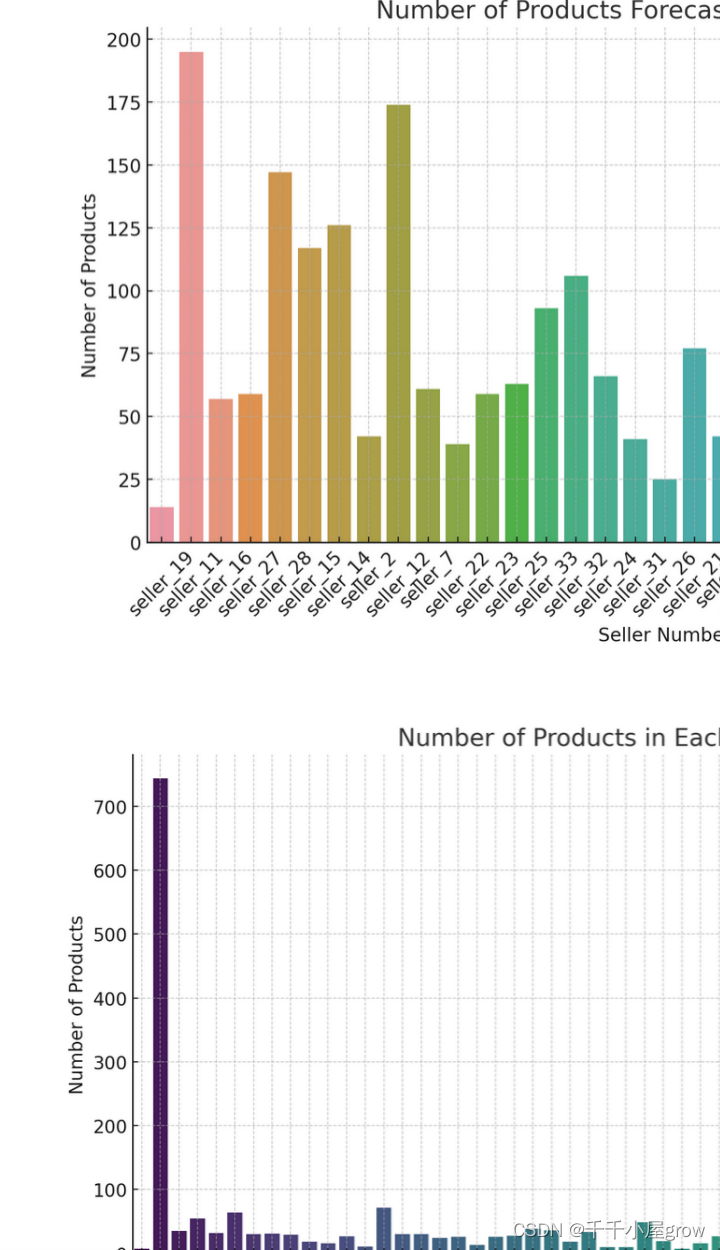
每个商家的预测产品数量:这个图表显示了各个商家的预测产品数量。这有助于了解哪些商家的产品数量较多,可能需要更多关注。
每个仓库的产品数量:这个图表展示了每个仓库中的产品数量。这有助于分析不同仓库的库存分布情况。
最常见的商品价格(前10名):这个图表显示了最常见的商品价格及其出现频率。这可以帮助我们理解价格分布的重点区域。
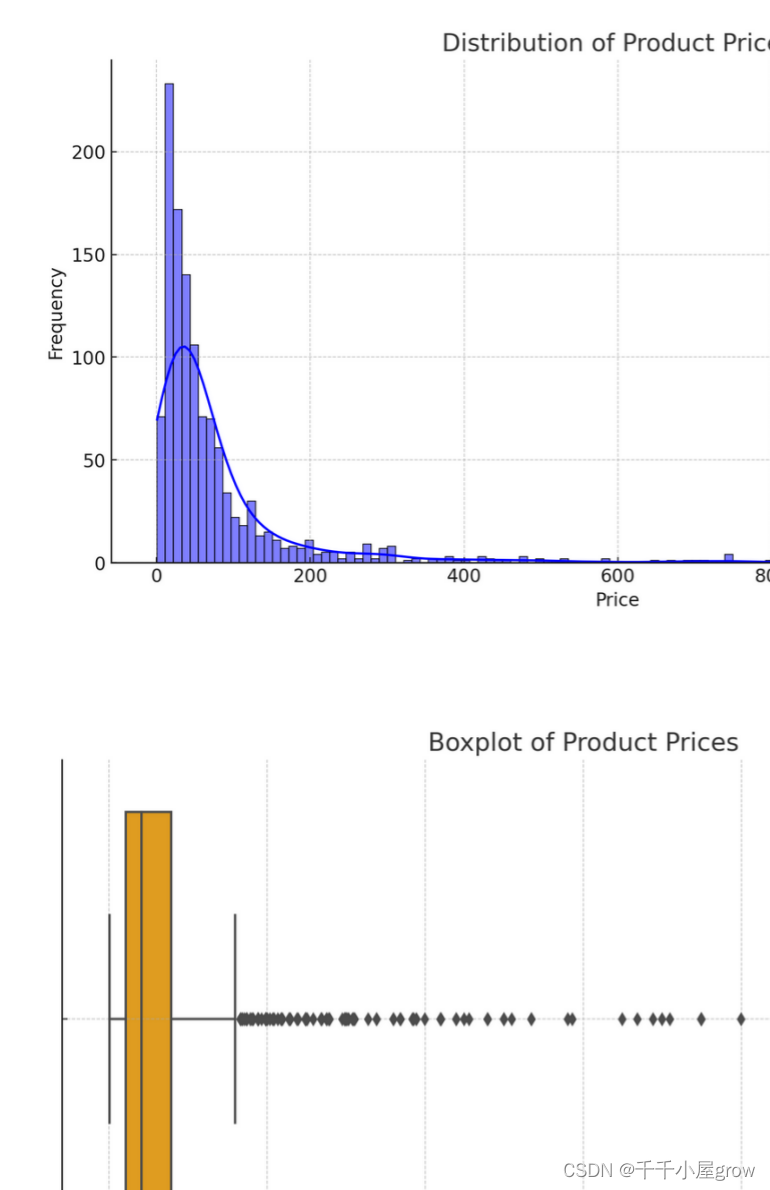
价格分布图:这个直方图显示了商品价格的分布情况,并包含一个核密度估计(KDE)曲线,可以帮助理解价格的总体分布趋势。
价格箱线图:这个箱线图提供了商品价格的五数概括(最小值、第一四分位数、中位数、第三四分位数、最大值),以及可能的异常值。
价格密度图:这个密度图展示了价格的概率密度分布,可以帮助更详细地了解价格分布的形状。
补货模型的构建步骤
- 数据整合
将商品价格数据与预测需求数据结合,以便在补货决策中考虑成本。 - 确定补货策略
我们将采用周期性盘点库存策略(s, S)。
根据商品的预测需求和价格确定每个商品的s和S值。 - 考虑库存成本
考虑持有成本(基于商品价格和库存水平)和缺货成本(当需求不能被满足时)。
目标是平衡成本和服务水平。 - 模型实现
使用Python来实现这个模型。
可以考虑使用库存管理理论,如经济订货量(EOQ)模型
或者基于机器学习的预测模型。
或者构建规划方程 - 模型测试与优化
测试模型在不同参数下的表现。
根据成本、库存水平和服务水平进行优化。 - 结果输出
输出2023-05-16至2023-05-30期间的补货计划
结合了预测需求数据和商品价格来计算每个商品的补货点(s值)和目标库存水平(S值)。这里,s和S的计算基于简单的假设
需要考虑了持有成本和缺货成本,这些成本根据商品价格和设定的比率计算得出。
下一步
参数调整:根据具体需求和成本考虑,调整s和S的计算方法。
模型验证:测试模型以确保其准确性和有效性。
优化策略:可能需要进一步优化策略,以更好地适应实际情况。
#初步代码
import pandas as pd
import numpy as np
File paths
forecast_results_file_path = ‘结果表1-预测结果表.xlsx’
product_price_file_path = ‘商品价格数据.xlsx’
Load the forecast results data
forecast_results_data = pd.read_excel(forecast_results_file_path)
Load the product price data
product_price_data = pd.read_excel(product_price_file_path)
Constants and assumptions
initial_inventory = 5 # Initial inventory level for all products
lead_time = 3 # Lead time in days
review_period = 1 # Review period in days
holding_cost_rate = 0.01 # Holding cost rate (percentage of product price)
shortage_cost_rate = 0.02 # Shortage cost rate (percentage of product price)
Merging forecast data with price data
merged_data = forecast_results_data.merge(product_price_data, on=‘product_no’, how=‘left’)
Function to calculate s and S values for each product
def calculate_replenish_points(row):
forecast_demand = row[‘forecast_qty’]
price = row[‘price’]
holding_cost_per_unit = price * holding_cost_rate
shortage_cost_per_unit = price * shortage_cost_rate
return s, S
Apply the function to each row in the dataframe
merged_data[[‘s’, ‘S’]] = merged_data.apply(lambda row: calculate_replenish_points(row), axis=1, result_type=“expand”)
Display the updated dataframe
merged_data.head()
初步预测结果对可视化
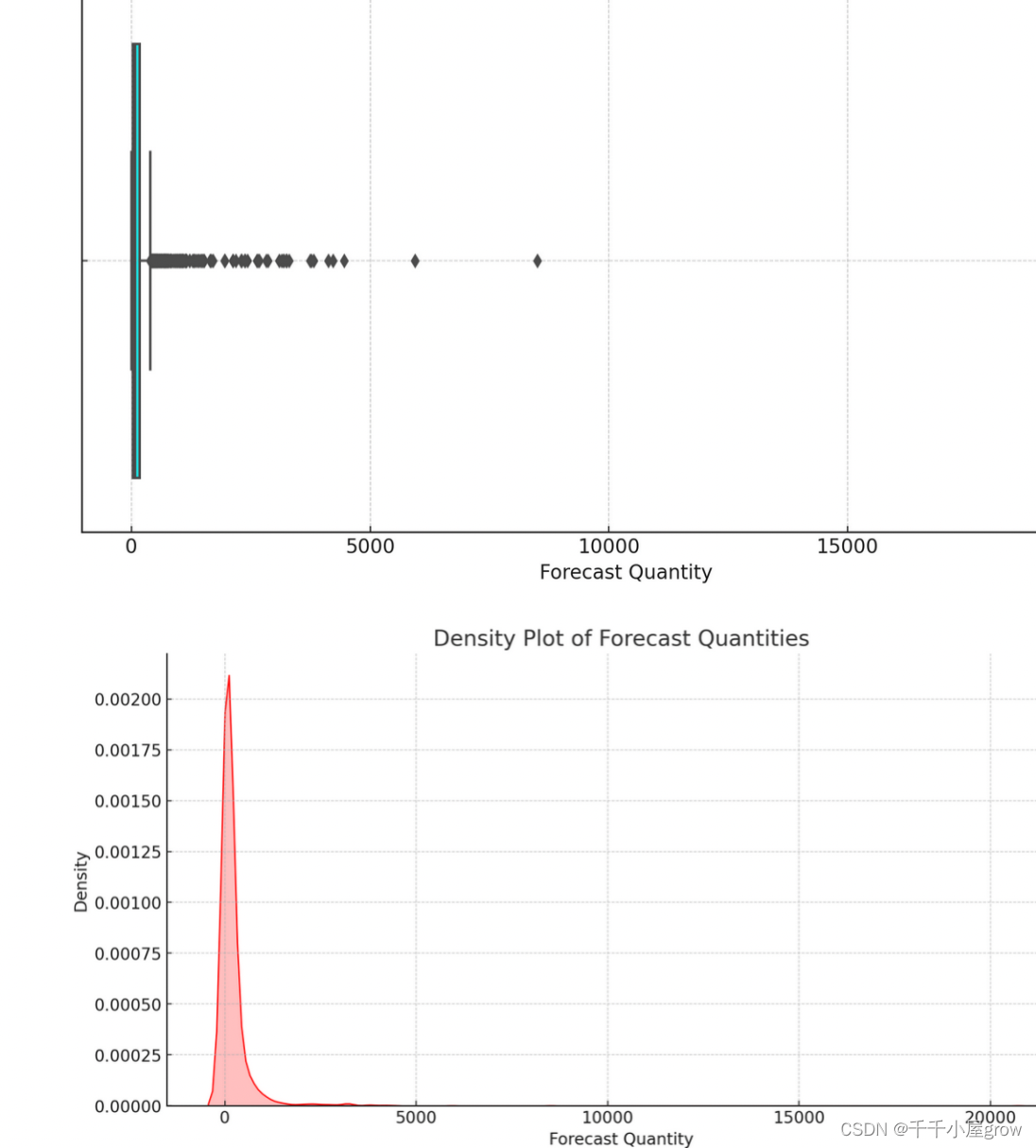
预测数量分布图:这个直方图展示了预测数量的分布情况,并包含一个核密度估计(KDE)曲线,有助于理解预测数量的总体分布趋势。
预测数量箱线图:这个箱线图提供了预测数量的五数概括(最小值、第一四分位数、中位数、第三四分位数、最大值),以及可能的异常值。
预测数量密度图:这个密度图显示了预测数量的概率密度分布,可以更详细地了解预测数量分布的形状。