1 引言
-
目前已囊括48个大模型,覆盖chatgpt、gpt4、谷歌bard、百度文心一言、阿里通义千问、讯飞星火、360智脑、商汤senseChat、微软new-bing、minimax、tigerbot等商用模型, 以及百川、belle、chatglm6b、ziya、guanaco、Phoenix、linly、MOSS、AquilaChat、vicuna、wizardLM、书生internLM、llama2-chat等开源大模型。
-
模型来源涉及国内外大厂、大模型创业公司、高校研究机构。
-
支持多维度能力评测,包括分类能力、信息抽取能力、阅读理解能力、表格问答能力。
2 大模型基本信息
由于大模型较多,下表只展示部分大模型的信息,更多更详细的信息,见https://github.com/jeinlee1991/chinese-llm-benchmark
3 排行榜
3.1 综合能力排行榜
综合能力得分为分类能力、信息抽取能力、阅读理解能力、数据分析能力四者得分的平均值。
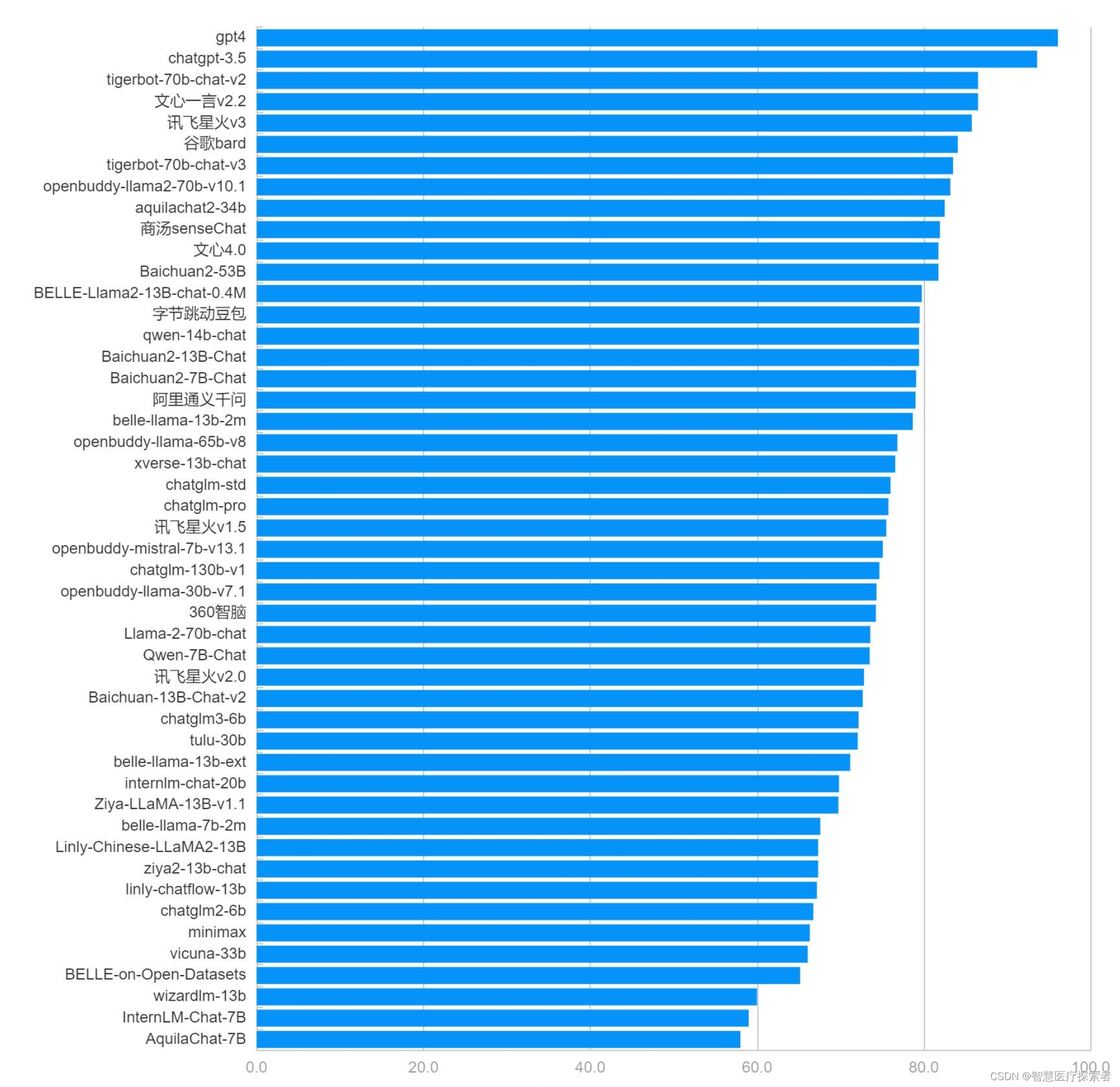
| 类别 | 大模型 | 总分 | 排名 |
|---|---|---|---|
| 商用 | gpt4 | 96.1 | 1 |
| 商用 | chatgpt-3.5 | 93.6 | 2 |
| 开源 | tigerbot-70b-chat-v2 | 86.5 | 3 |
| 商用 | 文心一言v2.2 | 86.5 | 4 |
| 商用 | 讯飞星火v3 | 85.8 | 5 |
| 商用 | 谷歌bard | 84.1 | 6 |
| 开源 | tigerbot-70b-chat-v3 | 83.5 | 7 |
| 开源 | openbuddy-llama2-70b-v10.1 | 83.2 | 8 |
| 开源 | aquilachat2-34b | 82.5 | 9 |
| 商用 | 商汤senseChat | 81.9 | 10 |
| 商用 | 文心4.0 | 81.8 | 11 |
| 商用 | Baichuan2-53B | 81.8 | 12 |
| 开源 | BELLE-Llama2-13B-chat-0.4M | 79.8 | 13 |
| 商用 | 豆包 | 79.5 | 14 |
| 开源 | qwen-14b-chat | 79.4 | 15 |
| 开源 | Baichuan2-13B-Chat | 79.4 | 16 |
| 开源 | Baichuan2-7B-Chat | 79.1 | 17 |
| 商用 | 阿里通义千问 | 79.0 | 18 |
| 开源 | belle-llama-13b-2m | 78.7 | 19 |
| 开源 | openbuddy-llama-65b-v8 | 76.8 | 20 |
| 开源 | xverse-13b-chat | 76.6 | 21 |
| 商用 | chatglm-std | 76.0 | 22 |
| 商用 | chatglm-pro | 75.8 | 23 |
| 商用 | 讯飞星火v1.5 | 75.5 | 24 |
| 开源 | openbuddy-mistral-7b-v13.1 | 75.1 | 25 |
| 商用 | chatglm-130b-v1 | 74.7 | 26 |
| 开源 | openbuddy-llama-30b-v7.1 | 74.3 | 27 |
| 商用 | 360智脑 | 74.3 | 28 |
| 开源 | Llama-2-70b-chat | 73.6 | 29 |
| 开源 | Qwen-7B-Chat | 73.5 | 30 |
| 商用 | 讯飞星火v2.0 | 72.8 | 31 |
| 开源 | Baichuan-13B-Chat-v2 | 72.7 | 32 |
| 开源 | chatglm3-6b | 72.2 | 33 |
| 开源 | tulu-30b | 72.1 | 34 |
| 开源 | belle-llama-13b-ext | 71.2 | 35 |
| 开源 | internlm-chat-20b | 69.8 | 36 |
| 开源 | Ziya-LLaMA-13B-v1.1 | 69.8 | 37 |
| 开源 | belle-llama-7b-2m | 67.6 | 38 |
| 开源 | Linly-Chinese-LLaMA2-13B | 67.3 | 39 |
| 开源 | ziya2-13b-chat | 67.3 | 40 |
| 开源 | linly-chatflow-13b | 67.2 | 41 |
| 开源 | chatglm2-6b | 66.8 | 42 |
| 商用 | minimax | 66.3 | 43 |
| 开源 | vicuna-33b | 66.1 | 44 |
| 开源 | BELLE-on-Open-Datasets | 65.2 | 45 |
| 开源 | wizardlm-13b | 60.0 | 46 |
| 开源 | InternLM-Chat-7B | 59.0 | 47 |
| 开源 | AquilaChat-7B | 58.0 | 48 |
3.2 分类能力排行榜
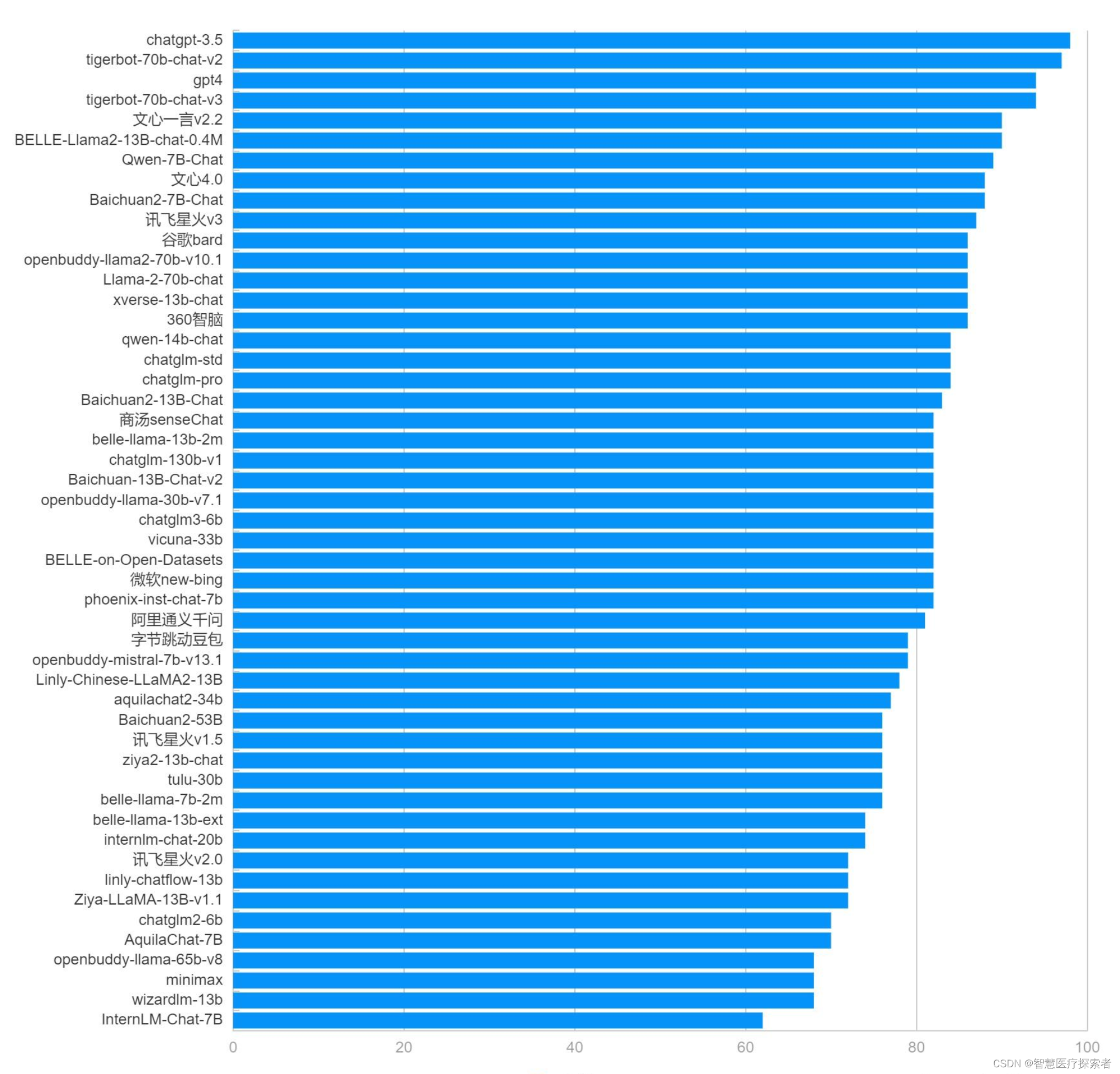
| 类别 | 大模型 | 分类能力 | 排名 |
|---|---|---|---|
| 商用 | chatgpt-3.5 | 98 | 1 |
| 开源 | tigerbot-70b-chat-v2 | 97 | 2 |
| 商用 | gpt4 | 94 | 3 |
| 开源 | tigerbot-70b-chat-v3 | 94 | 4 |
| 商用 | 文心一言v2.2 | 90 | 5 |
| 开源 | BELLE-Llama2-13B-chat-0.4M | 90 | 6 |
| 开源 | Qwen-7B-Chat | 89 | 7 |
| 商用 | 文心4.0 | 88 | 8 |
| 开源 | Baichuan2-7B-Chat | 88 | 9 |
| 商用 | 讯飞星火v3 | 87 | 10 |
| 商用 | 谷歌bard | 86 | 11 |
| 开源 | openbuddy-llama2-70b-v10.1 | 86 | 12 |
| 开源 | xverse-13b-chat | 86 | 13 |
| 商用 | 360智脑 | 86 | 14 |
| 开源 | Llama-2-70b-chat | 86 | 15 |
| 开源 | qwen-14b-chat | 84 | 16 |
| 商用 | chatglm-std | 84 | 17 |
| 商用 | chatglm-pro | 84 | 18 |
| 开源 | Baichuan2-13B-Chat | 83 | 19 |
| 商用 | 商汤senseChat | 82 | 20 |
| 开源 | belle-llama-13b-2m | 82 | 21 |
| 商用 | chatglm-130b-v1 | 82 | 22 |
| 开源 | openbuddy-llama-30b-v7.1 | 82 | 23 |
| 开源 | Baichuan-13B-Chat-v2 | 82 | 24 |
| 开源 | chatglm3-6b | 82 | 25 |
| 开源 | vicuna-33b | 82 | 26 |
| 开源 | BELLE-on-Open-Datasets | 82 | 27 |
| 开源 | phoenix-inst-chat-7b | 82 | 28 |
| 商用 | 微软new-bing | 82 | 29 |
| 商用 | 阿里通义千问 | 81 | 30 |
| 商用 | 豆包 | 79 | 31 |
| 开源 | openbuddy-mistral-7b-v13.1 | 79 | 32 |
| 开源 | Linly-Chinese-LLaMA2-13B | 78 | 33 |
| 开源 | aquilachat2-34b | 77 | 34 |
| 商用 | Baichuan2-53B | 76 | 35 |
| 商用 | 讯飞星火v1.5 | 76 | 36 |
| 开源 | tulu-30b | 76 | 37 |
| 开源 | belle-llama-7b-2m | 76 | 38 |
| 开源 | ziya2-13b-chat | 76 | 39 |
| 开源 | belle-llama-13b-ext | 74 | 40 |
| 开源 | internlm-chat-20b | 74 | 41 |
| 商用 | 讯飞星火v2.0 | 72 | 42 |
| 开源 | Ziya-LLaMA-13B-v1.1 | 72 | 43 |
| 开源 | linly-chatflow-13b | 72 | 44 |
| 开源 | chatglm2-6b | 70 | 45 |
| 开源 | AquilaChat-7B | 70 | 46 |
| 开源 | openbuddy-llama-65b-v8 | 68 | 47 |
| 商用 | minimax | 68 | 48 |
| 开源 | wizardlm-13b | 68 | 49 |
| 开源 | InternLM-Chat-7B | 62 | 50 |
3.3 信息抽取能力排行榜

| 类别 | 大模型 | 信息抽取能力 | 排名 |
|---|---|---|---|
| 商用 | gpt4 | 94 | 1 |
| 商用 | chatgpt-3.5 | 88 | 2 |
| 商用 | 谷歌bard | 88 | 3 |
| 商用 | 文心一言v2.2 | 87 | 4 |
| 开源 | tigerbot-70b-chat-v3 | 85 | 5 |
| 商用 | 商汤senseChat | 85 | 6 |
| 开源 | tigerbot-70b-chat-v2 | 84 | 7 |
| 开源 | openbuddy-llama2-70b-v10.1 | 84 | 8 |
| 商用 | 文心4.0 | 84 | 9 |
| 商用 | Baichuan2-53B | 84 | 10 |
| 开源 | openbuddy-llama-65b-v8 | 84 | 11 |
| 开源 | Baichuan2-13B-Chat | 83 | 12 |
| 商用 | 讯飞星火v3 | 82 | 13 |
| 开源 | aquilachat2-34b | 82 | 14 |
| 商用 | 阿里通义千问 | 81 | 15 |
| 商用 | 讯飞星火v1.5 | 81 | 16 |
| 商用 | 豆包 | 77 | 17 |
| 开源 | Baichuan2-7B-Chat | 76 | 18 |
| 商用 | chatglm-130b-v1 | 76 | 19 |
| 开源 | tulu-30b | 76 | 20 |
| 开源 | belle-llama-13b-2m | 75 | 21 |
| 商用 | 讯飞星火v2.0 | 75 | 22 |
| 开源 | BELLE-Llama2-13B-chat-0.4M | 74 | 23 |
| 开源 | openbuddy-llama-30b-v7.1 | 74 | 24 |
| 开源 | qwen-14b-chat | 72 | 25 |
| 开源 | xverse-13b-chat | 72 | 26 |
| 开源 | openbuddy-mistral-7b-v13.1 | 72 | 27 |
| 开源 | Qwen-7B-Chat | 72 | 28 |
| 商用 | chatglm-std | 71 | 29 |
| 商用 | 360智脑 | 71 | 30 |
| 商用 | chatglm-pro | 70 | 31 |
| 开源 | Baichuan-13B-Chat-v2 | 69 | 32 |
| 开源 | Ziya-LLaMA-13B-v1.1 | 69 | 33 |
| 开源 | chatglm3-6b | 68 | 34 |
| 开源 | chatglm2-6b | 68 | 35 |
| 开源 | Linly-Chinese-LLaMA2-13B | 67 | 36 |
| 开源 | Llama-2-70b-chat | 66 | 37 |
| 开源 | belle-llama-13b-ext | 65 | 38 |
| 开源 | vicuna-33b | 65 | 39 |
| 开源 | internlm-chat-20b | 64 | 40 |
| 开源 | belle-llama-7b-2m | 64 | 41 |
| 开源 | linly-chatflow-13b | 63 | 42 |
| 开源 | BELLE-on-Open-Datasets | 62 | 43 |
| 开源 | phoenix-inst-chat-7b | 62 | 44 |
| 商用 | minimax | 61 | 45 |
| 开源 | InternLM-Chat-7B | 55 | 46 |
| 开源 | ziya2-13b-chat | 54 | 47 |
| 开源 | wizardlm-13b | 52 | 48 |
| 开源 | AquilaChat-7B | 51 | 49 |
| 商用 | 微软new-bing | 44 | 50 |
3.4 阅读理解能力排行榜

| 类别 | 大模型 | 阅读理解能力 | 排名 |
|---|---|---|---|
| 商用 | gpt4 | 99.3 | 1 |
| 商用 | chatgpt-3.5 | 95.3 | 2 |
| 商用 | 文心一言v2.2 | 88.0 | 3 |
| 商用 | Baichuan2-53B | 88.0 | 4 |
| 商用 | 讯飞星火v3 | 88.0 | 5 |
| 开源 | aquilachat2-34b | 88.0 | 6 |
| 开源 | openbuddy-llama2-70b-v10.1 | 86.7 | 7 |
| 商用 | 谷歌bard | 85.3 | 8 |
| 开源 | qwen-14b-chat | 84.7 | 9 |
| 开源 | tigerbot-70b-chat-v3 | 84.0 | 10 |
| 开源 | Baichuan2-7B-Chat | 83.3 | 11 |
| 商用 | 文心4.0 | 83.0 | 12 |
| 商用 | 商汤senseChat | 82.7 | 13 |
| 开源 | openbuddy-llama-30b-v7.1 | 81.3 | 14 |
| 开源 | xverse-13b-chat | 81.3 | 15 |
| 商用 | 阿里通义千问 | 81.0 | 16 |
| 开源 | belle-llama-13b-2m | 80.7 | 17 |
| 开源 | tigerbot-70b-chat-v2 | 80.0 | 18 |
| 商用 | 豆包 | 80.0 | 19 |
| 开源 | Ziya-LLaMA-13B-v1.1 | 80.0 | 20 |
| 开源 | openbuddy-llama-65b-v8 | 79.3 | 21 |
| 商用 | 讯飞星火v2.0 | 79.3 | 22 |
| 开源 | chatglm3-6b | 78.7 | 23 |
| 开源 | internlm-chat-20b | 77.3 | 24 |
| 开源 | belle-llama-13b-ext | 76.7 | 25 |
| 商用 | 讯飞星火v1.5 | 76.0 | 26 |
| 开源 | BELLE-Llama2-13B-chat-0.4M | 76.0 | 27 |
| 商用 | chatglm-std | 76.0 | 28 |
| 商用 | chatglm-pro | 76.0 | 29 |
| 商用 | 微软new-bing | 76.0 | 30 |
| 开源 | tulu-30b | 75.3 | 31 |
| 开源 | Baichuan2-13B-Chat | 74.7 | 32 |
| 开源 | linly-chatflow-13b | 74.7 | 33 |
| 开源 | Qwen-7B-Chat | 74.0 | 34 |
| 商用 | 360智脑 | 74.0 | 35 |
| 开源 | openbuddy-mistral-7b-v13.1 | 73.3 | 36 |
| 开源 | Llama-2-70b-chat | 73.3 | 37 |
| 商用 | minimax | 73.3 | 38 |
| 开源 | Baichuan-13B-Chat-v2 | 72.7 | 39 |
| 商用 | chatglm-130b-v1 | 72.7 | 40 |
| 开源 | chatglm2-6b | 72.0 | 41 |
| 开源 | wizardlm-13b | 72.0 | 42 |
| 开源 | belle-llama-7b-2m | 71.3 | 43 |
| 开源 | phoenix-inst-chat-7b | 71.3 | 44 |
| 开源 | ziya2-13b-chat | 71.3 | 45 |
| 开源 | BELLE-on-Open-Datasets | 68.7 | 46 |
| 开源 | Linly-Chinese-LLaMA2-13B | 67.3 | 47 |
| 开源 | InternLM-Chat-7B | 66.0 | 48 |
| 开源 | vicuna-33b | 63.3 | 49 |
| 开源 | AquilaChat-7B | 56.0 | 50 |
3.5 表格问答排行榜(数据分析)
专门考查大模型对表格的理解分析能力,常用于数据分析。
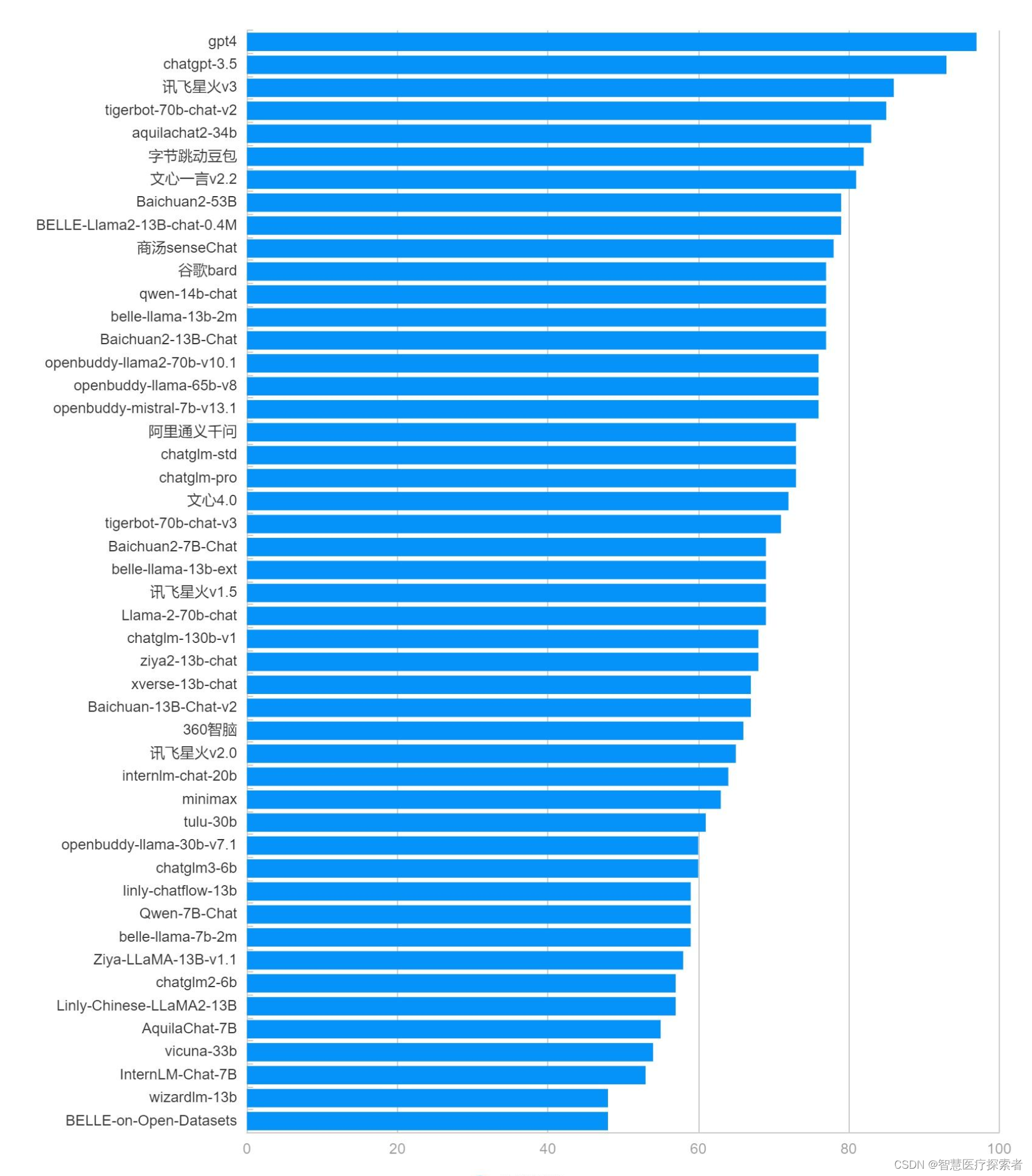
| 类别 | 大模型 | 表格问答能力 | 排名 |
|---|---|---|---|
| 商用 | gpt4 | 97 | 1 |
| 商用 | chatgpt-3.5 | 93 | 2 |
| 商用 | 讯飞星火v3 | 86 | 3 |
| 开源 | tigerbot-70b-chat-v2 | 85 | 4 |
| 开源 | aquilachat2-34b | 83 | 5 |
| 商用 | 豆包 | 82 | 6 |
| 商用 | 文心一言v2.2 | 81 | 7 |
| 商用 | Baichuan2-53B | 79 | 8 |
| 开源 | BELLE-Llama2-13B-chat-0.4M | 79 | 9 |
| 商用 | 商汤senseChat | 78 | 10 |
| 商用 | 谷歌bard | 77 | 11 |
| 开源 | qwen-14b-chat | 77 | 12 |
| 开源 | belle-llama-13b-2m | 77 | 13 |
| 开源 | Baichuan2-13B-Chat | 77 | 14 |
| 开源 | openbuddy-llama2-70b-v10.1 | 76 | 15 |
| 开源 | openbuddy-llama-65b-v8 | 76 | 16 |
| 开源 | openbuddy-mistral-7b-v13.1 | 76 | 17 |
| 商用 | 阿里通义千问 | 73 | 18 |
| 商用 | chatglm-std | 73 | 19 |
| 商用 | chatglm-pro | 73 | 20 |
| 商用 | 文心4.0 | 72 | 21 |
| 开源 | tigerbot-70b-chat-v3 | 71 | 22 |
| 开源 | Baichuan2-7B-Chat | 69 | 23 |
| 开源 | belle-llama-13b-ext | 69 | 24 |
| 商用 | 讯飞星火v1.5 | 69 | 25 |
| 开源 | Llama-2-70b-chat | 69 | 26 |
| 商用 | chatglm-130b-v1 | 68 | 27 |
| 开源 | ziya2-13b-chat | 68 | 28 |
| 开源 | xverse-13b-chat | 67 | 29 |
| 开源 | Baichuan-13B-Chat-v2 | 67 | 30 |
| 商用 | 360智脑 | 66 | 31 |
| 商用 | 讯飞星火v2.0 | 65 | 32 |
| 开源 | internlm-chat-20b | 64 | 33 |
| 商用 | minimax | 63 | 34 |
| 开源 | tulu-30b | 61 | 35 |
| 开源 | openbuddy-llama-30b-v7.1 | 60 | 36 |
| 开源 | chatglm3-6b | 60 | 37 |
| 开源 | linly-chatflow-13b | 59 | 38 |
| 开源 | Qwen-7B-Chat | 59 | 39 |
| 开源 | belle-llama-7b-2m | 59 | 40 |
| 开源 | Ziya-LLaMA-13B-v1.1 | 58 | 41 |
| 开源 | chatglm2-6b | 57 | 42 |
| 开源 | Linly-Chinese-LLaMA2-13B | 57 | 43 |
| 开源 | AquilaChat-7B | 55 | 44 |
| 开源 | vicuna-33b | 54 | 45 |
| 开源 | InternLM-Chat-7B | 53 | 46 |
| 开源 | wizardlm-13b | 48 | 47 |
| 开源 | BELLE-on-Open-Datasets | 48 | 48 |
4 各项能力评分
评分方法:从各个维度给大模型打分,每个维度都对应一个评测数据集,包含若干道题。 每道题依据大模型回复质量给1~5分,将评测集内所有题的得分累加并归一化为100分制,即作为最终得分。
| 类别 | 大模型 | 分类能力 | 信息抽取能力 | 阅读理解能力 | 数据分析能力 | 综合能力 |
|---|---|---|---|---|---|---|
| 商用 | gpt4 | 94 | 94 | 99.3 | 97 | 96.1 |
| 商用 | chatgpt-3.5 | 98 | 88 | 95.3 | 93 | 93.6 |
| 商用 | 文心一言v2.2 | 90 | 87 | 88.0 | 81 | 86.5 |
| 开源 | tigerbot-70b-chat-v2 | 97 | 84 | 80.0 | 85 | 86.5 |
| 商用 | 讯飞星火v3 | 87 | 82 | 88.0 | 86 | 85.8 |
| 商用 | 谷歌bard | 86 | 88 | 85.3 | 77 | 84.1 |
| 开源 | tigerbot-70b-chat-v3 | 94 | 85 | 84.0 | 71 | 83.5 |
| 开源 | openbuddy-llama2-70b-v10.1 | 86 | 84 | 86.7 | 76 | 83.2 |
| 开源 | aquilachat2-34b | 77 | 82 | 88.0 | 83 | 82.5 |
| 商用 | 商汤senseChat | 82 | 85 | 82.7 | 78 | 81.9 |
| 商用 | 文心4.0 | 88 | 84 | 83.0 | 72 | 81.8 |
| 商用 | Baichuan2-53B | 76 | 84 | 88.0 | 79 | 81.8 |
| 开源 | BELLE-Llama2-13B-chat-0.4M | 90 | 74 | 76.0 | 79 | 79.8 |
| 商用 | 豆包 | 79 | 77 | 80.0 | 82 | 79.5 |
| 开源 | Baichuan2-13B-Chat | 83 | 83 | 74.7 | 77 | 79.4 |
| 开源 | qwen-14b-chat | 84 | 72 | 84.7 | 77 | 79.4 |
| 开源 | Baichuan2-7B-Chat | 88 | 76 | 83.3 | 69 | 79.1 |
| 商用 | 阿里通义千问 | 81 | 81 | 81.0 | 73 | 79.0 |
| 开源 | belle-llama-13b-2m | 82 | 75 | 80.7 | 77 | 78.7 |
| 开源 | openbuddy-llama-65b-v8 | 68 | 84 | 79.3 | 76 | 76.8 |
| 开源 | xverse-13b-chat | 86 | 72 | 81.3 | 67 | 76.6 |
| 商用 | chatglm-std | 84 | 71 | 76.0 | 73 | 76.0 |
| 商用 | chatglm-pro | 84 | 70 | 76.0 | 73 | 75.8 |
| 商用 | 讯飞星火v1.5 | 76 | 81 | 76.0 | 69 | 75.5 |
| 开源 | openbuddy-mistral-7b-v13.1 | 79 | 72 | 73.3 | 76 | 75.1 |
| 商用 | chatglm-130b-v1 | 82 | 76 | 72.7 | 68 | 74.7 |
| 开源 | openbuddy-llama-30b-v7.1 | 82 | 74 | 81.3 | 60 | 74.3 |
| 商用 | 360智脑 | 86 | 71 | 74.0 | 66 | 74.3 |
| 开源 | Llama-2-70b-chat | 86 | 66 | 73.3 | 69 | 73.6 |
| 开源 | Qwen-7B-Chat | 89 | 72 | 74.0 | 59 | 73.5 |
| 商用 | 讯飞星火v2.0 | 72 | 75 | 79.3 | 65 | 72.8 |
| 开源 | Baichuan-13B-Chat-v2 | 82 | 69 | 72.7 | 67 | 72.7 |
| 开源 | chatglm3-6b | 82 | 68 | 78.7 | 60 | 72.2 |
| 开源 | tulu-30b | 76 | 76 | 75.3 | 61 | 72.1 |
| 开源 | belle-llama-13b-ext | 74 | 65 | 76.7 | 69 | 71.2 |
| 开源 | internlm-chat-20b | 74 | 64 | 77.3 | 64 | 69.8 |
| 开源 | Ziya-LLaMA-13B-v1.1 | 72 | 69 | 80.0 | 58 | 69.8 |
| 开源 | belle-llama-7b-2m | 76 | 64 | 71.3 | 59 | 67.6 |
| 开源 | Linly-Chinese-LLaMA2-13B | 78 | 67 | 67.3 | 57 | 67.3 |
| 开源 | ziya2-13b-chat | 76 | 54 | 71.3 | 68 | 67.3 |
| 开源 | linly-chatflow-13b | 72 | 63 | 74.7 | 59 | 67.2 |
| 开源 | chatglm2-6b | 70 | 68 | 72.0 | 57 | 66.8 |
| 商用 | minimax | 68 | 61 | 73.3 | 63 | 66.3 |
| 开源 | vicuna-33b | 82 | 65 | 63.3 | 54 | 66.1 |
| 开源 | BELLE-on-Open-Datasets | 82 | 62 | 68.7 | 48 | 65.2 |
| 开源 | wizardlm-13b | 68 | 52 | 72.0 | 48 | 60.0 |
| 开源 | InternLM-Chat-7B | 62 | 55 | 66.0 | 53 | 59.0 |
| 开源 | AquilaChat-7B | 70 | 51 | 56.0 | 55 | 58.0 |
| 开源 | phoenix-inst-chat-7b | 82 | 62 | 71.3 | / | / |
| 商用 | 微软new-bing | 82 | 44 | 76.0 | / | / |
5 ️原始评测数据
测评数据地址:https://github.com/jeinlee1991/chinese-llm-benchmark
评测样本示例:
| 分类评测样本举例 |
|---|
| 请分类以下5种水果:香蕉、西瓜、苹果、草莓、葡萄。 |
| 将下列单词按词性分类。狗,追,跑,大人,高兴,树 |
| 将下列五个词分为两个组别,每个组别都有一个共同点:狗、猫、鸟、鱼、蛇。 |
| 给定一组文本,将文本分成正面和负面情感。举例文本:这部电影非常出色,值得推荐。我觉得导演做得很好。这场音乐会真是个灾难,我非常失望。 |
| 将以下10个单词分类为动物或植物。树木、狮子、玫瑰、草地、松鼠、猴子、蘑菇、兔子、山羊、香蕉 |
| …… |
| 信息抽取评测样本举例 |
|---|
| HR: 你好,我是XYZ公司的招聘主管。我很高兴地通知你,你已经通过了我们的初步筛选,并且我们希望邀请你来参加面试。 候选人:非常感谢,我很高兴收到你们的邀请。请问面试的时间和地点是什么时候和哪里呢? HR: 面试的时间是下周二上午10点,地点是我们公司位于市中心的办公室。你会在面试前收到一封详细的面试通知邮件,里面会包含面试官的名字、面试时间和地址等信息。 候选人:好的,我会准时出席面试的。请问需要我做哪些准备工作呢? HR: 在面试前,请确保你已经仔细研究了我们公司的业务和文化,并准备好了相关的问题和回答。另外,请务必提前到达面试现场,以便有足够的时间了解我们的公司和环境。 候选人:明白了,我会尽最大努力准备好的。非常感谢你的邀请,期待能有机会加入贵公司。 HR: 很高兴能和你通话,我们也期待着能和你见面。祝你好运,并期待下周能见到你。 基于以上对话,抽取出其中的时间、地点和事件。 |
| 给定以下文本段落,提取其中的关键信息。今天早上,纽约市长在新闻发布会上宣布了新的计划,旨在减少治安问题。该计划包括增加派遣警察的人数,以及启动社区倡议,以提高居民对警察工作的支持度。 |
| 在给定的短文中找出三个关键词。西方的哲学历史可上溯至古希腊时期,最重要的哲学流派包括柏拉图学派、亚里士多德学派和斯多葛学派。 |
| 从以下诗句中提取人物名称:两个黄鹂鸣翠柳,一行白鹭上青天。 |
| 明天天气怎么样?广州明天最冷多少度?广东大后天最暖多少度?北京冷不冷?提取出上述句子中的地理位置实体 |
| …… |
| 阅读理解评测样本举例 |
|---|
| 牙医:好的,让我们看看你的牙齿。从你的描述和我们的检查结果来看,你可能有一些牙齦疾病,导致牙齿的神经受到刺激,引起了敏感。此外,这些黑色斑点可能是蛀牙。病人:哦,真的吗?那我该怎么办?牙医:别担心,我们可以为你制定一个治疗计划。我们需要首先治疗牙龈疾病,然后清除蛀牙并填充牙洞。在此过程中,我们将确保您感到舒适,并使用先进的技术和材料来实现最佳效果。病人:好的,谢谢您,医生。那么我什么时候可以开始治疗?牙医:让我们为您安排一个约会。您的治疗将在两天后开始。在此期间,请继续刷牙,使用牙线,并避免吃过于甜腻和酸性的食物和饮料。病人:好的,我会的。再次感谢您,医生。牙医:不用谢,我们会尽最大的努力帮助您恢复健康的牙齿。基于以上对话回答:病人在检查中发现的牙齿问题有哪些? |
| 文化艺术报讯 国务院办公厅发布关于2023年部分节假日安排的通知,具体内容如下:元旦:2022年12月31日至2023年1月2日放假调休,共3天。春节:1月21日至27日放假调休,共7天。1月28日(星期六)、1月29日(星期日)上班。清明节:4月5日放假,共1天。劳动节:4月29日至5月3日放假调休,共5天。4月23日(星期日)、5月6日(星期六)上班。端午节:6月22日至24日放假调休,共3天。6月25日(星期日)上班。中秋节、国庆节:9月29日至10月6日放假调休,共8天。10月7日(星期六)、10月8日(星期日)上班。基于以上信息回答:2023年五一假期怎么放假。 |
| 基于以下表格,请问张三的考勤情况员工姓名,日期,上班时间,下班时间,是否迟到,是否早退,是否请假张三,1月1日,8:30,17:30,否,否,否李四,1月1日,9:00,18:00,是,否,否王五,1月1日,8:00,16:30,否,是,否赵六,1月1日,8:30,17:00,否,否,是张三,1月2日,8:00,17:00,否,否,否李四,1月2日,8:30,17:30,否,否,否王五,1月2日,9:00,18:00,是,否,否赵六,1月2日,8:30,17:00,否,否,是 |
| 对于给定的问答对,判断问题是否被正确回答问题:地球是第几颗行星?答案:地球是第三颗行星。 |
| 根据以下文本回答问题:什么是能量守恒定律?物理学是自然科学的一个重要分支,研究自然界的物质、能量、空间和时间等基本概念。在物理学的研究中,科学家们探索了宇宙的奥秘,从微观粒子到宏观天体的各个方面都进行了深入研究。在物理学中,一个重要的概念是能量守恒定律。能量守恒定律指出,一个孤立系统的总能量在任何时间都是不变的。也就是说,能量不能被创造或摧毁,只能被转化成其他形式。例如,当一个物体被提起并释放时,它的势能被转化为动能,使得物体开始运动。 |
| …… |
大模型输出结果示例
| prompt输入 | chatgpt3.5输出 |
|---|---|
| 将下列单词按词性分类。狗,追,跑,大人,高兴,树 | 好的,以下是这些单词按照词性分类后的结果:名词:狗、大人、树动词:追、跑形容词:高兴 |
| 从以下诗句中提取人物名称:两个黄鹂鸣翠柳,一行白鹭上青天。 | 这句诗出自唐代诗人杜甫的《绝句》,并没有明确提到人物名称。这句诗主要是在描绘自然景色,通过形象生动的语言来表现春天的美丽景象。诗中提到“两个黄鹂”,“一行白鹭”,他们是动物而非人物名称。黄鹂是一种鸟类,它们身体鲜黄色,嘴巴呈钩形,叫声清脆悦耳;白鹭是另一种水鸟,身体白色,嘴巴细长,善于捕捉鱼类等。杨婉这句诗意境深远,很好地表现了大自然的美丽和神奇。 |
| …… | …… |
6 评测的目的和意义
-
大模型百花齐放,也参差不齐。不少媒体的宣传往往夸大其词,避重就轻,容易混淆视听;而某些公司为了PR,也过分标榜自己大模型的能力,动不动就“达到chatgpt水平”,动不动就“国内第一”。 所谓“外行看热闹,内行看门道”,业界急需一股气流,摒弃浮躁,静下心来打磨前沿技术,真真正正用技术实力说话。这就少不了一个公开、公正、公平的大模型评测系统,把各类大模型的优点、不足一一展示出来。 如此,大家既能把握当下的发展水平、与国外顶尖技术的差距,也能更加清晰地看明白未来的努力方向,而不被资本热潮、舆论热潮所裹挟。
-
对于产业界来说,特别是对于不具备大模型研发能力的公司,熟悉大模型的技术边界、高效有针对性地做大模型技术选型,在现如今显得尤为重要。 而一个公开、公正、公平的大模型评测系统,恰好能够提供应有的助力,避免重复造轮子,避免因技术栈不同而导致不必要的争论,避免“鸡同鸭讲”。
-
对于大模型研发人员,包括对大模型技术感兴趣的人、学术界看中实践的人,各类大模型的效果对比,反应出了背后不同技术路线、技术方法的有效性,这就提供了非常好的参考意义。 不同大模型的相互参考、借鉴,帮忙大家躲过不必要的坑、避免重复实验带来的资源浪费,有助于整个大模型生态圈的良性高效发展。