前言
上篇文章讲了mycat2实现读写分离,本文讲解数据分片。
首先给出官方推荐的三篇学习文档:
mycat2 分表部署
通过注释配置
逻辑库与逻辑表
正式配置之前,先声明一下,配置分表这里采用注释配置的方法,配置即可生效并且动态更新Mycat配置并且把配置持久化,具体可参考上边给出的第二个文档介绍,这个注释配置挺方便的。
下边开始正式讲解,老规矩,讲分库分表,分区就不讲了,因为感觉如果单单分区,就没必要使用mycat了,什么是分区可以自行百度。
首先先让mycat连接上mysql:
vim conf/datasources/prototypeDs.datasource.json
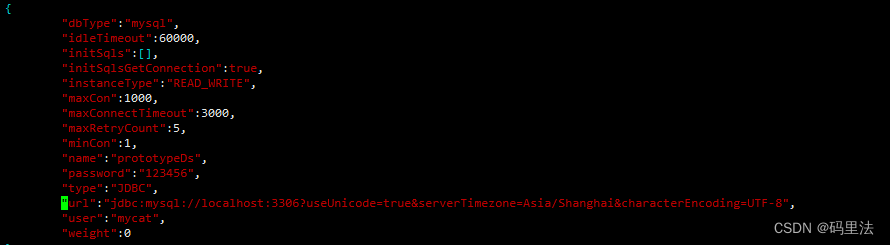
这个
url可以写库名称,也可以不写,也可以默认就是mysql库不动,反正无所谓,只需要保证账号密码以及ip端口没错,让mycat能顺利连接上mysql就行,到时会自动在mysql下创建mycat库,用于内部使用,就不研究这个了,知道就行。
另外说明一下,我所有的连接mysql,mycat都是用的navicat工具。
单数据源单库分表
-
准备内容
这里采用一个库,多个分表来掩饰,准备内容:
一个库(test_data),三个分片表(user_0、user_1、user_2)(也可以不配置,等我们设置分片规则的时候,这些库表会自动创建的)
 扫描二维码关注公众号,回复: 17153156 查看本文章
扫描二维码关注公众号,回复: 17153156 查看本文章
-
配置
首先在mycat上创建逻辑库(test_data),对应mysql上真实存在的物理库(test_data)。CREATE DATABASE `test_data`;
接着创建数据分片规则,采用注释方法配置,先看配置:/*+ mycat:createTable{ "schemaName":"test_data", "tableName":"user", "shardingTable":{ "createTableSQL":"CREATE TABLE `user` ( `id` int(32) NOT NULL, `name` varchar(255) DEFAULT NULL, `age` int(3) NULL DEFAULT NULL, `price` decimal(10, 2) DEFAULT NULL, `note` varchar(255) DEFAULT NULL, PRIMARY KEY (`id`), KEY `id` (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8", "function":{ "properties":{ "mappingFormat": "prototype/test_data/user_${tableIndex}", "dbNum":1, //分库数量 "tableNum":3, //分表数量 "tableMethod":"mod_hash(id)", //分表分片函数 "storeNum":1, //实际存储节点数量 "dbMethod":"mod_hash(id)" //分库分片函数 } }, "partition":{ } } } */;解释一下
mappingFormat属性
targetName/schemaName/tableName
数据库 /物理库名 /物理分表名
targetName:就是配置集群数据源名称,对应prototype.cluster.json文件中的name属性;
schemaName:逻辑库;
tableName: 分表的名称;
以上属性都支持表达式,比如user_${tableIndex}会自动根据配置的分表数量(tableNum),从0开始,分为user_0、user_1、user_2三个表,配置集群数据源和逻辑库都是这个原理,这里是单数据源单库就不演示了。
另外,建表语句复杂的话可以先导出表结构,复制粘贴到createTableSQL属性后边即可。
算法请参考:分片算法简介——如果默认的算法都不满足需求,可以下载mycat的源代码,然后修改对应的算法,打包来用即可。分片规则我放在文章最后讲。配置完成之后,会发现在schemas路径下的test_data.schema.json文件多了刚才我们配置的内容:
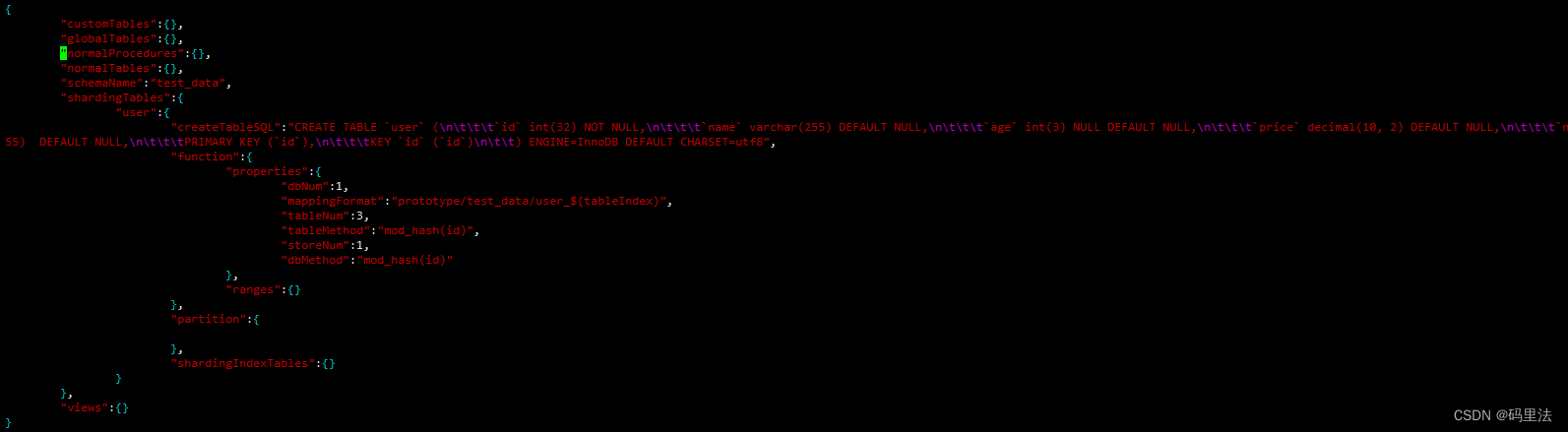
并且mycat下也多了一张user表:

注意这个user表是逻辑表,在物理库中是不存在的,主要是综合user_0~3表的信息
查看一下分片规则,在mycat下:
/*+ mycat:showTopology{ "schemaName":"test_data", "tableName":"user" } */;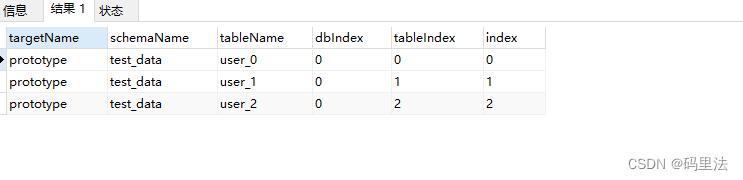
-
测试
INSERT INTO user VALUES(1, 'zhangsan',24,12.45,'备注一下'); INSERT INTO user VALUES(2, 'lisi',24,12.45,'备注一下'); INSERT INTO user VALUES(3, 'wangwu',24,12.45,'备注一下'); INSERT INTO user VALUES(4, 'zhaoliu',24,12.45,'备注一下');在mycat的user表下会看到全部数据
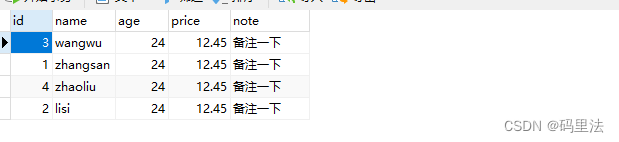
同时这四条数据会按照hash算法分不到3个不同的user表中。
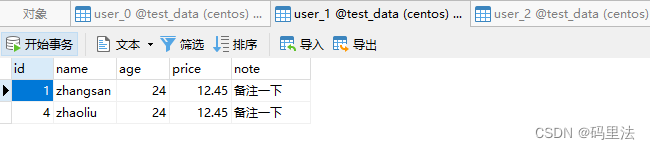
多数据源多库分表
-
期望
我们要创建出这样的分片表:
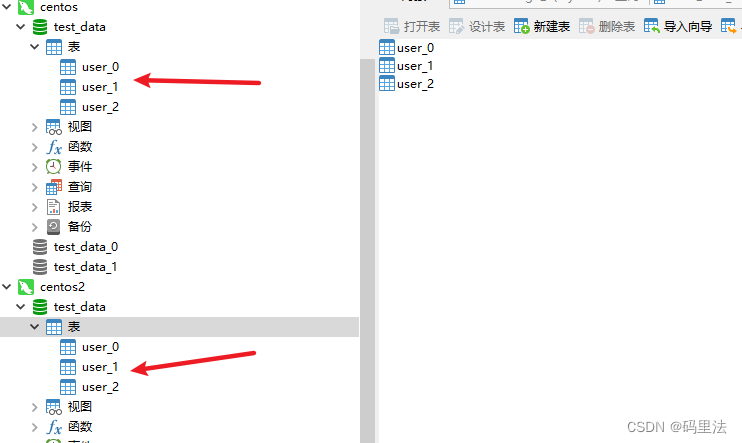
-
准备
在上一步的准备下,增加数据源,首先清空上一步的配置清空mycat下的user表数据,对应的其他物理表上的数据也会被清除。
truncate table user然后删除掉user表,相当于删除之前的分片规则。
-
配置
由于这里采用了多个数据源,多个库,多个表,所以我们需要在mycat中相应的创建多个数据源,多个集群。创建多数据源数据源1:/*+ mycat:createDataSource{ "dbType":"mysql", "idleTimeout":60000, "initSqls":[], "initSqlsGetConnection":true, "instanceType":"READ_WRITE", "maxCon":1000, "maxConnectTimeout":3000, "maxRetryCount":5, "minCon":1, "name":"ds0", "password":"root", "type":"JDBC", "url":"jdbc:mysql://localhost:3306/test_data?useUnicode=true&serverTimezone=UTC&characterEncoding=UTF-8", "user":"root", "weight":0 } */;数据源2:/*+ mycat:createDataSource{ "dbType":"mysql", "idleTimeout":60000, "initSqls":[], "initSqlsGetConnection":true, "instanceType":"READ_WRITE", "maxCon":1000, "maxConnectTimeout":3000, "maxRetryCount":5, "minCon":1, "name":"ds1", "password":"root", "type":"JDBC", "url":"jdbc:mysql://192.168.150.131:3306/test_data?useUnicode=true&serverTimezone=UTC&characterEncoding=UTF-8", "user":"root", "weight":0 } */;这里我单独创建了两个数据源配置文件,当然你也可以利用已经存在的prototypeDs.datasource.json文件作为数据源1,那么你只需要再配置数据源2就可以了。
创建集群创建c0、c1集群,用来关联数据源1、2。
自动分片默认要求集群名字以c为前缀,数字为后缀,c0就是分片表第一个节点,c1就是第二个节点,也可以自己更改命名。集群0/*+ mycat:createCluster{ "clusterType":"MASTER_SLAVE", "heartbeat":{ "heartbeatTimeout":1000, "maxRetry":3, "minSwitchTimeInterval":300, "slaveThreshold":0 }, "masters":[ "ds0" //主节点 ], "maxCon":2000, "name":"c0", "readBalanceType":"BALANCE_ALL", "switchType":"SWITCH" } */;集群1/*+ mycat:createCluster{ "clusterType":"MASTER_SLAVE", "heartbeat":{ "heartbeatTimeout":1000, "maxRetry":3, "minSwitchTimeInterval":300, "slaveThreshold":0 }, "masters":[ "ds1" //主节点 ], "maxCon":2000, "name":"c1", "readBalanceType":"BALANCE_ALL", "switchType":"SWITCH" } */;创建分片规则/*+ mycat:createTable{ "schemaName":"test_data", "tableName":"user", "shardingTable":{ "createTableSQL":"CREATE TABLE `user` ( `id` int(32) NOT NULL, `name` varchar(255) DEFAULT NULL, `age` int(3) NULL DEFAULT NULL, `price` decimal(10, 2) DEFAULT NULL, `note` varchar(255) DEFAULT NULL, PRIMARY KEY (`id`), KEY `id` (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8", "function":{ "properties":{ "mappingFormat": "c${targetIndex}/test_data/user_${tableIndex}", "dbNum":2, //分库数量 "tableNum":3, //分表数量 "tableMethod":"mod_hash(id)", //分表分片函数 "storeNum":2, //实际存储节点数量 "dbMethod":"mod_hash(id)" //分库分片函数 } }, "partition":{ } } } */;可以看到分库数量和存储节点都是设置的2,因为分库名称都是test_data,所以mappingFormat中直接写死就行了,不用动态配置。
分片表创建出来了,再查看一下分片详细信息:
/*+ mycat:showTopology{ "schemaName":"test_data", "tableName":"user" } */;结果如下,符合我们一开始的期望。
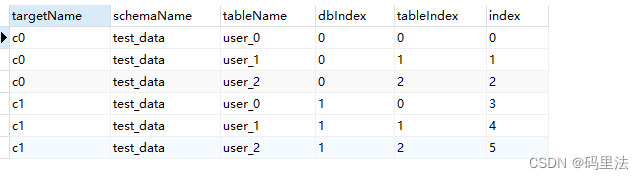
-
测试
添加数据INSERT INTO user VALUES(1, 'zhangsan',24,12.45,'备注一下'); INSERT INTO user VALUES(2, 'lisi',24,12.45,'备注一下'); INSERT INTO user VALUES(3, 'wangwu',24,12.45,'备注一下'); INSERT INTO user VALUES(4, 'zhaoliu',24,12.45,'备注一下');测试结果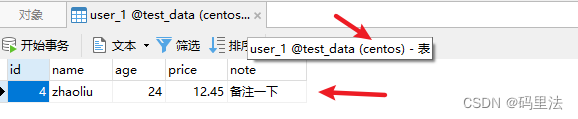
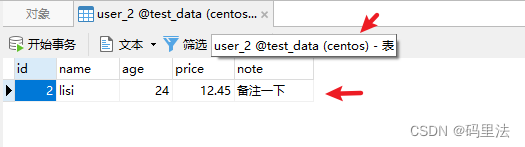
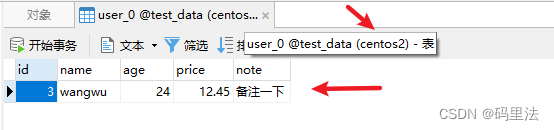
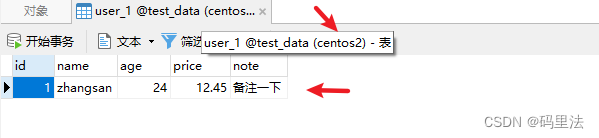
可以看出来,插入数据根据mod_hash算法分布到了不同的数据源,数据库表中。
默认分片规则讲解
通过上边的两个小例子,可以看出来,分片的核心计算方法取决于属性properties里的配置。
"function":{
"properties":{
"mappingFormat": "c${targetIndex}/test_data/user_${tableIndex}",
"dbNum":2, //分库数量
"tableNum":3, //分表数量
"tableMethod":"mod_hash(id)", //分表分片函数
"storeNum":2, //实际存储节点数量
"dbMethod":"mod_hash(id)" //分库分片函数
}
},
可以看到,mappingFormat是映射分片表的,创建映射的规则取决于下边的dbNum、tableNum、storeNum。
为什么这么说,因为mappingFormat中的${targetIndex}的值就是根据这个三个num决定的,那么再说一下index都分为哪几种,先看下边的图,上边案例也有这个图的说明。
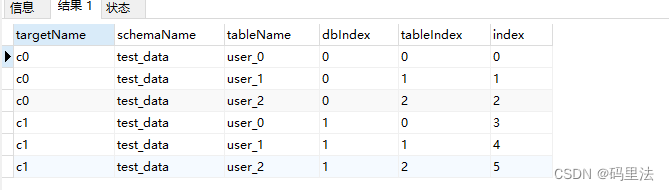
由此可见index分为:dbIndex、tableIndex、index,另外还有一个targetIndex,图里没显示,所以不难看出,这些index都是根据上边的三个num从0开始累加的,index属于全局索引,计算下来有多少表,索引就累计加到多少。
明白这个之后,咱们再举例讲。
准备环境
已知条件:
两个数据源:192.168.150.131、127.0.0.1
三个集群:c0,c1,prototype
c0关联127.0.0.1、c1关联192.168.150.131、prototype关联127.0.0.1
所有数据源都有test_data库。

公用配置:
/*+ mycat:createTable{
"schemaName":"test_data",
"tableName":"user",
"shardingTable":{
"createTableSQL":"CREATE TABLE `user` (
`id` int(32) NOT NULL,
`name` varchar(255) DEFAULT NULL,
`age` int(3) NULL DEFAULT NULL,
`price` decimal(10, 2) DEFAULT NULL,
`note` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `id` (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8",
"function":{
"properties":{
...//这里变化
}
},
"partition":{
}
}
} */;
案例一
这样配置分片规则
"function":{
"properties":{
"mappingFormat": "prototype/test_data/user_${tableIndex}",
"dbNum":1, //分库数量
"tableNum":3, //分表数量
"tableMethod":"mod_hash(id)", //分表分片函数
"storeNum":1, //实际存储节点数量
"dbMethod":"mod_hash(id)" //分库分片函数
}
},
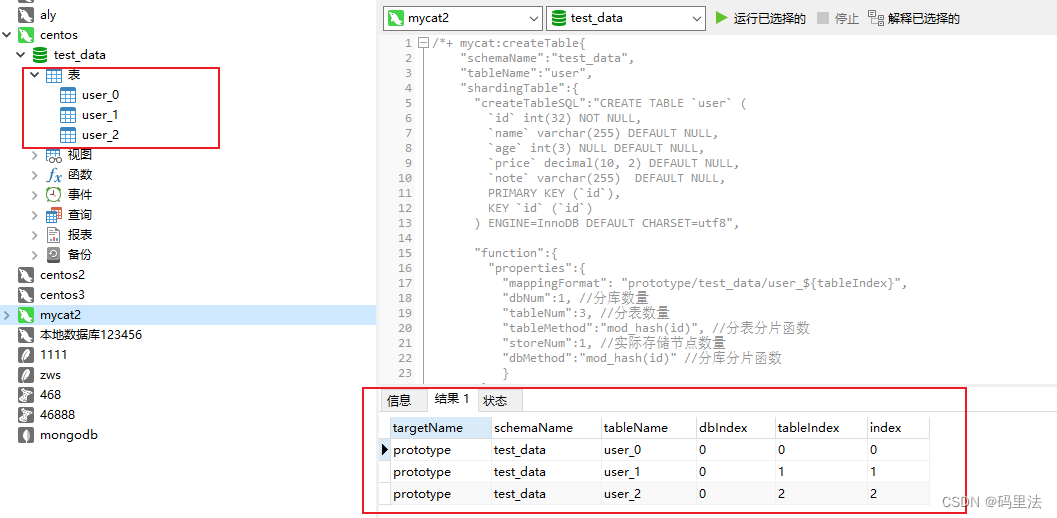
可以看出这里只配置了一个变量,因为tableNum=3,可以算出tableIndex取值范围为:{0,1,2},
那么结果将是:在prototype(127.0.0.1数据源)的test_data表下会创建出,user_0、user_1、user_2三个表。
实际结果也是如此:
案例二
这样配置分片规则
"function":{
"properties":{
"mappingFormat": "prototype/test_data_${dbIndex}/user_${tableIndex}",
"dbNum":2, //分库数量
"tableNum":3, //分表数量
"tableMethod":"mod_hash(id)", //分表分片函数
"storeNum":1, //实际存储节点数量
"dbMethod":"mod_hash(id)" //分库分片函数
}
},
可以看出这里配置了两个变量,因为dbNum=2,tableNum=3,可以算出dbIndex的取值范围为:{0,1},tableIndex取值范围为:{0,1,2},
那么结果将是:在prototype(127.0.0.1数据源)下创建出test_data_0和test_data_1两个库,并且在两个库中都创建出user_0、user_1、user_2三个表。
实际结果也是如此:

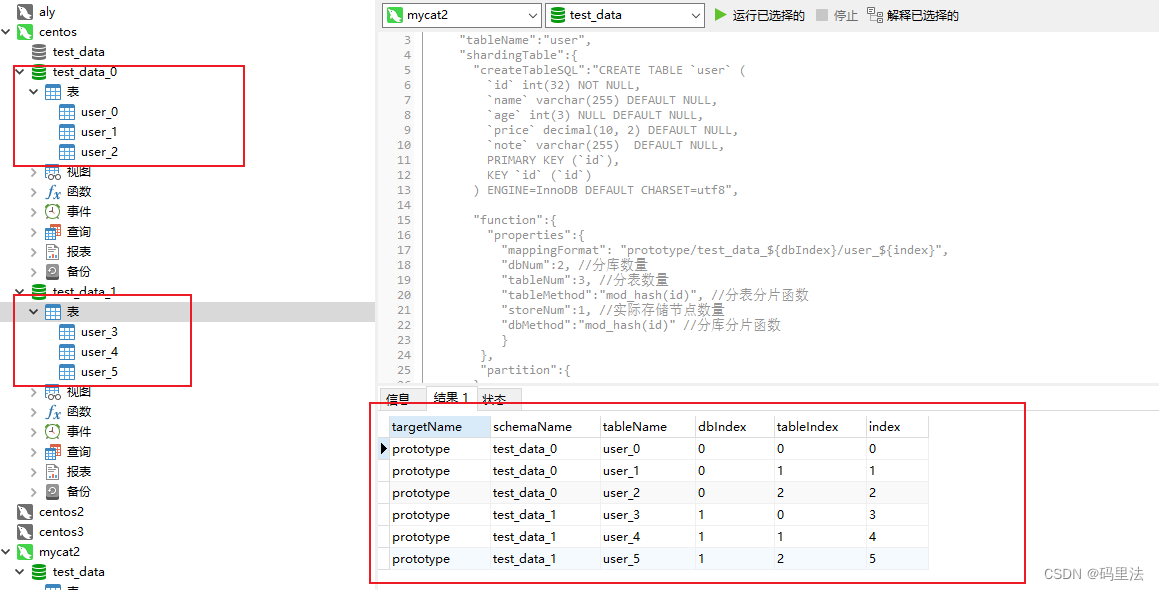
那么我们把规则小小改动一下,将tableIndex改为index,那么结果将会什么呢?
index的值等于所有表的值,我们设置了两个库(dbNum),三个表(tableNum),那么index最大值就是5,所以结果将是:在prototype(127.0.0.1数据源)下创建出test_data_0和test_data_1两个库,并且在0库中会创建出user_0、user_1、user_2三个表,1库中创建出user_3、user_4、user_5三个表。
实际结果也是如此:
案例三
"function":{
"properties":{
"mappingFormat": "c${targetIndex}/test_data_${dbIndex}/user_${index}",
"dbNum":2, //分库数量
"tableNum":3, //分表数量
"tableMethod":"mod_hash(id)", //分表分片函数
"storeNum":2, //实际存储节点数量
"dbMethod":"mod_hash(id)" //分库分片函数
}
},
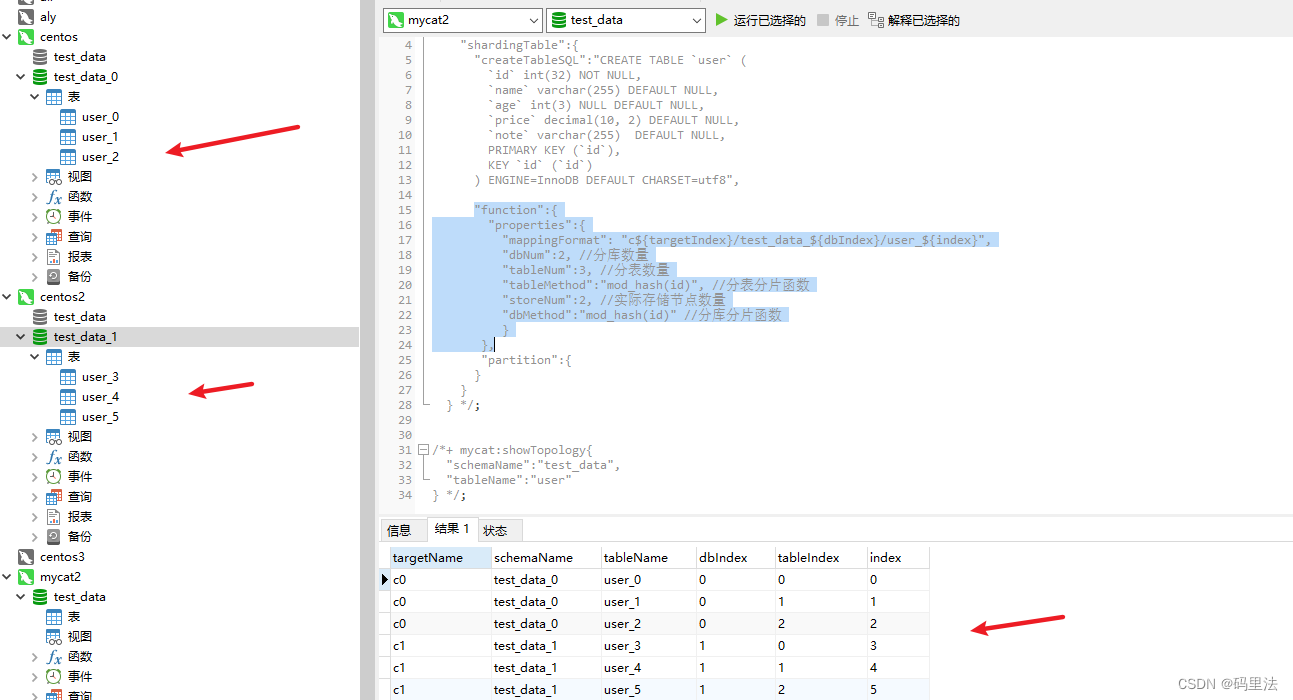
可以看出这里配置了两个变量,因为dbNum=2,tableNum=3,storeNum=3,可以算出dbIndex的取值范围为:{0,1},tableIndex取值范围为:{0,1,2},targetIndex的取值范围为:{0,1},
那么结果将是:在c0数据源下创建出test_data_0库,并且在库中创建出user_0、user_1、user_2三个表,在c1数据源下创建出test_data_1库,并且在库中创建出user_3、user_4、user_5三个表。
实际结果也是如此:
当然,如果你想在不同的数据源下,库名都使用test_data,那么你只需要将test_data_${dbIndex}改成test_data即可,如下图。
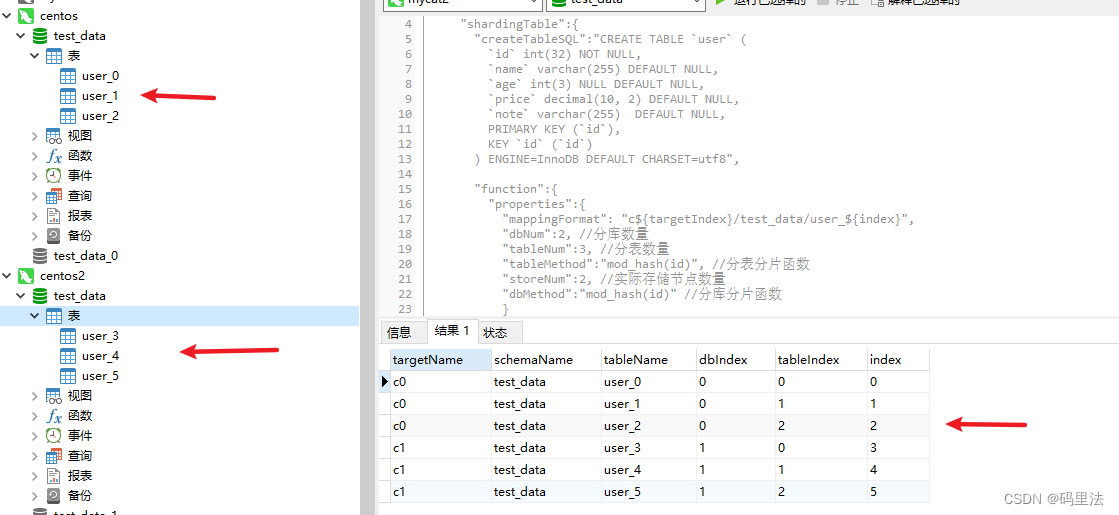
自定义分区
通过上边的讲解,已经能够完成大部分的需求了,但是如果你想不规则的划分分区位置,那么上边的做法可能做不了,因为上边的算法都是平均的,不管是单库、多库、多数据源,举个例子:
如果我想实现一个库里放4张分表(user_0~3),一个库里放2张分表(user_4~5),这个用上边的方法就没法弄了
想实现上边的分区,我们将会用到partition的data属性。
先上代码:
/*+ mycat:createTable{
"schemaName":"test_data",
"tableName":"user",
"shardingTable":{
"createTableSQL":"CREATE TABLE `user` (
`id` int(32) NOT NULL,
`name` varchar(255) DEFAULT NULL,
`age` int(3) NULL DEFAULT NULL,
`price` decimal(10, 2) DEFAULT NULL,
`note` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `id` (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8",
"function":{
"properties":{
"mappingFormat": "c${targetIndex}/test_data/user_${index}",
"dbNum":2, //分库数量
"tableNum":3, //分表数量
"tableMethod":"mod_hash(id)", //分表分片函数
"storeNum":2, //实际存储节点数量
"dbMethod":"mod_hash(id)" //分库分片函数
}
},
"partition":{
//这里自定义,读写分离指定表
"data":[["c0","test_data","user_0","0","0","0"],["c0","test_data","user_1","0","1","1"],["c0","test_data","user_2","0","2","2"],["c0","test_data","user_3","0","3","3"]
,["c1","test_data","user_4","1","0","4"],["c1","test_data","user_5","1","1","5"]
]
}
}
} */;
[“c0”,“test_data”,“user_0”,“0”,“0”,“0”]
c0:集群名字或者数据源名字
test_data:物理库名字
user_0:物理表名字
0:总物理库下标(代表该表所属分库的下标,两个库,0就代表第一个库,1就代表第二个库,对应dbIndex);
0:每物理表下标(代表当前表在所属库中的排位下标,对应tableIndex);
0:总物理分表下标(代表当前表在所有表中的排位下标,对应index)。
当data属性配置后,会覆盖其他的分区配置
接下来看一下实际效果:
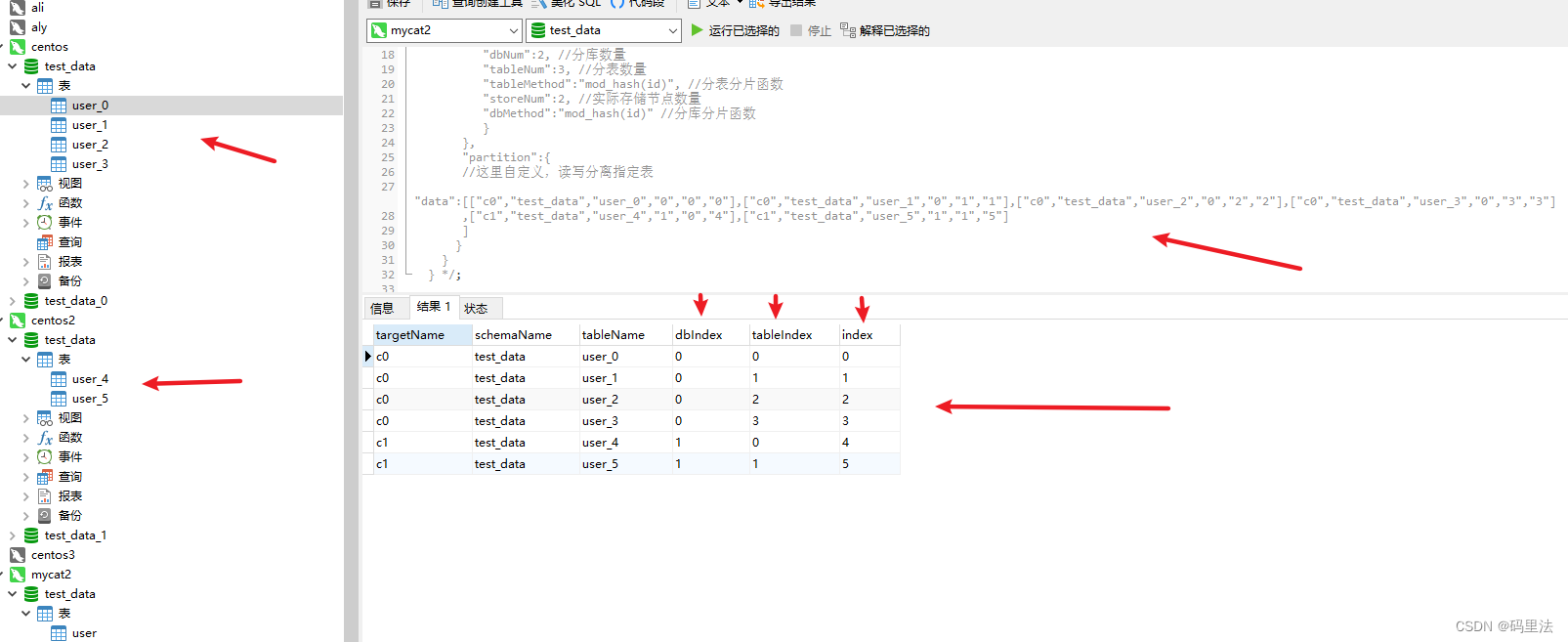
插入数据也是OK的,会根据算法分配到不同的表里。
INSERT INTO user VALUES(1, 'zhangsan',24,12.45,'备注一下');
INSERT INTO user VALUES(2, 'lisi',24,12.45,'备注一下');
INSERT INTO user VALUES(3, 'wangwu',24,12.45,'备注一下');
INSERT INTO user VALUES(4, 'zhaoliu',24,12.45,'备注一下');
INSERT INTO user VALUES(5, 'lili',24,12.45,'备注一下');
INSERT INTO user VALUES(6, 'xi9xi',24,12.45,'备注一下');