目录:导读
前言
1、究竟什么是压力测试
压力测试指的是在高并发大流量下进行的测试,测试人员可以通过观察系统在峰值负载下的表现,从而找到系统中存在的性能隐患。
与监控一样,压力测试是一种常见的发现系统中存在问题的方式,也是保障系统可用性和稳定性的重要手段。
而在压力测试的过程中,我们不能只针对某一个核心模块来做压测,而需要将接入层、所有后端服务、数据库、缓存、消息队列、中间件以及依赖的第三方服务系统及其资源,都纳入压力测试的目标之中。
因为,一旦用户的访问行为增加,包含上述组件服务的整个链路都会受到不确定的大流量的冲击。因此,它们都需要依赖压力测试来发现可能存在的性能瓶颈,这种针对整个调用链路执行的压力测试也称为“全链路压测”。
2、如何搭建全链路压测平台
搭建全链路压测平台,主要有两个关键点。
一点是流量的隔离。由于压力测试是在正式环境进行,所以需要区分压力测试流量和正式流量,这样可以针对压力测试的流量做单独的处理。
另一点是风险的控制。也就是尽量避免压力测试对于正常访问用户的影响。
因此,一般来说全链路压测平台需要包含以下几个模块:
1)流量构造和产生模块;
2)压测数据隔离模块;
3)系统健康度检查和压测流量干预模块。
3、压测数据的产生
一般来说,我们系统的入口流量是来自于客户端的HTTP请求。所以,我们会考虑在系统高峰期时,将这些入口流量拷贝一份,在经过一些流量清洗的工作之后(比如过滤一些无效的请求),将数据存储在像是HBase、MongoDB这些NoSQL存储组件或者亚马逊S3这些云存储服务中,我们称之为流量数据工厂。
这样,当我们要压测的时候,就可以从这个工厂中获取数据,将数据切分多份后下发到多个压测节点上了。
特殊注意点:
首先,我们可以使用多种方式来实现流量的拷贝。最简单的一种方式:直接拷贝负载均衡服务器的访问日志,数据就以文本的方式写入到流量数据工厂中。但是这样产生的数据在发起压测时,需要自己写解析的脚本来解析访问日志,会增加压测时候的成本,不太建议使用。
另一种方式:通过一些开源的工具来实现流量的拷贝。这里,我推荐一款轻型的流量拷贝工具GoReplay,它可以劫持本机某一个端口的流量,将它们记录在文件中,传送到流量数据工厂中。
在压测时,你也可以使用这个工具进行加速的流量回放,这样就可以实现对正式环境的压力测试了。
其次,如上文中提到,我们在下发压测流量时,需要保证下发流量的节点与用户更加接近,起码不能和服务部署节点在同一个机房中,这样可以尽量保证压测数据的真实性。
另外,我们还需要对压测流量染色,也就是增加压测标记。在实际项目中,我会在HTTP的请求头中增加一个标记项,比如说叫做is stress test,在流量拷贝之后,批量在请求中增加这个标记项,再写入到数据流量工厂中。
4、数据如何隔离
将压测流量拷贝下来的同时,我们也需要考虑对系统做改造,以实现压测流量和正式流量的隔离,这样一来就会尽量避免压测对线上系统的影响。一般来说,我们需要做两方面的事情。
一方面,针对读取数据的请求(一般称之为下行流量),我们会针对某些不能压测的服务或者组件,做Mock或者特殊的处理,举个例子。
在业务开发中,我们一般会依据请求记录用户的行为,比如,用户请求了某个商品的页面,我们会记录这个商品多了一次浏览的行为,这些行为数据会写入一份单独的大数据日志中,再传输给数据分析部门,形成业务报表给到产品或者老板做业务的分析决策。
在压测的时候,肯定会增加这些行为数据,比如原本一天商品页面的浏览行为是一亿次,而压测之后变成了十亿次,这样就会对业务报表产生影响,影响后续的产品方向的决策。因此,我们对于这些压测产生的用户行为做特殊处理,不再记录到大数据日志中。
再比如,我们系统会依赖一些推荐服务,推荐一些你可能感兴趣的商品,但是这些数据的展示有一个特点就是展示过的商品就不再会被推荐出来。
如果你的压测流量经过这些推荐服务,大量的商品就会被压测流量请求到,线上的用户就不会再看到这些商品了,也就会影响推荐的效果。
所以,我们需要Mock这些推荐服务,让不带有压测标记的请求经过推荐服务,而让带有压测标记的请求经过Mock服务。
搭建Mock服务,你需要注意一点:这些Mock服务最好部署在真实服务所在的机房,这样可以尽量模拟真实的服务部署结构,提高压测结果的真实性。
另一方面,针对写入数据的请求(一般称之为上行流量),我们会把压测流量产生的数据写入到影子库,也就是和线上数据存储完全隔离的一份存储系统中。针对不同的存储类型,我们会使用不同的影子库的搭建方式。
1)如果数据存储在MySQL中,我们可以在同一个MySQL实例,不同的Schema中创建一套和线上相同的库表结构,并且把线上的数据也导入进来。
2)而如果数据是放在Redis中,我们对压测流量产生的数据,增加一个统一的前缀,存储在同一份存储中。
3)还有一些数据会存储在Elasticsearch中,针对这部分数据,我们可以放在另外一个单独的索引表中。
通过对下行流量的特殊处理以及对上行流量增加影子库的方式,我们就可以实现压测流量的隔离了。
5、压力测试如何实施
在拷贝了线上流量和完成了对线上系统的改造之后,我们就可以进行压力测试的实施了。在此之前,一般会设立一个压力测试的目标,比如说,整体系统的QPS需要达到每秒20万。
不过,在压测时,不会一下子把请求量增加到每秒20万次,而是按照一定的步长(比如每次压测增加一万QPS),逐渐地增加流量。在增加一次流量之后,让系统稳定运行一段时间,观察系统在性能上的表现。
如果发现依赖的服务或者组件出现了瓶颈,可以先减少压测流量,比如,回退到上一次压测的QPS,保证服务的稳定,再针对此服务或者组件进行扩容,然后再继续增加流量压测。
为了能够减少压力测试过程中人力投入成本,可以开发一个流量监控的组件,在这个组件中,预先设定一些性能阈值。
比如,容器的CPU使用率的阈值可以设定为60%~70%;
系统的平均响应时间的上限可以设定为1秒;
系统慢请求的比例设置为1%等等。
当系统性能达到这个阈值之后,流量监控组件可以及时发现,并且通知压测流量下发组件减少压测流量,并且发送报警给到开发和运维的同学,开发和运维同学就迅速地排查性能瓶颈,在解决问题或者扩容之后再继续执行压测。
| 下面是我整理的2023年最全的软件测试工程师学习知识架构体系图 |
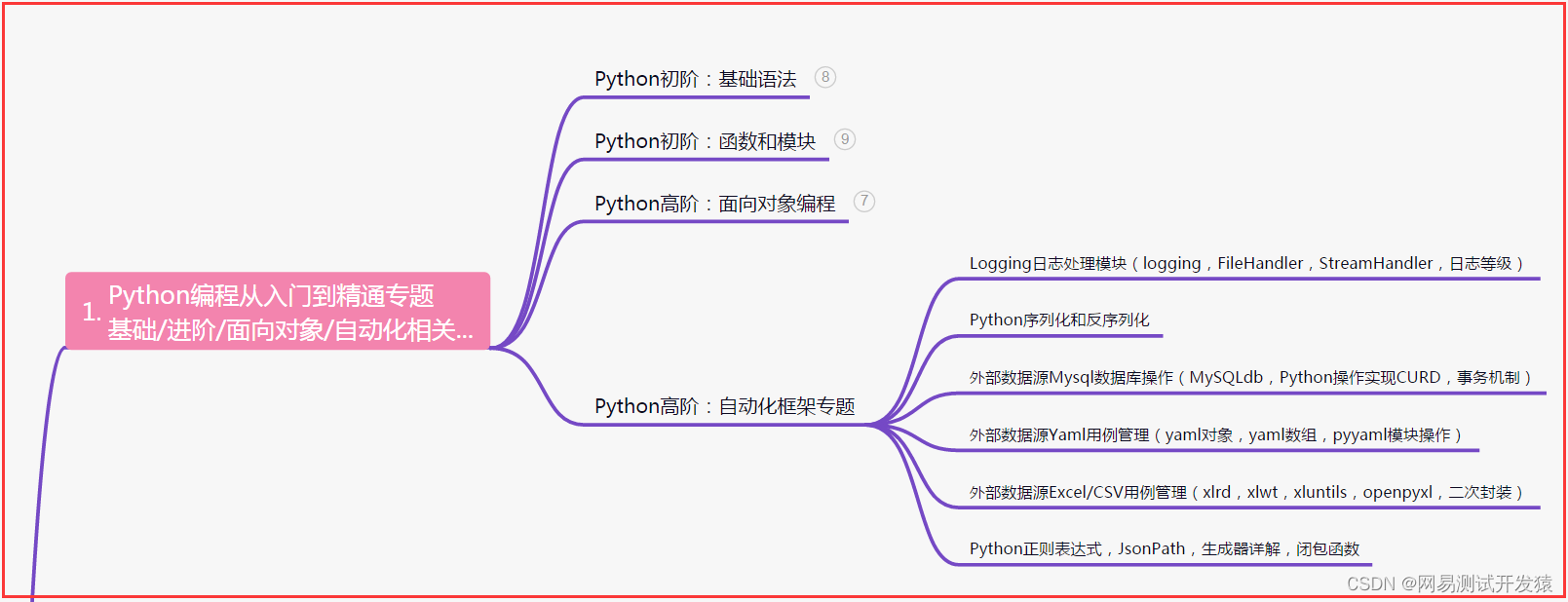
一、Python编程入门到精通
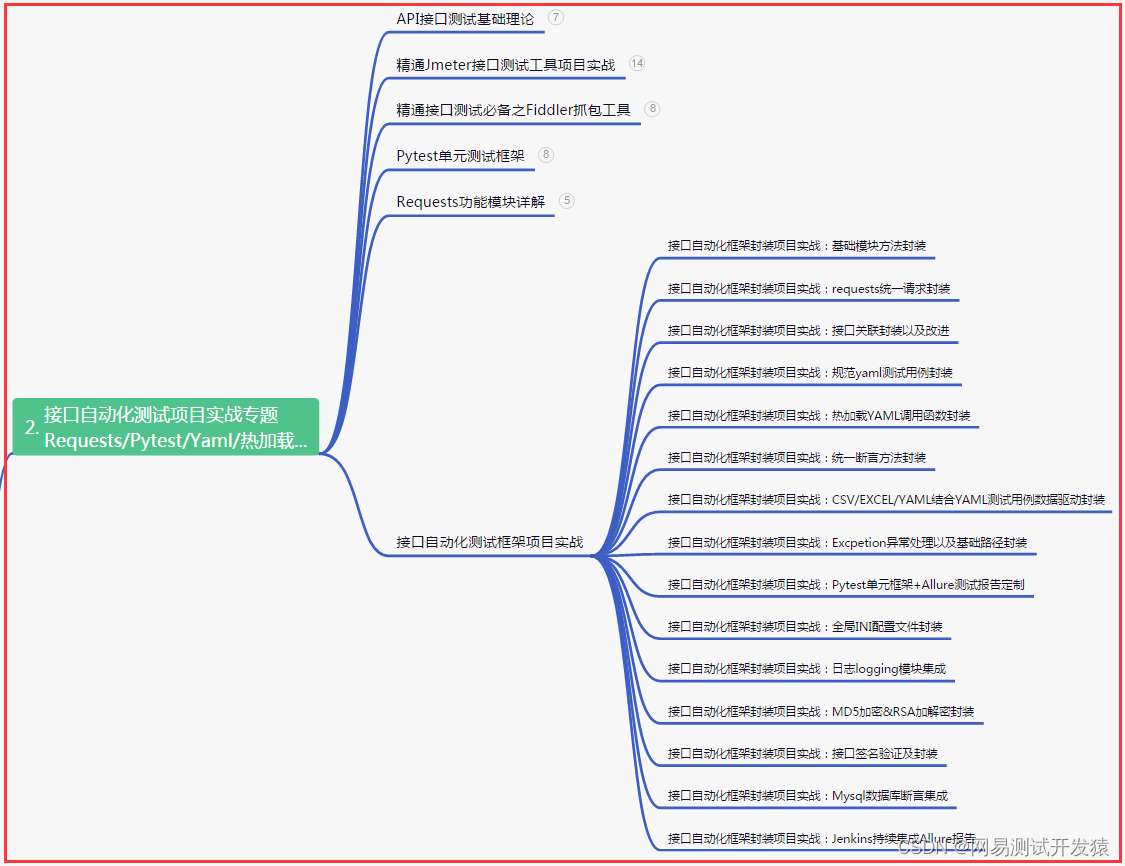
二、接口自动化项目实战
三、Web自动化项目实战

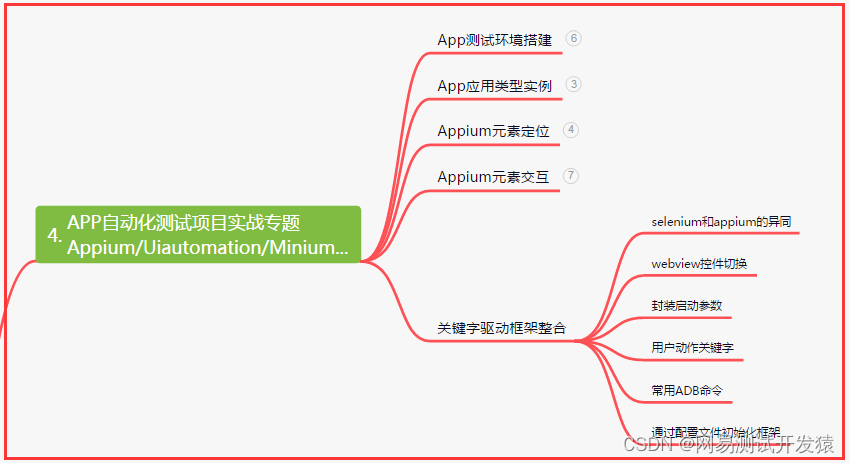
四、App自动化项目实战
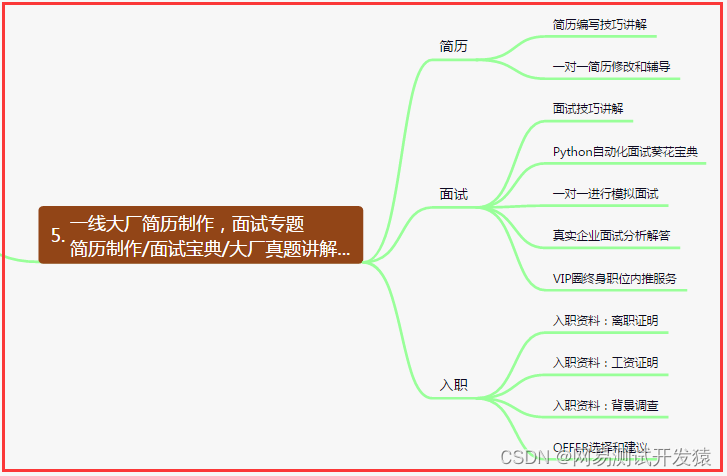
五、一线大厂简历
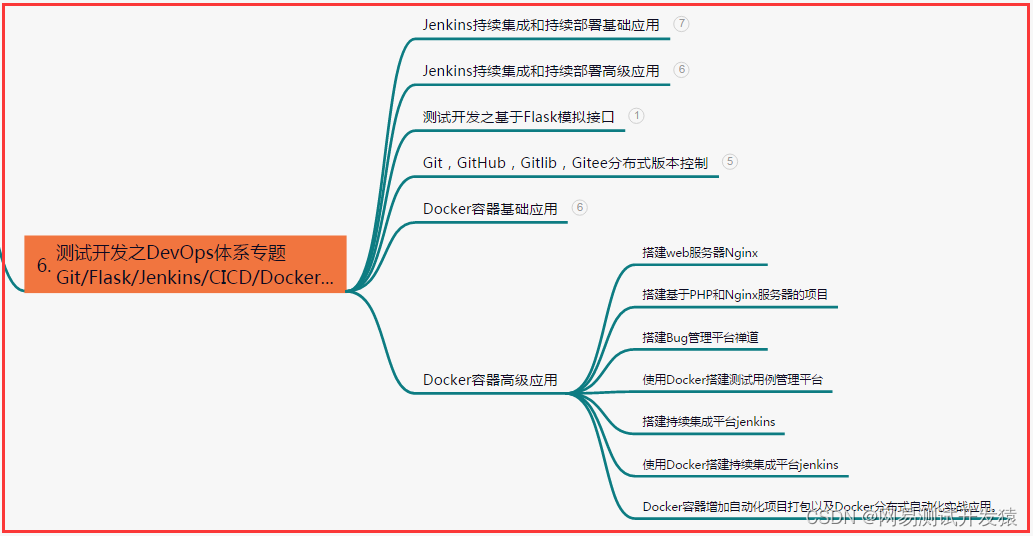
六、测试开发DevOps体系
七、常用自动化测试工具

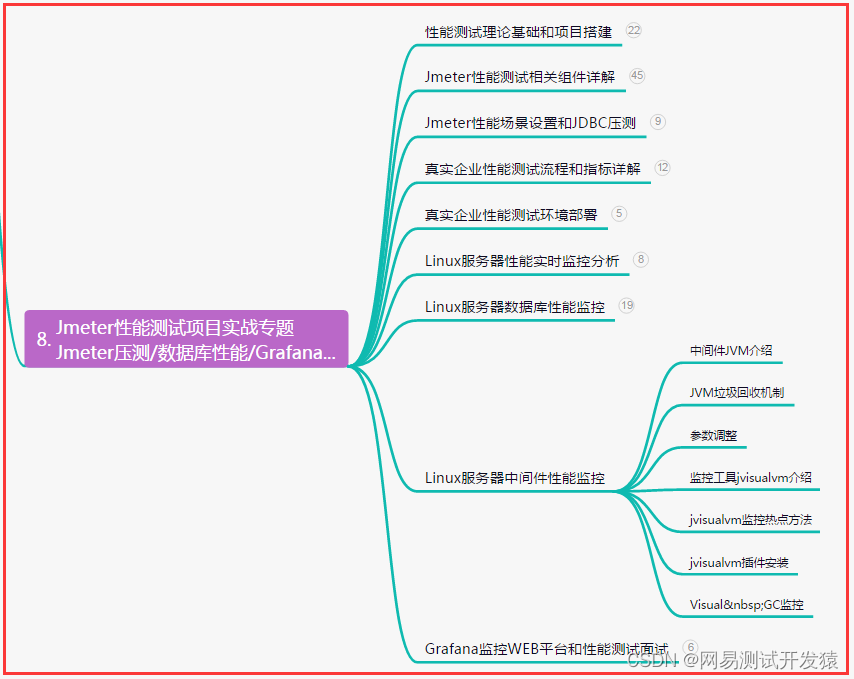
八、JMeter性能测试
九、总结(尾部小惊喜)
在追逐梦想的道路上,不要忘记奋斗的初心。坚守激情,超越自我,只有付出努力和汗水,才能绽放出属于你独一无二的辉煌光芒。
心怀信念,脚踏实地,不断努力奋斗。无论前路多么艰难,相信自己的能力,勇敢追求梦想,只有坚持不懈,才能创造出真正的辉煌人生。
困难不会永远存在,但坚持奋斗的精神会让你变得更加强大。勇敢追求梦想,坚持不懈,成功的光芒终将照耀在你的人生之路上。