halcon深度学习里,用到了很多封装好的函数,都很实用。如果要想更好的理解深度学习的过程。
我需要首先理解这些库函数,所以我今天开始再搞一个系列《halcon深度学习之那些封装好的库函数》
函数解析
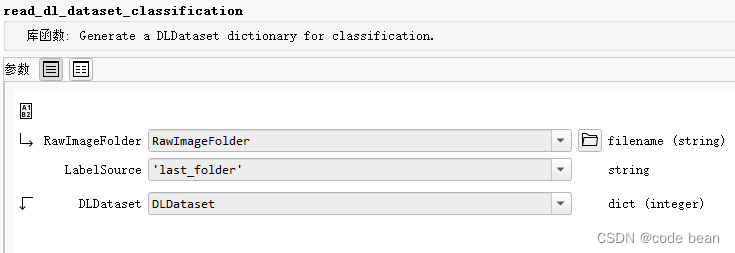
该read_dl_dataset_classification过程的目的是生成用于深度学习分类模型的DLDataset字典。以下是该过程的简要描述和参数说明:
简短描述:
read_dl_dataset_classification用于为基于深度学习的分类模型生成一个DLDataset字典。
签名:
read_dl_dataset_classification( : : RawImageFolder, LabelSource : DLDataset)
描述:
此过程用于生成一个DLDataset字典,该字典用于深度学习分类模型。
RawImageFolder是包含图像的文件夹的元组。这些文件夹及其子文件夹中的所有图像都将添加到DLDataset字典中。- 图像使用
list_image_files过程列出。请注意,子文件夹和链接也会被包含。有关使用的默认目录的更多信息,请参阅该过程的文档。 LabelSource确定用于提取图像的地面真实标签的模式。支持三种LabelSource模式:- ‘last_folder’: 使用包含图像的最后一个文件夹的名称作为标签。
- ‘file_name’: 使用每个图像的文件名作为标签。
- ‘file_name_remove_index’: 使用每个图像的文件名作为标签,但删除文件名末尾的所有连续数字和下划线(例如,‘01’,‘_20180101’)。如果要配置自己的
LabelSource模式,可以使用parse_filename过程。
- 过程的输出是一个DLDataset字典,它充当数据库。字典的键包括:
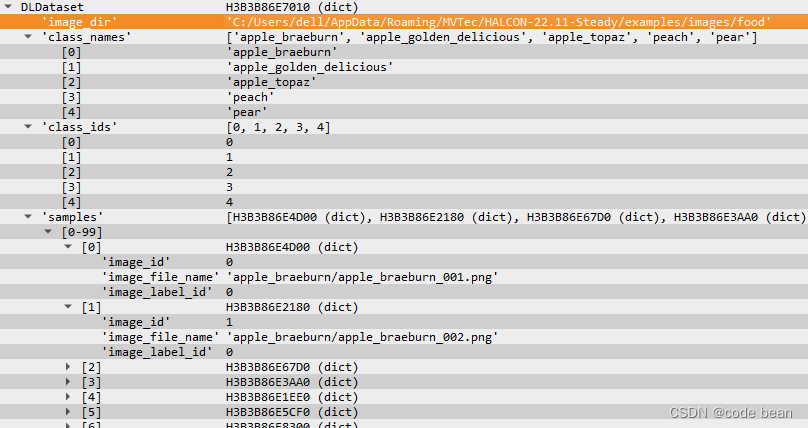
- ‘image_dir’: 所有图像的公共基本路径,由ImageDirectory中所有目录的最深层次共同父目录的路径给出。
- ‘class_names’: 用于区分类别的字符串名称元组。
- ‘class_ids’: 整数元组。
- ‘samples’: 每个样本的字典元组。
- 单个样本的字典具有以下条目:
- ‘image_file_name’: 样本图像的相对路径。
- ‘image_id’: 每个样本的唯一整数ID。
- ‘image_label_id’: 分配给图像的类别ID。
- 单个样本的字典具有以下条目:
- 请注意,该过程假定
RawImageFolder中的所有文件夹都包含在一个共同的父文件夹中。如果不是这种情况,将引发异常。
参数:
RawImageFolder(输入控制):包含带标签图像的图像文件夹的文件夹元组。LabelSource(输入控制):用于提取地面真实标签的模式。默认为’last_folder’。DLDataset(输出控制):生成的数据集字典。
可能用在该函数之后的函数:
split_dl_dataset: 用于拆分DLDataset字典,生成训练、验证和测试集。
提出问题
last_folder: The name of the last folder containing the image is used as label.
怎么理解 这个last?最后?
回答
在这个上下文中,‘last_folder’ 意味着使用包含图像的路径中的最后一个文件夹的名称作为标签。在计算机文件系统中,文件路径是由多个文件夹名称组成的,这些文件夹名称之间通过路径分隔符(例如,在Windows上为反斜杠 \ 或在Unix/Linux上为正斜杠 /)分隔。
例如,考虑以下文件路径:
C:\Users\dell\Images\fruits\apple\image1.jpg
在这个路径中,‘last_folder’ 将使用 “apple” 作为图像的标签,因为 “apple” 是路径中的最后一个文件夹。在这种方式下,图像的标签是基于其所在路径的文件夹结构确定的,而不是文件名。
我的理解
read_dl_dataset_classification 这个函数的第一个参数是一个文件夹,这个文件夹我找到了,里面有四个文件夹:

第二个参数,是输入控制参数,就是决定每个类别的标签名称。
最后就会输出一个数据集。
那这个函数就很好用了,只要你把图片分类放到文件夹中,那么这个函数就能直接输出一个可以供halcon实用的数据集给你!
代码上下文
ImageBaseFolder := PathExample + '/images/food/'
RawImageFolder := ImageBaseFolder + ['apple_braeburn', 'apple_golden_delicious', 'apple_topaz', 'peach', 'pear']
read_dl_dataset_classification (RawImageFolder, 'last_folder', DLDataset)
*
* Read the pretrained classification model.
read_dl_model ('pretrained_dl_classifier_compact.hdl', DLModelHandle)
* Set the class names for the model.
set_dl_model_param (DLModelHandle, 'class_names', DLDataset.class_names)
*
* Preprocess the data in DLDataset.
split_dl_dataset (DLDataset, 70, 15, [])